


Der im Dezember 2020 veröffentlichte CPM-1 ist das erste chinesische Großmodell in China; der im September 2022 veröffentlichte CPM-Ant kann den vollen Parameter-Feinabstimmungseffekt durch eine Feinabstimmung von nur 0,06 % der veröffentlichten Parameter erreichen im Mai 2023 ist Chinesisch Das erste Open-Source-Modell für suchbasierte Fragenbeantwortung. Das CPM-Bee 10-Milliarden-Großmodell ist das neueste vom Team veröffentlichte Basismodell. Seine Chinesischkenntnisse stehen an der Spitze der maßgeblichen Liste ZeroCLUE, und seine Englischkenntnisse sind gleichauf mit LLaMA.
Die CPM-Serie großer Modelle hat wiederholt bahnbrechende Erfolge erzielt und inländische große Modelle an die Spitze geführt, und das kürzlich veröffentlichte VisCPM ist ein weiterer Beweis! VisCPM ist eine multimodale große Modellreihe, die gemeinsam von Wallface Intelligence, dem Tsinghua University NLP Laboratory und Zhihu in OpenBMB bereitgestellt wird. Das VisCPM-Chat-Modell unterstützt zweisprachige multimodale Dialogfunktionen in Chinesisch und Englisch, und das VisCPM-Paint-Modell unterstützt Die Auswertung zeigt, dass VisCPM das beste Niveau unter den chinesischen multimodalen Open-Source-Modellen erreicht.
VisCPM wird auf der Grundlage des zig Milliarden Parameter-Basismodells CPM-Bee trainiert und integriert den visuellen Encoder (Q-Former) und den visuellen Decoder (Diffusion-UNet), um die Eingabe und Ausgabe visueller Signale zu unterstützen. Dank CPM-Bee Mit den hervorragenden zweisprachigen Funktionen der Basis kann VisCPM mit englischen multimodalen Daten vorab trainiert und verallgemeinert werden, um hervorragende chinesische multimodale Funktionen zu erzielen Schauen Sie sich VisCPM-Chat im Detail an. Wo ist die Kuh mit VisCPM-Paint? VisCPM-Chat unterstützt die bildorientierte zweisprachige Verarbeitung in Chinesisch und Englisch
Das Modell verwendet Q-Former als visuellen Encoder, verwendet CPM-Bee (10B) als Basismodell für die Sprachinteraktion und verbindet visuelle Elemente und Sprachmodelle durch Sprachmodellierungs-Trainingsziele. Das Team verwendete etwa  hochwertige englische Bild- und Textdaten, einschließlich CC3M , CC12M, COCO, Visual Genome, Laion usw. im Vortraining. In dieser Phase bleiben die Parameter des Sprachmodells festgelegt und nur einige Parameter von Q-Former werden aktualisiert, um eine effiziente Ausrichtung umfangreicher visueller Sprachdarstellungen zu unterstützen .
hochwertige englische Bild- und Textdaten, einschließlich CC3M , CC12M, COCO, Visual Genome, Laion usw. im Vortraining. In dieser Phase bleiben die Parameter des Sprachmodells festgelegt und nur einige Parameter von Q-Former werden aktualisiert, um eine effiziente Ausrichtung umfangreicher visueller Sprachdarstellungen zu unterstützen .
Das Team hat dann die Anweisungen von VisCPM-Chat unter Verwendung der LLaVA-150K-Befehls-Feinabstimmungsdaten verfeinert und die entsprechenden übersetzten chinesischen Daten gemischt, um das Modell zu verfeinern - Modale Grundfunktionen und Benutzernutzungsabsichten. In der Befehlsfeinabstimmungsphase wurden alle Modellparameter aktualisiert, um die Befehlsnutzungseffizienz der Feinabstimmungsdaten zu verbessern Die Daten wurden zur Feinabstimmung der Anweisungen verwendet. Das Modell konnte chinesische Fragen verstehen, konnte jedoch nur auf Englisch antworten. Dies zeigt, dass die modalen Fähigkeiten durch das weitere Hinzufügen einer kleinen Menge chinesischer Übersetzungsdaten gut verallgemeinert wurden In der Feinabstimmungsphase der Anweisungen kann die Antwortsprache des Modells an die Fragesprache des Benutzers angepasst werden
 Das Team testete den LLaVA-Testsatz für Englisch und die Übersetzung auf Chinesisch. Das Modell wurde anhand dieses Bewertungsbenchmarks bewertet Untersucht die Leistung des Modells im offenen Domänendialog, in der Bilddetailbeschreibung und im komplexen Denken und verwendet GPT-4 zur Bewertung. Es kann beobachtet werden, dass VisCPM-Chat über hervorragende chinesische multimodale Fähigkeiten verfügt
Das Team testete den LLaVA-Testsatz für Englisch und die Übersetzung auf Chinesisch. Das Modell wurde anhand dieses Bewertungsbenchmarks bewertet Untersucht die Leistung des Modells im offenen Domänendialog, in der Bilddetailbeschreibung und im komplexen Denken und verwendet GPT-4 zur Bewertung. Es kann beobachtet werden, dass VisCPM-Chat über hervorragende chinesische multimodale Fähigkeiten verfügt
VisCPM-Chat bietet zwei Modellversionen, VisCPM-Chat-balance und VisCPM-Chat-zhplus ausgeglichenere Fähigkeiten in Englisch und Chinesisch, während Letzteres bei den Chinesischkenntnissen stärker ausgeprägt ist. Die beiden Modelle verwenden in der Feinabstimmungsphase der Anweisungen die gleichen Daten. VisCPM-Chat-zhplus fügt in der Vortrainingsphase zusätzlich 20 Millionen bereinigte native chinesische Bild-Text-Paardaten und 120 Millionen übersetzte chinesische Bild-Text-Paardaten hinzu.
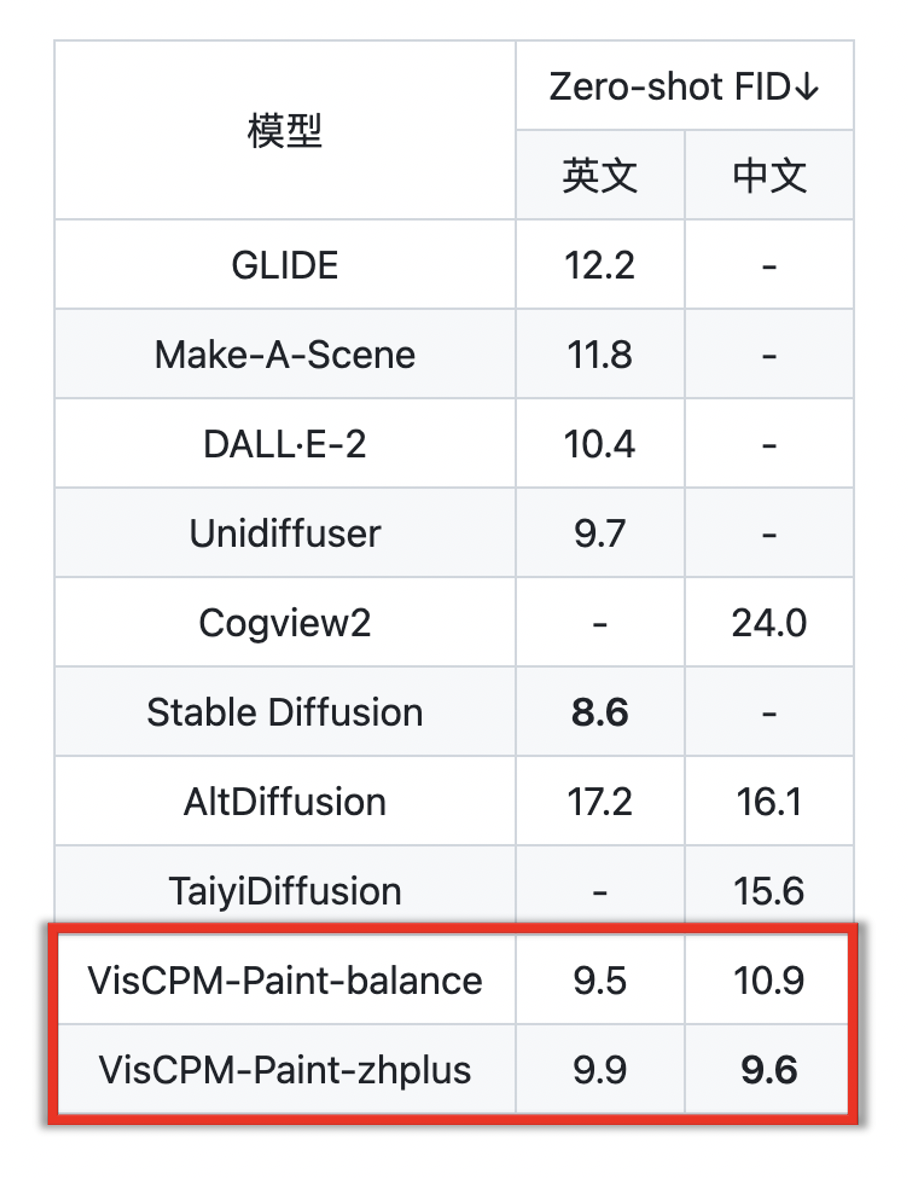
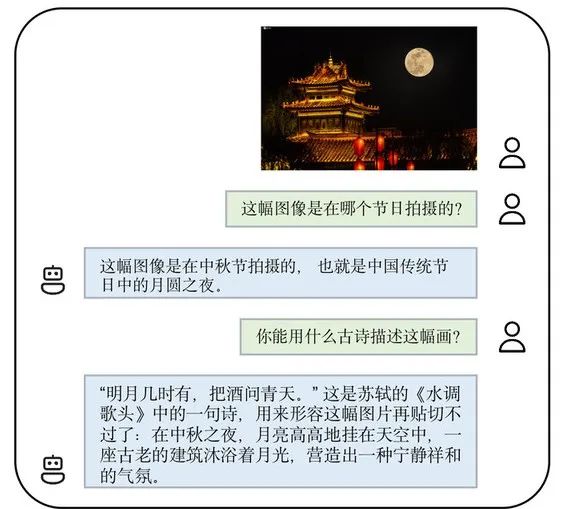
Bilder Das Folgende ist eine Demonstration der multimodalen Dialogfunktionen von VisCPM-Chat. Es kann nicht nur Karten bestimmter Bereiche erkennen, sondern auch Graffiti und Filmplakate verstehen und sogar das Starbucks-Logo erkennen. Außerdem bin ich sehr zweisprachig in Chinesisch und Englisch! Schauen wir uns VisCPM-Paint an, das die zweisprachige Text-zu-Bild-Generierung in Chinesisch und Englisch unterstützt. Das Modell verwendet CPM-Bee (10B) als Textkodierer, UNet als Bilddekodierer und zielt durch Diffusionsmodelltraining auf verschmolzene Sprach- und visuelle Modelle ab. Während des Trainingsprozesses bleiben die Parameter des Sprachmodells immer fest. Initialisieren Sie den visuellen Decoder mit den UNet-Parametern von Stable Diffusion 2.1 und verschmelzen Sie ihn mit dem Sprachmodell, indem Sie seine wichtigsten Überbrückungsparameter schrittweise freigeben: Trainieren Sie zunächst die lineare Schicht der Textdarstellungszuordnung zum visuellen Modell und geben Sie dann die Queraufmerksamkeit weiter frei Schicht von UNet. Das Modell wurde auf englischen Bild-Text-Daten von Laion 2B trainiert. Ähnlich wie VisCPM-Paint kann VisCPM-Paint dank der zweisprachigen Fähigkeit des Basismodells CPM-Bee nur durch englische Bild- und Textpaare trainiert und verallgemeinert werden, um gute chinesische Text-zu-Bild-Generierungsfähigkeiten zu erreichen und erreicht damit chinesische Open-Source-Modelle von ihrer besten Seite. Durch das weitere Hinzufügen von 20 Mio. bereinigten nativen chinesischen Bild-Text-Paardaten und 120 Mio. ins Chinesische übersetzten Bild-Text-Paardaten wurde die Fähigkeit des Modells zur chinesischen Text-zu-Bild-Generierung weiter verbessert. Ebenso gibt es von VisCPM-Paint zwei verschiedene Versionen: Balance und zhplus. Sie haben 30.000 Bilder mit dem Standard-Bilderzeugungstestsatz MSCOCO abgetastet und die häufig verwendete Bewertungsbilderzeugungsmetrik FID (Fréchet Inception Distance) berechnet, um die Qualität der erzeugten Bilder zu bewerten. Geben Sie zwei Eingabeaufforderungen in das VisCPM-Paint-Modell ein: „Der helle Mond geht auf dem Meer auf, die Welt ist zu dieser Zeit, ästhetischer Stil, abstrakter Stil“ und „Die Leute sind untätig, Osmanthusblüten fallen, die „Mond ist ruhig am Frühlingshimmel“, und die folgenden beiden werden generiert. Bild: (Die Stabilität des Erzeugungseffekts hat noch Raum für Verbesserungen) ist ziemlich erstaunlich. Man kann es sagen dass es die künstlerische Konzeption antiker Poesie genau erfasst. Wenn Sie das Gedicht in Zukunft nicht verstehen können, erstellen Sie einfach ein Bild, um es zu verstehen! Wenn es im Design angewendet wird, kann es viel Personal einsparen. Mit VisCPM-Chat können Sie nicht nur „zeichnen“, sondern auch „Gedichte aufsagen“: Rückwärtssuche nach Gedichten anhand von Bildern. Ich kann zum Beispiel die Gedichte von Li Bai verwenden, um die Szene am Gelben Fluss zu beschreiben und zu interpretieren, und ich kann auch Su Shis „Shui Tiao Ge Tou“ verwenden, um meine Gefühle auszudrücken, wenn ich der Mittherbstmondnacht gegenüberstehe. VisCPM liefert nicht nur gute Generierungsergebnisse, die Download-Version ist auch durchdacht gestaltet und auch sehr einfach zu installieren und zu verwenden. VisCPM bietet Modellversionen mit unterschiedlichen chinesischen und englischen Funktionen zum Herunterladen und Auswählen. Die Installationsschritte sind einfach und für mehrere Modelle geeignet kann mit wenigen Codezeilen während der Verwendung implementiert werden, und Sicherheitsprüfungen für Eingabetext und Ausgabebilder sind standardmäßig im Code aktiviert. (Spezifische Tutorials finden Sie in der README-Datei.) In Zukunft wird das Team VisCPM auch in das Huggingface-Code-Framework integrieren und das Sicherheitsmodell schrittweise verbessern, die schnelle Bereitstellung von Webseiten unterstützen, Modellquantifizierungsfunktionen unterstützen, die Feinabstimmung des Modells unterstützen und vieles mehr Funktionen. Bleiben Sie dran für Updates! Erwähnenswert ist, dass Modelle der VisCPM-Serie für den persönlichen Gebrauch und Forschungszwecke sehr willkommen sind. Wenn Sie das Modell für kommerzielle Zwecke nutzen möchten, können Sie sich auch an cpm@modelbest.cn wenden, um kommerzielle Lizenzfragen zu besprechen. Traditionelle Modelle konzentrieren sich auf die Verarbeitung monomodaler Daten in der realen Welt. Multimodale große Modelle verbessern die Wahrnehmungsinteraktionsfähigkeiten künstlicher Intelligenzsysteme und lösen komplexe Wahrnehmungs- und Interaktionsprobleme in der realen Welt für KI. Aufgaben zu verstehen bringt neue Möglichkeiten. Es muss gesagt werden, dass die in Tsinghua ansässigen großen Modellunternehmen über starke Forschungs- und Entwicklungskapazitäten für wandorientierte Intelligenz verfügen. Das gemeinsam veröffentlichte multimodale Großmodell VisCPM ist leistungsstark und weist eine erstaunliche Leistung auf. 


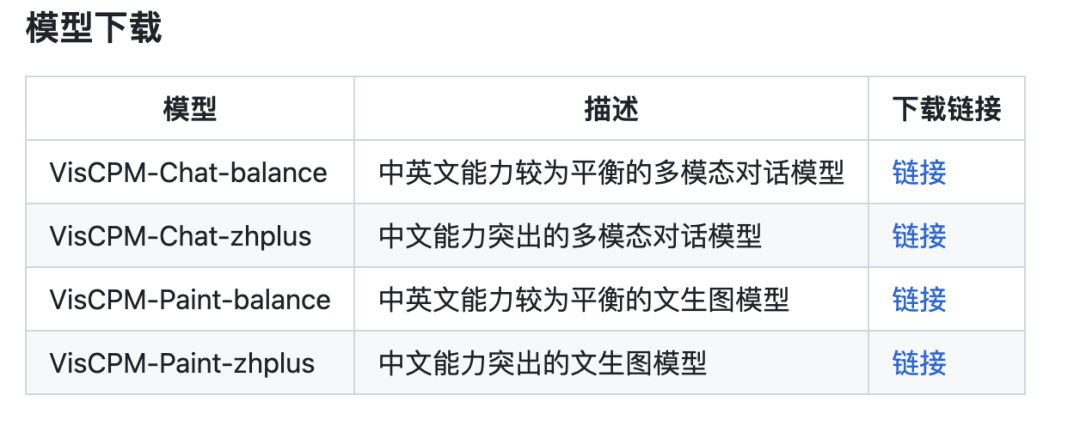 VisCPM bietet Modellversionen mit unterschiedlichen chinesischen und englischen Funktionen.
VisCPM bietet Modellversionen mit unterschiedlichen chinesischen und englischen Funktionen. 
Das obige ist der detaillierte Inhalt vonDas intelligente Open-Source-Multimodal-Großmodell VisCPM der Tsinghua-Universität in China unterstützt die bidirektionale Generierung von Dialogtexten und -bildern und verfügt über erstaunliche Poesie- und Malfunktionen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Wie man den Douyin-Moment mit engen Freunden zum Leuchten bringt
Wie man den Douyin-Moment mit engen Freunden zum Leuchten bringt
 Was soll ich tun, wenn mein Computer hochfährt und auf dem Bildschirm ein schwarzer Bildschirm ohne Signal angezeigt wird?
Was soll ich tun, wenn mein Computer hochfährt und auf dem Bildschirm ein schwarzer Bildschirm ohne Signal angezeigt wird?
 Kaspersky-Firewall
Kaspersky-Firewall
 Plugin.exe-Anwendungsfehler
Plugin.exe-Anwendungsfehler
 nvidia geforce 940mx
nvidia geforce 940mx
 Wissen Sie, ob Sie die andere Person sofort kündigen, nachdem Sie ihr auf Douyin gefolgt sind?
Wissen Sie, ob Sie die andere Person sofort kündigen, nachdem Sie ihr auf Douyin gefolgt sind?
 So berechnen Sie die Bearbeitungsgebühr für die Rückerstattung der Eisenbahn 12306
So berechnen Sie die Bearbeitungsgebühr für die Rückerstattung der Eisenbahn 12306
 Die zehn besten Börsen für digitale Währungen
Die zehn besten Börsen für digitale Währungen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



