


Die automatische Zusammenfassungstechnologie hat in den letzten Jahren große Fortschritte gemacht, hauptsächlich aufgrund des Paradigmenwechsels – von der überwachten Feinabstimmung an gekennzeichneten Datensätzen hin zur Verwendung großer Sprachmodelle (LLM) für Zero-Shot-Hinweise, wie z. B. GPT-4. Sorgfältig gestaltete Eingabeaufforderungen ermöglichen eine genaue Kontrolle über Länge, Thema, Stil und andere Funktionen der Zusammenfassung ohne zusätzliche Schulung
Aber ein Aspekt wird oft übersehen: die Informationsdichte der Zusammenfassung. Theoretisch sollte eine Zusammenfassung als Komprimierung eines anderen Textes dichter sein, also mehr Informationen enthalten als die Quelldatei. Angesichts der hohen Latenz der LLM-Dekodierung ist es wichtig, mehr Informationen mit weniger Wörtern abzudecken, insbesondere für Echtzeitanwendungen.
Die Informationsdichte ist jedoch eine offene Frage: Wenn die Zusammenfassung nicht genügend Details enthält, ist sie gleichbedeutend mit keiner Information; wenn sie zu viele Informationen enthält, ohne die Gesamtlänge zu erhöhen, wird sie schwer zu verstehen. Um innerhalb eines festen Wortschatzbudgets mehr Informationen zu vermitteln, müssen Sie Abstraktion, Komprimierung und Fusion kombinieren dichtere Zusammenfassungen, die von GPT-4 generiert werden. Diese Methode bietet viele Inspirationen für die Verbesserung der „Ausdrucksfähigkeit“ großer Sprachmodelle wie GPT-4.
Papierlink: https://arxiv.org/pdf/2309.04269.pdf
Datensatzadresse: https://huggingface.co/datasets/griffin/chain_of_density
Spezifische Details sagen Ihr Ansatz verwendet die durchschnittliche Anzahl von Entitäten pro Tag als Proxy für die Dichte und generiert so eine anfängliche Zusammenfassung mit geringer Entitätsdichte. Anschließend werden, ohne die Gesamtlänge zu erhöhen (die Gesamtlänge beträgt das Fünffache der ursprünglichen Zusammenfassung), iterativ 1–3 in der vorherigen Zusammenfassung fehlende Entitäten identifiziert und zusammengeführt, sodass das Verhältnis von Entitäten zu Tags in jeder Zusammenfassung höher ist als in der vorherigen Zusammenfassung. Durch die Analyse menschlicher Präferenzdaten identifizierten die Autoren schließlich eine Form der Zusammenfassung, die fast so dicht ist wie von Menschen geschriebene Zusammenfassungen und dichter als Zusammenfassungen, die durch gewöhnliche GPT-4-Eingabeaufforderungen generiert werden
Die Gesamtbeiträge der Studie umfassen:
Entwickeln Sie eine iterative prompt-basierte Methode (CoD), die die Entitätsdichte von Zusammenfassungen immer höher macht;
Was ist CoD?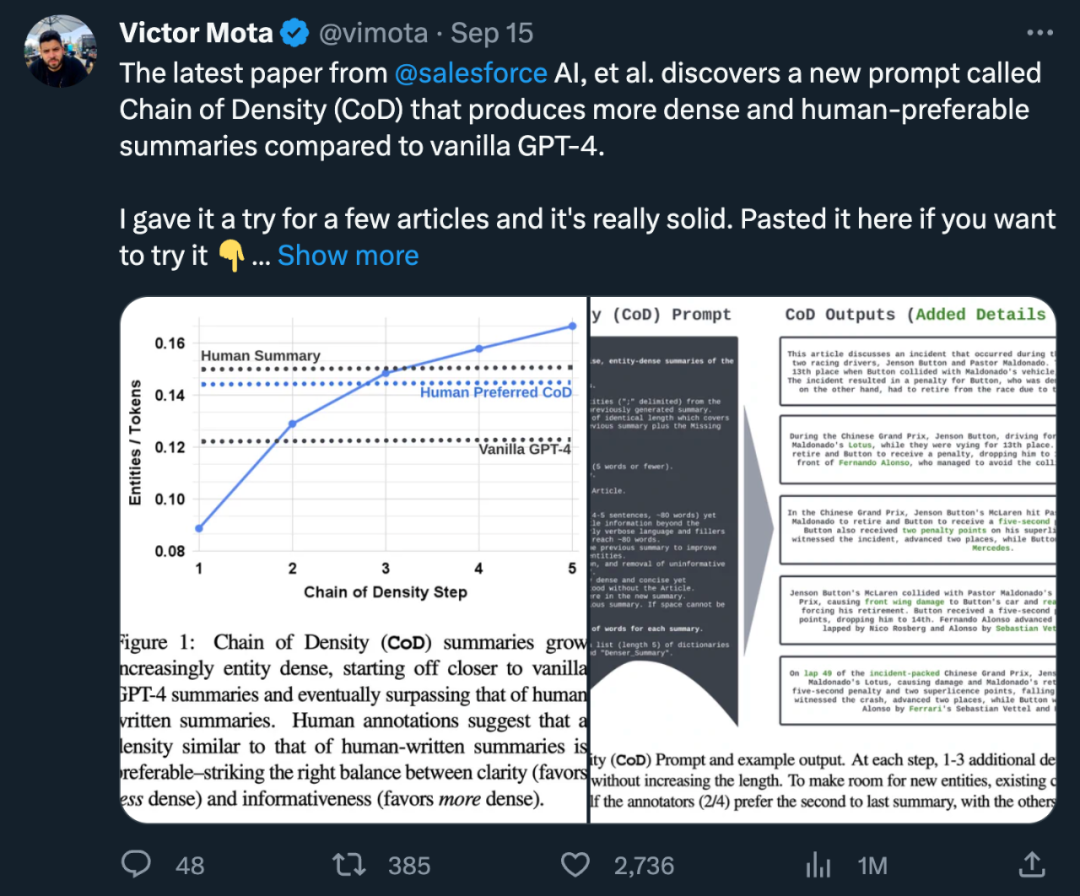
Verwandt: bezogen auf die Hauptgeschichte
Spezifisch: beschreibend, aber prägnant (5 Wörter oder weniger);
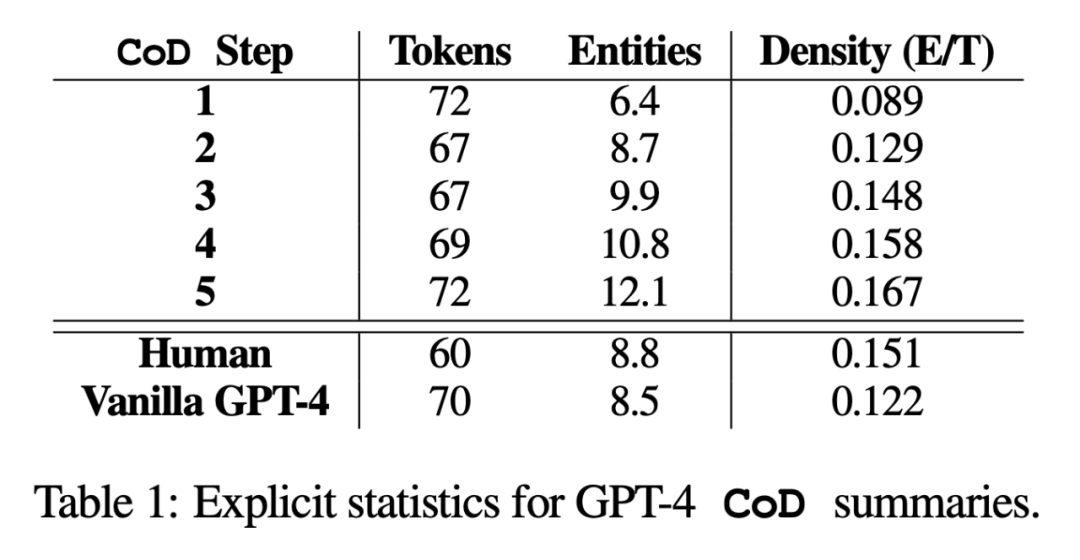
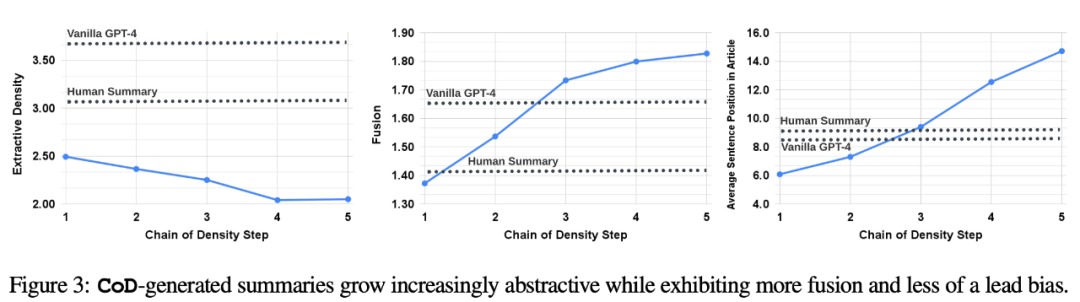
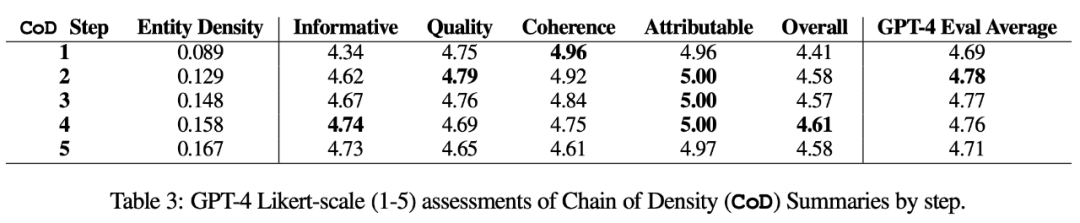
In der Studie fasste der Autor zwei Aspekte zusammen: direkte Statistik und indirekte Statistik. Direkte Statistiken (Tokens, Entitäten, Entitätsdichte) werden direkt von CoD gesteuert, während indirekte Statistiken ein erwartetes Nebenprodukt der Verdichtung sind. Der umgeschriebene Inhalt sieht wie folgt aus: Laut Statistik wurde durch das Entfernen unnötiger Wörter in langen Zusammenfassungen die durchschnittliche Länge des zweiten Schritts um 5 Token reduziert (von 72 auf 67). Die anfängliche Entitätsdichte beträgt 0,089, was niedriger ist als bei menschlichem und Vanille-GPT-4 (0,151 und 0,122), und nach 5 Verdichtungsschritten steigt sie schließlich auf 0,167 indirekte Statistik. Der Abstraktionsgrad sollte mit jedem CoD-Schritt steigen, da die Zusammenfassung immer wieder neu geschrieben wird, um Platz für jede zusätzliche Entität zu schaffen. Die Autoren messen die Abstraktion anhand der Extraktionsdichte: der durchschnittlichen Quadratlänge extrahierter Fragmente (Grusky et al., 2018). Ebenso sollte die Konzeptfusion monoton zunehmen, wenn Entitäten zu einer Zusammenfassung fester Länge hinzugefügt werden. Die Autoren drückten den Grad der Integration durch die durchschnittliche Anzahl der Quellsätze aus, die mit jedem zusammenfassenden Satz abgeglichen wurden. Zur Ausrichtung verwenden die Autoren die Methode der relativen ROUGE-Verstärkung (Zhou et al., 2018), die den Quellsatz so lange am Zielsatz ausrichtet, bis die relative ROUGE-Verstärkung der zusätzlichen Sätze nicht mehr positiv ist. Sie erwarteten auch Änderungen in der Inhaltsverteilung oder der Position innerhalb des Artikels, aus dem der zusammenfassende Inhalt stammt. Konkret gehen die Autoren davon aus, dass die Zusammenfassungen von Call of Duty (CoD) zunächst einen starken „Bootstrapping-Bias“ aufweisen werden, d. h. am Anfang des Artikels werden weitere Entitäten vorgestellt. Mit der Weiterentwicklung des Artikels schwächt sich dieser Leitgedanke jedoch allmählich ab, und in der Mitte und am Ende des Artikels werden Entitäten eingeführt. Um dies zu messen, haben wir die Alignment-Ergebnisse in der Fusion verwendet und den durchschnittlichen Satzrang aller ausgerichteten Quellsätze gemessen Abbildung 3 bestätigt diese Hypothesen: Mit zunehmenden Umschreibungsschritten nimmt auch die Abstraktheit zu Extraktionsdichte links), erhöht sich die Fusionsrate (mittleres Bild) und die Zusammenfassung beginnt, Inhalte aus der Mitte und dem Ende des Artikels zu integrieren (rechtes Bild). Interessanterweise waren alle CoD-Zusammenfassungen abstrakter im Vergleich zu von Menschen verfassten Zusammenfassungen und Baseline-Zusammenfassungen Bewertungsbasierte Bewertung mit GPT-4 Basierend auf der durchschnittlichen Dichte der Schritt-3-Zusammenfassung kann grob gefolgert werden, dass die bevorzugte Entitätsdichte aller CoD-Kandidaten ∼ 0,15 beträgt. Wie in Tabelle 1 zu sehen ist, stimmt diese Dichte mit von Menschen verfassten Zusammenfassungen überein (0,151), ist jedoch deutlich höher als mit Zusammenfassungen, die mit gewöhnlichen GPT-4-Eingabeaufforderungen verfasst wurden (0,122). Automatische Messung. Als Ergänzung zur menschlichen Bewertung (unten) verwendeten die Autoren GPT-4, um CoD-Zusammenfassungen (1–5 Punkte) in fünf Dimensionen zu bewerten: Informativität, Qualität, Kohärenz, Zuordenbarkeit und Gesamtheit. Wie in Tabelle 3 gezeigt, korreliert die Dichte mit der Aussagekraft, allerdings bis zu einem gewissen Grad, wobei die Punktzahl bei Stufe 4 (4,74) ihren Höhepunkt erreicht. Von den Durchschnittswerten jeder Dimension weisen der erste und der letzte Schritt von CoD die niedrigsten Werte auf, während die mittleren drei Schritte nahe beieinander liegende Werte aufweisen (4,78, 4,77 bzw. 4,76). Qualitative Analyse. Es besteht ein klarer Kompromiss zwischen Kohärenz/Lesbarkeit und Informationsgehalt der Zusammenfassung. Abbildung 4 zeigt zwei CoD-Schritte: Die Zusammenfassung eines Schritts wird durch mehr Details verbessert, während die Zusammenfassung des anderen Schritts beeinträchtigt wird. Insgesamt ist die CoD-Zwischenzusammenfassung in der Lage, dieses Gleichgewicht zu erreichen, dieser Kompromiss muss jedoch in zukünftigen Arbeiten noch genau definiert und quantifiziert werden Weitere Einzelheiten zum Papier finden Sie im Originalpapier. 
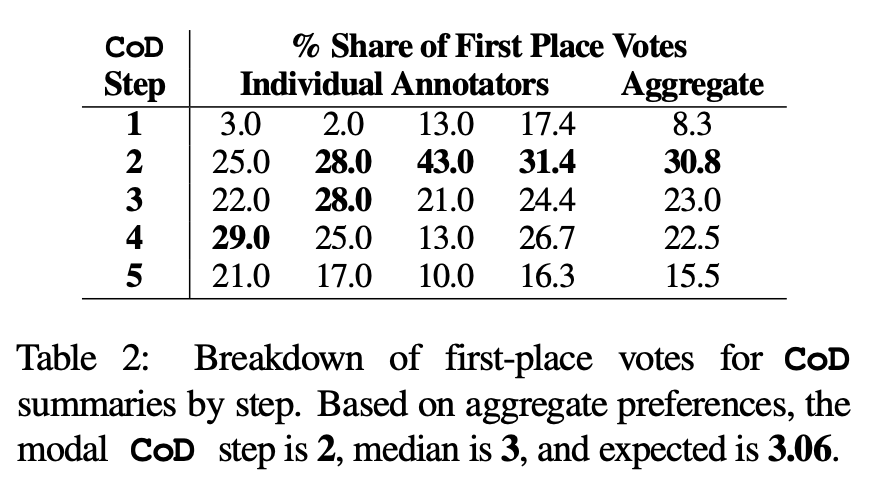
 Menschliche Vorlieben. Konkret zeigte der Autor für dieselben 100 Artikel (5 Schritte * 100 = insgesamt 500 Abstracts) die „neu erstellten“ CoD-Abstracts und Artikel nach dem Zufallsprinzip den ersten vier Autoren des Papiers. Jeder Kommentator gab seine Lieblingszusammenfassung basierend auf der Definition einer „guten Zusammenfassung“ von Stiennon et al. (2020) ab. In Tabelle 2 sind die Erstplatzierungen jedes Annotators in der CoD-Phase sowie die Zusammenfassung jedes Annotators aufgeführt. Insgesamt umfassten 61 % der Abstracts mit dem ersten Platz (23,0+22,5+15,5) ≥3 Verdichtungsschritte. Die mittlere Anzahl der bevorzugten CoD-Schritte liegt im Mittelfeld (3), mit einer erwarteten Schrittzahl von 3,06.
Menschliche Vorlieben. Konkret zeigte der Autor für dieselben 100 Artikel (5 Schritte * 100 = insgesamt 500 Abstracts) die „neu erstellten“ CoD-Abstracts und Artikel nach dem Zufallsprinzip den ersten vier Autoren des Papiers. Jeder Kommentator gab seine Lieblingszusammenfassung basierend auf der Definition einer „guten Zusammenfassung“ von Stiennon et al. (2020) ab. In Tabelle 2 sind die Erstplatzierungen jedes Annotators in der CoD-Phase sowie die Zusammenfassung jedes Annotators aufgeführt. Insgesamt umfassten 61 % der Abstracts mit dem ersten Platz (23,0+22,5+15,5) ≥3 Verdichtungsschritte. Die mittlere Anzahl der bevorzugten CoD-Schritte liegt im Mittelfeld (3), mit einer erwarteten Schrittzahl von 3,06.

Das obige ist der detaillierte Inhalt von„Wenige Wörter, große Menge an Informationen', lehren Salesforce- und MIT-Forscher die „Revision' von GPT-4, der Datensatz war Open Source. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So binden Sie Daten in einer Dropdown-Liste
So binden Sie Daten in einer Dropdown-Liste
 Über welche Caching-Mechanismen verfügt PHP?
Über welche Caching-Mechanismen verfügt PHP?
 Was ist der Grund für einen Fehler bei der DNS-Auflösung?
Was ist der Grund für einen Fehler bei der DNS-Auflösung?
 So beschleunigen Sie Webseiten
So beschleunigen Sie Webseiten
 So aktivieren Sie Computerfenster
So aktivieren Sie Computerfenster
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Prioritätsreihenfolge der Operatoren in der Sprache C
Prioritätsreihenfolge der Operatoren in der Sprache C
 So öffnen Sie eine DB-Datei
So öffnen Sie eine DB-Datei








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



