



Dies ist das Panorama von UG.
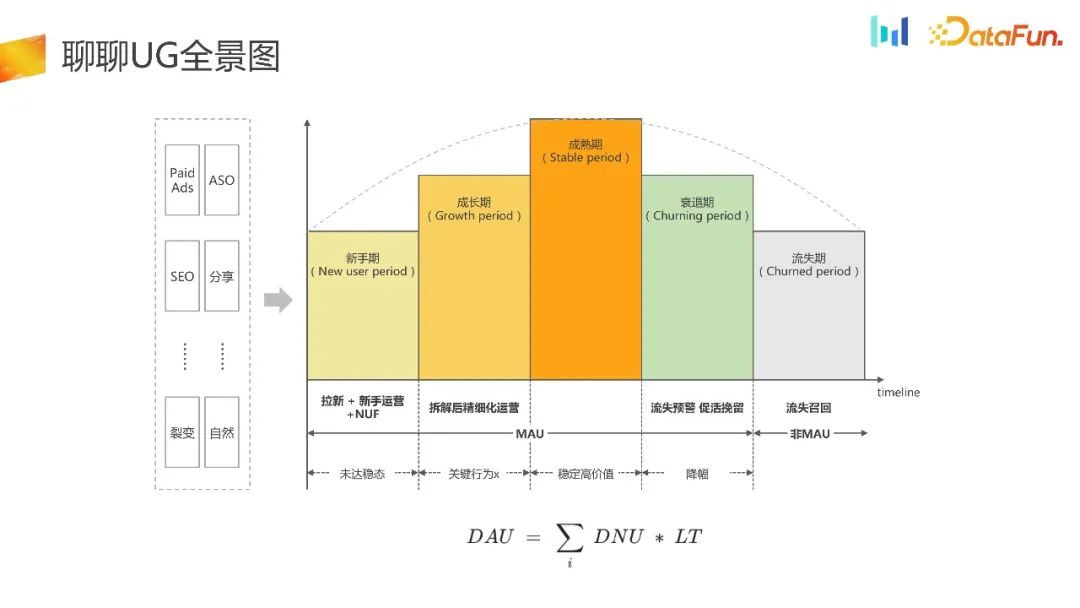
UG Gewinnen Sie Kunden und leiten Sie den Verkehr zur APP über Kanäle wie bezahlte Anzeigen, ASO, SEO und andere Kanäle weiter. Als nächstes werden wir einige Vorgänge und Anleitungen für Anfänger durchführen, um Benutzer zu aktivieren und sie in die Reifephase zu bringen. Nachfolgende Benutzer können langsam inaktiv werden, in eine Ablehnungsphase eintreten oder sogar in eine Abwanderungsphase eintreten. Während dieser Zeit führen wir einige Frühwarnungen bei Abwanderung, Rückrufe zur Förderung der Aktivierung und später einige Rückrufe für verlorene Benutzer durch.
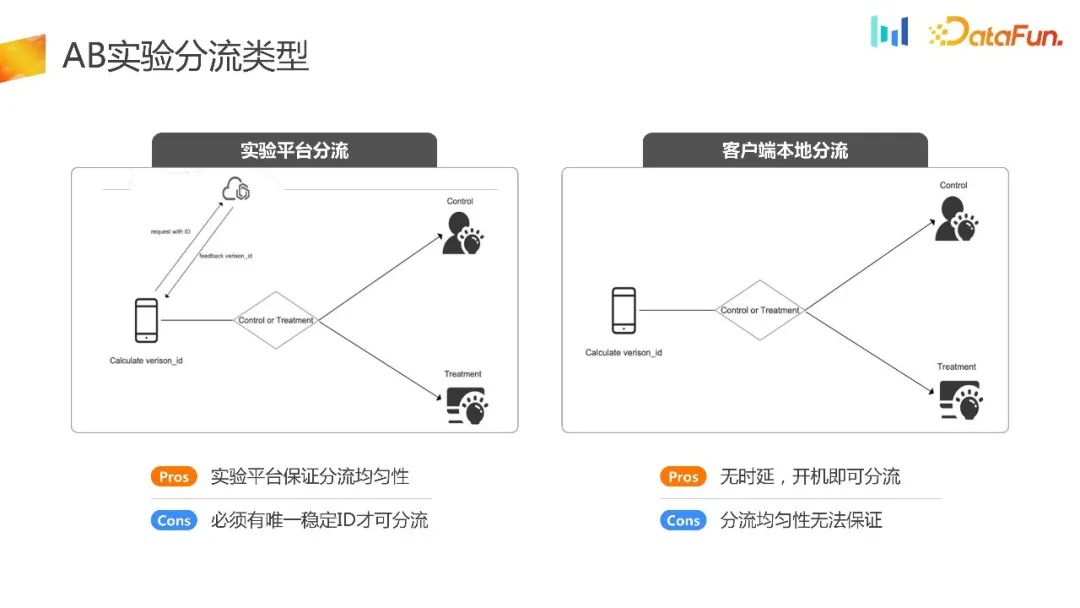
kann wie die Formel im Bild oben zusammengefasst werden, das heißt, DAU ist gleich DNU mal LT. Alle Arbeiten im UG-Szenario können nach dieser Formel demontiert werden. 2. Prinzip des AB-Experiments Schließlich werden wissenschaftliche Entscheidungen durch die Kombination statistischer Methoden und experimenteller Hypothesen getroffen, die den Rahmen des gesamten Experiments bilden. Derzeit sind die Arten der experimentellen Verteilung auf dem Markt grob in zwei Arten unterteilt: experimentelle Plattformverteilung und lokale Clientverteilung. Für die experimentelle Plattformverteilung ist es erforderlich, dass das Gerät nach der Initialisierung eine stabile ID erhalten kann Auf dieser Grundlage fordert die ID die experimentelle Plattform auf, die Offload-bezogene Logik abzuschließen, gibt die Offload-ID an das Terminal zurück und das Terminal führt dann entsprechende Strategien basierend auf der empfangenen ID aus. Sein Vorteil besteht darin, dass es über eine experimentelle Plattform verfügt, die die Gleichmäßigkeit und Stabilität des Shunts gewährleisten kann. Der Nachteil besteht darin, dass die Ausrüstung initialisiert werden muss, bevor experimentelles Rangieren durchgeführt werden kann.
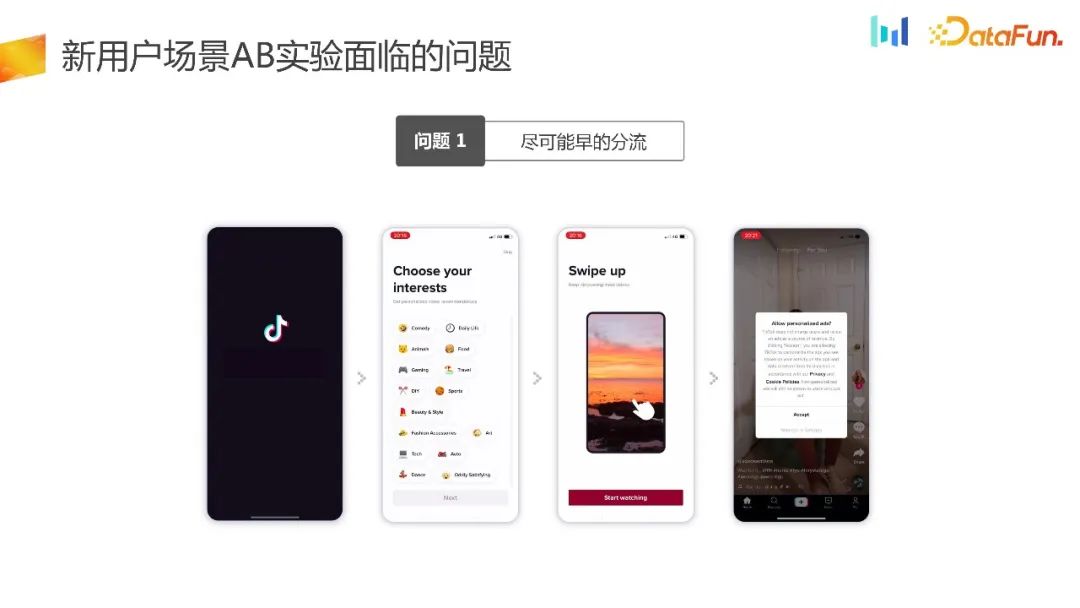
3. Probleme, mit denen das neue Benutzerszenario AB-Experiment konfrontiert ist 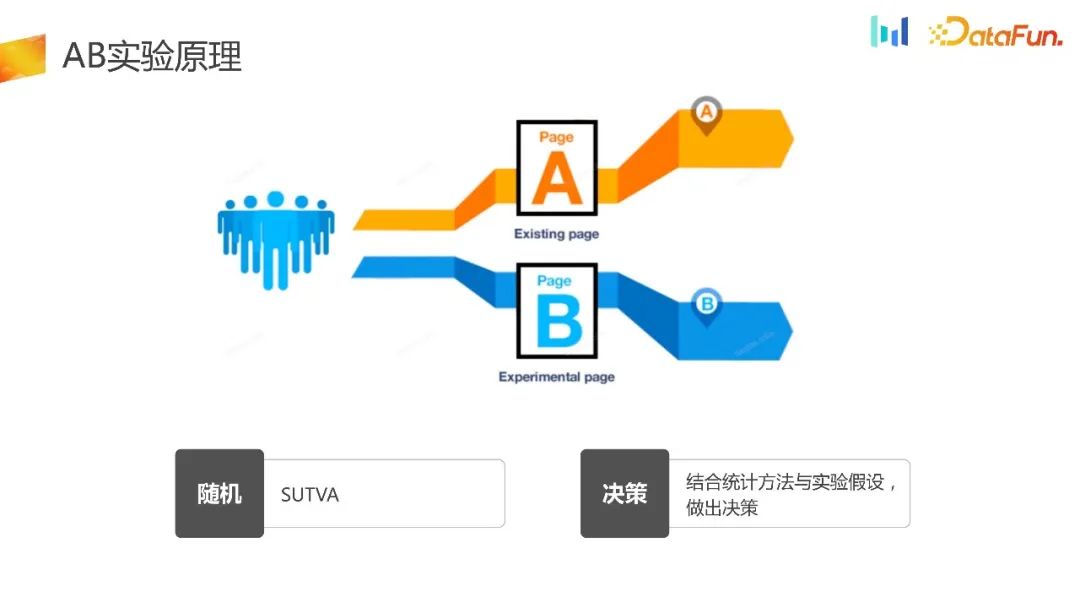
UG Das erste Problem, mit dem das Szenario tatsächlich konfrontiert ist, besteht darin, den Verkehr so früh wie möglich umzuleiten.
Hier ist ein Beispiel, wie zum Beispiel die Verkehrsakzeptanzseite hier. Der Produktmanager ist der Meinung, dass die Benutzeroberfläche optimiert werden kann, um die Kernindikatoren zu verbessern. In einem solchen Szenario hoffen wir, dass das Experiment so schnell wie möglich einer Triage unterzogen wird.
Während des Entladevorgangs auf Seite 1 wird das Gerät initialisiert und erhält die ID. 18,62 % der Benutzer können keine IDs generieren. Wenn die traditionelle experimentelle Plattformumleitungsmethode verwendet wird, werden 18,62 % der Benutzer nicht gruppiert, was zu einem inhärenten Auswahlverzerrungsproblem führt
Darüber hinaus ist der Datenverkehr neuer Benutzer sehr wertvoll, da 18,62 % der neuen Benutzer dies nicht können für Experimente verwendet werden, und es wird einen großen Verlust an der Dauer des Experiments und der Effizienz der Verkehrsnutzung geben.
Um das Problem der Auslagerung von Experimenten so früh wie möglich zu lösen, werden wir in Zukunft den Client verwenden, um Experimente lokal auszulagern. Der Vorteil besteht darin, dass die Entladung abgeschlossen ist, wenn das Gerät initialisiert wird. Das Prinzip besteht darin, dass das Terminal bei der Initialisierung zunächst selbst Zufallszahlen generieren, die Zufallszahlen hashen und sie dann auf die gleiche Weise gruppieren kann, wodurch eine experimentelle Gruppe und eine Kontrollgruppe generiert werden. Grundsätzlich sollte es möglich sein, eine gleichmäßige Verkehrsverteilung sicherzustellen, anhand des Datensatzes in der obigen Abbildung lässt sich jedoch feststellen, dass mehr als 21 % der Benutzer wiederholt in verschiedene Gruppen eintreten.
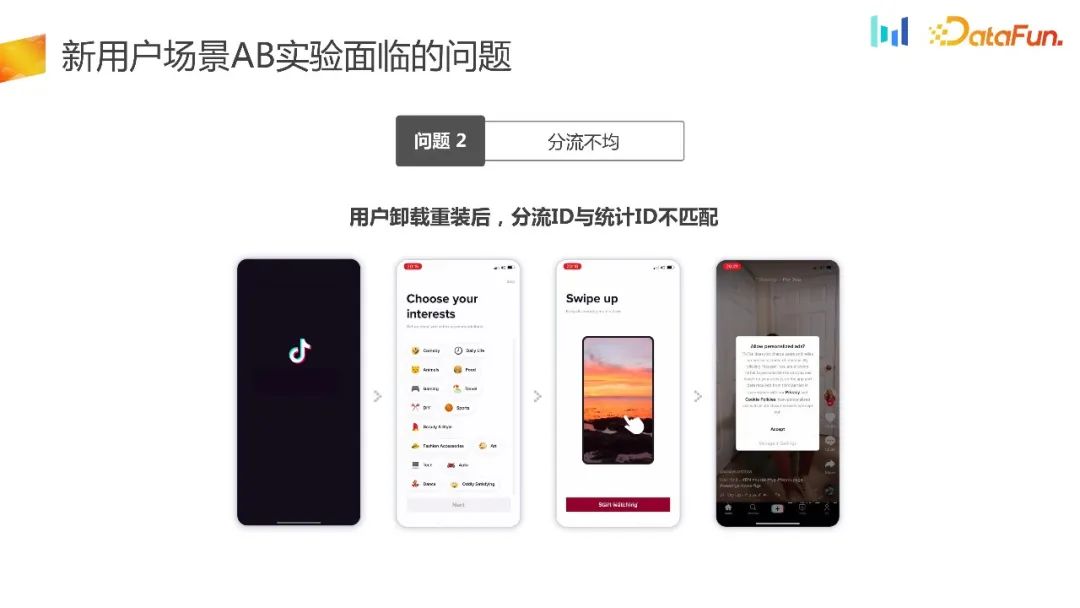
Es gibt ein Szenario, in dem Benutzer einiger sehr beliebter Produkte wie Honor of Kings oder Douyin leicht süchtig werden. Neue Benutzer werden während des Testzyklus mehrmals deinstallieren und neu installieren. Gemäß der gerade erwähnten Logik der lokalen Umleitung können Benutzer durch die Generierung und Umleitung von Zufallszahlen in verschiedene Gruppen eintreten, sodass die Umleitungs-ID und die statistische ID nicht eins zu eins übereinstimmen können. Dadurch entstand das Problem der ungleichmäßigen Verteilung.
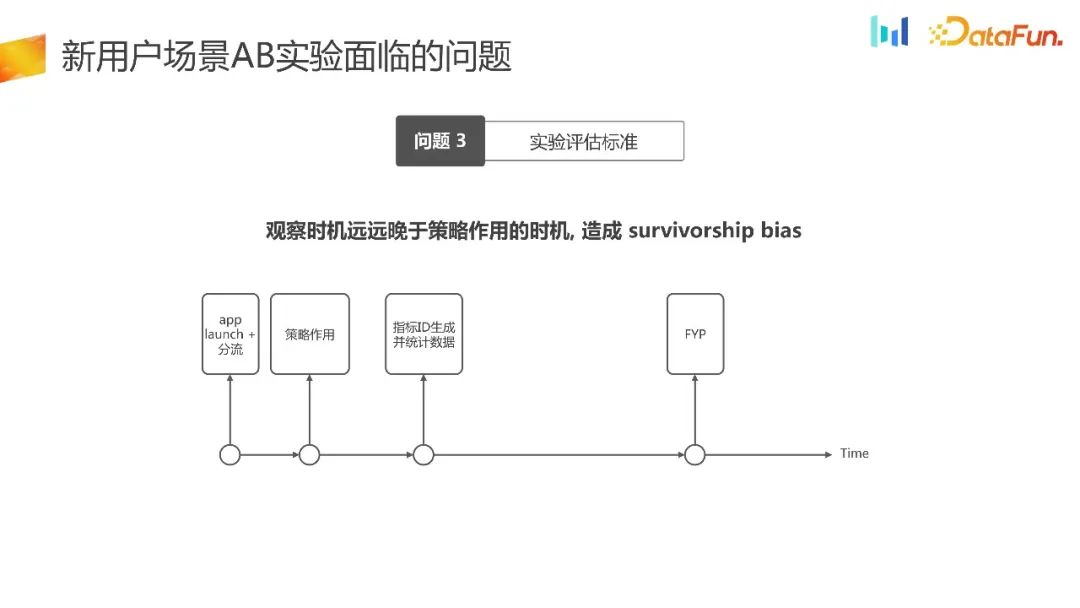
In neuen Benutzerszenarien stehen wir auch vor dem Problem experimenteller Bewertungsstandards.
Wir haben das Zeitdiagramm für den neuen Benutzerverkehr neu organisiert, der dieses Szenario übernimmt. Beim Start der Anwendung haben wir uns für die Auslagerung entschieden. Gehen Sie davon aus, dass wir einen einheitlichen Verteilungszeitpunkt erreichen und gleichzeitig entsprechende strategische Effekte erzielen können. Als nächstes liegt der Zeitpunkt der Generierung der statistischen Indikator-ID später als der Zeitpunkt des Strategieeffekts, und nur dann können die Daten beobachtet werden. Der Zeitpunkt der Datenbeobachtung liegt weit hinter dem Zeitpunkt der Strategieeffekte zurück, was zu einem Überlebensbias führen wird
Um die oben genannten Probleme zu lösen, haben wir ein neues experimentelles System vorgeschlagen System und wissenschaftlich verifiziert
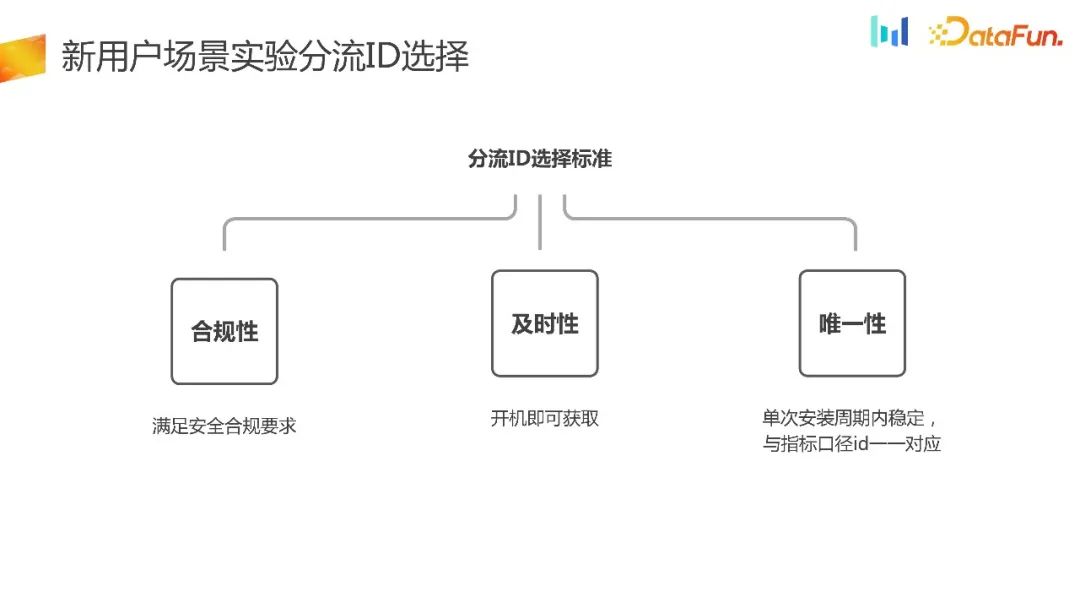
Wie bereits erwähnt, werden die Anforderungen an die Umleitungsauswahl für neue Benutzer relativ hoch sein. Wie wählt man also neue Benutzerexperimente aus? Shunt-ID? Im Folgenden sind einige Grundsätze aufgeführt:

Nach der Auswahl der Ablade-ID wird die Abladefähigkeit häufig auf zwei Arten abgeschlossen: Die erste erfolgt über die experimentelle Plattform und die zweite über das Ende.
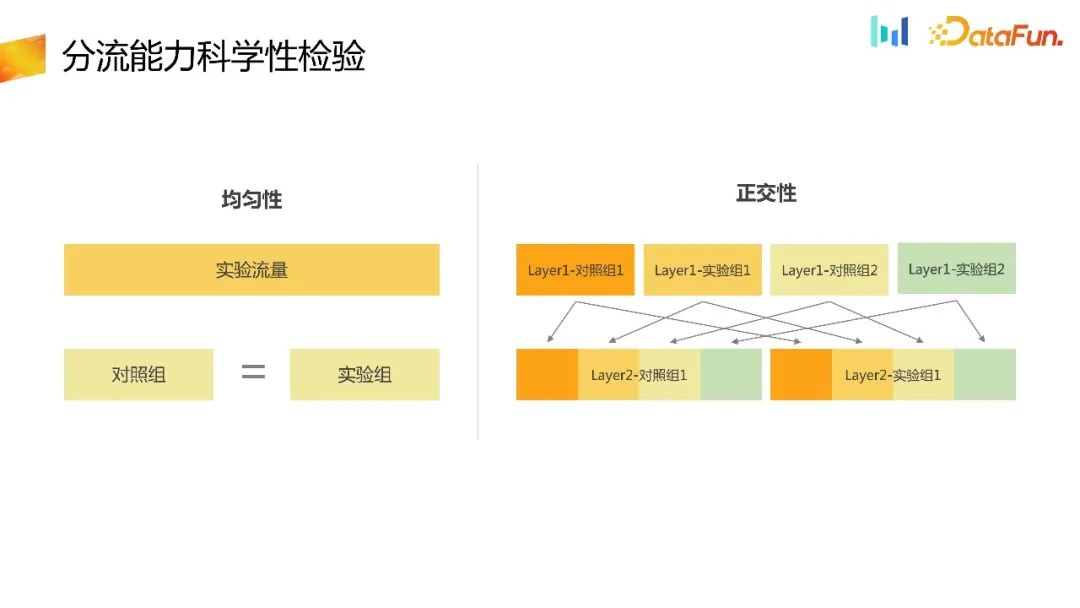
Nachdem Sie die Ablade-ID erhalten haben, geben Sie die Ablade-ID an die experimentelle Plattform weiter und schließen Sie die Abladefunktion auf der experimentellen Plattform ab. Als Vertriebsplattform ist es am grundlegendsten, ihre Zufälligkeit zu überprüfen. Das erste ist die Einheitlichkeit. In derselben Experimentebene wird der Datenverkehr gleichmäßig in viele Buckets aufgeteilt, und die Anzahl der Gruppen in jedem Bucket sollte gleichmäßig sein. Hier kann es vereinfacht werden: Wenn auf einer Ebene nur ein Experiment vorhanden ist und dieses in zwei Gruppen, a und b, unterteilt ist, sollte die Anzahl der Benutzer in der Kontrollgruppe und der experimentellen Gruppe ungefähr gleich sein, wodurch die Einheitlichkeit überprüft wird Umleitungsfähigkeit. Zweitens sollten Mehrschichtexperimente orthogonal zueinander und unbeeinflusst sein. Ebenso ist es notwendig, die Orthogonalität zwischen Experimenten auf verschiedenen Schichten zu überprüfen. Einheitlichkeit und Orthogonalität können durch statistische Kategorietests überprüft werden.
Nachdem wir die ID der Umleitungsauswahl und die Umleitungsfähigkeit eingeführt haben, müssen wir abschließend überprüfen, ob die neu vorgeschlagenen Umleitungsergebnisse den Anforderungen des AB-Experiments auf der Ebene der Indikatorergebnisse entsprechen.
Mithilfe der internen Plattform haben wir mehrere AA-Simulationen durchgeführt
, um zu vergleichen, ob die Kontrollgruppe und die Versuchsgruppe die experimentellen Anforderungen an die entsprechenden Indikatoren erfüllten. Schauen wir uns als Nächstes diesen Datensatz an.

Wir haben einige Indikatorgruppen des T-Tests untersucht. Es ist verständlich, dass die Fehlerrate vom Typ eins bei sehr geringer Wahrscheinlichkeit liegen sollte ,055, %, sein Konfidenzintervall sollte eigentlich etwa 1000 betragen, was zwischen 0,0365 und 0,0635 liegen sollte. Sie können sehen, dass einige der in der ersten Spalte abgetasteten Indikatoren innerhalb dieses Ausführungsbereichs liegen. Aus Sicht der Fehlerrate vom ersten Typ ist das vorhandene experimentelle System also in Ordnung.
Angesichts der Tatsache, dass es sich bei dem Test um einen Test der t-Statistik handelt, sollte die entsprechende t-Statistik in etwa der Normalverteilung unter der Verteilung des großen Verkehrs entsprechen. Sie können auch die Normalverteilung der T-Test-Statistiken testen. Hier wird der Normalverteilungstest verwendet, und Sie können sehen, dass das Testergebnis auch viel größer als 0,05 ist, d.
Für jeden Test ist der p-Wert des t-Statistik-Testergebnisses in so vielen Experimenten ungefähr gleichmäßig verteilt. Gleichzeitig kann der p-Wert auch auf Gleichverteilung getestet werden, pvalue_uniform_test, oder ähnliche Ergebnisse sehen viel größer als 0,05. Daher ist auch die Nullhypothese, dass der p-Wert annähernd einer Gleichverteilung folgt, in Ordnung.
Die obige Eins-zu-eins-Entsprechung zwischen der Umleitungs-ID und dem Indexberechnungskaliber, der Umleitungskapazität und den Ergebnissen des Umleitungsergebnisindikators hat den wissenschaftlichen Charakter des neu vorgeschlagenen experimentellen Umleitungssystems bestätigt. 3. Analyse von Anwendungsfällen Bewertung
Wenn man den Prozess vom Herunterladen neuer Benutzer über die Installation bis zum ersten Start annimmt, ist der PM der Ansicht, dass ein solcher Prozess für Benutzer zu hoch ist, insbesondere für diejenigen, die noch nie Erfahrung mit der Produktnutzung haben Machen Sie sich mit dem Produkt vertraut, erleben Sie den Hip-Hop-Moment des Produkts und leiten Sie sie dann zum Anmelden an. 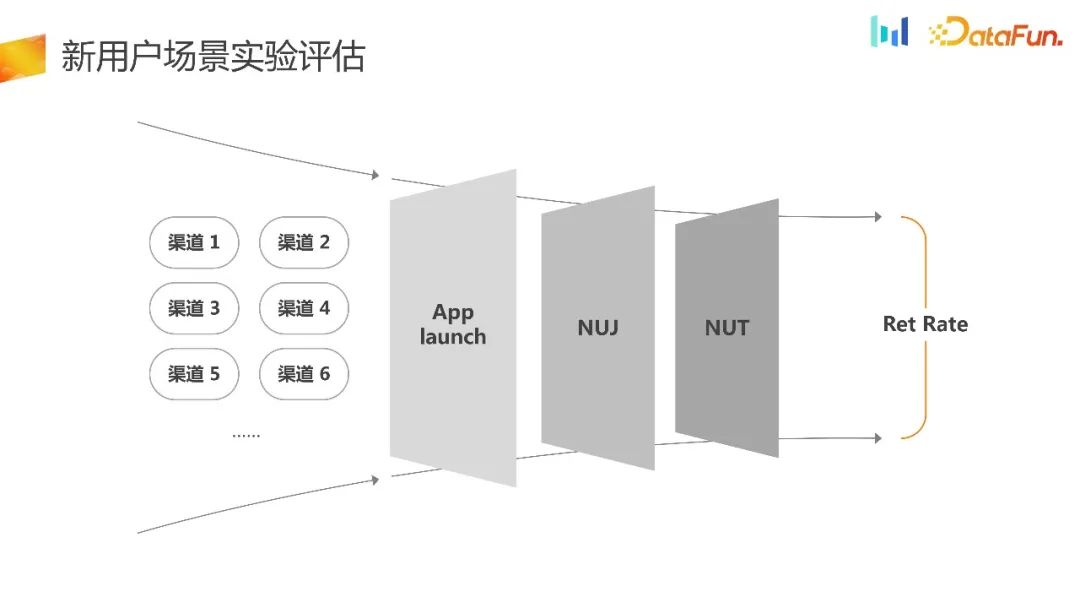
Darüber hinaus schlug der Produktmanager eine weitere Hypothese vor, die darin besteht, den Widerstand bei der Anmeldung neuer Benutzer oder NUJ-Szenarien neuer Benutzer für Benutzer zu verringern, die das Produkt noch nie erlebt haben. Für Benutzer, die das Produkt bereits kennengelernt haben, und Benutzer, die das Gerät gewechselt haben, wird weiterhin der Online-Prozess verwendet. Die Umleitungsmethode basierend auf der Indikator-ID erhält zunächst die ID des Indikators und führt dann die Umleitung durch. Diese Aufteilungsmethode ist normalerweise einheitlich und unterscheidet sich kaum von den experimentellen Ergebnissen und der Retentionsrate. Angesichts solcher Ergebnisse ist es schwierig, eine umfassende Entscheidung zu treffen. Diese Art von Experiment verschwendet tatsächlich einen Teil des Datenverkehrs und bringt das Problem der Selektionsverzerrung mit sich. Daher werden wir ein lokales Offload-Experiment durchführen. Die folgende Abbildung zeigt die Ergebnisse des lokalen Offload-Experiments. Es wird einen signifikanten Unterschied in der Anzahl der neuen Geräte geben, die der Gruppe hinzugefügt werden. Gleichzeitig gibt es eine Verbesserung der Bindungsrate, die jedoch bei anderen Kernindikatoren tatsächlich negativ ist, und diese negative Richtung ist schwer zu verstehen, da sie tatsächlich stark mit der Bindung zusammenhängt. Daher ist es schwierig, sie auf der Grundlage solcher Daten zu erklären oder zuzuordnen, und es ist auch schwierig, umfassende Entscheidungen zu treffen. 
Sie können die Situation von Benutzern beobachten, die wiederholt Gruppen beigetreten sind, und Sie werden feststellen, dass mehr als 20 % der Benutzer wiederholt verschiedenen Gruppen zugeordnet werden. Dadurch wird die Zufälligkeit des AB-Experiments zerstört und es wird schwierig, wissenschaftliche Vergleichsentscheidungen zu treffen
Schauen Sie sich abschließend die Ergebnisse der Experimente mit dem vorgeschlagenen neuen Shunt an.
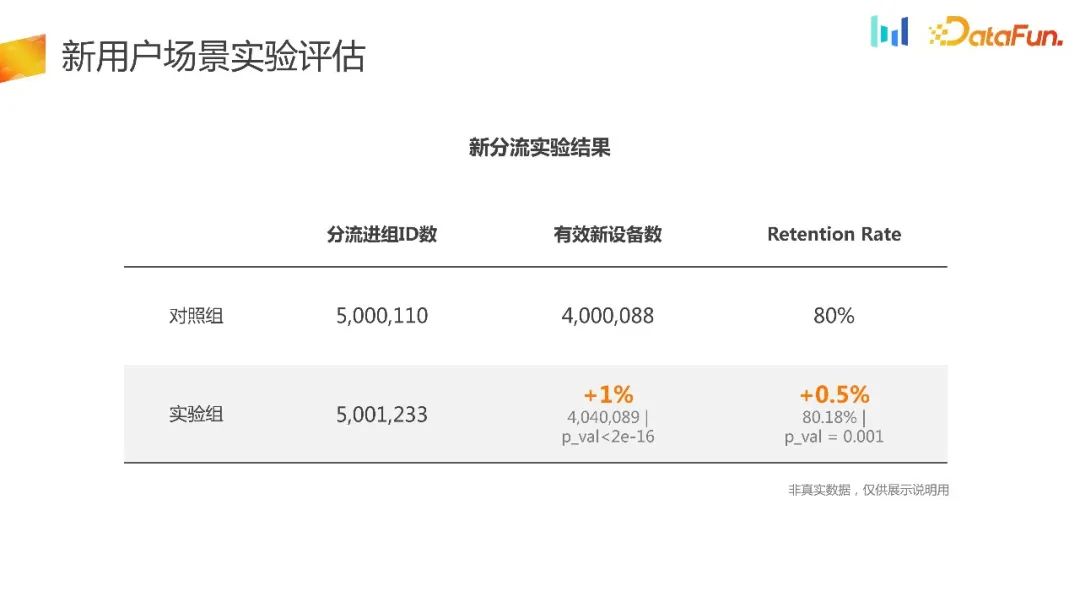
Es kann umgeleitet werden, wenn es eingeschaltet ist. Die Umleitungskapazität wird durch die interne Plattform gewährleistet, die die Gleichmäßigkeit und Stabilität der Umleitung weitgehend gewährleisten kann. Den experimentellen Daten nach zu urteilen, ist es fast nah dran. Beim Quadratwurzeltest können wir auch sehen, dass es die Anforderungen vollständig erfüllt. Gleichzeitig können wir feststellen, dass die Anzahl effektiver Neugeräte deutlich um 1 % gestiegen ist und sich auch die Bindungsrate verbessert hat. Wenn Sie sich gleichzeitig die Kontrollgruppe oder die Experimentalgruppe allein ansehen, können Sie sehen, dass die Traffic-Conversion-Rate basierend auf der Umleitungs-ID zum neuen Gerät letztendlich generiert wurde. Die Experimentalgruppe ist 1 % höher als die Kontrollgruppe. Der Grund für dieses Ergebnis liegt darin, dass die Versuchsgruppe tatsächlich den Einstiegspunkt des Benutzers in NUJ und NUT vergrößert hat, was es für mehr Benutzer einfacher macht, einzusteigen, das Produkt zu erleben und dann zu bleiben.
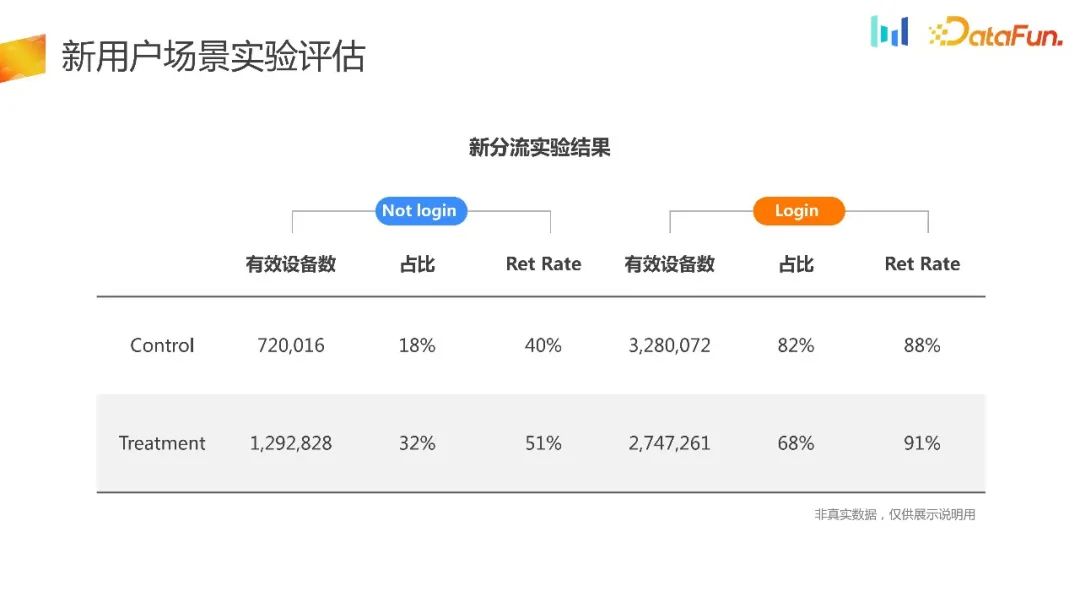
Unterteilen Sie die experimentellen Daten in Login- und Nicht-Login-Teile. Es zeigt sich, dass für Benutzer in der Experimentalgruppe mehr Benutzer den Nicht-Login-Modus wählen, um das Produkt zu erleben, und die Aufbewahrungsrate hat sich ebenfalls erhöht Die Ergebnisse entsprechen auch den Erwartungen
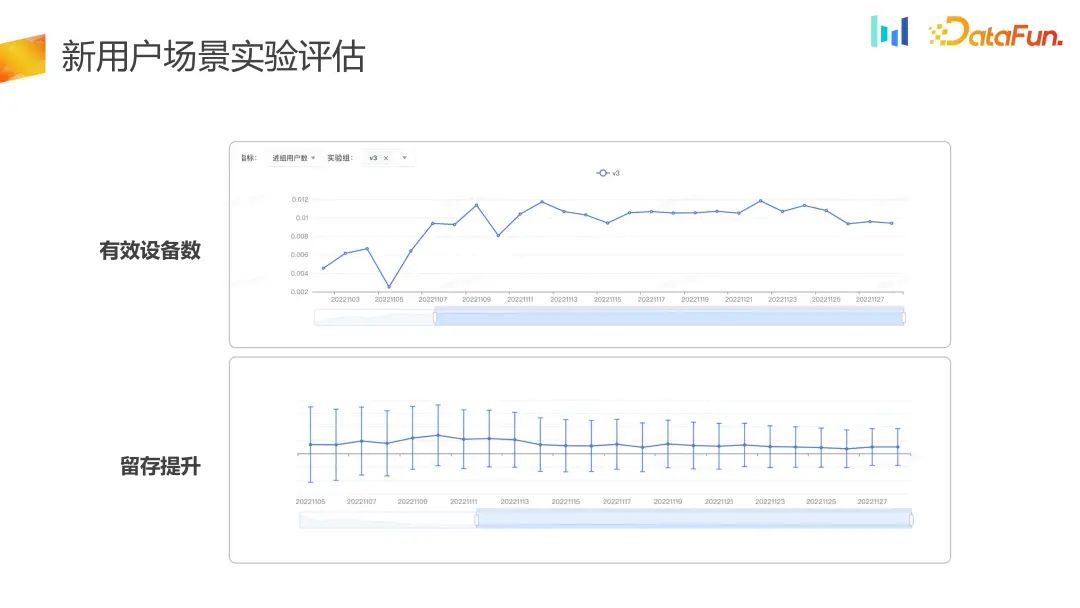
Die Anzahl der Benutzer, die der Gruppe beitreten, wird tatsächlich über einen langen Zeitraum geschrieben steigt stetig und auch der Retention-Indikator hat sich verbessert. Im Vergleich zur Kontrollgruppe hat sich die Anzahl der wirksamen Geräte und die Retention der Versuchsgruppe verbessert.
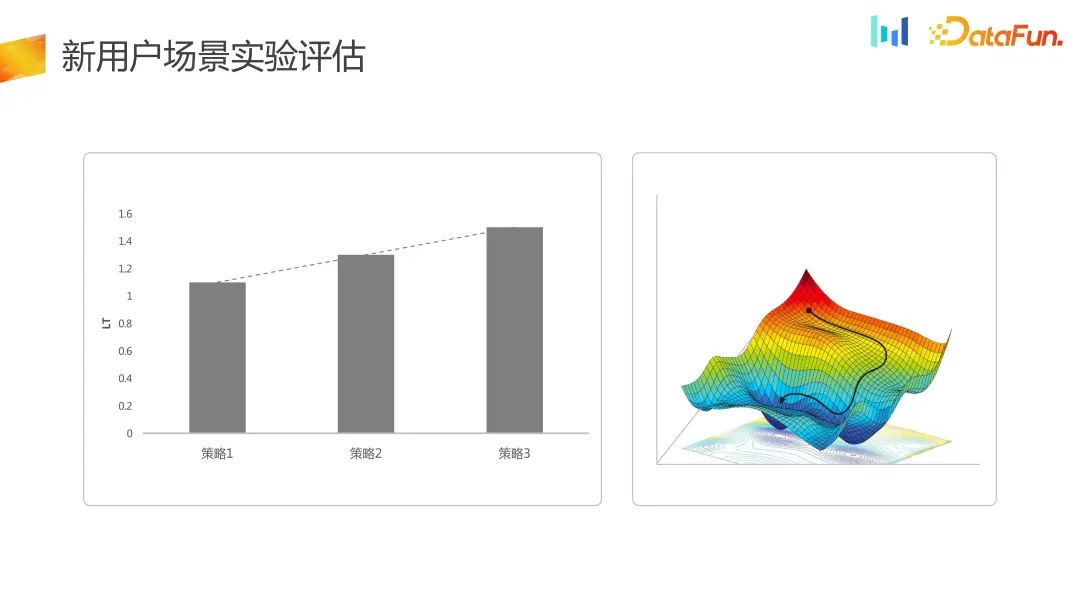
Für das Szenario der Akzeptanz des neuen Benutzerverkehrs werden die Bewertungsindikatoren eher anhand der Retention- oder kurzfristigen LT-Dimension bewertet. Hier wird die Optimierung tatsächlich nur im eindimensionalen Raum auf der LT-Ebene durchgeführt
Im neuen experimentellen System wird die eindimensionale Optimierung in eine zweidimensionale Optimierung umgewandelt, und die gesamte DNU Shenshang LT wurde erstellt verbessert, also Der Strategieraum hat sich von der vorherigen eindimensionalen in eine zweidimensionale geändert, und gleichzeitig kann in einigen Szenarien der Verlust eines Teils von LT akzeptiert werden.
Lassen Sie uns abschließend die experimentellen Fähigkeitsaufbau- und experimentellen Bewertungsstandards in neuen Benutzerszenarien zusammenfassen.
Das obige ist der detaillierte Inhalt vonWie baut man ein AB-Experimentiersystem in Benutzerwachstumsszenarien auf?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Algorithmus zum Ersetzen von Seiten
Algorithmus zum Ersetzen von Seiten
 Beliebte Fernverbindungssoftware
Beliebte Fernverbindungssoftware
 Einführung in Screenshot-Tastenkombinationen im Windows 7-System
Einführung in Screenshot-Tastenkombinationen im Windows 7-System
 Grenzradius
Grenzradius
 CAD-Zeilenbruchbefehl
CAD-Zeilenbruchbefehl
 So stellen Sie Chinesisch in vscode ein
So stellen Sie Chinesisch in vscode ein
 Die Direct3D-Funktion ist nicht verfügbar
Die Direct3D-Funktion ist nicht verfügbar
 Lösung dafür, dass Google Chrome nicht funktioniert
Lösung dafür, dass Google Chrome nicht funktioniert












