


Meta hat kürzlich das Voicebox AI-Modell veröffentlicht, das erhebliche Vorteile bei der Audiosimulation bietet.
Es wird berichtet, dass Voicebox nur ein 2-sekündiges Audiobeispiel benötigt, um die Audiodetails und die Klangfarbe genau zu identifizieren und es basierend auf den Textergebnissen in eine Sprachausgabe umzuwandeln.

Voicebox ist ein generatives KI-Modell, das bei der Audiobearbeitung, dem Sampling und dem Styling hilft.
Mit dieser Technologie können YouTuber in Zukunft Audiospuren einfacher bearbeiten. Gleichzeitig kann sie auch Menschen mit geschädigten Stimmbändern helfen und ihnen helfen, wieder zu „klingen“. Ermöglicht sehbehinderten Menschen, die schriftlichen Nachrichten ihrer Freunde über Ton zu hören, während Menschen gleichzeitig jede Fremdsprache mit ihrer eigenen Stimme sprechen können.
Gleichzeitig kann es auch automatisch den fehlenden Inhalt basierend auf dem vorhergehenden und nachfolgenden Inhalt des Sprachclips ergänzen.
Laut Meta kann Voicebox im zukünftigen Metaversum natürliche und realistische Spracheffekte für KI-Assistenten oder NPCs bereitstellen und so das Eintauchen der Benutzer bei der Verwendung erheblich verbessern.
Die Vielseitigkeit von Voicebox unterstützt eine Vielzahl von Aufgaben, darunter:
Kontextuelle Text-zu-Sprache-Synthese: Mit Audio-Samples von nur zwei Sekunden kann Voicebox den Audiostil anpassen und für die Text-zu-Sprache-Erzeugung verwenden.
Sprachbearbeitung und Rauschunterdrückung: Voicebox kann durch Rauschen unterbrochene Wortteile wiederherstellen oder falsch gesprochene Wörter ersetzen, ohne die gesamte Sprache neu aufzeichnen zu müssen. Sie können beispielsweise einen durch einen bellenden Hund unterbrochenen Sprachabschnitt identifizieren, ihn zuschneiden und dann Voicebox anweisen, den Abschnitt neu zu generieren – wie ein Radiergummi für die Audiobearbeitung.
Sprachübergreifende Konvertierung: Wenn Voicebox eine Sprachprobe und einen Text in Englisch, Französisch, Deutsch, Spanisch, Polnisch oder Portugiesisch erhält, kann sie eine Textlesung in jeder dieser Sprachen generieren, auch wenn die Sprachprobe und der Text unterschiedlich sind Sprache. In Zukunft können Menschen diese Funktion nutzen, um natürlicher und authentischer zu kommunizieren, auch wenn sie die Sprachen nicht verstehen.
Flow Matching ist eine von Voicebox verwendete Methode, die nachweislich die Leistung von Diffusionsmodellen verbessert. Voicebox übertrifft VALL-E, das aktuelle hochmoderne englische Modell, in Bezug auf Verständlichkeit (5,9 % gegenüber 1,9 % Wortfehlerrate) und Audioähnlichkeit (0,580 gegenüber 0,681) und ist gleichzeitig 20-mal schneller. Bei der sprachübergreifenden Stilübertragung übertrifft Voicebox YourTTS, indem es die durchschnittliche Wortfehlerrate von 10,9 % auf 5,2 % senkt und die Audioähnlichkeit von 0,335 auf 0,481 verbessert.
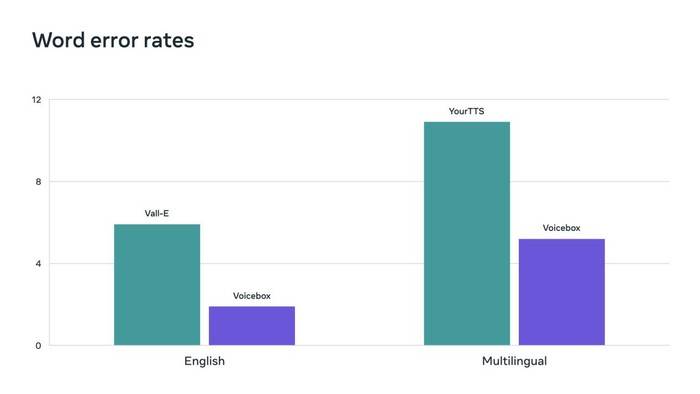
Voicebox erzielt neue, hochmoderne Ergebnisse und übertrifft Vall-E und YourTTS bei der Wortfehlerrate.
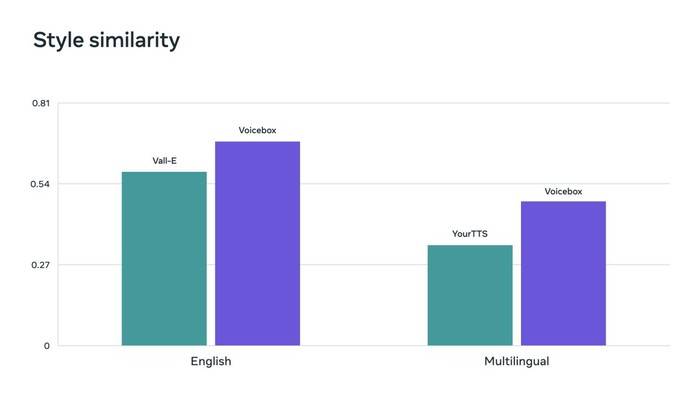
Voicebox erzielt auch hochmoderne Ergebnisse bei Kennzahlen zur Ähnlichkeit von Audiostilen in englischen bzw. mehrsprachigen Benchmarks.
Es ist erwähnenswert, dass sich Meta derzeit des potenziellen Schadens bewusst ist, der bei der Verwendung von Voicebox im Bereich der Fälschung entsteht, und daher nach einer Möglichkeit sucht, zwischen echter Sprache und von Voicebox generierter Sprache zu unterscheiden.
Bis eine Lösung gefunden ist, wird Meta das Voicebox-KI-Modell nicht der Öffentlichkeit zugänglich machen, um unnötigen Schaden zu vermeiden.
Anmerkung des Herausgebers: KI wurde mittlerweile in verschiedenen Bereichen eingesetzt und ist das erste multifunktionale und effiziente Modell, das die Aufgabenverallgemeinerung erfolgreich durchführt. Ich glaube, dass Voicebox eine neue Ära der Sprachgenerierungs-KI einläuten kann. Wenn Meta Audio-Betrug nicht effektiv bekämpfen kann, wird die Voicebox-Technologie möglicherweise deaktiviert.
Das obige ist der detaillierte Inhalt vonMeta veröffentlicht ein Audio-KI-Modell, das die Sprache einer echten Person in nur 2 Sekunden simuliert. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was ist digitale Währung?
Was ist digitale Währung?
 So öffnen Sie ESP-Dateien
So öffnen Sie ESP-Dateien
 So deaktivieren Sie den Echtzeitschutz im Windows-Sicherheitscenter
So deaktivieren Sie den Echtzeitschutz im Windows-Sicherheitscenter
 Was sind die neuen Funktionen von Hongmeng OS 3.0?
Was sind die neuen Funktionen von Hongmeng OS 3.0?
 So entsperren Sie das Oppo-Telefon, wenn ich das Passwort vergessen habe
So entsperren Sie das Oppo-Telefon, wenn ich das Passwort vergessen habe
 So lösen Sie das Problem, dass localhost nicht geöffnet werden kann
So lösen Sie das Problem, dass localhost nicht geöffnet werden kann
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Wie kaufe und verkaufe ich Bitcoin? Tutorial zum Bitcoin-Handel
Wie kaufe und verkaufe ich Bitcoin? Tutorial zum Bitcoin-Handel








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



