


Der Open-Source-Alpaka-Großmodell-LLaMA-Kontext entspricht GPT-4, mit nur einer einfachen Änderung!
Dieses gerade von Meta AI eingereichte Papier zeigt, dass weniger als 1000 Feinabstimmungsschritte erforderlich sind, nachdem das LLaMA-Kontextfenster von 2k auf 32k erweitert wurde.
Die Kosten sind im Vergleich zum Vortraining vernachlässigbar.

Das Erweitern des Kontextfensters bedeutet, dass die „Arbeitsgedächtnis“-Kapazität der KI erhöht wird. Konkret kann sie:
Die wichtigere Bedeutung ist, dass alle großen Alpaka-Modellfamilien, die auf LLaMA basieren, diese Methode zu geringen Kosten übernehmen und sich gemeinsam weiterentwickeln können?
Alpaca ist derzeit das umfassendste Open-Source-Basismodell und hat viele vollständig kommerziell verfügbare Open-Source-Großmodelle und vertikale Industriemodelle abgeleitet.
Auch Tian Yuandong, der korrespondierende Autor des Papiers, teilte diese neue Entwicklung begeistert in seinem Freundeskreis.
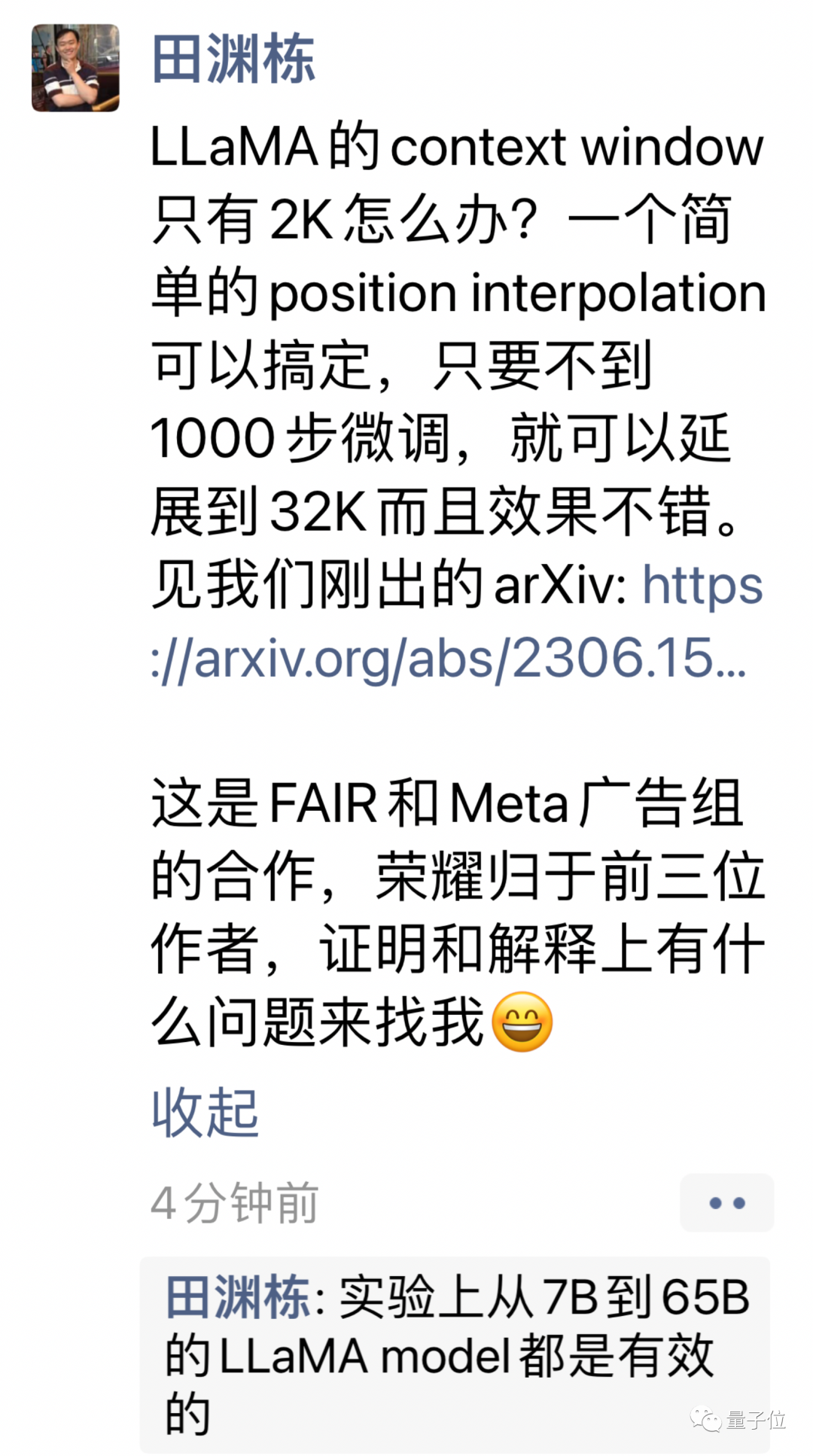
Die neue Methode heißt Positionsinterpolation und eignet sich für große Modelle, die RoPE (Rotationspositionskodierung) verwenden.
RoPE wurde bereits 2021 vom Team von Zhuiyi Technology vorgeschlagen und hat sich mittlerweile zu einer der gebräuchlichsten Methoden zur Positionskodierung für große Modelle entwickelt.

Aber die direkte Verwendung der Extrapolation zur Erweiterung des Kontextfensters unter dieser Architektur wird den Selbstaufmerksamkeitsmechanismus vollständig zerstören.
Insbesondere der Teil, der über die Länge des vorab trainierten Kontexts hinausgeht, führt dazu, dass die Ratlosigkeit des Modells auf das gleiche Niveau ansteigt wie bei einem untrainierten Modell.
Die neue Methode wurde geändert, um den Positionsindex linear zu verkleinern, die Bereichsausrichtung des vorderen und hinteren Positionsindex und den relativen Abstand zu erweitern.

Es ist intuitiver, Bilder zu verwenden, um den Unterschied zwischen den beiden auszudrücken.
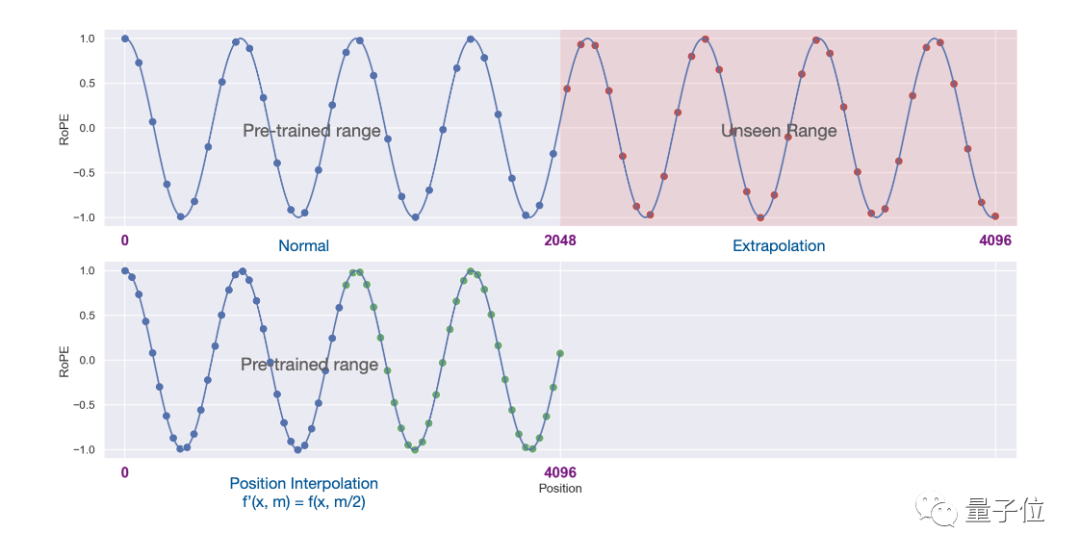
Experimentelle Ergebnisse zeigen, dass die neue Methode für LLaMA-Großmodelle von 7B bis 65B wirksam ist.
Bei der Langsequenz-Sprachmodellierung, dem Passkey-Abruf und der Zusammenfassung langer Dokumente gibt es keine nennenswerten Leistungseinbußen.
Neben Experimenten findet sich im Anhang der Arbeit auch ein ausführlicher Nachweis der neuen Methode.
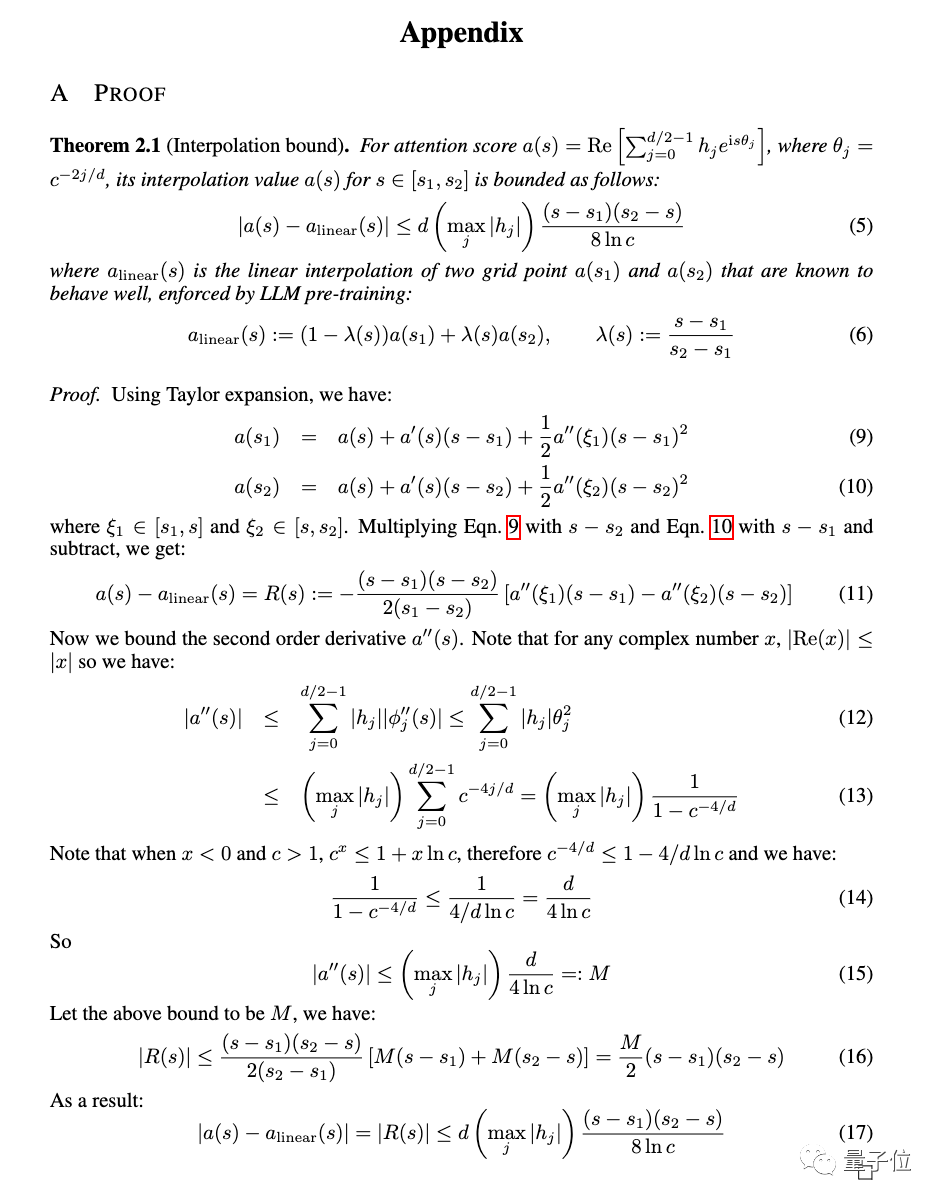
Das Kontextfenster war früher eine wichtige Lücke zwischen Open-Source-Großmodellen und kommerziellen Großmodellen.
Zum Beispiel unterstützt GPT-3.5 von OpenAI bis zu 16.000, GPT-4 unterstützt 32.000 und Claude von AnthropicAI unterstützt bis zu 100.000.
Gleichzeitig stecken viele Open-Source-Großmodelle wie LLaMA und Falcon immer noch bei 2k fest.
Jetzt haben die neuen Ergebnisse von Meta AI diese Lücke direkt geschlossen.
Die Erweiterung des Kontextfensters ist auch einer der Schwerpunkte der jüngsten Großmodellforschung. Neben Positionsinterpolationsmethoden gibt es viele Versuche, die Aufmerksamkeit der Industrie auf sich zu ziehen.
1. Entwickler Kaiokendev hat in einem technischen Blog eine Methode zur Erweiterung des LLaMa-Kontextfensters auf 8k untersucht.
2. Galina Alperovich, Leiterin für maschinelles Lernen beim Datensicherheitsunternehmen Soveren, hat in einem Artikel 6 Tipps zum Erweitern des Kontextfensters zusammengefasst.

3. Teams von Mila, IBM und anderen Institutionen haben in einem Artikel auch versucht, die Positionskodierung in Transformer vollständig zu entfernen.伴 Wenn Sie es benötigen, können Sie auf den Link unten klicken, um ~ anzuzeigen TPS:/ /m.sbmmt.com/link/9659078925b57e621eb3f9ef19773ac3
 Das Geheimnis hinter dem 100K-Kontextfenster in
Das Geheimnis hinter dem 100K-Kontextfenster in
https:/ /m.sbmmt.com/link/fb6c84779f12283a81d739d8f088fc12
Das obige ist der detaillierte Inhalt vonDas große Modell der Alpaka-Familie entwickelt sich gemeinsam weiter! 32k-Kontext entspricht GPT-4, erstellt vom Team von Tian Yuandong. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Der Apache-Start ist fehlgeschlagen
Der Apache-Start ist fehlgeschlagen
 Verwendung der Memset-Funktion
Verwendung der Memset-Funktion
 So ändern Sie die Hosts-Datei
So ändern Sie die Hosts-Datei
 Einführung in die Hauptarbeitsinhalte des Backends
Einführung in die Hauptarbeitsinhalte des Backends
 ASUS x402c
ASUS x402c
 Was ist der Unterschied zwischen Ibatis und Mybatis?
Was ist der Unterschied zwischen Ibatis und Mybatis?
 So richten Sie Textfelder in HTML aus
So richten Sie Textfelder in HTML aus
 Kosteneffizienzanalyse des Lernens von Python, Java und C++
Kosteneffizienzanalyse des Lernens von Python, Java und C++












