


Vor kurzem hat das Großmodell von Yuncong Technology erneut wichtige Fortschritte im Bereich der Sicht gemacht. Der auf dem grundlegenden Großmodell der Sicht basierende Zieldetektor hat im berühmten Benchmark-COCO-Datensatz im Erkennungsbereich von Microsoft hervorragende Ergebnisse erzielt Research (MSR), Shanghai Artificial Intelligence Laboratory und Intelligent Intelligence Viele bekannte Unternehmen und Forschungseinrichtungen wie das Yuan Artificial Intelligence Research Institute stachen hervor und stellten einen neuen Weltrekord auf.


Die durchschnittliche Genauigkeit (im Folgenden als mAP bezeichnet, mittlere durchschnittliche Präzision) des großen Modells von Yuncong Technology auf dem COCO-Testsatz erreichte 0,662 und belegte damit den ersten Platz in der Liste (siehe Abbildung unten). Auf dem Validierungssatz erreichte die Einzelskala einen mAP von 0,656 und der mAP nach der Mehrskalen-TTA erreichte 0,662, beide erreichten weltweit führende Werte.
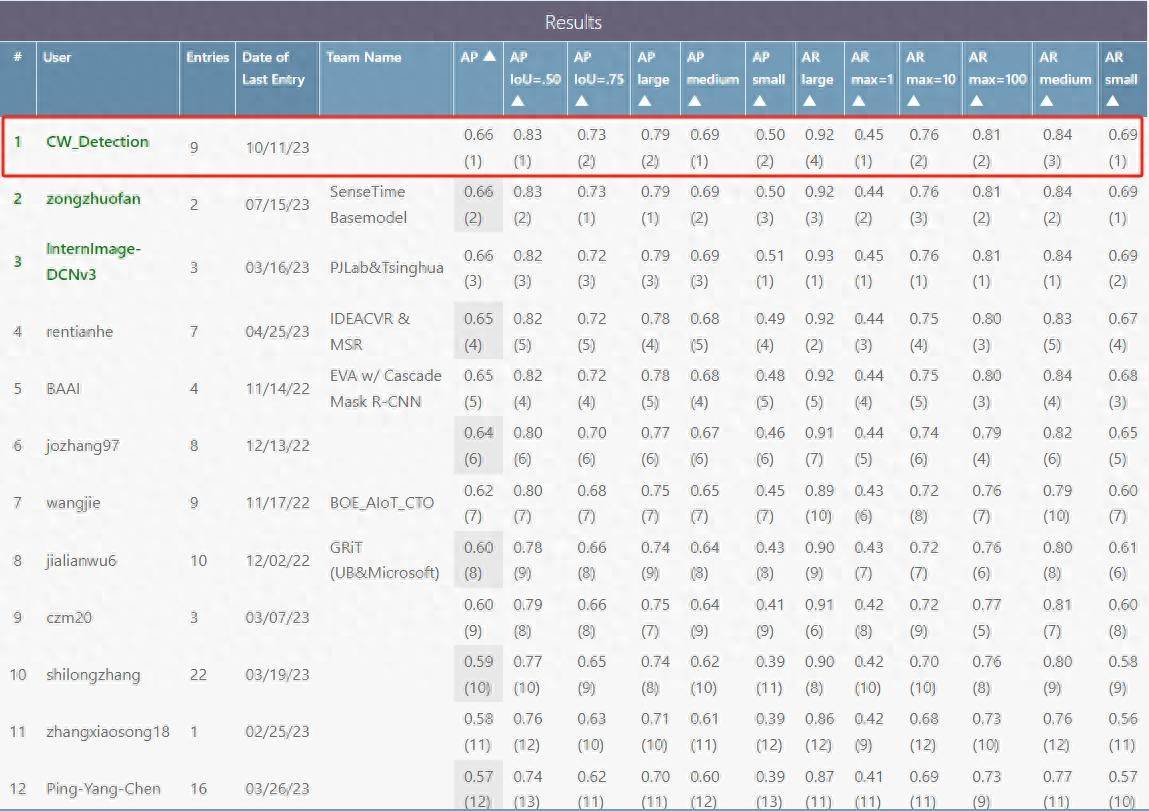
Big Data kombiniert mit selbstüberwachtem Lernen zur Entwicklung zentraler visueller Technologie
Das von GPT repräsentierte selbstüberwachte Big-Data-Vortraining hat bemerkenswerte Durchbrüche im Bereich des natürlichen Sprachverständnisses (NLP) erzielt. Auch im visuellen Bereich hat Big Data in Kombination mit selbstüberwachtem Lernen wichtige Fortschritte beim grundlegenden Modelltraining erzielt.
Einerseits helfen umfangreiche visuelle Daten dem Modell, gemeinsame Grundfunktionen zu erlernen. Das groß angelegte Basismodell von YunCong Vision verwendet mehr als 2 Milliarden Daten, darunter eine große Anzahl unbeschrifteter Datensätze und multimodaler Bild- und Textdatensätze die Komplexität nachgelagerter Entwicklungskosten.
Andererseits erfordert selbstüberwachtes Lernen keine manuelle Annotation, wodurch es möglich ist, visuelle Modelle mit riesigen, unbeschrifteten Daten zu trainieren. Yuncong hat viele Verbesserungen am selbstüberwachten Lernalgorithmus vorgenommen, wodurch er sich besser für feinkörnige Aufgaben wie Erkennung und Segmentierung eignet, wie die guten Ergebnisse bei der COCO-Erkennungsaufgabe belegen.
Offene Zielerkennung + Zero-Time-Learning-Erkennungsfähigkeit reduziert die Forschungs- und Entwicklungskosten erheblich
Dank der hervorragenden Leistung des visuellen Basismodells kann das große Modell von Yuncong Rongrong auf der Grundlage umfangreicher multimodaler Bild- und Textdaten trainiert werden, um die Erkennung von Tausenden von Null-Schuss-Lernen (im Folgenden als Null-Schuss bezeichnet) zu unterstützen Kategorien von Zielen, die Energie, Transport und Fertigung in anderen Branchen abdecken.
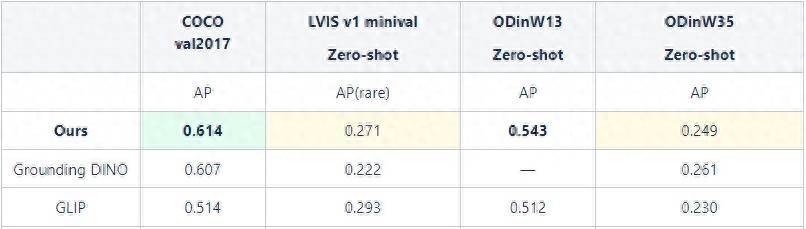 Die Leistung der Zero-Shot-Fähigkeiten großer Modelle auf verschiedenen Datensätzen
Die Leistung der Zero-Shot-Fähigkeiten großer Modelle auf verschiedenen Datensätzen
Zero-Shot kann den menschlichen Denkprozess nachahmen und früheres Wissen nutzen, um über die spezifische Form neuer Objekte im Computer nachzudenken, wodurch der Computer die Fähigkeit erhält, neue Dinge zu erkennen.
Wie ist Zero-Shot zu verstehen? Angenommen, wir kennen die morphologischen Eigenschaften von Eseln und Pferden und wissen auch, dass Tiger und Hyänen gestreifte Tiere sind und Pandas und Pinguine schwarz-weiße Tiere sind. Wir definieren Zebras als Equiden mit schwarzen und weißen Streifen. Ohne sich Fotos von Zebras anzuschauen, sondern nur auf Schlussfolgerungen zu vertrauen, können wir unter allen Tieren im Zoo Zebras finden.
Das große visuelle Basismodell von Yuncong zeigt eine starke Generalisierungsleistung, wodurch die Datenabhängigkeit und die Entwicklungskosten für nachgelagerte Aufgaben erheblich reduziert werden. Gleichzeitig verbessert Zero-Shot die Schulungs- und Entwicklungseffizienz erheblich und ermöglicht eine breite Anwendung und schnelle Bereitstellung.
Das obige ist der detaillierte Inhalt vonDas Großmodell von Yuncong Technology bricht den Weltrekord im COCO-Benchmark und senkt die Kosten für KI-Anwendungen erheblich. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



