


Glauben Sie, dass dies ein gewöhnliches selbstfahrendes Video ist?
 Bilder
Bilder
Dieser Inhalt muss ins Chinesische umgeschrieben werden, ohne die ursprüngliche Bedeutung zu ändern
Kein einziges Bild ist „echt“.
 Bilder
Bilder
Verschiedene Straßenbedingungen, verschiedene Wetterbedingungen und mehr als 20 Situationen können simuliert werden, und der Effekt ist genau wie im Original.
 Bilder
Bilder
Das Weltmodell hat wieder tolle Arbeit geleistet! LeCun hat dies begeistert retweetet, nachdem er es gesehen hat.
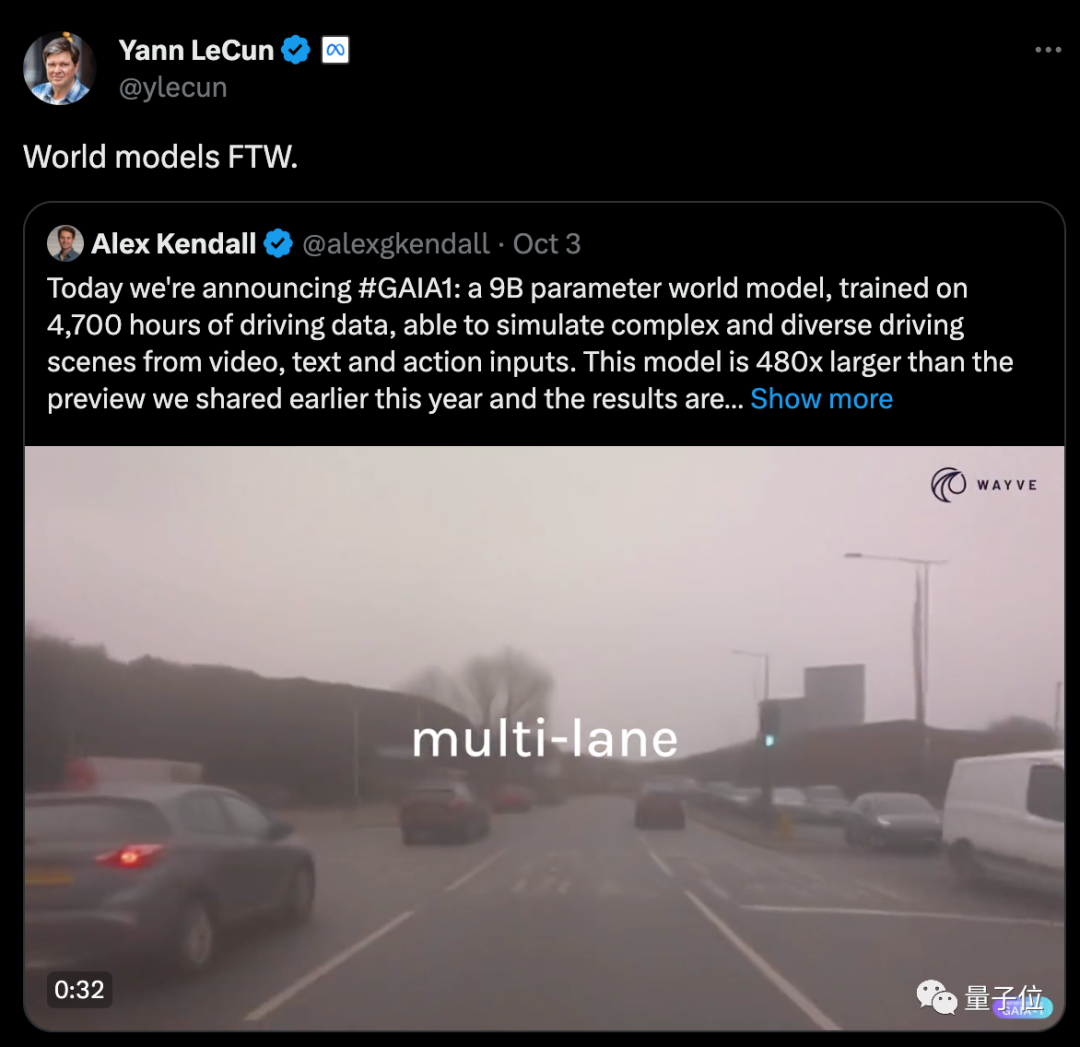 Bilder
Bilder
Den oben genannten Effekten wird dies durch die neueste Version von GAIA-1 erreicht
Der Umfang dieses Projekts hat 9 Milliarden Parameter erreicht und wurde durch 4700 Stunden Fahrvideotraining erfolgreich erreicht Das Eingabevideo. Der unmittelbarste Vorteil der Generierung selbstfahrender Videos aus Text oder Vorgängen besteht darin, dass zukünftige Ereignisse besser vorhergesagt werden können und mehr als 20 Szenarien simuliert werden können, wodurch die Sicherheit des selbstfahrenden Fahrens weiter verbessert und die Kosten gesenkt werden.
Bilder Unser Kreativteam hat unverblümt erklärt, dass dies die Regeln des autonomen Fahrspiels völlig ändern wird!
Unser Kreativteam hat unverblümt erklärt, dass dies die Regeln des autonomen Fahrspiels völlig ändern wird!
Wie wird GAIA-1 umgesetzt? „Je größer der Maßstab, desto besser.“ Verhalten und Szenenmerkmale
Videos können nur mithilfe von Textaufforderungen generiert werden
Bilder
Das Modellprinzip ähnelt großen Sprachmodellen, d Die Videobilder und die anschließende Vorhersage zukünftiger Szenen werden in die Vorhersage des nächsten Tokens in der Sequenz umgewandelt. Das Diffusionsmodell wird dann verwendet, um hochwertige Videos aus dem Sprachraum des Weltmodells zu generieren. Die spezifischen Schritte sind wie folgt: Bilder
Bilder
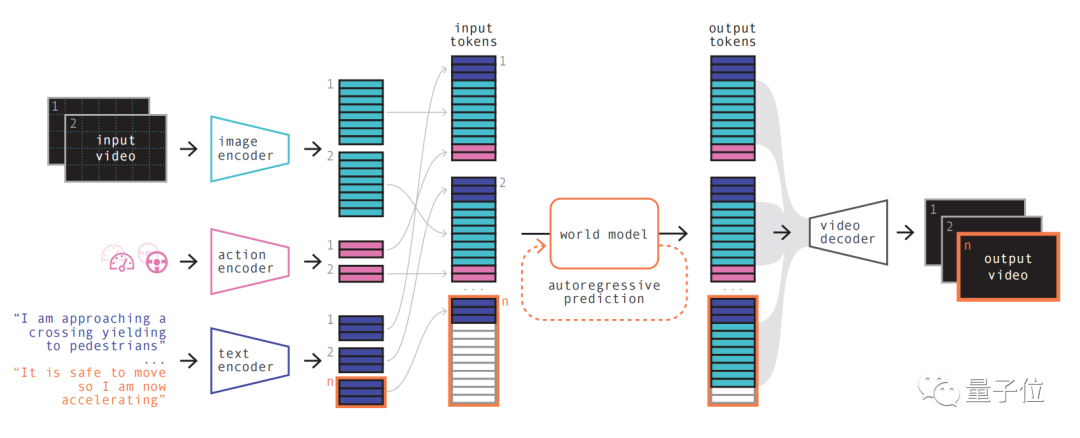 Als autoregressiver Transformer kann er den nächsten Satz von Bild-Tokens in der Sequenz vorhersagen. Und es berücksichtigt nicht nur das vorherige Bild-Token, sondern auch die Kontextinformationen des Textes und der Operation. Der vom Modell generierte Inhalt behält nicht nur die Konsistenz des Bildes bei, sondern stimmt auch mit dem vorhergesagten Text und den vorhergesagten Aktionen überein
Als autoregressiver Transformer kann er den nächsten Satz von Bild-Tokens in der Sequenz vorhersagen. Und es berücksichtigt nicht nur das vorherige Bild-Token, sondern auch die Kontextinformationen des Textes und der Operation. Der vom Modell generierte Inhalt behält nicht nur die Konsistenz des Bildes bei, sondern stimmt auch mit dem vorhergesagten Text und den vorhergesagten Aktionen überein
Das Team stellte fest, dass die Weltmodellgröße in GAIA-1 6,5 Milliarden Parameter beträgt und auf 64 trainiert wurde A100s für 15 Tage.
Verwenden Sie abschließend den Videodecoder und das Videodiffusionsmodell, um diese Token wieder in Videos umzuwandeln.
Die Bedeutung dieses Schritts besteht darin, die semantische Qualität, Bildgenauigkeit und zeitliche Konsistenz des Videos sicherzustellen.
Der Videodecoder von GAIA-1 verfügt über eine Skala von 2,6 Milliarden Parametern und wurde 15 Tage lang mit 32 A100 trainiert.
Es ist erwähnenswert, dass GAIA-1 nicht nur dem Prinzip großer Sprachmodelle ähnelt, sondern auch die Merkmale einer verbesserten Generierungsqualität mit zunehmender Modellskala aufweist
Bilder
Das Team überprüfte die zuvor veröffentlicht im Juni Die frühe Version und der neueste Effekt wurden verglichen Letzterer ist 480-mal größer als ersterer. Sie können intuitiv erkennen, dass die Videodetails und die Auflösung deutlich verbessert wurden.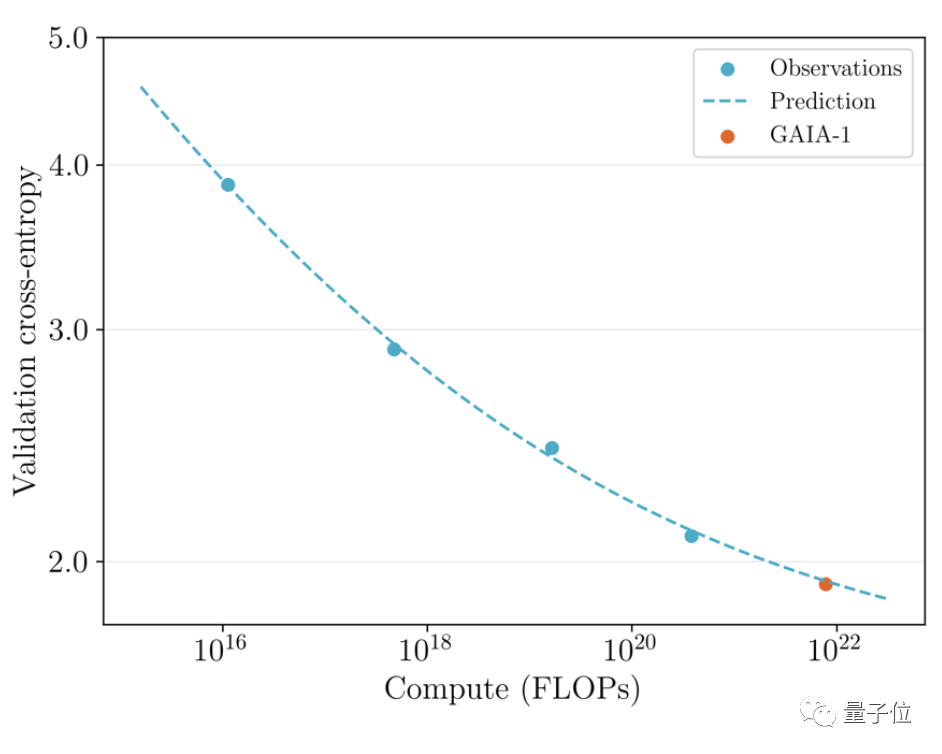 Bilder
Bilder
 Bilder
Bilder
Die Gründe lassen sich aus drei Aspekten erklären:
Zuallererst kann das Weltmodell in Bezug auf die Sicherheit die Zukunft simulieren. Geben Sie der KI die Möglichkeit, Ihre eigenen Entscheidungen zu treffen, was für die Sicherheit des autonomen Fahrens von entscheidender Bedeutung ist.
Zweitens sind Trainingsdaten auch für das autonome Fahren sehr wichtig. Die generierten Daten sind sicherer, kostengünstiger und unbegrenzt skalierbar. Generative KI kann eine der Long-Tail-Szenario-Herausforderungen beim autonomen Fahren lösen. Es kann mehr Randszenarien bewältigen, beispielsweise die Begegnung mit Fußgängern, die bei nebligem Wetter die Straße überqueren. Dadurch werden die Möglichkeiten des autonomen Fahrens weiter verbessert
Wer ist Wayve?
Wayve wurde 2017 gegründet. Zu den Investoren zählen Microsoft und andere, und seine Bewertung hat Einhorn erreicht.
Die Gründer sind Alex Kendall und Amar Shah, die beide einen Doktortitel in maschinellem Lernen von der Universität Cambridge haben haben die hochpräzisen Karten schon sehr früh aufgegeben und sind konsequent dem Weg der „Echtzeitwahrnehmung“ gefolgt.
Vor nicht allzu langer Zeit erregte auch ein weiteres vom Team veröffentlichtes großes Modell LINGO-1 große Aufmerksamkeit
Dieses autonome Fahrmodell kann während der Fahrt Erklärungen in Echtzeit generieren und so die Interpretierbarkeit des Modells weiter verbessern Im März dieses Jahres Auch Bill Gates machte eine Probefahrt mit Wayves selbstfahrendem Auto.
Im März dieses Jahres Auch Bill Gates machte eine Probefahrt mit Wayves selbstfahrendem Auto.
Papieradresse:
//m.sbmmt.com/link/1f8c4b6a0115a4617e285b4494126fbfReferenzlink:  [1]//m.sbmmt.com/link/ 85dca1d 270f7f9aef00c9d372f114482 [2]
[1]//m.sbmmt.com/link/ 85dca1d 270f7f9aef00c9d372f114482 [2]
Das obige ist der detaillierte Inhalt vonLeCun war zutiefst enttäuscht über den Betrug mit selbstfahrenden Einhörnern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Der Unterschied zwischen PD-Schnellladen und allgemeinem Schnellladen
Der Unterschied zwischen PD-Schnellladen und allgemeinem Schnellladen
 So geben Sie den Drucker in Win10 frei
So geben Sie den Drucker in Win10 frei
 WAN-Zugriffseinstellungen
WAN-Zugriffseinstellungen
 Java-Export Excel
Java-Export Excel
 Virtuelle Mobiltelefonnummer, um den Bestätigungscode zu erhalten
Virtuelle Mobiltelefonnummer, um den Bestätigungscode zu erhalten
 Der Unterschied zwischen leichtgewichtigen Anwendungsservern und Cloud-Servern
Der Unterschied zwischen leichtgewichtigen Anwendungsservern und Cloud-Servern
 Vollständige Sammlung von HTML-Tags
Vollständige Sammlung von HTML-Tags
 Die Rolle des Index
Die Rolle des Index








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



