


Daten als einer der drei Hauptfaktoren, die die Leistung von Modellen für maschinelles Lernen bestimmen, werden zu einem Engpass, der die Entwicklung großer Modelle einschränkt. Wie das Sprichwort sagt: „Müll rein, Müll raus“ [1]: Unabhängig davon, wie gut Ihr Algorithmus ist und wie leistungsfähig Ihre Rechenressourcen sind, hängt die Qualität des Modells direkt von den Daten ab, die Sie zum Trainieren des Modells verwenden.
Mit dem Aufkommen verschiedener großer Open-Source-Modelle wird die Bedeutung von Daten, insbesondere von hochwertigen Branchendaten, noch stärker hervorgehoben. Bloomberg erstellt ein großes Finanzmodell BloombergGPT basierend auf dem Open-Source-GPT-3-Framework, das die Machbarkeit der Entwicklung großer Modelle für vertikale Branchen auf der Grundlage des Open-Source-Frameworks für große Modelle beweist. Tatsächlich ist die Entwicklung oder Anpassung von Closed-Source-Leichtbau-Großmodellen für vertikale Industrien der von den meisten großen Modell-Startups in China gewählte Weg.
In diesem Bereich sind hochwertige vertikale Branchendaten, Feinabstimmungs- und Ausrichtungsmöglichkeiten auf der Grundlage von Fachwissen von entscheidender Bedeutung – BloombergGPT basiert auf den von Bloomberg seit mehr als 40 Jahren gesammelten Finanzdokumenten, und der Schulungskorpus umfasst mehr als 700 Milliarden Token[2 ].
Allerdings ist es nicht einfach, qualitativ hochwertige Daten zu erhalten. Einige Studien haben darauf hingewiesen, dass bei der derzeitigen Geschwindigkeit, mit der große Modelle Daten verschlingen, hochwertige gemeinfreie Sprachdaten wie Bücher, Nachrichtenberichte, wissenschaftliche Arbeiten, Wikipedia usw. um das Jahr 2026 erschöpft sein werden [3].
Es gibt relativ wenige öffentlich zugängliche hochwertige chinesische Datenressourcen, und inländische professionelle Datendienste stecken noch in den Kinderschuhen. Die Datenerfassung, -bereinigung, -kennzeichnung und -überprüfung erfordert viel Personal und materielle Ressourcen. Es wird berichtet, dass die Kosten für das Sammeln und Bereinigen von 3 TB hochwertiger chinesischer Daten für ein großes Modellteam einer inländischen Universität einschließlich des Herunterladens von Datenbandbreite, Datenspeicherressourcen (ungebereinigte Originaldaten betragen etwa 100 TB) und CPU-Ressourcenkosten für die Bereinigung anfallen Die Daten belaufen sich auf etwa Hunderttausende Yuan.
Da die Entwicklung großer Modelle tiefer geht, sind mehr Branchenkenntnisse und sogar vertrauliche kommerzielle private Domänendaten erforderlich, um vertikale Industriemodelle zu trainieren, die den Branchenanforderungen entsprechen und eine extrem hohe Genauigkeit aufweisen. Aufgrund von Datenschutzanforderungen und Schwierigkeiten bei der Geltendmachung von Rechten und der Gewinnaufteilung sind Unternehmen jedoch häufig nicht bereit, nicht in der Lage oder haben Angst, ihre Daten weiterzugeben.
Gibt es eine Lösung, die nicht nur die Vorteile der Datenoffenheit und -freigabe nutzt, sondern auch die Sicherheit und den Datenschutz der Daten schützt?
Datenschutzbewahrende Berechnungen können Daten analysieren, verarbeiten und nutzen, ohne sicherzustellen, dass der Datenanbieter die Originaldaten nicht offenlegt. Sie gelten als Schlüsseltechnologie zur Förderung der Verbreitung und Transaktion von Datenelementen.[4] Der Einsatz von Privacy Computing zum Schutz der Datensicherheit großer Modelle scheint eine natürliche Wahl zu sein.
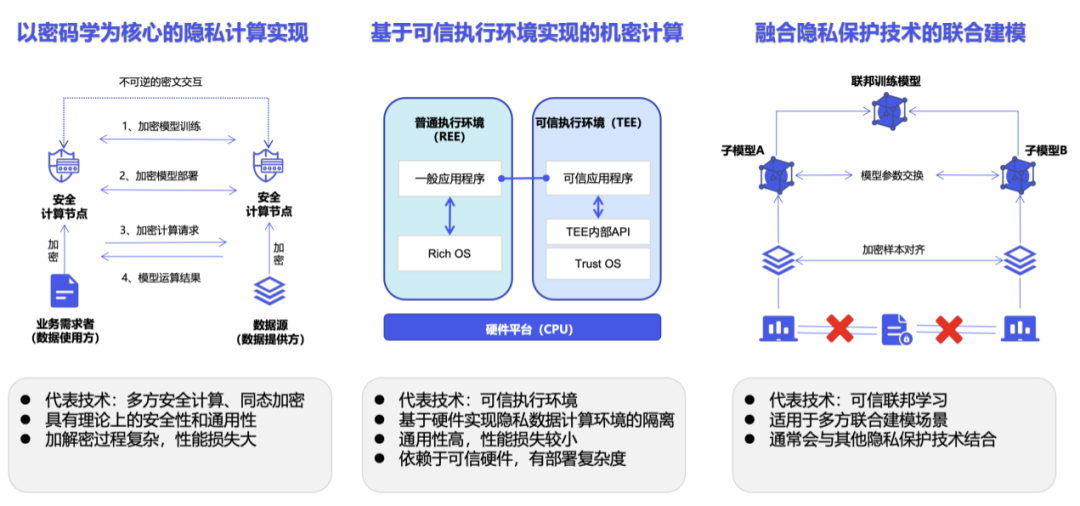
Privacy Computing ist keine Technologie, sondern ein technisches System. Entsprechend der spezifischen Implementierung wird Privacy Computing hauptsächlich in Kryptographiepfade unterteilt, die durch sicheres Mehrparteien-Computing dargestellt werden, Pfade für vertrauliche Datenverarbeitung, die durch vertrauenswürdige Ausführungsumgebungen dargestellt werden, und Pfade für künstliche Intelligenz, die durch föderiertes Lernen dargestellt werden [5].
In praktischen Anwendungen weist Privacy Computing jedoch einige Einschränkungen auf. Beispielsweise führt die Einführung des Privacy Computing SDK in der Regel zu Änderungen auf Codeebene am ursprünglichen Geschäftssystem [6]. Wenn es auf der Grundlage von Kryptographie implementiert wird, erhöhen Verschlüsselungs- und Entschlüsselungsvorgänge den Rechenaufwand exponentiell, und die Chiffretextberechnung erfordert größere Rechen- und Speicherressourcen sowie eine größere Kommunikationslast [7].
Darüber hinaus werden bestehende Privacy-Computing-Lösungen in großen Modelltrainingsszenarien mit extrem großen Datenmengen auf einige neue Probleme stoßen.
Federated Learning Based Schemes
Schauen wir uns zunächst die Schwierigkeiten des Federated Learning an. Der Kerngedanke des föderierten Lernens lautet: „Die Daten bewegen sich nicht, aber das Modell bewegt sich.“ Dieser dezentrale Ansatz stellt sicher, dass sensible Daten lokal bleiben und nicht offengelegt oder übertragen werden müssen. Jedes Gerät oder jeder Server nimmt am Trainingsprozess teil, indem es Modellaktualisierungen an den zentralen Server sendet, der diese Aktualisierungen aggregiert und zusammenführt, um das globale Modell zu verbessern [8].
Allerdings ist das zentralisierte Training großer Modelle bereits sehr schwierig, und verteilte Trainingsmethoden erhöhen die Komplexität des Systems erheblich. Wir müssen auch die Heterogenität der Daten berücksichtigen, wenn das Modell auf verschiedenen Geräten trainiert wird, und wie wir die Lerngewichte sicher über alle Geräte hinweg aggregieren können – für das Training großer Modelle sind die Modellgewichte selbst ein wichtiger Vorteil. Darüber hinaus muss verhindert werden, dass Angreifer aus einem einzelnen Modellupdate auf private Daten schließen, und entsprechende Abwehrmaßnahmen würden den Trainingsaufwand weiter erhöhen.
Kryptographiebasierte Lösung
Homomorphe Verschlüsselung kann verschlüsselte Daten direkt berechnen und die Daten „verfügbar und unsichtbar“ machen [9]. Die homomorphe Verschlüsselung ist ein leistungsstarkes Instrument zum Schutz der Privatsphäre in Szenarien, in denen sensible Daten verarbeitet oder analysiert werden und deren Vertraulichkeit gewährleistet ist. Diese Technik kann nicht nur auf das Training großer Modelle, sondern auch auf Inferenzen angewendet werden und gleichzeitig die Vertraulichkeit der Benutzereingaben (Eingabeaufforderung) schützen.
Die Verwendung verschlüsselter Daten ist jedoch viel schwieriger als die Verwendung unverschlüsselter Daten für das Training und die Inferenz großer Modelle. Gleichzeitig erfordert die Verarbeitung verschlüsselter Daten mehr Rechenleistung, was die Verarbeitungszeit exponentiell erhöht und die ohnehin schon sehr hohen Anforderungen an die Rechenleistung beim Training großer Modelle noch weiter erhöht.
Lösungen basierend auf Trusted Execution Environment
Lassen Sie uns über Lösungen sprechen, die auf Trusted Execution Environment (TEE) basieren. Die meisten TEE-Lösungen oder -Produkte erfordern den Kauf zusätzlicher Spezialausrüstung, wie sichere Mehrparteien-Rechenknoten, vertrauenswürdige Ausführungsumgebungsausrüstung, kryptografische Beschleunigerkarten usw., und können nicht an vorhandene Rechen- und Speicherressourcen angepasst werden, sodass diese Lösung für viele ungeeignet ist Für kleine und mittlere Unternehmen ist dies nicht realistisch. Darüber hinaus basieren aktuelle TEE-Lösungen hauptsächlich auf der CPU, während das Training großer Modelle stark auf der GPU basiert. Zu diesem Zeitpunkt sind GPU-Lösungen, die Privacy Computing unterstützen, noch nicht ausgereift, bergen jedoch zusätzliche Risiken [10].
Im Allgemeinen ist es in Mehrparteien-Collaborative-Computing-Szenarien oft unangemessen zu verlangen, dass Rohdaten im physischen Sinne „unsichtbar“ sind. Da der Verschlüsselungsprozess außerdem Rauschen zu den Daten hinzufügt, führt Training oder Rückschluss auf verschlüsselte Daten auch zu einem Leistungsverlust des Modells und verringert die Modellgenauigkeit. Bestehende Datenschutz-Computing-Lösungen sind hinsichtlich Leistung und GPU-Unterstützung nicht gut für große Modellschulungsszenarien geeignet. Sie hindern Unternehmen und Institutionen auch daran, Informationen zu öffnen und auszutauschen und an der großen Modellbranche teilzunehmen.
„Wenn wir die große Modellindustrie als Kette von Daten zu Anwendungen betrachten, werden wir feststellen, dass es sich bei dieser Kette tatsächlich um eine Vielzahl von Daten (einschließlich Rohdaten) handelt , umfasst auch die Zirkulationskette von Daten, die im Modell in Form von Parametern zwischen verschiedenen Einheiten vorhanden sind, und das Geschäftsmodell dieser Branche sollte auf der Grundlage aufgebaut sein, dass diese zirkulierenden Daten (oder Modelle) Vermögenswerte sind, die gehandelt werden können . " sagte Dr. Tang Zaiyang, CEO von YiZhi Technology.
„An der Zirkulation von Datenelementen sind mehrere Einheiten beteiligt, und die Quelle der Industriekette muss der Datenanbieter sein. Mit anderen Worten: Alle Geschäfte werden tatsächlich vom Datenanbieter initiiert. Dies ist nur mit Genehmigung des Datenanbieters möglich.“ Die Transaktion kann abgeschlossen werden, daher sollte der Wahrung der Rechte und Interessen der Datenanbieter Vorrang eingeräumt werden und föderiertes Lernen konzentrieren sich alle auf die Art und Weise, wie Datennutzer Daten verarbeiten. Tang Zaiyang ist der Ansicht, dass wir das Problem aus der Perspektive des Datenanbieters betrachten müssen.
Yizhi Technology wurde 2019 gegründet und ist als Anbieter von Datenschutzlösungen für die Datenkooperation positioniert. Im Jahr 2021 wurde das Unternehmen als eine der ersten teilnehmenden Einheiten in der von der China Academy of Information and Communications Technology initiierten „Data Security Initiative (DSI)“ ausgewählt und von DSI als eines der neun repräsentativen Privacy Computing-Unternehmen zertifiziert Unternehmensanbieter. Im Jahr 2022 wurde YiZhi Technology offiziell Mitglied der Open-Source-Community Open Islands, Chinas erster internationaler unabhängiger und kontrollierbarer Open-Source-Community für Datenschutz-Computing, um gemeinsam den Aufbau wichtiger Infrastruktur für die Verbreitung von Datenelementen zu fördern.
Als Reaktion auf das aktuelle Datendilemma beim Training großer Modelle sowie auf das umfassendere Problem der Zirkulation von Datenelementen hat Yizhi Technology eine neue Datenschutz-Computing-Lösung vorgeschlagen, die auf der Praxis basiert – kontrollierbares Computing.
„Der Kernfokus des Controlable Computing liegt darin, Informationen unter Wahrung der Privatsphäre zu entdecken und zu teilen. Das Problem, das wir lösen, besteht darin, die Sicherheit der während des Trainingsprozesses verwendeten Daten zu gewährleisten und zu verhindern, dass das trainierte Modell davon betroffen ist.“ böswillig gestohlen wurde
“, sagte Tang Zaiyang.Konkret erfordert kontrollierbares Computing, dass Datennutzer Daten in der vom Datenanbieter definierten Sicherheitsdomäne verarbeiten und verarbeiten.
Beispiel für eine Sicherheitsdomäne im Datenzirkulationsszenario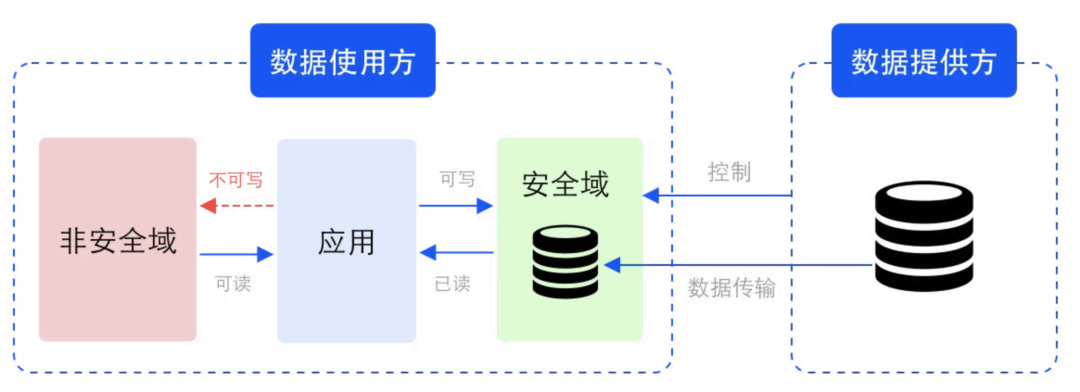
Sicherheitsdomäne ist ein logisches Konzept, das sich auf Speicher- und Recheneinheiten bezieht, die durch entsprechende Schlüssel und Verschlüsselungsalgorithmen geschützt sind. Der Sicherheitsbereich wird vom Datenanbieter definiert und eingeschränkt, die entsprechenden Speicher- und Rechenressourcen werden jedoch nicht vom Datenanbieter bereitgestellt. Physisch gesehen befindet sich die Sicherheitsdomäne auf der Seite des Datennutzers, wird jedoch vom Datenanbieter kontrolliert. Neben Rohdaten liegen auch verarbeitete und verarbeitete Zwischendaten und Ergebnisdaten in derselben Sicherheitsdomäne.
Im Sicherheitsbereich können die Daten Chiffretext (unsichtbar) oder Klartext (sichtbar) sein, da der sichtbare Bereich der Daten kontrolliert wird, wird sichergestellt, dass die Daten während der Nutzungssicherheit verwendet werden .
Der durch komplexe Chiffretextberechnungen verursachte Leistungsabfall ist ein wichtiger Faktor, der den Umfang von Datenschutz-Computing-Anwendungen einschränkt. Durch die Betonung der Kontrollierbarkeit von Daten, anstatt blind nach Unsichtbarkeit zu streben, löst kontrollierbares Computing das Problem herkömmlicher Datenschutz-Computing-Lösungen Geschäftsintensiv, daher eignet es sich sehr gut für große Modelltrainingsszenarien, die extrem große Datenmengen verarbeiten müssen.
Unternehmen können ihre Daten in mehreren verschiedenen Sicherheitsdomänen speichern und unterschiedliche Sicherheitsstufen, Nutzungsberechtigungen oder Whitelists für diese Sicherheitsdomänen festlegen. Für verteilte Anwendungen können Sicherheitsdomänen auch auf mehreren Computerknoten oder sogar Chips eingerichtet werden.
„Sicherheitsdomänen können aneinandergereiht werden. In jeder Verbindung der Datenzirkulation können Datenanbieter mehrere verschiedene Sicherheitsdomänen definieren, sodass ihre Daten nur zwischen diesen Sicherheitsdomänen fließen können. Am Ende werden diese serialisiert. Die Sicherheitsdomäne bildet eine.“ In diesem Netzwerk sind Daten kontrollierbar, der Datenfluss, die Analyse und die Verarbeitung können ebenfalls gemessen und überwacht werden, und die Datenzirkulation kann entsprechend auch monetarisiert werden.
Basierend auf der Idee des kontrollierbaren Rechnens hat YiZhi Technology „DataVault“ auf den Markt gebracht.
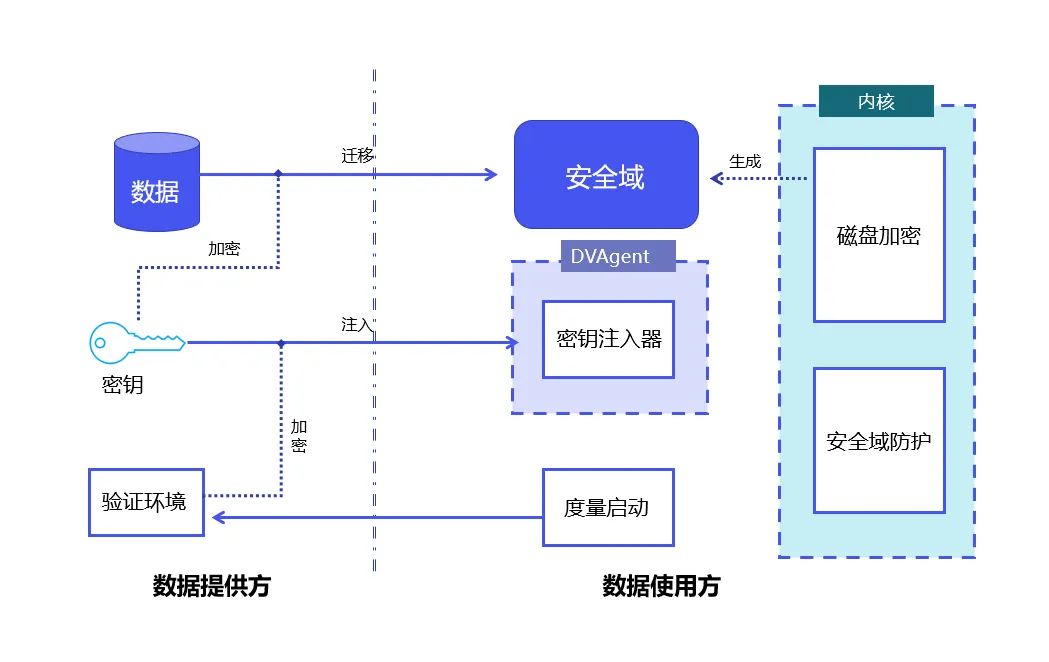
DataVault-Prinzip: Kombination von Linux-Metrikstart und Linux-Vollfestplattenverschlüsselungstechnologie, um Datenkontrolle und -schutz innerhalb der Sicherheitsdomäne zu erreichen.
DataVault verwendet das Trusted Platform Module TPM (Trusted Platform Module, dessen Kern darin besteht, hardwarebasierte sicherheitsbezogene Funktionen bereitzustellen) als Vertrauensbasis, um die Integrität des Systems zu schützen. Es verwendet das Linux Security Module LSM (; Linux-Sicherheitsmodule, Linux Ein im Kernel verwendetes Framework zur Unterstützung verschiedener Computersicherheitsmodelle, das unabhängig von jeder einzelnen Sicherheitsimplementierungstechnologie ist, sodass Daten in der Sicherheitsdomäne nur innerhalb kontrollierbarer Grenzen verwendet werden können.
Auf dieser Basis nutzt DataVault die von Linux bereitgestellte Technologie zur vollständigen Festplattenverschlüsselung, um die Daten in einer sicheren Domäne zu platzieren. YiZhi Technology hat selbst ein vollständiges kryptografisches Protokoll wie Schlüsselverteilung und Signaturautorisierung entwickelt und viel geleistet von technischen Optimierungen, die die Kontrollierbarkeit der Daten weiter gewährleisten.
DataVault unterstützt eine Vielzahl dedizierter Beschleunigerkarten, darunter verschiedene CPUs, GPUs, FPGAs und andere Hardware. Es unterstützt außerdem mehrere Datenverarbeitungs-Frameworks und Modelltrainings-Frameworks und ist binärkompatibel.
Noch wichtiger ist, dass der Leistungsverlust viel geringer ist als bei anderen Privacy-Computing-Lösungen. In den meisten Anwendungen ist der Gesamtleistungsverlust im Vergleich zum nativen System (d. h. ohne Privacy-Computing-Technologie) nicht höher 5%.
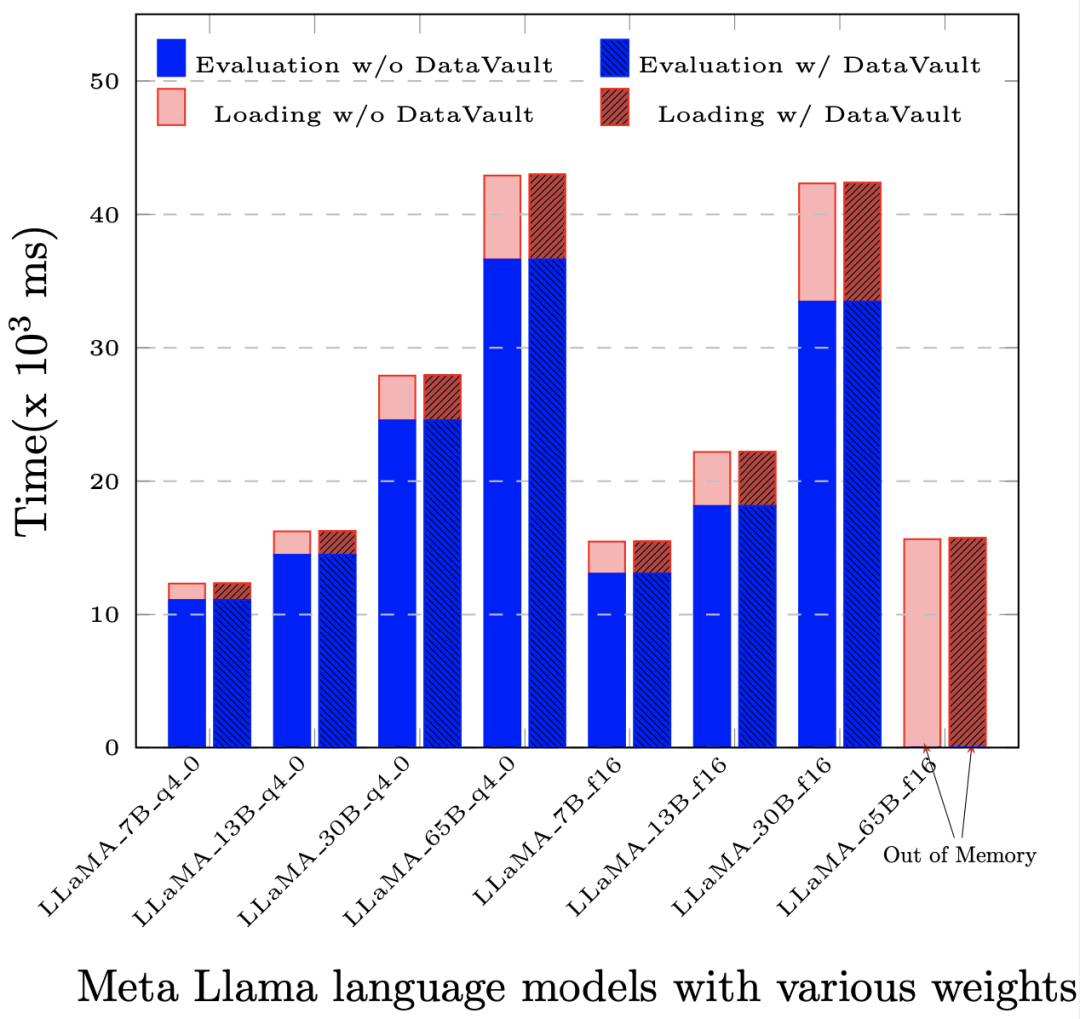
Nach der Bereitstellung von DataVault beträgt der Leistungsverlust bei der Auswertung (Evaluation) und der prompten Auswertung (Prompt Evaluation) basierend auf LLaMA-65B weniger als 1‰.
Jetzt hat YiZhi Technology eine Kooperation mit dem National Supercomputing Center geschlossen, um eine datenschutzschonende Hochleistungs-Computing-Plattform für KI-Anwendungen auf der Supercomputing-Plattform bereitzustellen. Basierend auf DataVault können Rechenleistungsnutzer Sicherheitsdomänen auf der Computerplattform festlegen, um sicherzustellen, dass sich der gesamte Prozess der Datenübertragung von Speicherknoten zu Computerknoten nur zwischen Sicherheitsdomänen bewegen kann und den festgelegten Bereich nicht verlässt.
Neben der Sicherstellung, dass Daten während des Modelltrainings kontrollierbar sind, kann auf Basis der DataVault-Lösung auch das trainierte große Modell selbst als Datengut geschützt und sicher gehandelt werden.
Derzeit leiden Unternehmen, die große Modelle lokal bereitstellen möchten, wie z. B. Finanz-, Medizin- und andere hochsensible Dateninstitute, unter dem Mangel an Infrastruktur, um große Modelle lokal auszuführen, einschließlich kostenintensiver und leistungsstarker Hardware für die Schulung großer Modelle sowie der Einsatz von Großmodellen. Anschließende Betriebs- und Wartungserfahrung des Modells. Unternehmen, die große Industriemodelle erstellen, befürchten, dass die hinter dem Modell selbst und den Modellparametern gesammelten Branchendaten und das Know-how, das hinter dem Modell selbst und den Modellparametern steckt, weiterverkauft werden könnten, wenn die Modelle direkt an Kunden geliefert werden.
Um die Umsetzung großer Modelle in vertikalen Industrien zu untersuchen, arbeitet YiZhi Technology auch mit dem Guangdong-Hong Kong-Macao Greater Bay Area Digital Economy Research Institute (IDEA Research Institute) zusammen großes Modell mit vorbildlichen Sicherheitsschutzfunktionen. Diese All-in-One-Maschine verfügt über mehrere integrierte große Modelle für vertikale Industrien und ist mit den grundlegenden Rechenressourcen ausgestattet, die für die Schulung und Förderung großer Modelle erforderlich sind, wodurch die Anforderungen der Kunden sofort erfüllt werden können. Darunter ist YiZhi steuerbar Die Rechenkomponente DataVault kann sicherstellen, dass diese integrierten Modelle nur bei autorisierter Verwendung das Modell und alle Zwischendaten nicht von externen Umgebungen gestohlen werden können.
Als neues Privacy-Computing-Paradigma hofft YiZhi Technology, dass kontrollierbares Computing Veränderungen in der großen Modellindustrie und der Verbreitung von Datenelementen bewirken kann.
「DataVault ist nur eine einfache Implementierungslösung. Da sich Technologie und Anforderungen ändern, werden wir weitere Versuche und Beiträge zum Datenelementzirkulationsmarkt unternehmen. Lassen Sie uns eine kontrollierbare Lösung aufbauen „Wir wollen die Computergemeinschaft zusammenbringen“, sagte Tang Zaiyang.
Das obige ist der detaillierte Inhalt vonFehlen qualitativ hochwertige Daten zum Trainieren großer Modelle? Wir haben eine neue Lösung gefunden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So ändern Sie devc++ auf Chinesisch
So ändern Sie devc++ auf Chinesisch
 Sonst-Verwendung in der Python-Schleifenstruktur
Sonst-Verwendung in der Python-Schleifenstruktur
 Der Unterschied zwischen Ankern und Zielen
Der Unterschied zwischen Ankern und Zielen
 Verwendung der isnumber-Funktion
Verwendung der isnumber-Funktion
 Was sind die häufigsten Tomcat-Schwachstellen?
Was sind die häufigsten Tomcat-Schwachstellen?
 Lösung außerhalb des zulässigen Bereichs
Lösung außerhalb des zulässigen Bereichs
 So gleichen Sie Zahlen in regulären Ausdrücken ab
So gleichen Sie Zahlen in regulären Ausdrücken ab
 Was ist der Handel mit digitalen Währungen?
Was ist der Handel mit digitalen Währungen?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



