
| Befehl | Beschreibung | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B LPOP-Taste 1, Taste 2,... Timeout | Entfernen und Holen Sie sich das erste Element der Liste. Wenn kein Element in der Liste vorhanden ist, wird die Liste blockiert, bis die Wartezeit abgelaufen ist oder das Element gelöscht wird. | |||||||||||||||||||
| BRPOP key1 [key2 ] timeout | Bewegen Sie sich und holen Sie sich das letzte Element der Liste. Wenn kein Element in der Liste vorhanden ist, wird das blockiert list, bis die Wartezeit abgelaufen ist oder ein Popable-Element gefunden wird. | |||||||||||||||||||
| BRPOPLPUSH Quell-Ziel-Timeout | Wählen Sie einen Wert aus der Liste, fügen Sie das entnommene Element in eine andere Liste ein und geben Sie es zurück Wartezeitüberschreitung oder Bis Popup-Elemente gefunden werden. | |||||||||||||||||||
| LIndex key index | 通过索引获取列表中的元素 | |||||||||||||||||||
| Linsert key before/after pivot value | 在列表的元素前或者后插入元素 | |||||||||||||||||||
| LLEN key | 获取列表长度 | |||||||||||||||||||
| LPOP key | 移出并获取列表的第一个元素 | |||||||||||||||||||
| LPUSH-Schlüsselwert1,Wert2,… | Fügen Sie einen oder mehrere Werte in den Kopf der Liste ein | |||||||||||||||||||
| LPUSHX-Schlüsselwert | fügt einen Wert in den Kopf einer vorhandenen Liste ein | |||||||||||||||||||
| LRANGE-Taste Srart Stop | Ruft die Elemente im angegebenen Bereich der Liste ab | |||||||||||||||||||
| LREM-Taste Zählwert | Listenelement entfernen | |||||||||||||||||||
| LSET-Schlüsselindexwert | Legen Sie den Wert des Listenelements fest durch. index | |||||||||||||||||||
| LTRIM-Taste Start Stop | Das Bereinigen einer Liste bedeutet, dass die Liste nur Elemente innerhalb des angegebenen Bereichs behält und alle Elemente, die nicht innerhalb des angegebenen Bereichs liegen, gelöscht werden. Der Index beginnt bei 0 und der Bereich ist inklusive. | |||||||||||||||||||
| RPOP-Taste | entfernt das letzte Element aus der Liste, und der Rückgabewert ist das entfernte Element | |||||||||||||||||||
| RPOPPUSH Quellziel | Entfernen Sie das letzte Element der Liste, fügen Sie dieses Element einer anderen Liste hinzu und geben Sie | |||||||||||||||||||
| RPUSH-Schlüsselwert1 Wert2 …… | zurück Eins hinzufügen oder Weitere Werte bis zum Ende der Liste
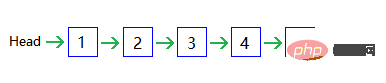
Einfach verknüpfte ListeBevor wir die Listenimplementierung von Redis lernen, werfen wir einen Blick darauf Zunächst einmal So implementieren Sie eine einfach verknüpfte Liste: Jeder Knoten hat einen Rückwärtszeiger (Referenz), der auf den nächsten Knoten zeigt, der letzte Knoten zeigt auf NULL, um das Ende anzuzeigen, und es gibt einen Kopfzeiger, der auf den zeigt erster Knoten, der den Start anzeigt.
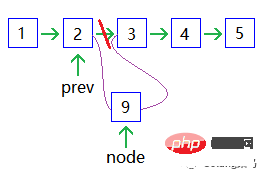
Ähnlich wie hier, aber neu und gelöscht benötigen nur Zeit; Rückwärtssuche ist nicht möglich und Sie müssen beginnen von Anfang an, falls Sie es verpassen. 🎜Knoten hinzufügen: 🎜🎜
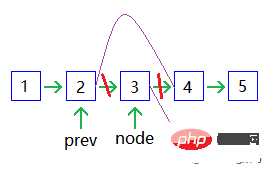
Einen Knoten löschen:
Eine doppelt verknüpfte Liste wird auch als doppelt verknüpfte Liste bezeichnet. Es handelt sich um eine Art verknüpfte Liste hat zwei Zeiger, die auf den unmittelbaren Nachfolger bzw. den unmittelbaren Vorgänger zeigen. Daher können Sie ausgehend von jedem Knoten in der doppelt verknüpften Liste problemlos auf dessen Vorgänger- und Nachfolgerknoten zugreifen.
|
| Wert | Bedeutung |
|---|---|
| 0 | Besonderer Wert bedeutet keine Komprimierung |
| 1 | An jedem Ende der Quicklist befindet sich 1 Knoten, der nicht komprimiert ist, und der mittlere Knoten ist komprimiert sind nicht komprimiert und der mittlere Knoten ist komprimiert |
| n | An beiden Enden der Quicklist gibt es n Knoten, die nicht komprimiert sind, und die Knoten in der Mitte sind komprimiert |
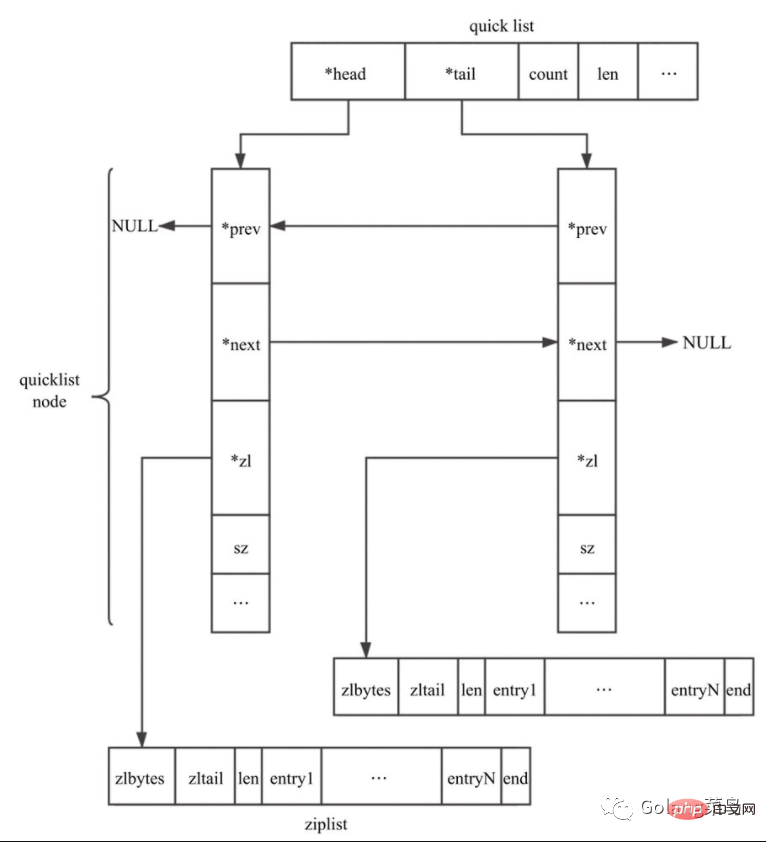
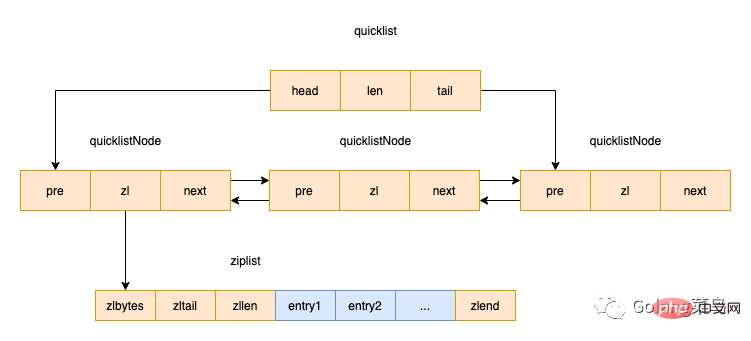
Es gibt auch ein Füllfeld, was bedeutet, dass die maximale Kapazität jedes Quicknode-Knotens unterschiedliche Bedeutungen hat kann auch auf andere Werte konfiguriert werden. ;list-max-ziplist-size -2
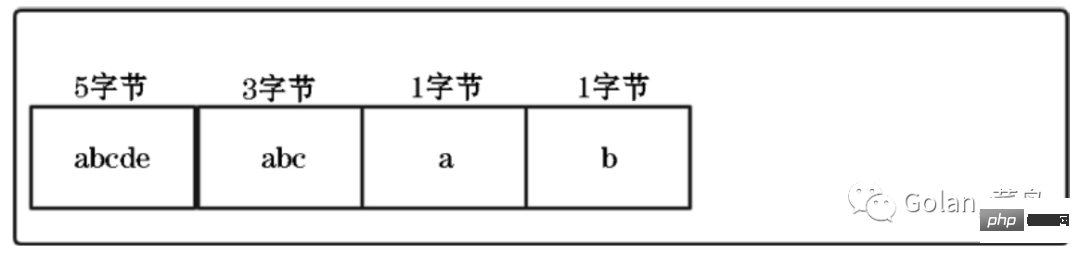
Wenn der Wert eine positive Zahl ist, stellt er die Länge der Ziplist auf dem QuicklistNode-Knoten dar. Wenn der Wert beispielsweise 5 ist, enthält die Ziplist jedes QuicklistNode-Knotens höchstens 5 Datenelemente Begrenzt entsprechend der Anzahl der Bytes. Mögliche Werte sind -1 bis -5.
| Wert | Bedeutung |
|---|---|
| -1 | Die maximale Größe des Ziplist-Knotens beträgt 4 KB |
| - 2 | Der maximale Ziplist-Knoten beträgt 8 KB. |
| -3 | -4 |
| -5 | Die maximale Größe des Ziplist-Knotens beträgt 64 KB. |
Das obige ist der detaillierte Inhalt vonRedis-Studiennotizen-Listen-Prinzip. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Häufig verwendete Datenbanksoftware
Häufig verwendete Datenbanksoftware
 Was sind In-Memory-Datenbanken?
Was sind In-Memory-Datenbanken?
 Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
 So verwenden Sie Redis als Cache-Server
So verwenden Sie Redis als Cache-Server
 Wie Redis die Datenkonsistenz löst
Wie Redis die Datenkonsistenz löst
 Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
 Welche Daten speichert der Redis-Cache im Allgemeinen?
Welche Daten speichert der Redis-Cache im Allgemeinen?
 Was sind die 8 Datentypen von Redis?
Was sind die 8 Datentypen von Redis?











![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



