


Originaltitel: UniOcc: Unifying Vision-Centric 3D Occupancy Prediction with Geometric and Semantic Rendering
Bitte klicken Sie auf den folgenden Link, um das Papier anzuzeigen: https://arxiv.org/pdf/2306.09117.pdf

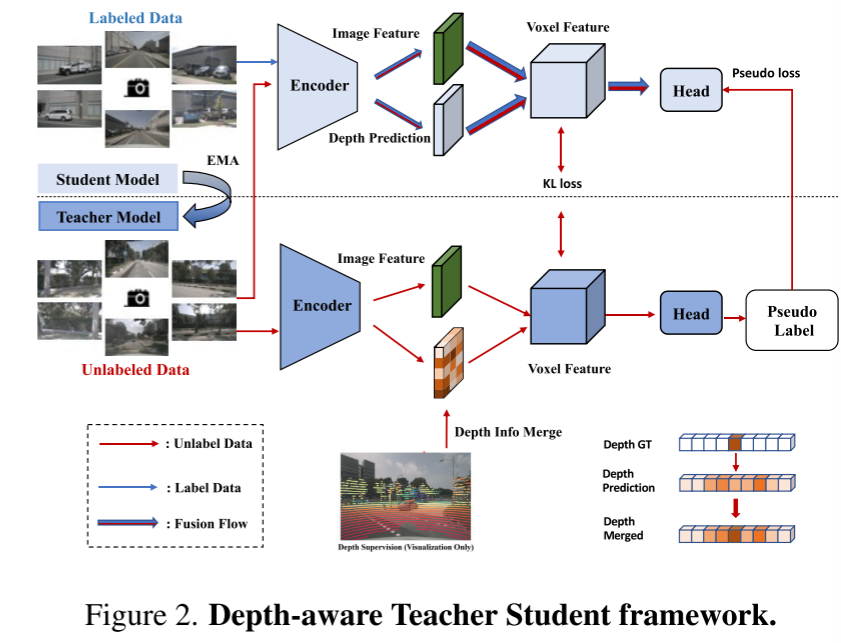
In diesem technischen Bericht schlagen wir eine Lösung namens UniOCC für visionszentrierte 3D-Belegungsvorhersagetrajektorien in der CVPR 2023 nuScenes Open Dataset Challenge vor. Bestehende Belegungsvorhersagemethoden konzentrieren sich hauptsächlich auf die Verwendung von 3D-Belegungsetiketten, um die projizierten Eigenschaften des 3D-Volumenraums zu optimieren. Der Generierungsprozess dieser Etiketten ist jedoch sehr komplex und teuer (basierend auf semantischer 3D-Annotation), ist durch die Voxelauflösung begrenzt und kann keine feinkörnige räumliche Semantik liefern. Um diese Einschränkung zu beheben, schlagen wir eine neue Methode zur Vorhersage der einheitlichen Belegung (UniOcc) vor, die explizit räumliche geometrische Einschränkungen auferlegt und die feinkörnige semantische Überwachung durch Volumenstrahl-Rendering ergänzt. Unsere Methode verbessert die Modellleistung erheblich und zeigt ein gutes Potenzial zur Reduzierung der manuellen Annotationskosten. Angesichts der mühsamen Kommentierung von 3D-Belegungen schlagen wir außerdem das tiefenbewusste Teacher Student (DTS)-Framework vor, um die Vorhersagegenauigkeit mithilfe unbeschrifteter Daten zu verbessern. Unsere Lösung erreichte 51,27 % mIoU im offiziellen Einzelmodell-Ranking und belegte in dieser Herausforderung den dritten Platz von 2D- und 3D-Darstellungen, wodurch Modelle zur Vorhersage der Belegung mit mehreren Kameras verbessert werden. In diesem Artikel wird keine neue Modellarchitektur entworfen, sondern der Schwerpunkt liegt auf der vielseitigen Plug-and-Play-Verbesserung vorhandener Modelle [3, 18, 20].
Bild 2. Tiefenbewusstes Lehrer-Schüler-Framework. 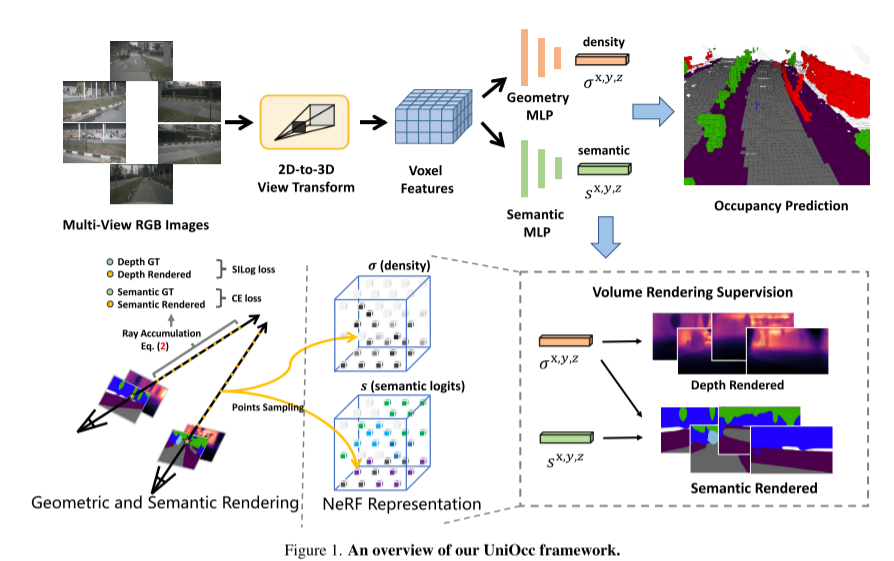
Experimentelle Ergebnisse:
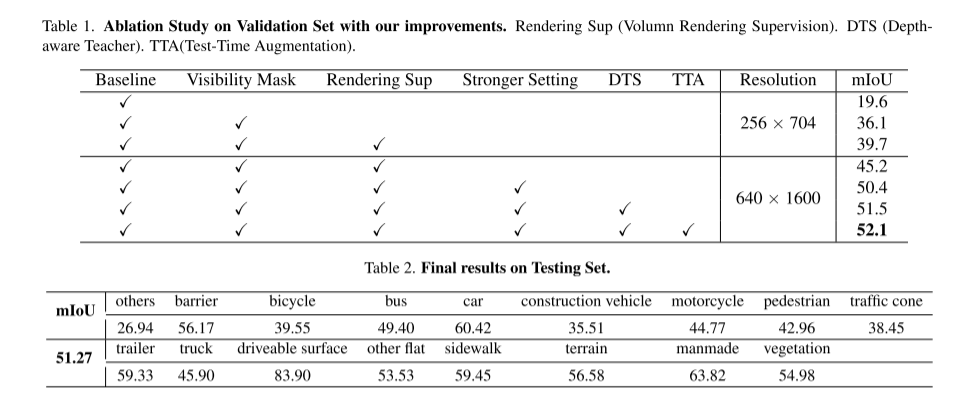

Das obige ist der detaillierte Inhalt vonUniOcc: Vereinigung der visionszentrierten Belegungsvorhersage mit geometrischer und semantischer Darstellung!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So verwenden Sie Left Join
So verwenden Sie Left Join
 So überprüfen Sie den Portstatus mit netstat
So überprüfen Sie den Portstatus mit netstat
 Die Speicherlösung kann nicht geschrieben werden
Die Speicherlösung kann nicht geschrieben werden
 was bedeutet PM
was bedeutet PM
 So erhöhen Sie die Download-Geschwindigkeit
So erhöhen Sie die Download-Geschwindigkeit
 vscode Chinesische Einstellungsmethode
vscode Chinesische Einstellungsmethode
 Alle Verwendungen von Cloud-Servern
Alle Verwendungen von Cloud-Servern
 So lösen Sie das Problem, dass Tomcat die Seite nicht anzeigen kann
So lösen Sie das Problem, dass Tomcat die Seite nicht anzeigen kann








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



