

 Technologie-Peripheriegeräte
KI
Neues Rückgrat eines leichten visuellen Netzwerks: effizienter Fourier-Operator-Token-Mixer
Technologie-Peripheriegeräte
KI
Neues Rückgrat eines leichten visuellen Netzwerks: effizienter Fourier-Operator-Token-Mixer
Neues Rückgrat eines leichten visuellen Netzwerks: effizienter Fourier-Operator-Token-Mixer

1. Hintergrund
Im Laufe der Jahre haben drei visuelle Backbone-Netzwerke, Transformer, Large-Kernel-CNN und MLP, große Erfolge bei einer Vielzahl von Computer-Vision-Aufgaben erzielt, hauptsächlich aufgrund ihrer effizienten globalen Skalierung um Informationen zu verschmelzen
Transformer, CNN und MLP sind derzeit die drei gängigen neuronalen Netze, und sie verwenden jeweils unterschiedliche Methoden, um eine globale Token-Fusion zu erreichen. Im Transformer-Netzwerk verwendet der Selbstaufmerksamkeitsmechanismus die Korrelation von Abfrage-Schlüssel-Paaren als Gewicht der Token-Fusion. CNN erreicht eine ähnliche Leistung wie Transformer, indem es die Größe des Faltungskerns erweitert. MLP implementiert ein weiteres leistungsstarkes Paradigma zwischen allen Token durch vollständige Konnektivität. Obwohl diese Methoden effektiv sind, weisen sie eine hohe Rechenkomplexität (O(N^2)) auf und lassen sich nur schwer auf Geräten mit begrenzten Speicher- und Rechenkapazitäten bereitstellen, wodurch der Anwendungsbereich vieler AFF-Token-Mixer eingeschränkt wird : Leicht, global, adaptiv
Um das rechenintensive Problem zu lösen, entwickelten Forscher einen effizienten globalen Token-Fusion namens Adaptive Fourier Filter (AFF)-Algorithmus. Dieser Algorithmus verwendet die Fourier-Transformation, um den Token-Satz in den Frequenzbereich umzuwandeln, und erlernt eine Filtermaske, die adaptive Inhalte im Frequenzbereich verarbeiten kann, um adaptive Filteroperationen für den in den Frequenzbereich konvertierten Token-Satz durchzuführen.
Adaptive Frequenzfilter : Effiziente globale Token-Mixer
Klicken Sie auf diesen Link, um auf den Originaltext zuzugreifen: https://arxiv.org/abs/2307.14008
Gemäß dem Frequenzdomänen-Faltungstheorem ist die Mathematik des AFF-Token-Mixers Die äquivalente Operation ist eine im Originalbereich ausgeführte Faltungsoperation, die der im Fourier-Bereich ausgeführten Hadamard-Produktoperation entspricht. Das bedeutet, dass AFF Token Mixer eine inhaltsadaptive globale Token-Fusion erreichen kann, indem er einen dynamischen Faltungskern in der Originaldomäne mit derselben räumlichen Auflösung wie der Größe des Token-Sets verwendet (wie in der rechten Teilfigur der Abbildung unten gezeigt)
Es ist bekannt, dass die dynamische Faltung rechenintensiv ist, insbesondere wenn dynamische Faltungskerne mit großer räumlicher Auflösung verwendet werden. Dieser Aufwand scheint für ein effizientes/leichtgewichtiges Netzwerkdesign inakzeptabel zu sein. Der in diesem Artikel vorgeschlagene AFF-Token-Mixer kann jedoch gleichzeitig die oben genannten Anforderungen in einer äquivalenten Implementierung mit geringem Stromverbrauch erfüllen, wodurch die Komplexität von O (N^2) auf O (N log N) reduziert und somit die Recheneffizienz erheblich verbessert wird
Schematisches Diagramm 1: Zeigt die Struktur des AFF-Moduls und des AFFNet-Netzwerks 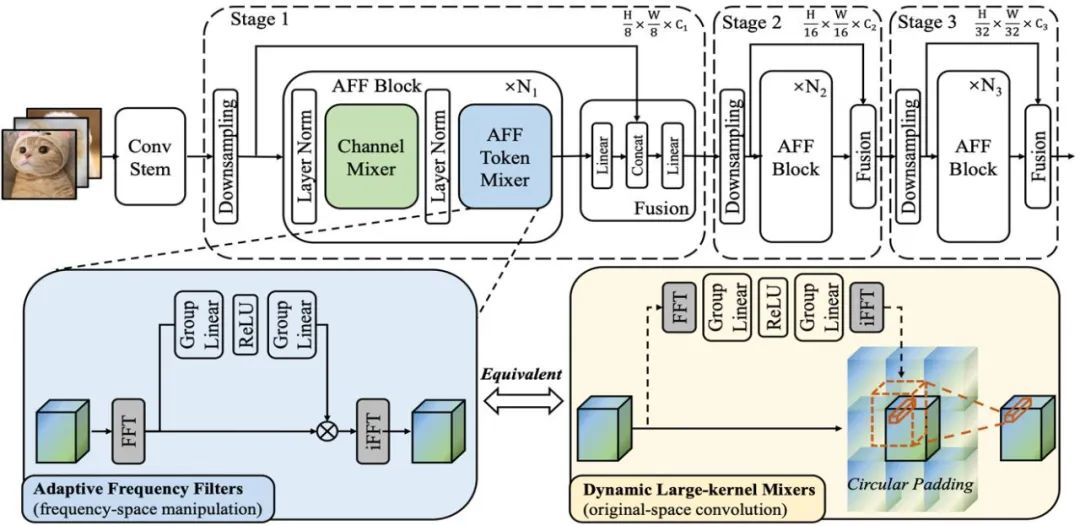
3. AFFNet: das neue Rückgrat des leichten visuellen Netzwerks
Durch die Verwendung von AFF Token Mixer als Hauptoperation des neuronalen Netzwerks Betreiber, Den Forschern gelang es, ein leichtes neuronales Netzwerk namens AFFNet aufzubauen. Umfangreiche experimentelle Ergebnisse zeigen, dass AFF Token Mixer bei einer Vielzahl visueller Aufgaben, einschließlich visueller semantischer Erkennung und dichter Vorhersageaufgaben, ein hervorragendes Gleichgewicht zwischen Genauigkeit und Effizienz erreicht Token Mixer und AFFNet vergleichen mehrere Aufgaben wie visuelle semantische Erkennung, Segmentierung und Erkennung mit dem fortschrittlichsten leichten visuellen Backbone-Netzwerk im aktuellen Forschungsbereich. Experimentelle Ergebnisse zeigen, dass das Modelldesign bei einer Vielzahl visueller Aufgaben gut funktioniert, was das Potenzial von AFF Token Mixer als neue Generation eines leichten und effizienten Token-Fusion-Operators bestätigt. Im Vergleich zu SOTA zeigt Abbildung 2 Acc -Param- und Acc-FLOPs-Kurven für den ImageNet-1K-Datensatz. Vergleich der Ergebnisse der modernsten Methoden mit dem ImageNet-1K-Datensatz, siehe Tabelle 1 Tabelle 2 zeigt den Vergleich visueller Erkennungs- und Segmentierungsaufgaben mit modernsten Techniken
5. Fazit
Diese Studie beweist, dass die Frequenzbereichstransformation im latenten Raum eine wichtige Rolle bei der globalen adaptiven Token-Fusion spielt und eine effiziente und stromsparende äquivalente Implementierung darstellt. Es liefert neue Forschungsideen für den Entwurf von Token-Fusion-Operatoren in neuronalen Netzen und bietet neuen Entwicklungsraum für den Einsatz neuronaler Netzmodelle auf Edge-Geräten, insbesondere wenn die Speicher- und Rechenkapazitäten begrenzt sind
Das obige ist der detaillierte Inhalt vonNeues Rückgrat eines leichten visuellen Netzwerks: effizienter Fourier-Operator-Token-Mixer. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 CUDAs universelle Matrixmultiplikation: vom Einstieg bis zur Kompetenz!
Mar 25, 2024 pm 12:30 PM
CUDAs universelle Matrixmultiplikation: vom Einstieg bis zur Kompetenz!
Mar 25, 2024 pm 12:30 PM
Die allgemeine Matrixmultiplikation (GEMM) ist ein wesentlicher Bestandteil vieler Anwendungen und Algorithmen und außerdem einer der wichtigen Indikatoren zur Bewertung der Leistung der Computerhardware. Eingehende Forschung und Optimierung der Implementierung von GEMM können uns helfen, Hochleistungsrechnen und die Beziehung zwischen Software- und Hardwaresystemen besser zu verstehen. In der Informatik kann eine effektive Optimierung von GEMM die Rechengeschwindigkeit erhöhen und Ressourcen einsparen, was für die Verbesserung der Gesamtleistung eines Computersystems von entscheidender Bedeutung ist. Ein tiefgreifendes Verständnis des Funktionsprinzips und der Optimierungsmethode von GEMM wird uns helfen, das Potenzial moderner Computerhardware besser zu nutzen und effizientere Lösungen für verschiedene komplexe Computeraufgaben bereitzustellen. Durch Optimierung der Leistung von GEMM
 So berechnen Sie Addition, Subtraktion, Multiplikation und Division in einem Word-Dokument
Mar 19, 2024 pm 08:13 PM
So berechnen Sie Addition, Subtraktion, Multiplikation und Division in einem Word-Dokument
Mar 19, 2024 pm 08:13 PM
WORD ist ein leistungsstarkes Textverarbeitungsprogramm, mit dem wir verschiedene Texte in Excel bearbeiten können. Wir beherrschen die Berechnungsmethoden der Addition, Subtraktion und Multiplikatoren. Wie subtrahiere ich den Multiplikator? Kann ich ihn nur mit einem Taschenrechner berechnen? Die Antwort ist natürlich nein, WORD kann das auch. Heute werde ich Ihnen beibringen, wie Sie mit Formeln grundlegende Operationen wie Addition, Subtraktion, Multiplikation und Division in Tabellen in Word-Dokumenten berechnen. Lassen Sie mich heute im Detail zeigen, wie man Addition, Subtraktion, Multiplikation und Division in einem WORD-Dokument berechnet. Schritt 1: Öffnen Sie ein WORD, klicken Sie in der Symbolleiste unter [Einfügen] auf [Tabelle] und fügen Sie eine Tabelle in das Dropdown-Menü ein.
 Ein tiefer Einblick in Modelle, Daten und Frameworks: eine ausführliche 54-seitige Übersicht über effiziente große Sprachmodelle
Jan 14, 2024 pm 07:48 PM
Ein tiefer Einblick in Modelle, Daten und Frameworks: eine ausführliche 54-seitige Übersicht über effiziente große Sprachmodelle
Jan 14, 2024 pm 07:48 PM
Large-Scale Language Models (LLMs) haben überzeugende Fähigkeiten bei vielen wichtigen Aufgaben bewiesen, darunter das Verständnis natürlicher Sprache, die Sprachgenerierung und das komplexe Denken, und hatten tiefgreifende Auswirkungen auf die Gesellschaft. Diese herausragenden Fähigkeiten erfordern jedoch erhebliche Schulungsressourcen (im linken Bild dargestellt) und lange Inferenzzeiten (im rechten Bild dargestellt). Daher müssen Forscher wirksame technische Mittel entwickeln, um ihre Effizienzprobleme zu lösen. Darüber hinaus wurden, wie auf der rechten Seite der Abbildung zu sehen ist, einige effiziente LLMs (LanguageModels) wie Mistral-7B erfolgreich beim Entwurf und Einsatz von LLMs eingesetzt. Diese effizienten LLMs können den Inferenzspeicher erheblich reduzieren und gleichzeitig eine ähnliche Genauigkeit wie LLaMA1-33B beibehalten
 So zählen Sie die Anzahl der Elemente in einer Liste mit der Funktion count() von Python
Nov 18, 2023 pm 02:53 PM
So zählen Sie die Anzahl der Elemente in einer Liste mit der Funktion count() von Python
Nov 18, 2023 pm 02:53 PM
Um die Anzahl der Elemente in einer Liste mit der Funktion count() von Python zu zählen, sind bestimmte Codebeispiele erforderlich. Als leistungsstarke und leicht zu erlernende Programmiersprache bietet Python viele integrierte Funktionen zur Verarbeitung unterschiedlicher Datenstrukturen. Eine davon ist die Funktion count(), mit der sich die Anzahl der Elemente in einer Liste zählen lässt. In diesem Artikel erklären wir die Verwendung der count()-Funktion im Detail und stellen spezifische Codebeispiele bereit. Die Funktion count() ist eine in Python integrierte Funktion, mit der ein bestimmter Wert berechnet wird
 Zählen Sie rekursiv die Anzahl der Vorkommen eines Teilstrings in Java
Sep 17, 2023 pm 07:49 PM
Zählen Sie rekursiv die Anzahl der Vorkommen eines Teilstrings in Java
Sep 17, 2023 pm 07:49 PM
Gegeben seien zwei Strings str_1 und str_2. Das Ziel besteht darin, mithilfe eines rekursiven Verfahrens die Anzahl der Vorkommen der Teilzeichenfolge str2 in der Zeichenfolge str1 zu zählen. Eine rekursive Funktion ist eine Funktion, die sich innerhalb ihrer Definition selbst aufruft. Wenn str1 „Iknowthatyouknowthatiknow“ und str2 „know“ ist, beträgt die Anzahl der Vorkommen -3. Lassen Sie uns das anhand von Beispielen verstehen. Geben Sie beispielsweise str1="TPisTPareTPamTP", str2="TP" ein; geben Sie Countofoccurrencesofasubstringrecursi aus
 So verwenden Sie die Math.Pow-Funktion in C#, um die Potenz einer bestimmten Zahl zu berechnen
Nov 18, 2023 am 11:32 AM
So verwenden Sie die Math.Pow-Funktion in C#, um die Potenz einer bestimmten Zahl zu berechnen
Nov 18, 2023 am 11:32 AM
In C# gibt es eine Math-Klassenbibliothek, die viele mathematische Funktionen enthält. Dazu gehört die Funktion Math.Pow, die Potenzen berechnet und uns dabei helfen kann, die Potenz einer bestimmten Zahl zu berechnen. Die Verwendung der Math.Pow-Funktion ist sehr einfach, Sie müssen lediglich die Basis und den Exponenten angeben. Die Syntax lautet wie folgt: Math.Pow(base,exponent); wobei base die Basis und exponent den Exponenten darstellt. Diese Funktion gibt ein Ergebnis vom Typ Double zurück, nämlich das Ergebnis der Leistungsberechnung. Lasst uns
 Nvidias GPU der nächsten Generation zerschmettert H100 und wird enthüllt! Das erste 3-nm-Multichip-Moduldesign, vorgestellt im Jahr 2024
Sep 30, 2023 pm 12:49 PM
Nvidias GPU der nächsten Generation zerschmettert H100 und wird enthüllt! Das erste 3-nm-Multichip-Moduldesign, vorgestellt im Jahr 2024
Sep 30, 2023 pm 12:49 PM
3-nm-Prozess, Leistung übertrifft H100! Kürzlich brachten die ausländischen Medien DigiTimes die Nachricht, dass Nvidia die GPU der nächsten Generation, die B100, mit dem Codenamen „Blackwell“ entwickelt, angeblich als Produkt für Anwendungen im Bereich der künstlichen Intelligenz (KI) und des Hochleistungsrechnens (HPC). Der B100 wird den 3-nm-Prozess von TSMC sowie ein komplexeres Multi-Chip-Modul (MCM)-Design nutzen und im vierten Quartal 2024 erscheinen. Nvidia, das mehr als 80 % des GPU-Marktes für künstliche Intelligenz monopolisiert, kann mit dem B100 zuschlagen, solange das Eisen heiß ist, und in dieser Welle des KI-Einsatzes weitere Herausforderer wie AMD und Intel angreifen. Nach Schätzungen von NVIDIA wird erwartet, dass der Produktionswert dieses Bereichs bis 2027 ungefähr erreicht
 Die umfassendste Übersicht über multimodale Großmodelle finden Sie hier! 7 Microsoft-Forscher arbeiteten intensiv zusammen, 5 Hauptthemen, 119 Seiten Dokument
Sep 25, 2023 pm 04:49 PM
Die umfassendste Übersicht über multimodale Großmodelle finden Sie hier! 7 Microsoft-Forscher arbeiteten intensiv zusammen, 5 Hauptthemen, 119 Seiten Dokument
Sep 25, 2023 pm 04:49 PM
Die umfassendste Übersicht über multimodale Großmodelle finden Sie hier! Es wurde