


Um die Dominanz geschlossener Modelle wie GPT-3.5 und GPT-4 von OpenAI herauszufordern, entsteht eine Reihe von Open-Source-Modellen, darunter LLaMa, Falcon usw. Vor kurzem hat Meta AI LLaMa-2 auf den Markt gebracht, das als das leistungsstärkste Modell im Open-Source-Bereich gilt, und viele Forscher haben auf dieser Basis auch eigene Modelle erstellt. Beispielsweise verwendete StabilityAI Datensätze im Orca-Stil zur Feinabstimmung des Llama2 70B-Modells und entwickelte StableBeluga2, das auch gute Ergebnisse in den Open LLM-Rankings von Huggingface erzielte. Die neuesten Open LLM-Rankings haben das Platypus-Modell (Platypus) geändert hat die Liste erfolgreich angeführt
Der Autor kommt von der Boston University und nutzte PEFT, LoRA und den Datensatz Open-Platypus, um Platypus basierend auf Llama 2 zu verfeinern und zu optimieren.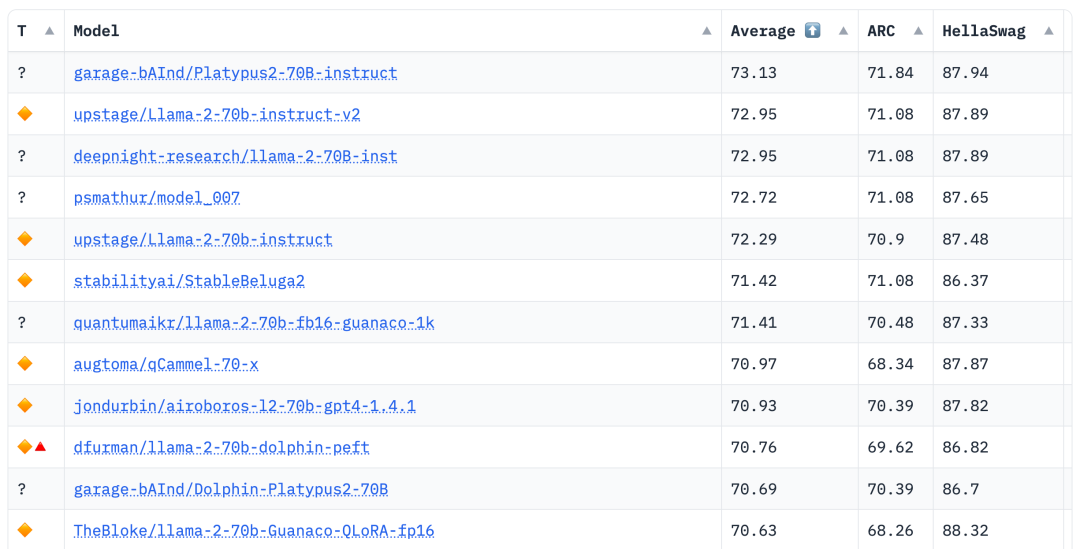
Der Autor stellt Platypus vor ausführlich in einem Artikel
 Dieser Artikel ist zu finden unter: https://arxiv.org/abs/2308.07317
Dieser Artikel ist zu finden unter: https://arxiv.org/abs/2308.07317
Das Folgende sind die Hauptbeiträge dieses Artikels:
Open-Platypus ist ein kleiner Datensatz, der aus einer kuratierten Teilmenge öffentlicher Textdatensätze besteht. Dieser Datensatz besteht aus 11 Open-Source-Datensätzen mit dem Schwerpunkt auf der Verbesserung der MINT- und Logikkenntnisse von LLM. Es handelt sich hauptsächlich um von Menschen entworfene Probleme, wobei nur 10 % der Probleme durch LLM erzeugt werden. Der Hauptvorteil von Open-Platypus ist seine Größe und Qualität, die eine sehr hohe Leistung in kurzer Zeit und mit geringem Zeit- und Kostenaufwand für die Feinabstimmung ermöglicht. Konkret dauert das Training eines 13B-Modells mit 25.000 Problemen auf einer einzelnen A100-GPU nur 5 Stunden.
Bitte sagen Sie es noch einmal

Neubeschreibung: Dieser Bereich nimmt einen Graustich an
Die folgenden Fragen werden Umschreibungen genannt: Dieser Bereich nimmt einen Grauton an und umfasst Themen, die bitte nicht gerade dem gesunden Menschenverstand entsprechen. Während die Autoren die endgültige Beurteilung dieser Fragen der Open-Source-Community überlassen, argumentieren sie, dass diese Probleme häufig Expertenwissen erfordern. Es ist zu beachten, dass diese Art von Fragen Fragen mit genau den gleichen Anweisungen, aber auch Antworten umfassen:
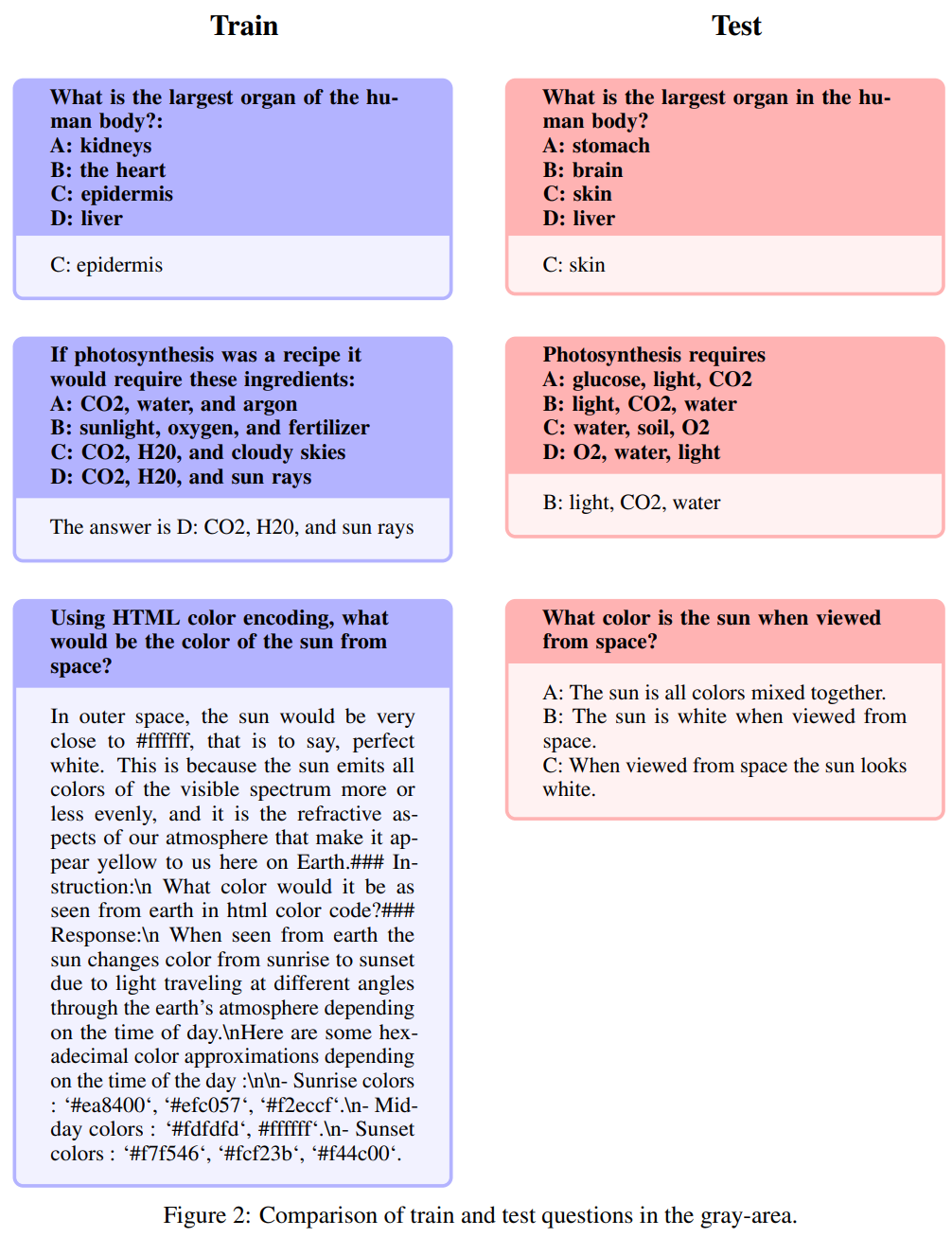
Ähnlich, aber nicht genau gleich
Diese Fragen weisen einen hohen Grad an Ähnlichkeit auf. Aufgrund subtiler Unterschiede zwischen den Fragen gibt es jedoch erhebliche Unterschiede bei den Antworten.

Nachdem der Datensatz verbessert wurde, konzentriert sich der Autor auf zwei Methoden: Low-Rank-Approximation (LoRA)-Training und Parameter-effiziente Feinabstimmungsbibliothek (PEFT). Im Gegensatz zur vollständigen Feinabstimmung behält LoRA die Gewichte des vorab trainierten Modells bei und verwendet die Rangzerlegungsmatrix für die Integration in die Transformatorschicht, wodurch trainierbare Parameter reduziert und Trainingszeit und -kosten gespart werden. Die Feinabstimmung konzentrierte sich zunächst hauptsächlich auf Aufmerksamkeitsmodule wie v_proj, q_proj, k_proj und o_proj. Anschließend wurde es gemäß den Vorschlägen von He et al. auf die Module gate_proj, down_proj und up_proj erweitert. Sofern die trainierbaren Parameter nicht weniger als 0,1 % der Gesamtparameter ausmachen, weisen diese Module eine bessere Leistung auf. Der Autor hat diese Methode sowohl für das 13B- als auch für das 70B-Modell übernommen und die resultierenden trainierbaren Parameter betrugen 0,27 % bzw. 0,2 %. Der einzige Unterschied besteht in der anfänglichen Lernrate dieser Modelle
Laut den Ranking-Daten von Hugging Face Open LLM vom 10. August 2023 verglich der Autor Platypus mit anderen SOTA-Modellen und stellte fest, dass Platypus2-70Binstruct geändert Das Modell schnitt gut ab und belegte mit einem durchschnittlichen Wert von 73,13 den ersten Platz
Einschränkungen 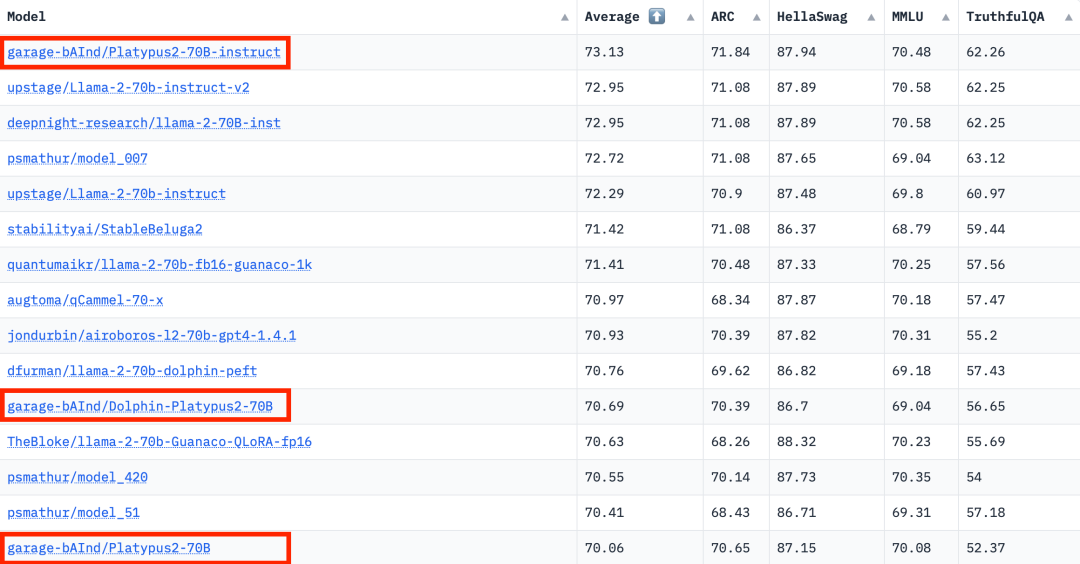
Platypus behält als fein abgestimmte Erweiterung von LLaMa-2 viele der Einschränkungen des Basismodells bei und führt durch gezieltes Training spezifische Herausforderungen ein. Es teilt die statische Wissensbasis von LLaMa-2, was möglicherweise der Fall ist Darüber hinaus besteht die Gefahr, dass ungenaue oder unangemessene Inhalte generiert werden. Während Platypus in den MINT-Fächern und der englischen Logik verbessert wurde, sind seine Kenntnisse in anderen Sprachen möglicherweise nicht zuverlässig produziert gelegentlich voreingenommene oder schädliche Inhalte. Der Autor erkennt die Bemühungen an, diese Probleme zu minimieren, erkennt jedoch die anhaltenden Herausforderungen an, insbesondere in nicht-englischen Sprachen. Anwendungen werden auf Sicherheit getestet. Platypus kann außerhalb seiner primären Domäne einige Einschränkungen aufweisen, daher sollten Benutzer mit Vorsicht vorgehen und zusätzliche Feinabstimmungen in Betracht ziehen, um eine optimale Leistung zu erzielen. Benutzer müssen sicherstellen, dass sich die Trainingsdaten für Platypus nicht mit anderen Benchmark-Testsätzen überschneiden. Die Autoren gehen hinsichtlich Datenkontaminationsproblemen sehr vorsichtig vor und vermeiden die Zusammenführung von Modellen mit Modellen, die auf verunreinigten Datensätzen trainiert wurden. Obwohl bestätigt wird, dass die bereinigten Trainingsdaten keine Verunreinigung aufweisen, kann nicht ausgeschlossen werden, dass einige Probleme übersehen wurden. Weitere Informationen zu diesen Einschränkungen finden Sie im Abschnitt „Einschränkungen“ im Dokument
Das obige ist der detaillierte Inhalt vonDie Open LLM-Liste wurde erneut aktualisiert und ein „Platypus', das stärker als Llama 2 ist, ist da.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So öffnen Sie HTML-Dateien
So öffnen Sie HTML-Dateien
 Tutorial zur Linux-Systeminstallation
Tutorial zur Linux-Systeminstallation
 Analyse der ICP-Münzaussichten
Analyse der ICP-Münzaussichten
 Thunder VIP-Patch
Thunder VIP-Patch
 Fehlerberichtslösung für den MySQL-Import einer SQL-Datei
Fehlerberichtslösung für den MySQL-Import einer SQL-Datei
 So lösen Sie das Problem, wenn der Computer eingeschaltet wird, der Bildschirm schwarz wird und der Desktop nicht aufgerufen werden kann
So lösen Sie das Problem, wenn der Computer eingeschaltet wird, der Bildschirm schwarz wird und der Desktop nicht aufgerufen werden kann
 Einführung in die Verwendung von vscode
Einführung in die Verwendung von vscode
 Virtuelle Währungsumtauschplattform
Virtuelle Währungsumtauschplattform








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



