


Bei Zeitreihenproblemen gibt es eine Art von Zeitreihen, die nicht mit gleichen Häufigkeiten abgetastet werden, d. h. die Zeitintervalle zwischen zwei benachbarten Beobachtungen in jeder Gruppe sind unterschiedlich. Das Lernen der Zeitreihendarstellung wurde in Zeitreihen mit gleicher Häufigkeit viel untersucht, es gibt jedoch weniger Forschung zu dieser Zeitreihe mit unregelmäßiger Stichprobe, und die Modellierungsmethode dieser Art von Zeitreihen unterscheidet sich von der bei der Stichprobe mit gleicher Häufigkeit ist ein großer Unterschied in den Modellierungsmethoden
Der heute vorgestellte Artikel untersucht die Anwendungsmethode des Repräsentationslernens beim Problem der unregelmäßigen Stichprobenzeitreihen, stützt sich auf relevante Erfahrungen im NLP und erzielt bemerkenswerte Vergleichsergebnisse bei nachgelagerten Aufgaben. 🔜 Datendefinition
Das Folgende ist eine Darstellung unregelmäßiger Zeitreihendaten, wie in der folgenden Abbildung dargestellt. Jede Zeitreihe besteht aus einer Reihe von Tripeln. Jedes Tripel enthält drei Felder: Zeit, Wert und Merkmal, die jeweils die Abtastzeit, den Wert und andere Merkmale jedes Elements in der Zeitreihe darstellen. Zusätzlich zu diesen Tripeln enthält jede Sequenz auch andere statische Merkmale, die sich im Laufe der Zeit nicht ändern, sowie Beschriftungen für jede Zeitreihe Dreifache Daten werden separat eingebettet, zusammengefügt und in Modelle wie Transformer eingegeben. Auf diese Weise werden die Informationen zu jedem Zeitpunkt und die Zeitdarstellung zu jedem Zeitpunkt integriert und in das Modell eingegeben, um nachfolgende Aufgaben vorherzusagen. 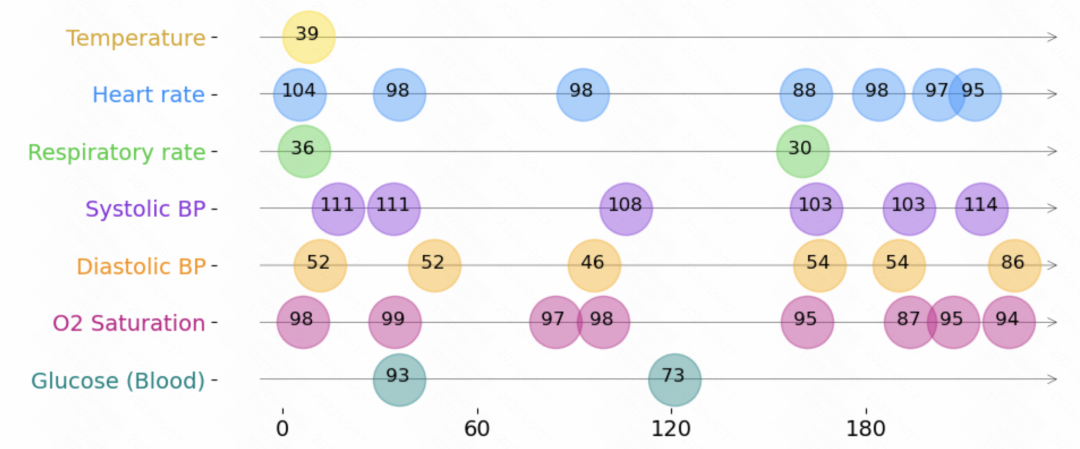
Gestaltung von Vortrainingsaufgaben: Um unregelmäßige Zeitreihen zu verarbeiten, angemessen Das Vortraining muss entworfen werden. Die Aufgabe ermöglicht es dem Modell, effektive Darstellungen aus unbeaufsichtigten Daten zu lernen. In diesem Artikel werden hauptsächlich zwei Vortrainingsaufgaben vorgestellt, die auf Vorhersagen und Rekonstruktionen basieren.
Entwurf von Datenverbesserungsmethoden: In dieser Studie wurde eine Datenverbesserungsmethode für unbeaufsichtigtes Lernen entwickelt, einschließlich Hinzufügen von Rauschen, Hinzufügen von Zufallsmasken usw. 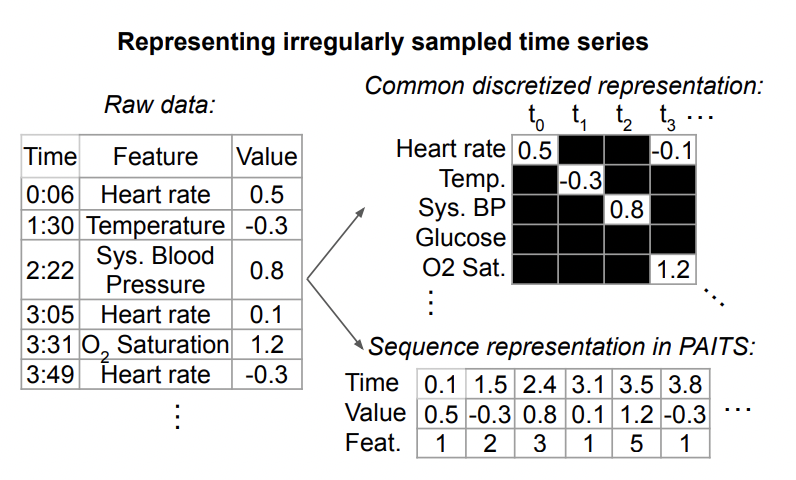 Darüber hinaus stellt der Artikel auch einen Algorithmus für verschiedene verteilte Datensätze vor, um die optimale Methode für unbeaufsichtigtes Lernen zu erkunden und Wiederaufbau-Vorschulung.
Darüber hinaus stellt der Artikel auch einen Algorithmus für verschiedene verteilte Datensätze vor, um die optimale Methode für unbeaufsichtigtes Lernen zu erkunden und Wiederaufbau-Vorschulung.
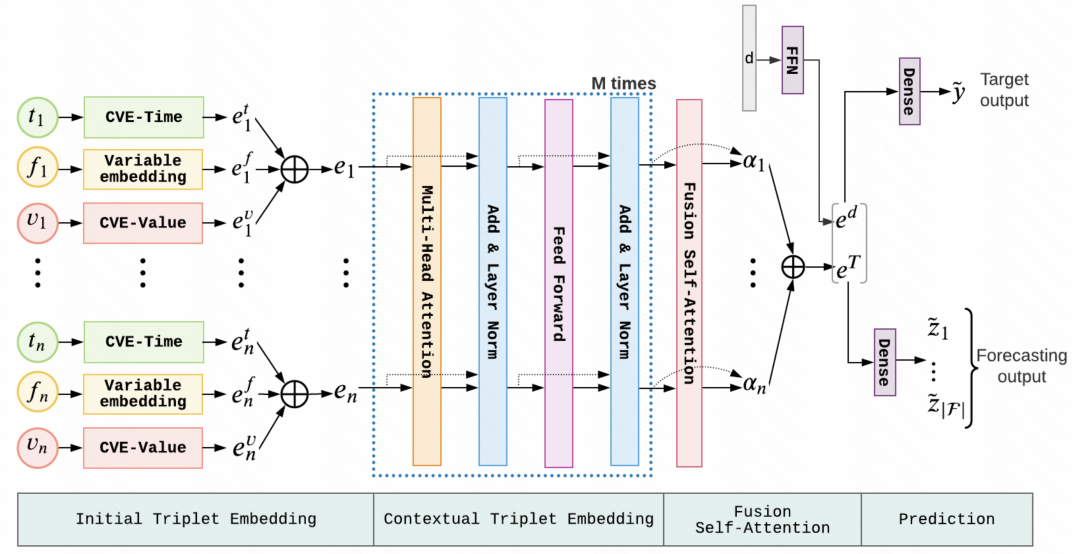 Nach Erhalt der Parameter vor dem Training kann sie direkt auf die nachgelagerte Feinabstimmungsaufgabe angewendet werden. Der gesamte Pretrain-Finetune-Prozess Wie unten gezeigt.
Nach Erhalt der Parameter vor dem Training kann sie direkt auf die nachgelagerte Feinabstimmungsaufgabe angewendet werden. Der gesamte Pretrain-Finetune-Prozess Wie unten gezeigt.
Bilder
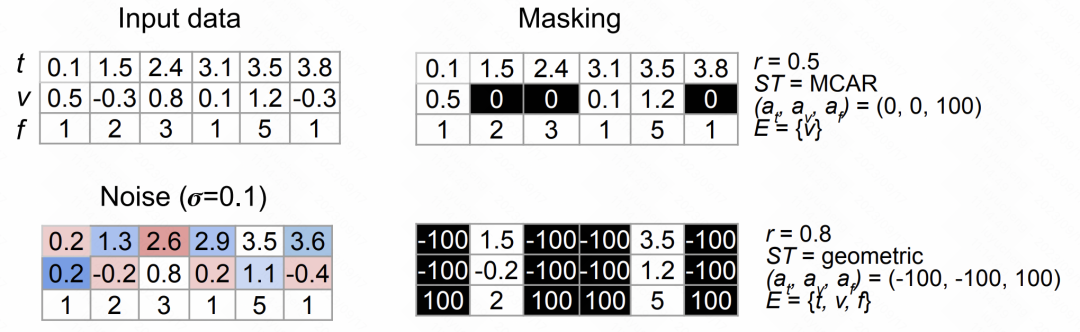
4. Design der DatenverbesserungsmethodeIn diesem Artikel schlagen wir zwei Datenverbesserungsmethoden vor. Die erste Methode besteht darin, Rauschen hinzuzufügen, indem zufällige Interferenzen in die Daten eingefügt werden, um die Vielfalt der Daten zu erhöhen. Die zweite Methode ist die Zufallsmaskierung, die das Modell dazu ermutigt, robustere Merkmale zu lernen, indem Teile der zu maskierenden Daten zufällig ausgewählt werden. Diese Datenverbesserungsmethoden können uns dabei helfen, die Leistung und Generalisierungsfähigkeit des Modells zu verbessernFür jeden Wert oder Zeitpunkt der Originalsequenz kann durch Hinzufügen von Gaußschem Rauschen Rauschen hinzugefügt werden. Die spezifische Berechnungsmethode ist wie folgt: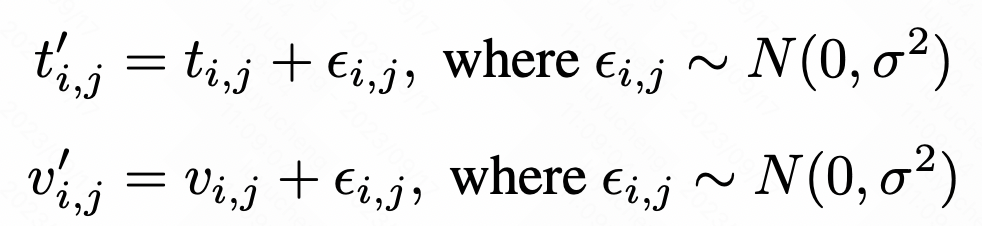 Bilder
Bilder
Die Methode der Zufallsmaske basiert auf Ideen aus dem NLP und erstellt eine erweiterte Zeitreihe durch zufällige Auswahl von Zeit, Merkmal, Wert und anderen Elementen für die zufällige Maskierung und Ersetzung.
Die folgende Abbildung zeigt die Wirkung der beiden oben genannten Arten von Datenverbesserungsmethoden:
 Bild
Bild
Darüber hinaus verwendet der Artikel verschiedene Kombinationen von Datenverbesserung, Vortrainingsmethoden usw. für verschiedene Zeitreihen Daten, aus diesen Kombinationen Suche nach der optimalen Vortrainingsmethode.
In diesem Artikel wurden Experimente mit mehreren Datensätzen durchgeführt, um die Auswirkungen verschiedener Vortrainingsmethoden auf diese Datensätze zu vergleichen. Es ist zu beobachten, dass die im Artikel vorgeschlagene Vortrainingsmethode bei den meisten Datensätzen eine deutliche Verbesserung erzielt hat
Das obige ist der detaillierte Inhalt vonGoogle: Neue Methode zum Erlernen der Zeitreihendarstellung mit ungleicher Frequenzabtastung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



