


Transformer wurde ursprünglich für Aufgaben zur Verarbeitung natürlicher Sprache entwickelt, wird aber mittlerweile häufig für Bildverarbeitungsaufgaben eingesetzt. Visual Transformer hat bei mehreren visuellen Erkennungsaufgaben eine hervorragende Genauigkeit bewiesen und die beste aktuelle Leistung bei Aufgaben wie Bildklassifizierung, Videoklassifizierung und Objekterkennung erzielt. Ein großer Nachteil von Visual Transformer ist der hohe Rechenaufwand. Typische Faltungsnetzwerke (CNN) erfordern mehrere zehn GFlops pro Bild, während visuelle Transformer oft eine Größenordnung mehr benötigen und Hunderte von GFlops pro Bild erreichen. Bei der Verarbeitung von Videos ist dieses Problem aufgrund der großen Datenmenge noch gravierender. Der hohe Rechenaufwand macht es schwierig, visuelle Transformer auf Geräten mit begrenzten Ressourcen oder strengen Latenzanforderungen bereitzustellen, was die Anwendungsszenarien dieser Technologie einschränkt, sonst hätten wir bereits einige spannende Anwendungen.
In einer aktuellen Arbeit schlugen drei Forscher der University of Wisconsin-Madison, Matthew Dutson, Yin Li und Mohit Gupta, zunächst vor, dass zeitliche Redundanz zwischen aufeinanderfolgenden Eingaben genutzt werden kann, um den visuellen Transformer in Videoanwendungen zu reduzieren . Sie haben auch den Modellcode veröffentlicht, der das PyTorch-Modul enthält, das zum Erstellen des Eventful Transformer verwendet wird.

Natürliche Videos enthalten erhebliche zeitliche Redundanz, d. h. die Unterschiede zwischen aufeinanderfolgenden Bildern sind gering. Dennoch berechnen tiefe Netzwerke, einschließlich Transformers, normalerweise jeden Frame „von Grund auf“. Diese Methode verwirft potenziell relevante Informationen, die durch vorherige Überlegungen gewonnen wurden, was äußerst verschwenderisch ist. Daher fragten sich diese drei Forscher: Können die Zwischenberechnungsergebnisse früherer Berechnungsschritte wiederverwendet werden, um die Effizienz der Verarbeitung redundanter Sequenzen zu verbessern?
Adaptive Inferenz: Bei visuellen Transformern und tiefen Netzwerken im Allgemeinen werden die Kosten der Inferenz oft von der Architektur bestimmt. In realen Anwendungen können sich die verfügbaren Ressourcen jedoch im Laufe der Zeit ändern, beispielsweise aufgrund konkurrierender Prozesse oder Leistungsänderungen. Daher kann es erforderlich sein, die Modellberechnungskosten zur Laufzeit zu ändern. Eines der wichtigsten Designziele, die sich die Forscher bei diesem neuen Projekt gesetzt hatten, war die Anpassungsfähigkeit – ihr Ansatz ermöglichte eine Echtzeitkontrolle der Rechenkosten. Abbildung 1 unten (unten) zeigt ein Beispiel für die Änderung des Rechenbudgets während der Videoverarbeitung.
Ereignisbasierter Transformer: In diesem Artikel wird ein ereignisbasierter Transformer vorgeschlagen, der zeitliche Redundanz zwischen Eingaben nutzen kann, um effizientes und adaptives Denken zu erreichen. Der Begriff Eventisierung ist inspiriert von Ereigniskameras, Sensoren, die diskret Bilder aufzeichnen, wenn sich die Szene ändert. Der ereignisbasierte Transformer verfolgt Änderungen auf Tokenebene im Laufe der Zeit und aktualisiert die Tokendarstellung und die Selbstaufmerksamkeitskarte bei jedem Zeitschritt selektiv. Das ereignisbasierte Transformer-Modul enthält ein Gating-Modul zur Steuerung der Anzahl der Aktualisierungstoken. Diese Methode eignet sich für bestehende Modelle (normalerweise ohne Umschulung) und ist für viele Videoverarbeitungsaufgaben geeignet. Die Forscher führten auch Experimente durch, um zu beweisen, dass die Ergebnisse zeigen, dass der Eventful Transformer auf den besten vorhandenen Modellen verwendet werden kann, während der Rechenaufwand erheblich reduziert und die ursprüngliche Genauigkeit beibehalten wird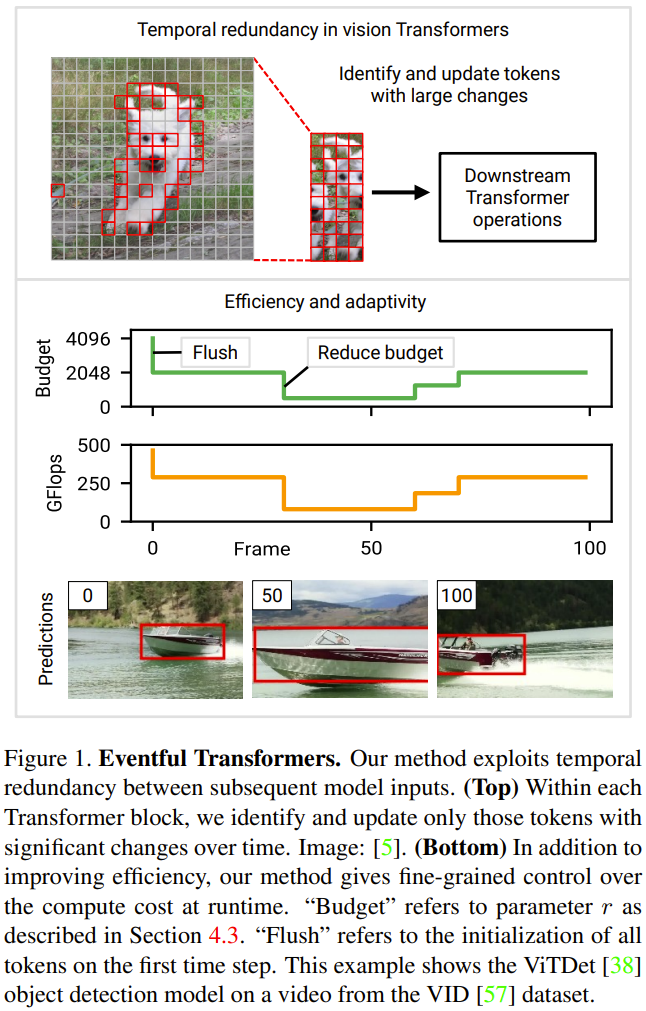
Eventful Transformer
Umgeschriebener Inhalt: Das Ziel von Ziel dieser Forschung ist es, visuelle Transformer für die Videoerkennung zu beschleunigen. In diesem Szenario muss der visuelle Transformer Videobilder oder Videoclips wiederholt verarbeiten. Zu den spezifischen Aufgaben gehören die Erkennung von Videozielen und Videoaktionen. Die vorgeschlagene Schlüsselidee besteht darin, zeitliche Redundanz auszunutzen, d. h. Berechnungsergebnisse aus früheren Zeitschritten wiederzuverwenden. Im Folgenden wird detailliert beschrieben, wie das Transformer-Modul so geändert wird, dass es Zeitredundanz wahrnehmen kann
Token-Gating: Erkennen von Redundanz
In diesem Abschnitt werden zwei neue Module vorgestellt, die von Forschern vorgeschlagen wurden: Token-Gate und Token-Puffer. Diese Module ermöglichen es dem Modell, Token zu identifizieren und zu aktualisieren, die sich seit der letzten Aktualisierung erheblich geändert haben. Gate-Modul: Dieses Gate wählt einen Teil M aus dem Eingabe-Token N aus und sendet ihn an die nachgelagerte Ebene, um Berechnungen durchzuführen. Es verwaltet einen Referenz-Token-Satz in seinem Speicher, der als u bezeichnet wird. Dieser Referenzvektor enthält den Wert jedes Tokens zum Zeitpunkt seiner letzten Aktualisierung. Bei jedem Zeitschritt wird jeder Token mit seinem entsprechenden Referenzwert verglichen und der Token, der sich deutlich vom Referenzwert unterscheidet, wird aktualisiert.
Markieren Sie nun den aktuellen Eingang dieses Gates als c. Bei jedem Zeitschritt wird der Zustand des Gates aktualisiert und seine Ausgabe wird gemäß dem folgenden Prozess bestimmt (siehe Abbildung 2 unten):
1 Berechnen Sie den Gesamtfehler e = u − c. 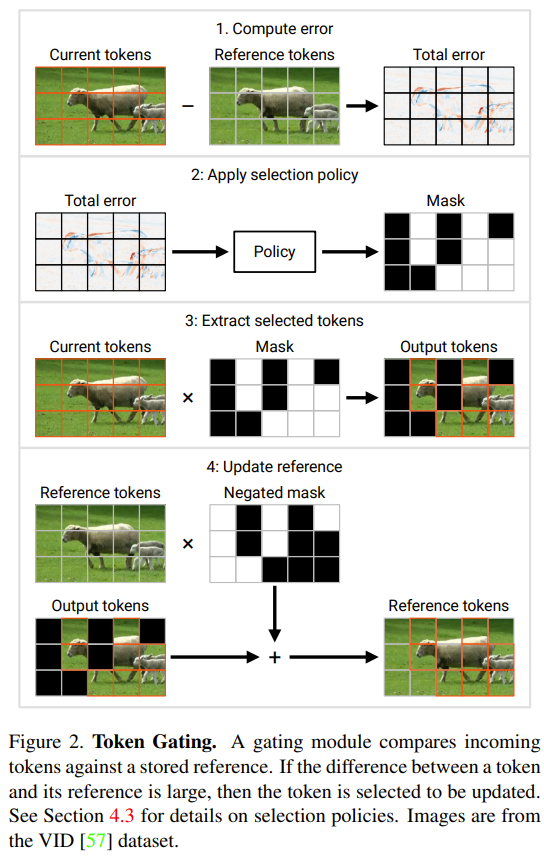
2. Verwenden Sie eine Auswahlstrategie für den Fehler z. Die Auswahlstrategie gibt eine Binärmaske m (entspricht einer Token-Indexliste) zurück, die angibt, welche M Token aktualisiert werden sollen.
3. Extrahieren Sie den mit der oben genannten Strategie ausgewählten Token. Dies wird in Abbildung 2 als Produkt c × m beschrieben. In der Praxis wird es durch Ausführen einer „Sammel“-Operation entlang der ersten Achse von c erreicht. Die gesammelten Token werden hier als
aufgezeichnet, was der Ausgang des Gates ist. 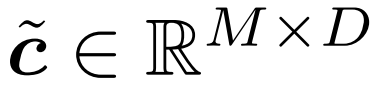 4. Aktualisieren Sie den Referenztoken auf den ausgewählten Token. Abbildung 2 beschreibt diesen Prozess als
4. Aktualisieren Sie den Referenztoken auf den ausgewählten Token. Abbildung 2 beschreibt diesen Prozess als
; die in der Praxis verwendete Operation ist „Streuung“. Im ersten Zeitschritt aktualisiert das Gatter alle Token (initialisiert u ← c und gibt c˜ = c zurück). 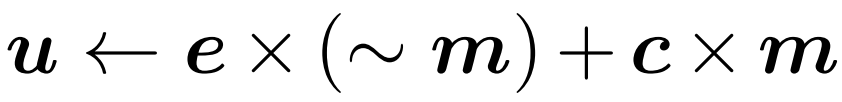 Puffermodul: Das Puffermodul verwaltet einen Zustandstensor
Puffermodul: Das Puffermodul verwaltet einen Zustandstensor
, der jedes Eingabe-Token 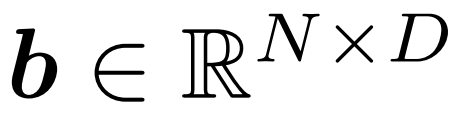 verfolgt. Der Puffer verteilt die Token von f (c˜) an die entsprechende Position in b. Anschließend wird das aktualisierte b als Ausgabe zurückgegeben, siehe Abbildung 3 unten.
verfolgt. Der Puffer verteilt die Token von f (c˜) an die entsprechende Position in b. Anschließend wird das aktualisierte b als Ausgabe zurückgegeben, siehe Abbildung 3 unten.
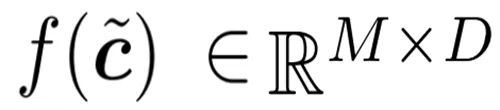
Die Forscher paarten jede Tür mit einem Puffer dahinter. Das Folgende ist ein einfaches Verwendungsmuster: Die Ausgabe des Gatters 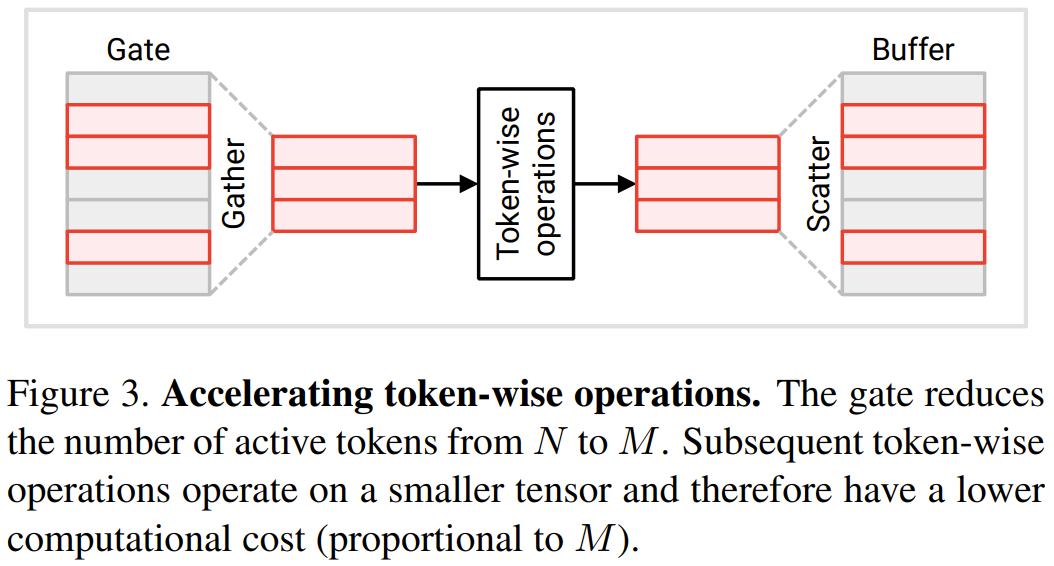
wird an eine Reihe von Operationen f (c˜) für jeden Token übergeben; dann wird der resultierende Tensor
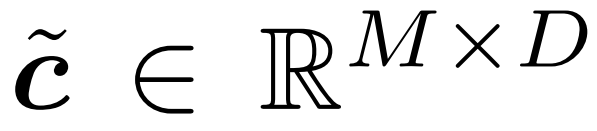 an einen Puffer übergeben, dessen vollständige Form wird wiederhergestellt.
an einen Puffer übergeben, dessen vollständige Form wird wiederhergestellt. 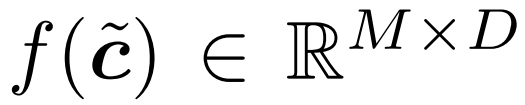 Rekonstruieren Sie den Transformer mit wahrnehmbarer Redundanz
Rekonstruieren Sie den Transformer mit wahrnehmbarer Redundanz
Um die oben genannte Zeitredundanz zu nutzen, schlug der Forscher ein Modifikationsschema für das Transformer-Modul vor. Abbildung 4 unten zeigt das Design des Eventful Transformer-Moduls. Diese Methode kann Vorgänge an einzelnen Token (z. B. MLP) sowie die Multiplikation von Abfrageschlüsselwerten und Aufmerksamkeitswerten beschleunigen.
Im Operation Transformer-Modul für jeden Token gelten viele Operationen für jeden Token, was bedeutet, dass sie keinen Informationsaustausch zwischen Token beinhalten, einschließlich linearer Transformationen in MLP und MSA. Um Rechenkosten zu sparen, gaben die Forscher an, dass tokenorientierte Operationen an Token, die nicht vom Gate ausgewählt wurden, übersprungen werden können. Aufgrund der Unabhängigkeit zwischen den Token ändert sich dadurch nicht das Ergebnis der Operation für den ausgewählten Token. Siehe Abbildung 3.
Konkret verwendeten die Forscher eine kontinuierliche Sequenz eines Gate-Puffer-Paares bei der Verarbeitung der Operationen jedes Tokens, einschließlich W_qkv-Transformation, W_p-Transformation und MLP. Es ist zu beachten, dass vor dem Überspringen der Verbindung auch ein Puffer hinzugefügt wurde, um sicherzustellen, dass die Token der beiden Additionsoperanden ordnungsgemäß ausgerichtet sind. Die Operationskosten für jedes Token sind proportional zur Anzahl der Token. Durch die Reduzierung der Zahl von N auf M werden die Downstream-Operationskosten pro Token um das N/M-fache reduziert. Schauen wir uns nun die Ergebnisse des Abfrage-Schlüssel-Wert-Produkts B = q k^T an Abbildung 5 unten zeigt eine Methode zum sparsamen Aktualisieren einer Teilmenge von Elementen im Abfrage-Schlüssel-Wert-Produkt B.
Die Gesamtkosten dieser Updates betragen 2NMD, verglichen mit den Kosten für die Berechnung von B von Grund auf N^2D. Beachten Sie, dass die Kosten der neuen Methode proportional zu M sind, der Anzahl der ausgewählten Token. Wenn M
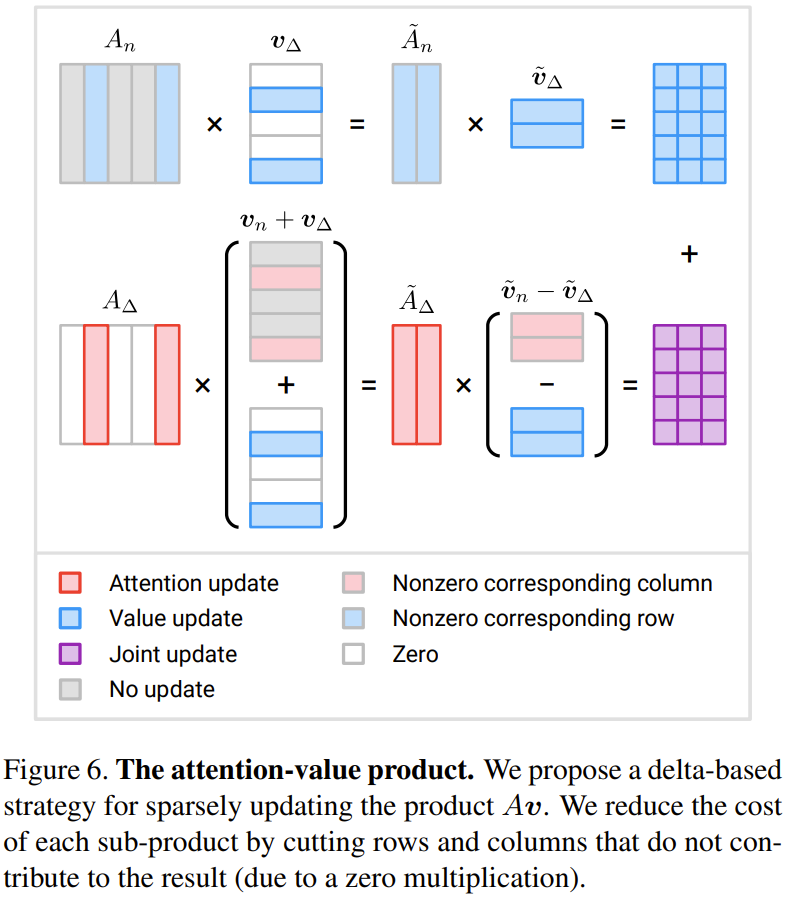
Achtung – Produkt von Werten: Der Forscher hat eine Methode vorgeschlagen, die auf dem Inkrement Δ basiert Update-Strategie.
Abbildung 6 zeigt eine neu vorgeschlagene Methode zur effizienten Berechnung von drei inkrementellen Termen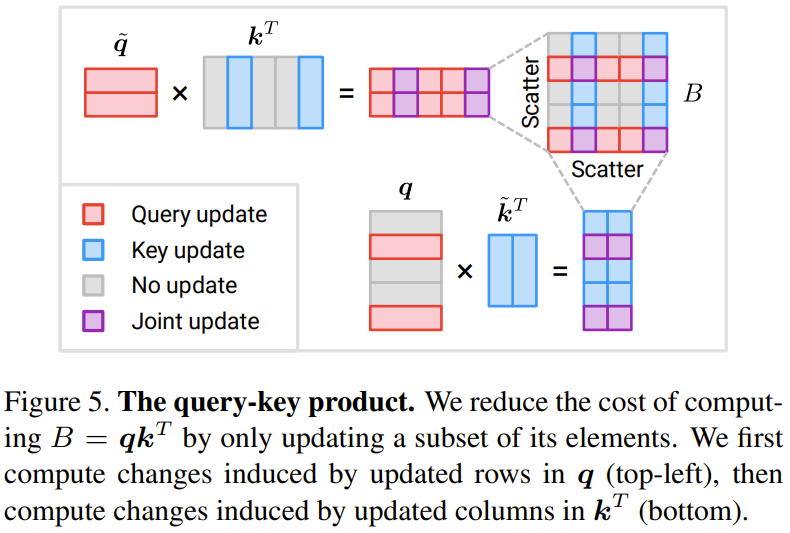
Wenn M weniger als die Hälfte von N beträgt, kann der Berechnungsaufwand reduziert werden
Token-Auswahlstrategie
Top-r-Strategie: Diese Strategie wählt r Token mit dem größten Fehler e aus (hier wird die L2-Norm verwendet).
Schwellenwertstrategie: Diese Strategie wählt alle Token aus, deren Fehlernorm e den Schwellenwert h überschreitet.
Umgeschriebener Inhalt: Andere Strategien: Mit komplexeren und ausgefeilteren Token-Auswahlstrategien können bessere Ergebnisse erzielt werden. Kompromiss zwischen Genauigkeit und Kosten Beispielsweise kann ein leichtgewichtiges Richtliniennetzwerk zum Erlernen der Richtlinie verwendet werden. Das Training des Entscheidungsmechanismus der Richtlinie kann jedoch auf Schwierigkeiten stoßen, da die Binärmaske m normalerweise nicht differenzierbar ist. Eine andere Idee besteht darin, den Wichtigkeitswert als Referenzinformation für die Auswahl zu verwenden. Diese Ideen erfordern jedoch noch weitere Forschung.
Experimente Experimentelle Ergebnisse der Zielerkennung. Dabei ist die positive Achse die rechnerische Einsparungsrate und die negative Achse die relative Reduzierung des mAP50-Scores für die neue Methode. Es ist ersichtlich, dass die neue Methode bei geringem Genauigkeitsverlust erhebliche Recheneinsparungen erzielt.
Abbildung 8 unten zeigt den Methodenvergleich und die experimentellen Ablationsergebnisse für die Videozielerkennungsaufgabe.
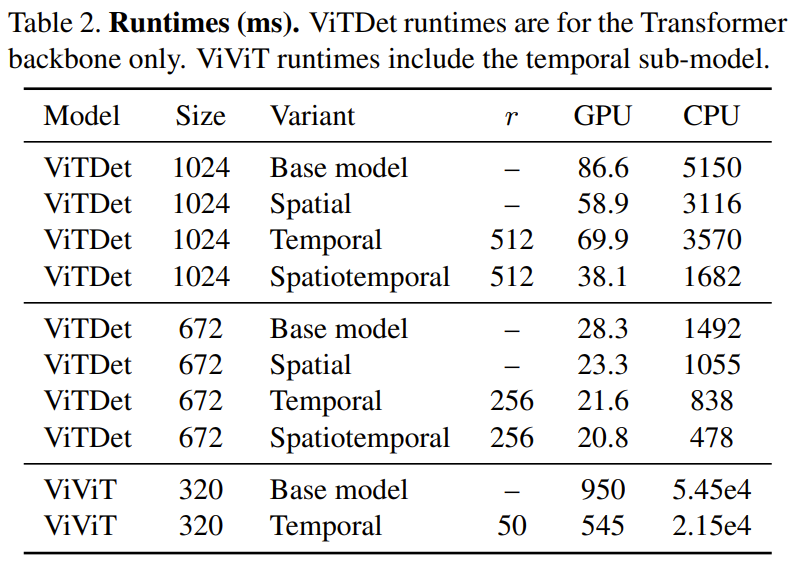
In Tabelle 2 unten werden die Zeitergebnisse (in Millisekunden) angezeigt, die auf einer CPU (Xeon Silver 4214, 2,2 GHz) und einer GPU (NVIDIA RTX3090) ausgeführt werden. Es ist zu beobachten, dass die Zeitredundanz auf der GPU eine Geschwindigkeitssteigerung um das 1,74-fache mit sich bringt, während die Verbesserung auf der CPU das 2,47-fache erreicht.
Weitere technische Details und experimentelle Ergebnisse finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonEine überraschende Methode der zeitlichen Redundanz: eine neue Möglichkeit, den Rechenaufwand visueller Transformer zu reduzieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

































