


Der Zweck des kontinuierlichen Lernens besteht darin, die Fähigkeit des Menschen nachzuahmen, kontinuierlich Wissen in kontinuierlichen Aufgaben anzusammeln. Die größte Herausforderung besteht darin, die Leistung zuvor erlernter Aufgaben aufrechtzuerhalten, nachdem er weiterhin neue Aufgaben gelernt hat, d. h. ein katastrophales Vergessen zu vermeiden (katastrophales Vergessen) . Der Unterschied zwischen kontinuierlichem Lernen und Multitasking-Lernen besteht darin, dass letzteres alle Aufgaben gleichzeitig erhalten kann und das Modell alle Aufgaben gleichzeitig lernen kann, während beim kontinuierlichen Lernen Aufgaben einzeln erscheinen und das Modell dies kann Lernen Sie nur Wissen über eine Aufgabe und vermeiden Sie es, altes Wissen beim Erlernen neuen Wissens zu vergessen. Die University of Southern California und Google Research haben eine neue Methode zur Lösung des kontinuierlichen Lernens vorgeschlagen , wird die Feature-Map jeder Kanalschicht neu programmiert, sodass die neu programmierte Feature-Map für neue Aufgaben geeignet ist. Dieses trainierbare Leichtbaumodul macht nur 0,6 % des gesamten Rückgrats aus. Jede neue Aufgabe kann ein eigenes Leichtbaumodul haben. Theoretisch können unendlich viele neue Aufgaben ohne katastrophales Vergessen gelernt werden. Das Papier wurde im ICCV 2023 veröffentlicht.
Papieradresse: https://arxiv.org/pdf/2307.11386.pdfProjektadresse: https://github.com/gyhandy/Channel-wise-Lightweight- Neuprogrammierung

Die Replay-Methode geht davon aus, dass beim Erlernen einer neuen Aufgabe ein Teil der Daten der alten Aufgabe abgerufen und zusammen mit der neuen Aufgabe trainiert werden kann.
Die Forscher reparierten zunächst das vorab trainierte Rückgrat und fügten dann nach der Faltungsschicht in jedem festen Faltungsblock eine kanalisierte, leichte Neuprogrammierungsschicht (CLR-Schicht) hinzu, um die Merkmale nach dem festen Faltungskern zu verfeinern. wie lineare Veränderungen. Angenommen ein Bild X, können wir für jeden Faltungskern Dynamische Netzwerke: PSP, SupSup, CCLL, Confit, EFTs Wiederholung: ER, DERPP
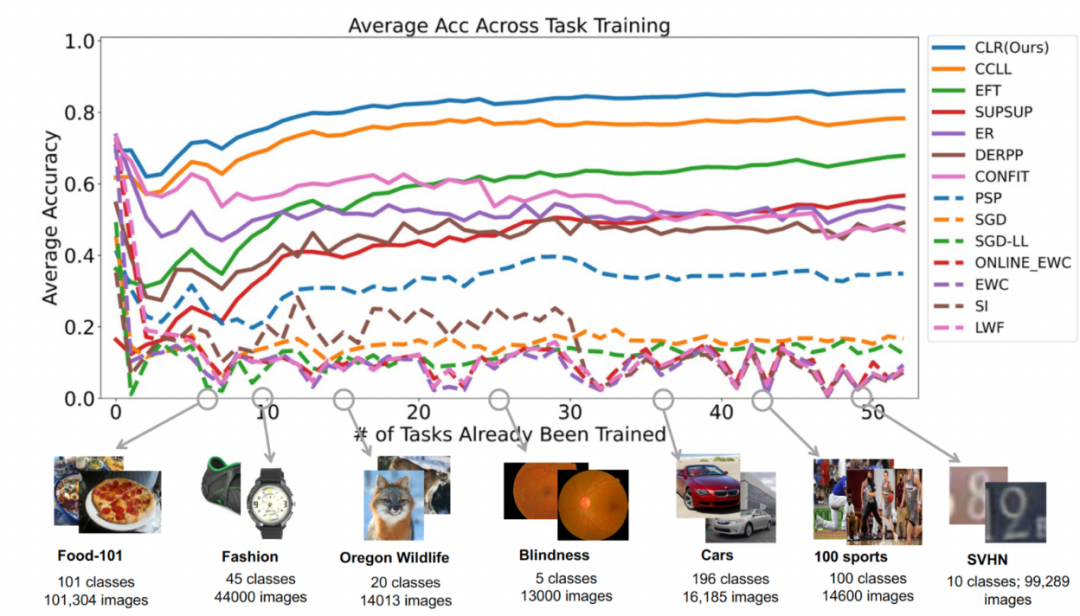
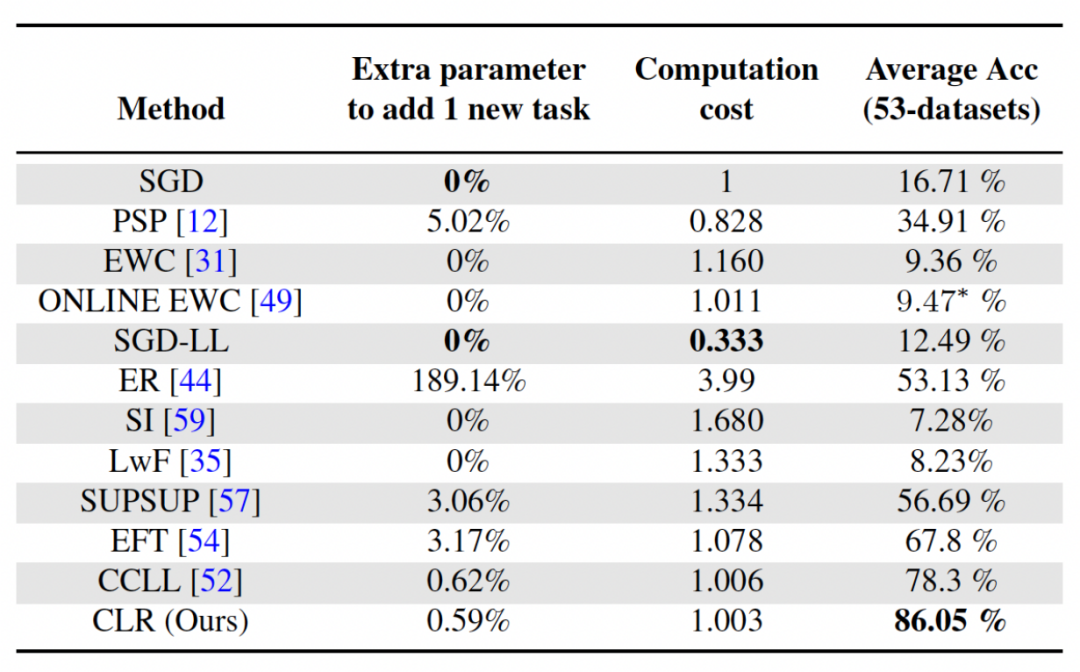
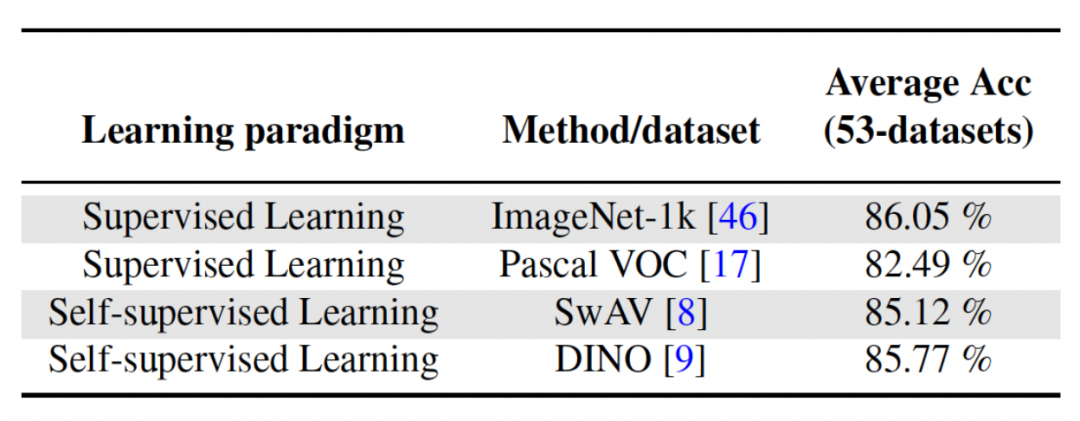
Zweites Experiment: Lernen mit durchschnittlicher Genauigkeit nach Abschluss aller Aufgaben Die folgende Abbildung zeigt die durchschnittliche Genauigkeit aller Methoden nach dem Erlernen aller Aufgaben. Die durchschnittliche Genauigkeit spiegelt die Gesamtleistung der kontinuierlichen Lernmethode wider. Da jede Aufgabe unterschiedliche Schwierigkeitsgrade aufweist, kann die durchschnittliche Genauigkeit aller Aufgaben steigen oder fallen, wenn eine neue Aufgabe hinzugefügt wird, je nachdem, ob die hinzugefügte Aufgabe einfach oder schwierig ist. Lassen Sie uns zunächst die Parameter und den Rechenaufwand analysieren Obwohl es für kontinuierliches Lernen sehr wichtig ist, eine höhere durchschnittliche Genauigkeit zu erzielen, hofft ein guter Algorithmus auch auf eine Maximierung. Reduzieren Sie die Anforderungen für zusätzliche Netzwerkparameter und Rechenkosten. „Zusätzliche Parameter für eine neue Aufgabe hinzufügen“ stellt einen Prozentsatz der ursprünglichen Backbone-Parametermenge dar. In diesem Artikel werden die Berechnungskosten von SGD als Einheit verwendet, und die Berechnungskosten anderer Methoden werden entsprechend den Kosten von SGD normalisiert. Umgeschriebener Inhalt: Wirkungsanalyse verschiedener Backbone-Netzwerke Die Methode in diesem Artikel trainiert ein vorab trainiertes Modell durch die Verwendung von überwachtem Lernen oder selbstüberwachtem Lernen an relativ unterschiedlichen Datensätzen als invarianter, von der Aufgabe unabhängiger Parameter. Um die Auswirkungen verschiedener Pre-Training-Methoden zu untersuchen, wurden in diesem Artikel vier verschiedene, aufgabenunabhängige Pre-Training-Modelle ausgewählt, die mit unterschiedlichen Datensätzen und Aufgaben trainiert wurden. Für das überwachte Lernen verwendeten die Forscher vorab trainierte Modelle auf ImageNet-1k und Pascal-VOC. Für das selbstüberwachte Lernen verwendeten die Forscher vorab trainierte Modelle, die mit zwei verschiedenen Methoden erhalten wurden: DINO und SwAV. Die folgende Tabelle zeigt die durchschnittliche Genauigkeit des vorab trainierten Modells unter Verwendung von vier verschiedenen Methoden. Es ist ersichtlich, dass die Endergebnisse jeder Methode sehr hoch sind (Hinweis: Pascal-VOC ist ein relativ kleiner Datensatz, daher ist die Genauigkeit relativ niedriger Punkt) und ist robust gegenüber verschiedenen vortrainierten Backbones. 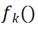 die Feature-Map erhalten, um jeden Kanal linear zu ändern Der Forscher initialisierte den CLR-Faltungskern auf denselben sich ändernden Kernel (d. h. für den 2D-Faltungskern ist nur der mittlere Parameter 1 und der Rest ist 0),
die Feature-Map erhalten, um jeden Kanal linear zu ändern Der Forscher initialisierte den CLR-Faltungskern auf denselben sich ändernden Kernel (d. h. für den 2D-Faltungskern ist nur der mittlere Parameter 1 und der Rest ist 0), 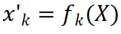 , da dadurch das ursprüngliche feste Rückgrat während der Initialisierung generiert werden kann Training Die Funktionen sind dieselben wie die, die das Modell nach dem Hinzufügen der CLR-Ebene erzeugt. Gleichzeitig werden die Forscher keine CLR-Schicht nach dem Faltungskern hinzufügen, um Parameter zu sparen und eine Überanpassung zu verhindern. Die CLR-Schicht wird erst nach dem Faltungskern agieren. Für ResNet50 nach CLR machen die erhöhten trainierbaren Parameter im Vergleich zum festen ResNet50-Backbone nur 0,59 % aus.
, da dadurch das ursprüngliche feste Rückgrat während der Initialisierung generiert werden kann Training Die Funktionen sind dieselben wie die, die das Modell nach dem Hinzufügen der CLR-Ebene erzeugt. Gleichzeitig werden die Forscher keine CLR-Schicht nach dem Faltungskern hinzufügen, um Parameter zu sparen und eine Überanpassung zu verhindern. Die CLR-Schicht wird erst nach dem Faltungskern agieren. Für ResNet50 nach CLR machen die erhöhten trainierbaren Parameter im Vergleich zum festen ResNet50-Backbone nur 0,59 % aus. 
 Für kontinuierliches Lernen kann das Modell, das trainierbare CLR-Parameter und ein nicht trainierbares Rückgrat hinzufügt, jede Aufgabe nacheinander lernen. Beim Testen gehen die Forscher davon aus, dass es einen Aufgabenprädiktor gibt, der dem Modell mitteilen kann, zu welcher Aufgabe das Testbild gehört, und dann das feste Rückgrat und die entsprechenden aufgabenspezifischen CLR-Parameter die endgültige Vorhersage treffen können. Da CLR die Eigenschaft einer absoluten Parameterisolation aufweist (die Parameter der CLR-Schicht, die jeder Aufgabe entsprechen, sind unterschiedlich und das gemeinsame Backbone ändert sich nicht), wird CLR nicht von der Anzahl der Aufgaben beeinflusst
Für kontinuierliches Lernen kann das Modell, das trainierbare CLR-Parameter und ein nicht trainierbares Rückgrat hinzufügt, jede Aufgabe nacheinander lernen. Beim Testen gehen die Forscher davon aus, dass es einen Aufgabenprädiktor gibt, der dem Modell mitteilen kann, zu welcher Aufgabe das Testbild gehört, und dann das feste Rückgrat und die entsprechenden aufgabenspezifischen CLR-Parameter die endgültige Vorhersage treffen können. Da CLR die Eigenschaft einer absoluten Parameterisolation aufweist (die Parameter der CLR-Schicht, die jeder Aufgabe entsprechen, sind unterschiedlich und das gemeinsame Backbone ändert sich nicht), wird CLR nicht von der Anzahl der Aufgaben beeinflusst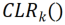 Experimentelle Ergebnisse
Experimentelle Ergebnisse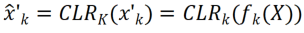 Datensatz: Die Forscher nutzten die Bildklassifizierung als Hauptaufgabe. Das Labor sammelte 53 Bildklassifizierungsdatensätze mit etwa 1,8 Millionen Bildern und 1584 Kategorien. Diese 53 Datensätze enthalten 5 verschiedene Klassifizierungsziele: Objekterkennung, Stilklassifizierung, Szenenklassifizierung, Zählung und medizinische Diagnose.
Datensatz: Die Forscher nutzten die Bildklassifizierung als Hauptaufgabe. Das Labor sammelte 53 Bildklassifizierungsdatensätze mit etwa 1,8 Millionen Bildern und 1584 Kategorien. Diese 53 Datensätze enthalten 5 verschiedene Klassifizierungsziele: Objekterkennung, Stilklassifizierung, Szenenklassifizierung, Zählung und medizinische Diagnose. 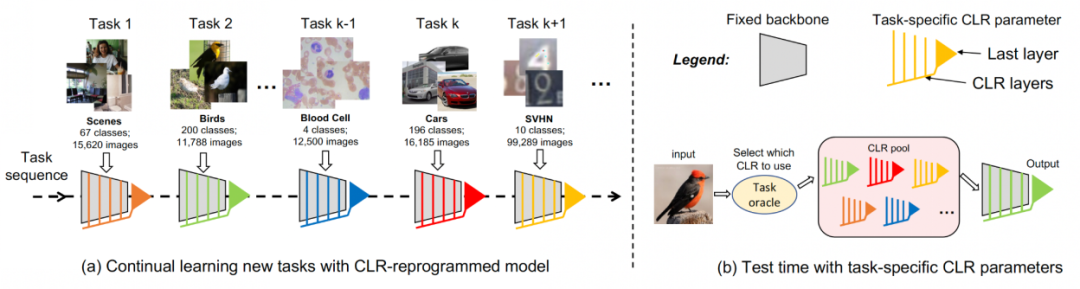 Die Forscher wählten 13 Baselines aus, die grob in 3 Kategorien unterteilt werden können
Die Forscher wählten 13 Baselines aus, die grob in 3 Kategorien unterteilt werden könnenRegularisierung: EWC, Online-EWC, SI, LwF
Es gibt auch einige Grundlinien, die kein kontinuierliches Lernen sind, wie z. B. SGD und SGD-LL. SGD lernt jede Aufgabe durch Feinabstimmung des gesamten Netzwerks. SGD-LL ist eine Variante, die ein festes Backbone für alle Aufgaben und eine lernbare gemeinsame Schicht verwendet, deren Länge der maximalen Anzahl von Kategorien für alle Aufgaben entspricht.
Das obige ist der detaillierte Inhalt vonOptimieren Sie die Lerneffizienz: Übertragen Sie alte Modelle auf neue Aufgaben mit 0,6 % zusätzlichen Parametern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



