

 Technologie-Peripheriegeräte
IT Industrie
Warum nutzt Alibaba ZooKeeper nicht für die Serviceerkennung?
Technologie-Peripheriegeräte
IT Industrie
Warum nutzt Alibaba ZooKeeper nicht für die Serviceerkennung?
Warum nutzt Alibaba ZooKeeper nicht für die Serviceerkennung?
Wenn wir am Scheideweg der Zukunft stehen, ist es oft interessant, auf den verlorenen Weg der Geschichte zurückzublicken, denn wir werden unabsichtlich verrückte Gedanken haben, wie zum Beispiel, was passiert wäre, wenn etwas früher passiert wäre, aber etwas anderes passiert wäre nicht passiert? Genau wie das, was passiert wäre, wenn Erzherzog Ferdinand und seine Frau, Thronfolger der österreichisch-ungarischen Monarchie, nicht von dem leidenschaftlichen serbischen Jugendlichen Princip erschossen worden wären, und was passiert wäre, wenn Qiu Laodao nicht durchgekommen wäre Niujia-Dorf?
Ende 2007 startete Taobao ein internes Rekonstruktionsprojekt namens „Colorful Stone“. Dieses Projekt wurde später zu Taobaos Servitisierung, Selbstforschung für den Vertrieb und trat aus der Internet-Middleware heraus des Systems und das Taobao-Dienstregistrierungszentrum ConfigServer wurde im selben Jahr geboren.
Um 2008 begann Yahoo, der ehemalige Internetriese, sein verteiltes Big-Data-Koordinationsprodukt ZooKeeper schrittweise öffentlich bekannt zu machen. Dieses Produkt bezog sich auf die von Google veröffentlichten Artikel zu Chubby und Paxos.
Im November 2010 entwickelte sich ZooKeeper von einem Unterprojekt von Apache Hadoop zu einem Spitzenprojekt von Apache und gab offiziell bekannt, dass ZooKeeper ein industrietaugliches, ausgereiftes und stabiles Produkt geworden ist.
Im Jahr 2011 musste Alibaba seine Beziehung zu Alibabas internen Systemen aufgeben und unterstützte später in China die Open-Source-Lösung Durch die Arbeit und Praxis aller Branchenteilnehmer hat die typische Servicelösung von Dubbo + ZooKeeper ZooKeeper als Registrierungszentrum berühmt gemacht.
Doppelte 11 im Jahr 2015, fast 8 Jahre sind vergangen, seit der ConfigServer-Dienst gestartet wurde. Alibabas interner „Serviceumfang“ überstieg mehrere Millionen, ebenso wie die Förderung der „Tausende Meilen entfernten“ IDC-Disaster-Recovery-Technologiestrategie usw. , was Alibaba gemeinsam dazu veranlasste, das interne zu öffnen Der Architektur-Upgrade-Pfad von ConfigServer 2.0 auf ConfigServer 3.0 wird erläutert.
Die Zeit rückt in Richtung 2018. Wie viele Menschen sind an der Schnittstelle von 10 Jahren bereit, ein wenig langsamer zu fahren und einen genaueren Blick auf den Bereich der Service-Erkennung zu werfen, wenn sie den sich ständig verändernden neuen Technologiekonzepten nachjagen? darüber nachgedacht oder darüber nachgedacht? Eine Frage:
Service Discovery, ist ZooKeeper wirklich die beste Wahl?
Rückblickend haben wir auch gelegentlich Mythen im Zusammenhang mit der Diensterkennung: Was wäre passiert, wenn ZooKeeper früher als unser HSF-Registrierungszentrum ConfigServer geboren worden wäre?
Werden wir einen Umweg machen, indem wir zuerst ZooKeeper verwenden und dann ZooKeeper hektisch umwandeln und patchen, um ihn an Alibabas serviceorientierte Szenarien und Bedürfnisse anzupassen?
Auf den Schultern von heute und unseren Vorgängern stehend, haben wir jedoch noch nie so deutlich erkannt wie heute, dass ZooKeeper im Bereich Service Discovery einfach nicht die beste Wahl ist, so wie wir alle es auch getan haben In diesem Jahr, Eureka-Kollege, und in diesem Artikel „Warum Sie ZooKeeper nicht für die Serviceerkennung verwenden sollten“, wird deutlich, warum Sie ZooKeeper nicht für die Serviceerkennung verwenden sollten!
Ich bin nicht allein auf meinem Weg.
Anforderungsanalyse des Registrierungszentrums und wichtige Überlegungen zum Design
Als nächstes kehren wir zur Bedarfsanalyse für die Serviceerkennung zurück, kombiniert mit Alibabas Praxis in Schlüsselszenarien, analysieren sie einzeln und diskutieren, warum ZooKeeper nicht das am besten geeignete Registrierungszentrum ist Lösung.
Ist das Registrierungszentrum ein CP- oder AP-System?
Ich glaube, dass die Leser mit den CAP- und BASE-Theorien vertraut sind und sie zu einem der Schlüsselprinzipien für den Aufbau verteilter Systeme und Internetanwendungen geworden sind Zu ihren Theorien gehen wir hier direkt auf die Analyse der Datenkonsistenz- und Verfügbarkeitsanforderungen des Registrierungszentrums ein:
Analyse der Datenkonsistenzanforderungen
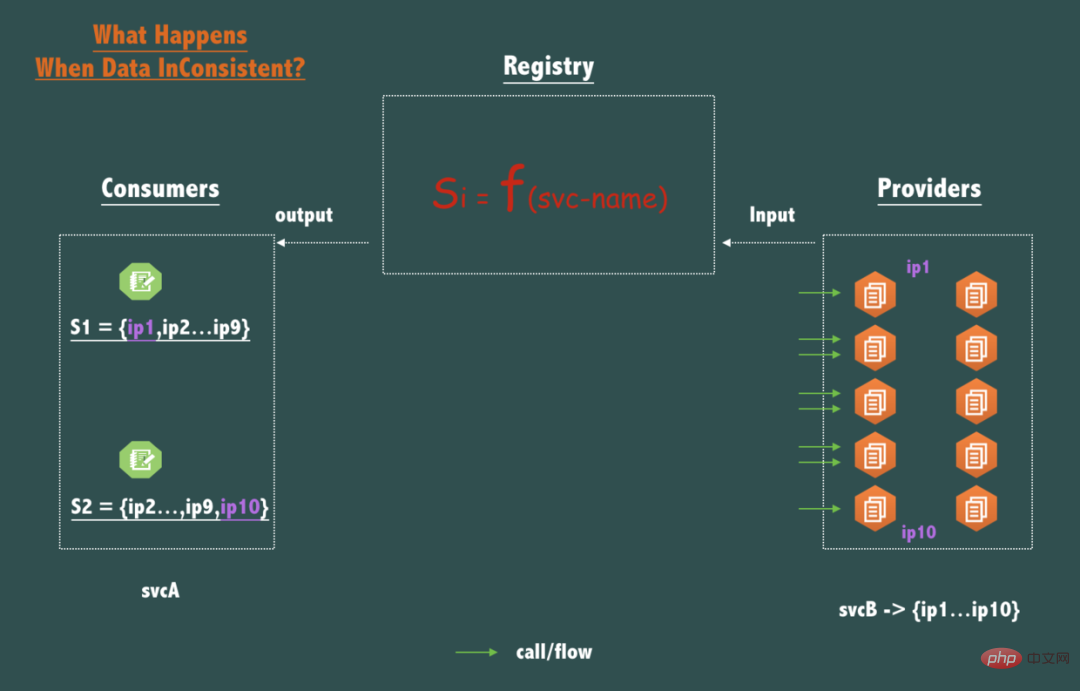
Die wesentlichste Funktion des Registrierungszentrums kann als angesehen werden eine Abfragefunktion Si = F(service-name),以 service-name 为查询参数,service-name 对应的服务的可用的 endpoints (ip:port) Die Liste ist der Rückgabewert
Hinweis: Service wird im folgenden Text mit svc abgekürzt.
Werfen wir zunächst einen Blick auf die Auswirkungen von Inkonsistenzen auf Schlüsseldaten endpoints (ip:port), d. copy/ Replica), wenn für denselben Dienstnamen svcB die beiden Abfragen der beiden Knoten des Aufrufers svcA inkonsistente Daten zurückgeben, zum Beispiel: S1 = { ip1,ip2,ip3...,ip9 }, S2 = { ip2 , ip3,....ip10}, Welche Auswirkungen hat diese Inkonsistenz?
Analyse der Partitionstoleranz und Verfügbarkeitsanforderungen
-
Als nächstes betrachten wir die Auswirkungen der Nichtverfügbarkeit des Registrierungszentrums auf Serviceanrufe im Fall einer Netzwerkpartition (Netzwerkpartition), d. h. wenn A in CAP ist ist nicht zufrieden. Stellen Sie sich eine typische ZooKeeper-Bereitstellungsstruktur mit drei Computerräumen für die Notfallwiederherstellung und 5 Knoten (d. h. 2-2-1-Struktur) vor, wie unten gezeigt:
Wenn eine Netzwerkpartition in Computerraum 3, also Computer, auftritt Raum 3 ist Das Netzwerk ist zu einer isolierten Insel geworden. Wir wissen, dass Knoten ZK5 nicht beschreibbar ist, obwohl der gesamte ZooKeeper-Dienst verfügbar ist, da der Leader nicht kontaktiert werden kann.
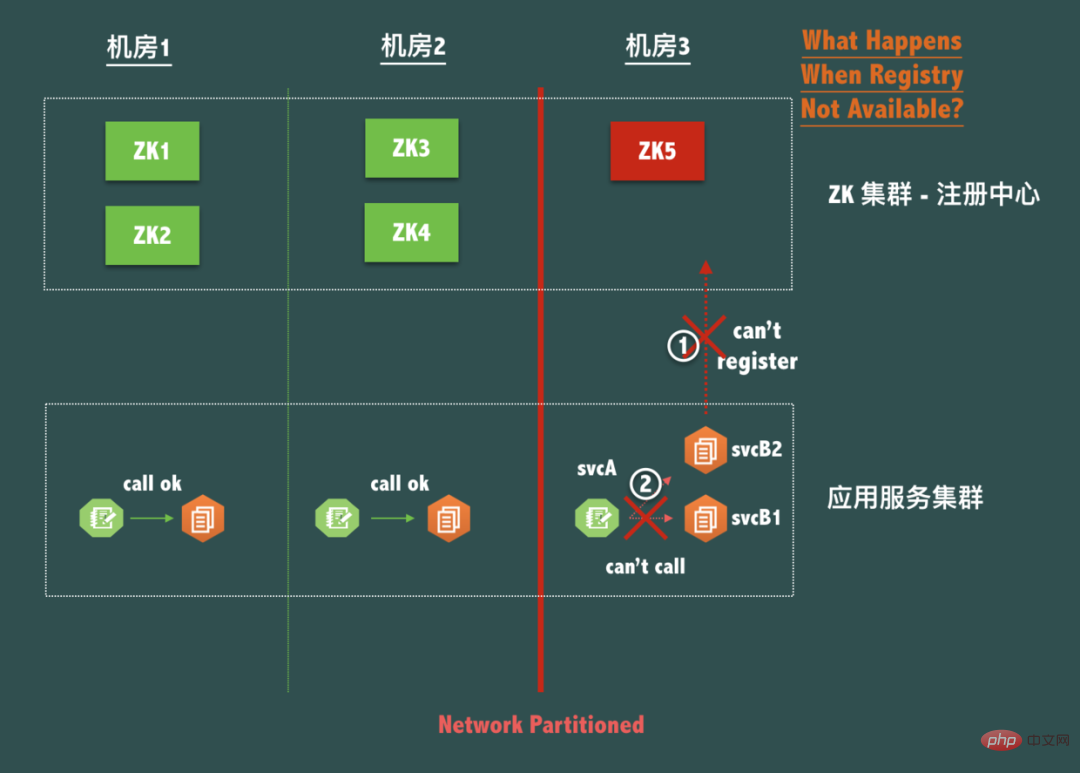
Da nun das Registrierungszentrum selbst die Verfügbarkeit aufgegeben hat, um die Datenkonsistenz (C) unter Split-Brain (P) sicherzustellen, können Dienste im selben Computerraum nicht aufgerufen werden. Dies ist absolut nicht zulässig! Man kann sagen, dass das Registrierungszentrum in der Praxis die Konnektivität zwischen Diensten aus keinem eigenen Grund zerstören kann. Dies ist ein ehernes Gesetz, dem das Design des Registrierungszentrums folgen sollte! Wir werden die Notfallwiederherstellung des Registrierungscenter-Clients später weiter besprechen.
Berücksichtigen wir gleichzeitig die Dateninkonsistenz in diesem Fall. Wenn die Computerräume 1, 2 und 3 alle zu isolierten Inseln werden, erhält svcA in jedem Computerraum nur die IP-Liste von svcB in diesem Computerraum Das heißt, die IP-Listendaten von svcB in jedem Computerraum sind völlig inkonsistent. Welche Auswirkungen hat das?
Tatsächlich hat es keine großen Auswirkungen, aber in diesem Fall werden sie alle zu Anrufen aus demselben Computerraum. Wenn wir das Registrierungszentrum entwerfen, nutzen wir manchmal sogar aktiv die Daten im Registrierungszentrum, um inkonsistent zu sein Um die Anwendung proaktiv zu unterstützen, erreichen Sie Anrufe im selben Computerraum und optimieren so die Wirkung der Service-Anrufverbindung RT!
Anhand unserer obigen Erklärung können wir erkennen, dass im CAP-Kompromiss die Verfügbarkeit des Registrierungszentrums wertvoller ist als die starke Konsistenz der Daten, sodass das Gesamtdesign eher auf AP als auf CP-Daten ausgerichtet sein sollte Die Inkonsistenz liegt im akzeptablen Bereich, während P das Löschen von A völlig gegen den Grundsatz verstößt, dass das Registrierungszentrum die Konnektivität des Dienstes selbst aus keinem eigenen Grund zerstören kann.
Serviceumfang, Kapazität, Servicekonnektivität
Wie groß ist der Umfang der „Microservices“ Ihres Unternehmens? Hunderte von Microservices? Hunderte von Knoten bereitgestellt? Was ist mit 3 Jahren später? Das Internet ist ein Ort, an dem Wunder geschehen. Vielleicht wird Ihr „Dienst“ über Nacht zu einem bekannten Namen, Ihr Datenverkehr verdoppelt sich und Ihre Größe verdoppelt sich!
Wenn der Serviceumfang des Rechenzentrums eine bestimmte Zahl überschreitet (Serviceumfang = F{Anzahl der Service-Pubs, Anzahl der Service-Subs}), wird ZooKeeper als Registrierungszentrum bald überfordert sein, wie der Esel im Bild unten

Tatsächlich sollte es so sein: Wenn ZooKeeper an der richtigen Stelle verwendet wird, dh in Szenarien mit grobkörniger verteilter Sperrung und verteilter Koordination, sind die von ZooKeeper unterstützten TPS und die Anzahl der Verbindungen ausreichend, da diese Szenarien keine hohen Anforderungen stellen Skalierbarkeit und Kapazität von ZooKeeper.
Aber in Serviceerkennungs- und Gesundheitsüberwachungsszenarien ist es mit zunehmender Servicegröße egal, ob es sich um Schreibanforderungen handelt, die durch die Dienstregistrierung verursacht werden, wenn Anwendungen häufig freigegeben werden, oder um Schreibanforderungen, die durch das Bürsten des Dienstgesundheitsstatus auf Millisekundenebene verursacht werden, oder wenn alle Maschinen vorhanden sind oder Container im gesamten Rechenzentrum haben lange Verbindungen zum Registrierungszentrum, ZooKeeper wird dem damit verbundenen Verbindungsdruck bald nicht mehr gewachsen sein und kann das Problem der horizontalen Skalierbarkeit nicht durch Hinzufügen von Knoten lösen.
Wenn Sie das Problem des Service-Skalenwachstums basierend auf ZooKeeper lösen möchten, können Sie eine praktische Methode in Betracht ziehen, indem Sie Wege finden, das Geschäft zu ordnen, die Geschäftsdomäne vertikal zu unterteilen und sie in mehrere ZooKeeper-Registrierungszentren aufzuteilen Ist es für die Service-Plattform-Organisationsgruppe als universelles System aufgrund unzureichender Service-Fähigkeiten wirklich möglich, das Geschäft nach dem technischen Staffelstab aufzuteilen und zu verwalten?
Und dies verstößt gegen die Tatsache, dass das Registrierungszentrum selbst (unzureichende Kapazität) die Konnektivität des Dienstes zerstört. Um ein einfaches Beispiel zu nennen: 1 Suchunternehmen, 1 Kartenunternehmen, 1 großes Unterhaltungsunternehmen und 1 Spieleunternehmen schließen sie sich gegenseitig aus? Vielleicht ist heute ja so, aber was ist mit morgen, was ist mit einem Jahr, was ist mit zehn Jahren? Wer weiß, dass in Zukunft mehrere Geschäftsfelder erschlossen werden, um seltsame Geschäftsinnovationen zu schaffen? Als Basisdienst kann das Registrierungszentrum die Zukunft nicht vorhersagen und schon gar nicht die Nachfrage des Unternehmensdienstes nach zukünftiger inhärenter Konnektivität behindern.
Benötigt das Registrierungscenter dauerhafte Speicher- und Transaktionsprotokolle?
Brauchen oder nicht.
Wir wissen, dass das ZAB-Protokoll von ZooKeeper für jede Schreibanforderung weiterhin ein Transaktionsprotokoll auf jedem ZooKeeper-Knoten schreibt und gleichzeitig die Speicherdaten regelmäßig auf die Festplatte spiegelt (Snapshot), um die Konsistenz und Haltbarkeit sicherzustellen Dies ist eine sehr gute Funktion, ebenso wie die Datenwiederherstellung nach einem Absturz. Allerdings müssen wir uns fragen, ob die Kerndaten – die Echtzeit-Adressliste fehlerfreier Dienste – wirklich Datenpersistenz benötigen. ?
Für diese Daten lautet die Antwort nein.
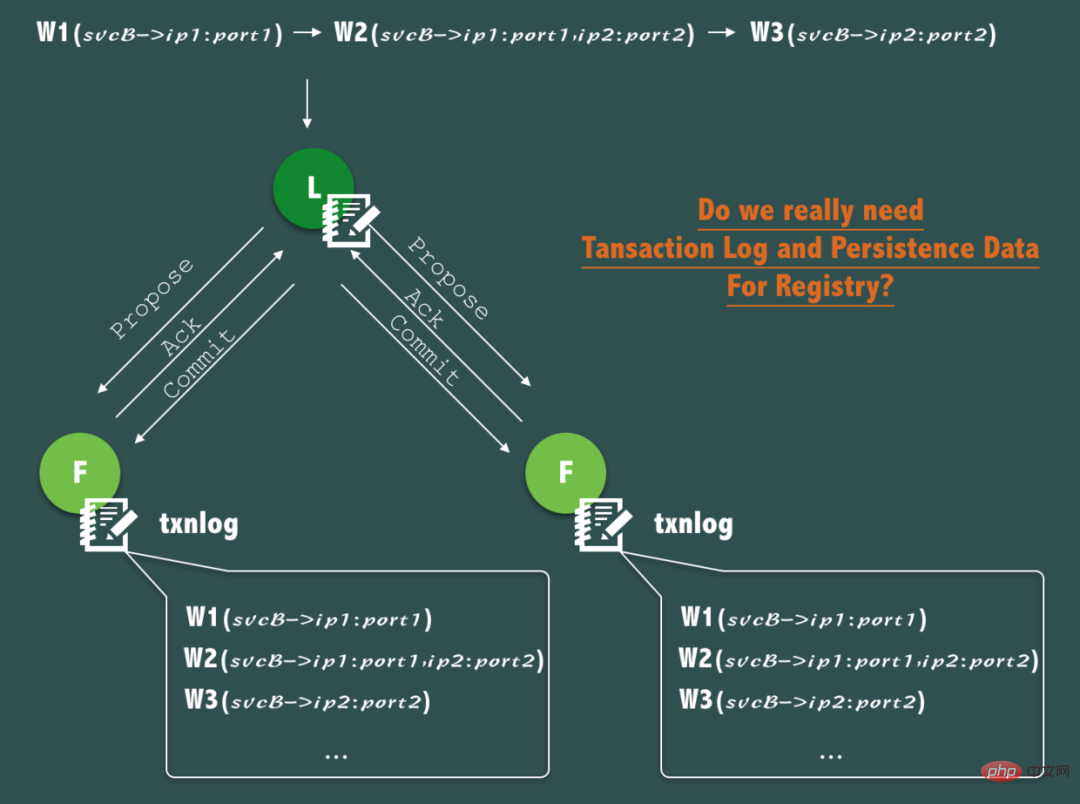
Wie in der Abbildung oben gezeigt, ist dieser Vorgang dreimal aufgetreten, wenn svcB den Registrierungsdienst (IP1), die Erweiterung auf 2 Knoten (IP1, IP2) und die Schrumpfung aufgrund von Ausfallzeiten (IP1-Ausfallzeit) durchlaufen hat Operationen für ZooKeeper.
Bei sorgfältiger Analyse ist es jedoch eigentlich von geringer Bedeutung, diesen Änderungsprozess kontinuierlich über Transaktionsprotokolle aufzuzeichnen, da sich der Initiator des Serviceanrufs bei der Serviceerkennung mehr um die Echtzeit-Adressliste und den Echtzeit-Gesundheitsstatus von kümmert Der Dienst, den er anrufen möchte, kümmert sich bei jedem Anruf nicht um die Liste der historischen Dienstadressen und den früheren Gesundheitszustand des anzurufenden Dienstes.
Aber warum ist es notwendig? Denn ein vollständig produktionsbereites Registrierungscenter speichert neben der Echtzeit-Adressliste und dem Echtzeit-Gesundheitsstatus des Dienstes auch einige Metadateninformationen des Dienstes, wie z. B. die Dienstversion , Gruppierung, Metainformationen wie das Rechenzentrum, in dem es sich befindet, Gewicht, Authentifizierungsrichtlinieninformationen, Service-Label usw. Diese Daten müssen dauerhaft gespeichert werden, und das Registrierungszentrum sollte die Möglichkeit bieten, diese Metainformationen abzurufen.
Service Health Check
Bei Verwendung von ZooKeeper als Service-Registrierungscenter verwendet die Gesundheitserkennung des Dienstes häufig den Session Active Track-Mechanismus von ZooKeeper und den Mechanismus in Kombination mit Ephemeral ZNode. Einfach ausgedrückt ist die Gesundheitsüberwachung des Dienstes an ZooKeeper gebunden . Überwachung des Sitzungszustands oder Bindung an die TCP-Long-Link-Aktivitätserkennung.
Dies kann in vielen Fällen auch zu schwerwiegenden Problemen führen. Wenn die Erkennung der TCP-Long-Link-Aktivität zwischen ZK und dem Dienstanbietercomputer normal ist, ist der Dienst dann fehlerfrei? Die Antwort ist natürlich nein! Das Registrierungszentrum sollte eine umfassendere Gesundheitsüberwachungslösung bereitstellen, und die Logik, ob der Dienst fehlerfrei ist oder nicht, sollte dem Dienstanbieter überlassen bleiben, anstatt ihn zu einem einheitlichen TCP-Aktivitätstest zu machen!
Eines der grundlegenden Designprinzipien der Gesundheitserkennung besteht darin, den wahren Gesundheitszustand des Dienstes selbst so wahrheitsgetreu wie möglich zurückzugeben. Andernfalls ist ein Ergebnis der Gesundheitszustandsbestimmung, das von den Dienstanrufern nicht geglaubt wird, schlimmer als keine Gesundheitserkennung.
Überlegungen zur Notfallwiederherstellung für das Registrierungszentrum
Wie bereits erwähnt: In der Praxis kann das Registrierungszentrum die Konnektivität zwischen Diensten aus keinem eigenen Grund zerstören, daher ist dies im Hinblick auf die Verfügbarkeit ein wesentliches Problem Registrierung Das Zentrum (Registrierung) selbst ist vollständig ausgefallen. Sollte der Link svcA, der svcB aufruft, betroffen sein?
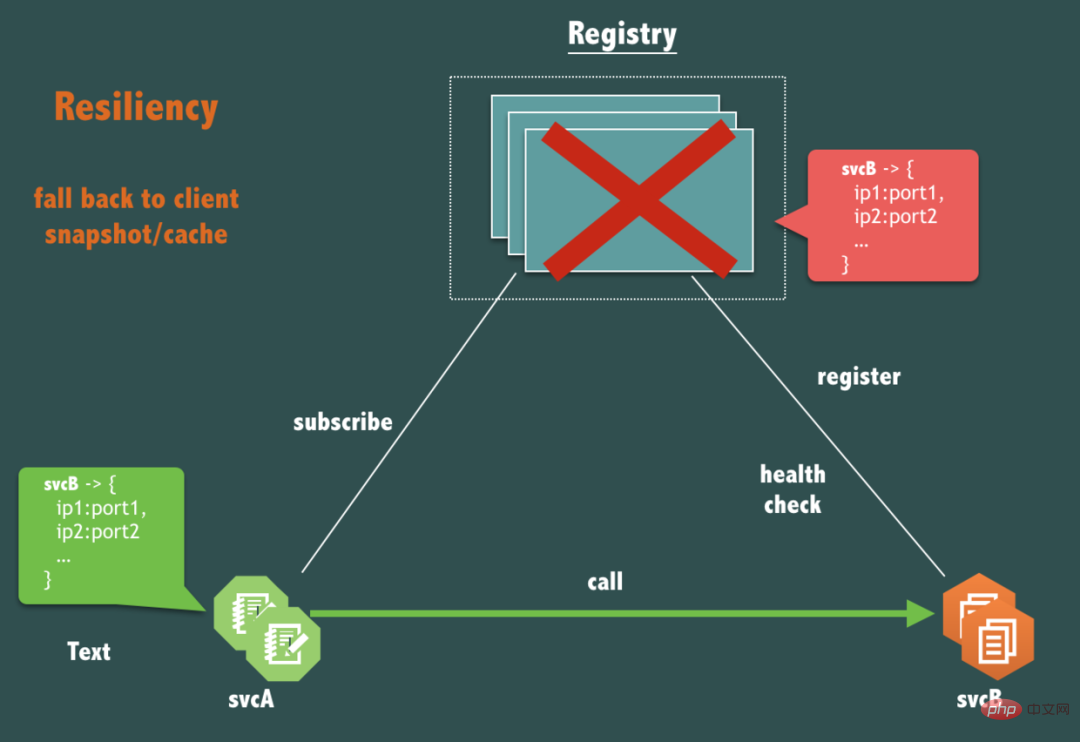
Ja, es sollte nicht betroffen sein.
Der Service-Call-Link (Request-Response-Flow) sollte schwach vom Registrierungscenter abhängig sein. Er darf sich nur dann auf das Registrierungscenter verlassen, wenn dies für die Servicefreigabe, die Online- und Offline-Maschine, die Serviceerweiterung und -verkürzung usw. erforderlich ist.
Dafür muss das Registrierungscenter den von ihm bereitgestellten Client sorgfältig entwerfen. Der Client sollte über Möglichkeiten zur Notfallwiederherstellung verfügen, wenn der Registrierungscenter-Dienst vollständig nicht verfügbar ist. Das Entwerfen eines Client-Cache-Datenmechanismus (wir nennen ihn Client-Snapshot) ist in Ordnung . ein wirksames Mittel. Darüber hinaus muss auch der Gesundheitskontrollmechanismus des Registrierungszentrums sorgfältig ausgelegt sein, damit es in dieser Situation nicht zu Situationen wie einer Entleerung kommt.
Der native Client von ZooKeeper verfügt nicht über diese Funktion. Wenn wir also ZooKeeper zur Implementierung des Registrierungscenters verwenden, müssen wir uns fragen, ob alle Service-Call-Links in Ihrer Produktion davon unberührt bleiben, wenn alle ZooKeeper-Knoten getötet werden. Und zu diesem Punkt sollten regelmäßig Fehlerübungen durchgeführt werden.
Haben Sie einen ZooKeeper-Experten, auf den Sie sich verlassen können?
ZooKeeper scheint ein sehr einfaches Produkt zu sein, es ist jedoch nicht selbstverständlich, es im großen Maßstab einzusetzen und in der Produktion gut einzusetzen. Wenn Sie sich für die Einführung von ZooKeeper in der Produktion entscheiden, sollten Sie darauf vorbereitet sein, jederzeit Hilfe von den technischen Experten von ZooKeeper in Anspruch zu nehmen. Die typischsten Erscheinungsformen sind in zwei Aspekten:
-
Client-/Sitzungszustandsmaschine, die schwer zu beherrschen ist
Der native Client von ZooKeeper ist definitiv nicht einfach zu verwenden, aber tatsächlich ist es nicht einfach, das Interaktionsprotokoll zwischen ZooKeeper-Client und Server vollständig zu verstehen Die Client-/Sitzungszustandsmaschine (Bild unten) ist nicht so einfach und klar:
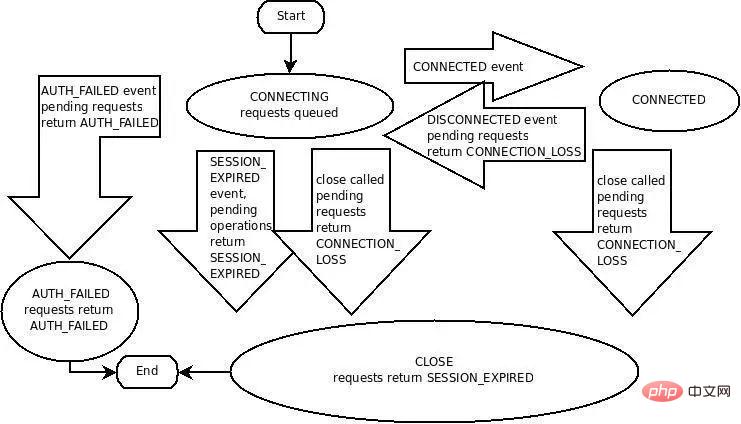
Aber die auf ZooKeeper basierende Service-Discovery-Lösung basiert auf der langen Verbindungs-/Sitzungsverwaltung, dem kurzlebigen ZNode, der Ereignis- und Benachrichtigungsfunktion. Um ZooKeeper für die Diensterkennung nutzen zu können, müssen Sie diese Kernmechanismen und -prinzipien verstehen. Das macht Sie manchmal irritiert ? Und wenn Sie das alles verstehen und keine Fallstricke begehen, herzlichen Glückwunsch, Sie sind ein technischer Experte von ZooKeeper geworden.
Unerträgliche Ausnahmebehandlung
Als wir ZooKeeper mit den internen Anwendungen von Alibaba verbanden, gab es ein WIKI mit dem Titel „Was Sie über die ZooKeeper-Anwendungsintegration wissen müssen“, in dem die Ausnahmebehandlung wie folgt besprochen wurde:
Wenn Sie was auswählen möchten Was müssen Anwendungsentwickler bei der Verwendung von ZooKeeper am deutlichsten wissen? Basierend auf unseren bisherigen Support-Erfahrungen muss es sich also um eine Ausnahmebehandlung handeln.
Wenn glücklicherweise alles (Host, Festplatte, Netzwerk usw.) ordnungsgemäß funktioniert, laufen die Anwendung und ZooKeeper möglicherweise auch gut, aber leider werden wir im Laufe des Tages mit verschiedenen Überraschungen konfrontiert. Und dies folgt Murphys Gesetz: Unerwartete schlimme Dinge passieren immer passieren, wenn Sie sich am meisten Sorgen um sie machen.
Stellen Sie daher sicher, dass Sie die Ausnahmen und Fehler, die in ZooKeeper in einigen Szenarien auftreten können, sorgfältig verstehen, stellen Sie sicher, dass Sie diese Ausnahmen und Fehler richtig verstehen und wissen, wie Ihre Anwendung diese Situationen richtig handhabt.
ConnectionLossException und Disconnected-Ereignis
Einfach ausgedrückt ist dies eine Ausnahme, die in derselben ZooKeeper-Sitzung wiederhergestellt werden kann (wiederherstellbar), aber der Anwendungsentwickler muss dafür verantwortlich sein, die Anwendung in den richtigen Zustand wiederherzustellen.
Es gibt viele Gründe für diese Ausnahme, z. B. eine Netzwerkunterbrechung zwischen dem Anwendungscomputer und dem ZooKeeper-Knoten, Ausfallzeiten des ZooKeeper-Knotens, eine zu lange serverseitige vollständige GC-Zeit oder sogar ein Absturz Ihres Anwendungsprozesses und die vollständige GC-Zeit des Anwendungsprozesses ist zu lang. Eine Wiederherstellung ist später möglich.
Um diese Ausnahme zu verstehen, müssen Sie ein typisches Problem in verteilten Anwendungen verstehen, wie unten gezeigt: 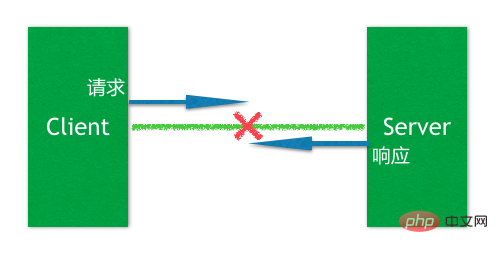
Bei einer typischen Client-Anfrage und Server-Antwort, wenn die lange Verbindung zwischen ihnen unterbrochen wird, wenn der Client dieses Flash-Ereignis erkennt , es wird in einer peinlichen Situation sein, das heißt, es kann den Status der nahegelegenen Anfrage nicht ermitteln, als das Ereignis eintrat. Hat der Server diese Anfrage empfangen? Wurde es bearbeitet? Da dies nicht ermittelt werden kann, erscheint bei der erneuten Verbindung des Clients mit dem Server ein Fragezeichen, ob die Anfrage erneut versucht werden soll (Retry).
Bei der Behandlung des Verbindungstrennungsereignisses muss der Anwendungsentwickler also wissen, um welche Anforderung es sich in der Nähe der Unterbrechung handelt (dies ist oft schwer zu beurteilen), ob die Anforderung idempotent ist und für Geschäftsanforderungen bei der serverseitigen Dienstverarbeitung die Semantik von „Nur einmal verarbeiten“, „Höchstens einmal verarbeiten“ und „Mindestens einmal verarbeiten“ sollten selektiv sein und erwartet werden.
Wenn die Anwendung beispielsweise eine ConnectionLossException empfängt und die vorherige Anforderung ein Erstellungsvorgang war, besteht eine mögliche Wiederherstellungslogik für die Anwendung darin, festzustellen, ob der durch die vorherige Anforderung erstellte Knoten bereits vorhanden ist Erstellen Sie es nicht, wenn es existiert, andernfalls erstellen Sie es.
Wenn die Anwendung beispielsweise „existent Watch“ verwendet, um das Erstellungsereignis eines nicht vorhandenen Knotens zu überwachen, kann es während der ConnectionLossException zu der Situation kommen, dass während dieser Unterbrechungsperiode möglicherweise andere Clientprozesse erstellt wurden Wenn der Knoten gelöscht wurde, wird für die aktuelle Anwendung das Erstellungsereignis des betreffenden Knotens verpasst. Welche Auswirkungen hat dieser Fehler auf die Anwendung? Ist es tolerierbar oder inakzeptabel? Anwendungsentwickler müssen es gemäß der Geschäftssemantik auswerten und verarbeiten.
SessionExpiredException und SessionExpired-Ereignis
Session-Timeout ist eine nicht behebbare Ausnahme. Das bedeutet, dass die Anwendung den Anwendungsstatus in derselben Sitzung nicht wiederherstellen kann und eine neue Sitzung erstellen muss. Der mit der alten Sitzung verknüpfte temporäre Knoten ist möglicherweise ebenfalls abgelaufen, und die Sperre, die er besitzt, ist möglicherweise ebenfalls abgelaufen. ...
Als Alibabas Freunde versuchten, ZooKeeper selbst für die Serviceerkennung zu nutzen, fassten sie einmal einen Erfahrungsaustausch in unserem Intranet-Technologieforum zusammen

. Der Artikel erwähnte treffend:
... Viele mögliche Fallen wurden während des Codierungsprozesses entdeckt. Grob geschätzt werden mehr als 80 % der Leute, die zk zum ersten Mal verwenden, in Fallen geraten, einige Fallstricke sind relativ versteckt. Sie werden nur angezeigt, wenn Netzwerkprobleme oder ungewöhnliche Szenarien vorliegen, und sind möglicherweise längere Zeit nicht sichtbar ...
Gehen Sie nach links, gehen Sie nach rechts
Ist Alibaba nicht völlig kostenlos? Nicht wirklich.
Jeder, der mit dem technischen System von Alibaba vertraut ist, weiß, dass Alibaba tatsächlich den größten ZooKeeper-Cluster in China mit einer Gesamtgröße von fast tausend ZooKeeper-Dienstknoten unterhält.
Gleichzeitig verwaltet die Alibaba-Middleware auch einen Codezweig von ZooKeeper, TaoKeeper, der auf die Produktion in großem Maßstab ausgerichtet ist, eine hohe Verfügbarkeit aufweist und auf der Grundlage unserer Praxis, ZooKeeper in verschiedenen Unternehmen einzusetzen, einfacher zu überwachen und zu bedienen ist Linien und Produktion in den letzten 10 Jahren. Wenn Sie ZooKeeper mit einem Ausdruck bewerten, dann denken wir, dass ZooKeeper „Der König der Koordination für Big Data“ sein sollte!
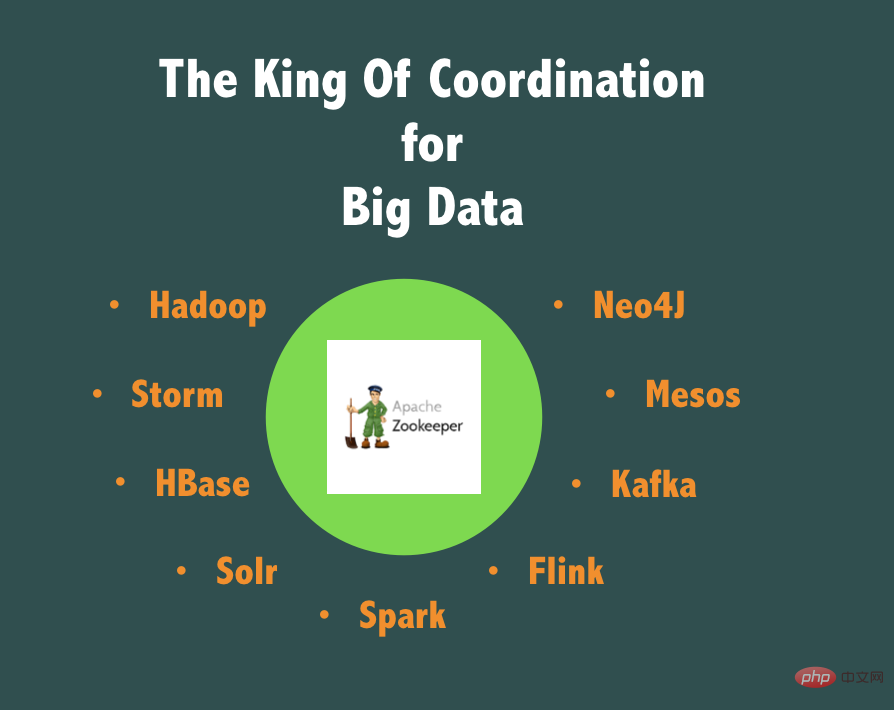
Es spielt eine unersetzliche Rolle in Szenarien wie grobkörnigen verteilten Sperren, verteilter Masterauswahl, Aktiv-Standby-Hochverfügbarkeits-Switching usw., die keine hohe TPS-Unterstützung erfordern, und diese Anforderungen konzentrieren sich häufig auf Big Data , Offline-Aufgaben usw. Im Geschäftsfeld ist es aufgrund des Big-Data-Bereichs wichtig, Datensätze zu segmentieren. Meistens werden diese Datensätze jedoch von Aufgaben und mehreren Prozessen/Threads parallel verarbeitet Es gibt immer einige Punkte, an denen diese Aufgaben und Prozesse koordiniert werden müssen. Zu diesem Zeitpunkt spielt ZooKeeper eine große Rolle.
Allerdings gibt es in der Transaktionsverknüpfung des Transaktionsszenarios natürliche Mängel beim Zugriff auf Hauptgeschäftsdaten, bei der Erkennung umfangreicher Dienste, bei der umfassenden Gesundheitsüberwachung usw. Wir sollten unser Bestes geben, um die Einführung von ZooKeeper in diesen Szenarien zu vermeiden. In der Praxis von Alibaba müssen Anwendungen eine strenge Bewertung der Szenarien, Kapazität und SLA-Anforderungen durchführen, wenn sie sich für die Verwendung von ZooKeeper bewerben.
Sie können ZooKeeper also verwenden, aber gehen Sie nach links für Big Data, nach rechts für Transaktionen, nach links für verteilte Koordination und nach rechts für Service Discovery.
Fazit
Vielen Dank für Ihre Geduld beim Lesen. An dieser Stelle glaube ich, dass Sie verstanden haben, dass wir diesen Artikel nicht schreiben, um ZooKeeper vollständig zu leugnen, sondern nur auf der Grundlage der groß angelegten Servitisierungsproduktion von Alibaba in der Vergangenheit In der Praxis werden wir unsere Erfahrungen und Erkenntnisse bei der Gestaltung und Nutzung von Service-Erkennungs- und Registrierungszentren zusammenfassen. Wir hoffen, die Branche zu inspirieren und ihnen zu helfen, wie sie ZooKeeper besser nutzen und ihre eigenen Service-Registrierungszentren besser gestalten können. Schließlich führen alle Wege nach Rom, und ich hoffe aufrichtig, dass Ihr Registrierungszentrum direkt in Rom entsteht.
Das obige ist der detaillierte Inhalt vonWarum nutzt Alibaba ZooKeeper nicht für die Serviceerkennung?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undress AI Tool
Ausziehbilder kostenlos

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Verwendung von ZooKeeper für die verteilte Sperrenverarbeitung in der Java-API-Entwicklung
Jun 17, 2023 pm 10:36 PM
Verwendung von ZooKeeper für die verteilte Sperrenverarbeitung in der Java-API-Entwicklung
Jun 17, 2023 pm 10:36 PM
Da sich moderne Anwendungen ständig weiterentwickeln und der Bedarf an Hochverfügbarkeit und Parallelität wächst, werden verteilte Systemarchitekturen immer häufiger eingesetzt. In einem verteilten System laufen mehrere Prozesse oder Knoten gleichzeitig und erledigen Aufgaben gemeinsam, wobei die Synchronisierung zwischen Prozessen besonders wichtig wird. Da viele Knoten in einer verteilten Umgebung gleichzeitig auf gemeinsam genutzte Ressourcen zugreifen können, ist der Umgang mit Parallelitäts- und Synchronisierungsproblemen zu einer wichtigen Aufgabe in einem verteilten System geworden. In dieser Hinsicht hat sich ZooKeeper zu einer sehr beliebten Lösung entwickelt. ZooKee
 Verwendung von ZooKeeper und Curator für die verteilte Koordination und Verwaltung in Beego
Jun 22, 2023 pm 09:27 PM
Verwendung von ZooKeeper und Curator für die verteilte Koordination und Verwaltung in Beego
Jun 22, 2023 pm 09:27 PM
Mit der rasanten Entwicklung des Internets sind verteilte Systeme zu einer der Infrastrukturen in vielen Unternehmen und Organisationen geworden. Damit ein verteiltes System ordnungsgemäß funktioniert, muss es koordiniert und verwaltet werden. In dieser Hinsicht sind ZooKeeper und Curator zwei lohnenswerte Tools. ZooKeeper ist ein sehr beliebter verteilter Koordinationsdienst, der uns dabei helfen kann, den Status und die Daten zwischen Knoten in einem Cluster zu koordinieren. Curator ist eine Kapselung von ZooKeeper
 Sollte ich Redis oder Zookeeper für verteilte Sperren verwenden?
Aug 22, 2023 pm 03:48 PM
Sollte ich Redis oder Zookeeper für verteilte Sperren verwenden?
Aug 22, 2023 pm 03:48 PM
Verteilte Sperren werden normalerweise auf folgende Weise implementiert: Datenbank, Cache (z. B. Redis), Zookeeper usw. In der tatsächlichen Entwicklung werden am häufigsten Redis und Zookeeper verwendet, daher wird in diesem Artikel nur auf diese beiden eingegangen.
 Warum nutzt Alibaba ZooKeeper nicht für die Serviceerkennung?
Jul 26, 2023 pm 05:19 PM
Warum nutzt Alibaba ZooKeeper nicht für die Serviceerkennung?
Jul 26, 2023 pm 05:19 PM
Wir schreiben diesen Artikel nicht, um ZooKeeper vollständig zu leugnen, sondern um unsere Erfahrungen und Lehren bei der Gestaltung und Nutzung von Service Discovery- und Registrierungszentren basierend auf Alibabas Produktionspraktiken bei der groß angelegten Servitisierung in den letzten 10 Jahren zusammenzufassen Helfen Sie der Branche, ZooKeeper besser zu nutzen und ihre eigenen Service-Registrierungszentren besser zu gestalten.
 Wie verwende ich die Zookeeper-Erweiterung von PHP?
Jun 02, 2023 pm 09:01 PM
Wie verwende ich die Zookeeper-Erweiterung von PHP?
Jun 02, 2023 pm 09:01 PM
PHP ist eine sehr beliebte Programmiersprache, die häufig in Webanwendungen und serverseitiger Entwicklung verwendet wird. Zookeeper ist ein verteilter Koordinierungsdienst zur Verwaltung, Koordinierung und Überwachung verteilter Anwendungen und Dienste. Die Verwendung von Zookeeper in PHP-Anwendungen kann die Leistung und Zuverlässigkeit Ihrer Anwendung verbessern. In diesem Artikel wird die Verwendung der Zookeeper-Erweiterung für PHP vorgestellt. 1. Installieren Sie die Zookeeper-Erweiterung. Um die Zookeeper-Erweiterung verwenden zu können, müssen Sie Zookeeper installieren.
 Verwendung von ZooKeeper zur Implementierung der Dienstregistrierung und -erkennung in Beego
Jun 22, 2023 am 08:21 AM
Verwendung von ZooKeeper zur Implementierung der Dienstregistrierung und -erkennung in Beego
Jun 22, 2023 am 08:21 AM
In der Microservice-Architektur ist die Registrierung und Erkennung von Diensten ein sehr wichtiges Thema. Um dieses Problem zu lösen, können wir ZooKeeper als Service-Registrierungscenter verwenden. In diesem Artikel stellen wir vor, wie Sie ZooKeeper im Beego-Framework verwenden, um die Registrierung und Erkennung von Diensten zu implementieren. 1. Einführung in ZooKeeper ZooKeeper ist ein verteilter Open-Source-Koordinierungsdienst. Es ist eines der Unterprojekte von Apache Hadoop. Die Hauptrolle von ZooKeeper
 So integrieren Sie Dubbo Zookeeper in SpringBoot
May 17, 2023 pm 02:16 PM
So integrieren Sie Dubbo Zookeeper in SpringBoot
May 17, 2023 pm 02:16 PM
dockerpullzookeeperdockerrun --namezk01-p2181:2181--restartalways-d2e30cac00aca zeigt an, dass zookeeper Zookeeper und Dubbo erfolgreich gestartet hat. • ZooKeeperZooKeeper ist ein verteilter Open-Source-Koordinierungsdienst für verteilte Anwendungen. Es handelt sich um eine Software, die konsistente Dienste für verteilte Anwendungen bereitstellt. Zu den bereitgestellten Funktionen gehören: Konfigurationswartung, Domänennamendienste, verteilte Synchronisierung, Gruppendienste usw. DubboDubbo ist Alibabas Open-Source-Framework für verteilte Dienste. Sein größtes Merkmal ist seine mehrschichtige Struktur.
 ZooKeeper-Vergleich der Redis-Implementierung verteilter Sperren
Jun 20, 2023 pm 03:19 PM
ZooKeeper-Vergleich der Redis-Implementierung verteilter Sperren
Jun 20, 2023 pm 03:19 PM
Mit der rasanten Entwicklung der Internet-Technologie sind verteilte Systeme in modernen Anwendungen weit verbreitet, insbesondere in großen Internetunternehmen. In einem verteilten System ist es jedoch sehr schwierig, die Konsistenz zwischen Knoten aufrechtzuerhalten. Daher ist der verteilte Sperrmechanismus zu einer der Grundlagen zur Lösung dieses Problems geworden. Bei der Implementierung verteilter Sperren sind Redis und ZooKeeper beliebte Tools. In diesem Artikel werden sie verglichen und analysiert. Redis implementiert verteilte Sperren. Redis ist ein Open-Source-Speicherdatenspeicher
