


Update: Ein neues Beispiel hinzugefügt, ein selbstfahrendes Lieferfahrzeug, das in den Zementboden von Xinpu fährt
Unter großer Aufmerksamkeit hat GPT4 heute endlich visionäre Funktionen eingeführt. Heute Nachmittag habe ich mit meinen Freunden schnell die Bildwahrnehmungsfähigkeiten von GPT getestet. Obwohl wir Erwartungen hatten, waren wir dennoch sehr schockiert. TL;DR ist Ich denke, die semantischen Probleme beim autonomen Fahren hätten von großen Modellen sehr gut gelöst werden sollen, aber die Glaubwürdigkeit und räumlichen Wahrnehmungsfähigkeiten großer Modelle sind immer noch nicht zufriedenstellend. Es sollte mehr als ausreichen, um einige sogenannte effizienzbezogene Eckfälle zu lösen, aber es ist noch weit entfernt, sich vollständig auf große Modelle zu verlassen, um das Fahren selbstständig abzuschließen und die Sicherheit zu gewährleisten.
 Ungenaue Teile: Die Position des dritten LKW ist von links nach rechts nicht zu unterscheiden und der Text über dem Kopf des zweiten LKW ist eine Vermutung. Eins (wegen unzureichender Auflösung?)
Ungenaue Teile: Die Position des dritten LKW ist von links nach rechts nicht zu unterscheiden und der Text über dem Kopf des zweiten LKW ist eine Vermutung. Eins (wegen unzureichender Auflösung?)
Das reicht nicht, wir geben weiterhin einen kleinen Hinweis, um zu fragen, was dieses Objekt ist und ob es überdrückt werden kann. 
Beeindruckend! Wir haben mehrere ähnliche Szenarien getestet und die Leistung bei unbekannten Hindernissen kann als sehr erstaunlich bezeichnet werden.
2 Beispiel 2: Verständnis der Ansammlung von Straßenwasser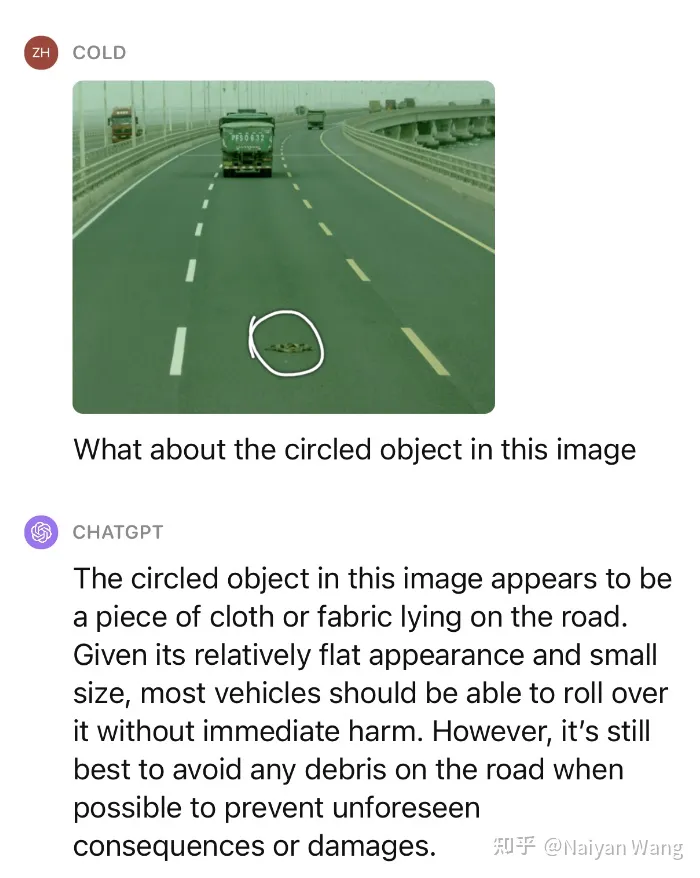
Es gibt keine Aufforderung, das Schild automatisch zu erkennen, wir geben weiterhin einige Hinweise




Ich war zunächst relativ konservativ und habe den Grund nicht direkt erraten. Dies entspricht dem Ziel der Ausrichtung. Nach der Verwendung von CoT wurde festgestellt, dass das Problem darin bestand, dass es sich bei dem Auto nicht um ein selbstfahrendes Fahrzeug handelte, so dass die rechtzeitige Angabe dieser Informationen genauere Informationen liefern kann. Schließlich kann durch eine Reihe von Eingabeaufforderungen der Schluss gezogen werden, dass der neu verlegte Asphalt nicht zum Befahren geeignet ist. Das Endergebnis ist immer noch in Ordnung, aber der Prozess ist umständlicher und erfordert eine schnellere Konstruktion und sorgfältiges Design. Dieser Grund könnte auch darin liegen, dass es sich nicht um ein Bild aus der Ich-Perspektive handelt und nur aus der Perspektive der Dritten Person spekuliert werden kann. Dieses Beispiel ist also nicht sehr präzise.
Einige schnelle Versuche haben die Leistungsfähigkeit und Generalisierungsleistung von GPT4V vollständig bewiesen. Bei entsprechenden Eingabeaufforderungen sollte die Stärke von GPT4V voll ausgenutzt werden können. Die Lösung des semantischen Eckfalls sollte sehr vielversprechend sein, aber das Problem der Illusion wird einige Anwendungen in sicherheitsrelevanten Szenarien immer noch plagen. Ich persönlich finde es sehr spannend, dass der rationelle Einsatz solch großer Modelle die Entwicklung des autonomen L4- und sogar L5-Fahrens erheblich beschleunigen kann. Insbesondere das durchgehende Fahren bleibt ein umstrittenes Thema. Ich habe in letzter Zeit viel nachgedacht, deshalb werde ich Zeit finden, einen Artikel zu schreiben, um mit euch allen zu plaudern~

Originallink: https://mp.weixin.qq.com/s/RtEek6HadErxXLSdtsMWHQ
Das obige ist der detaillierte Inhalt vonSpannend! Eine vorläufige Studie zu GPT-4V beim autonomen Fahren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Welche Fähigkeiten sind erforderlich, um in der PHP-Branche zu arbeiten?
Welche Fähigkeiten sind erforderlich, um in der PHP-Branche zu arbeiten?
 Welche Auswirkungen hat die Schließung von Port 445?
Welche Auswirkungen hat die Schließung von Port 445?
 Mit WLAN verbunden, aber kein Internetzugang möglich
Mit WLAN verbunden, aber kein Internetzugang möglich
 Was sind die häufig verwendeten Funktionen von Informix?
Was sind die häufig verwendeten Funktionen von Informix?
 Was bedeutet Liquidation?
Was bedeutet Liquidation?
 Die heutige Toutiao-Goldmünze entspricht 1 Yuan
Die heutige Toutiao-Goldmünze entspricht 1 Yuan
 Die Bedeutung des Titels in HTML
Die Bedeutung des Titels in HTML
 cmd-Befehl zum Bereinigen von Datenmüll auf Laufwerk C
cmd-Befehl zum Bereinigen von Datenmüll auf Laufwerk C








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



