


Multimodale Pre-Training-Methoden treiben auch die Entwicklung des 3D-Darstellungslernens voran, indem sie 3D-Formen, 2D-Bilder und entsprechende Sprachbeschreibungen aufeinander abstimmen.
Den vorhandenen multimodalen Pre-Training-Frameworks (Methoden zum Sammeln von Daten) mangelt es jedoch an Skalierbarkeit, was das Potenzial des multimodalen Lernens erheblich einschränkt. Der Hauptengpass liegt in der Skalierbarkeit und Skalierbarkeit der Sprachmodalitäten.
Vor kurzem hat sich Salesforce AI mit der StanfordUniversity und der University of Texas at Austin zusammengetan, um die Projekte ULIP (CVP R2023) und ULIP-2 zu veröffentlichen, die ein neues Kapitel im 3D-Verständnis aufschlagen.

Papierlink: https://arxiv.org/pdf/2212.05171.pdf
Papierlink: https://arxiv.org/pdf/2305.08275.pdf
Code-Link: https://github.com/salesforce/ULIP
Die Forscher nutzten einen einzigartigen Ansatz, um das Modell mithilfe von 3D-Punktwolken, Bildern und Text vorab zu trainieren und sie in einem einheitlichen Feature-Raum auszurichten . Dieser Ansatz erzielt modernste Ergebnisse bei 3D-Klassifizierungsaufgaben und eröffnet neue Möglichkeiten für domänenübergreifende Aufgaben wie die Bild-zu-3D-Retrieval.Und ULIP-2 ermöglicht dieses multimodale Vortraining ohne manuelle Anmerkungen und macht es so im großen Maßstab skalierbar.
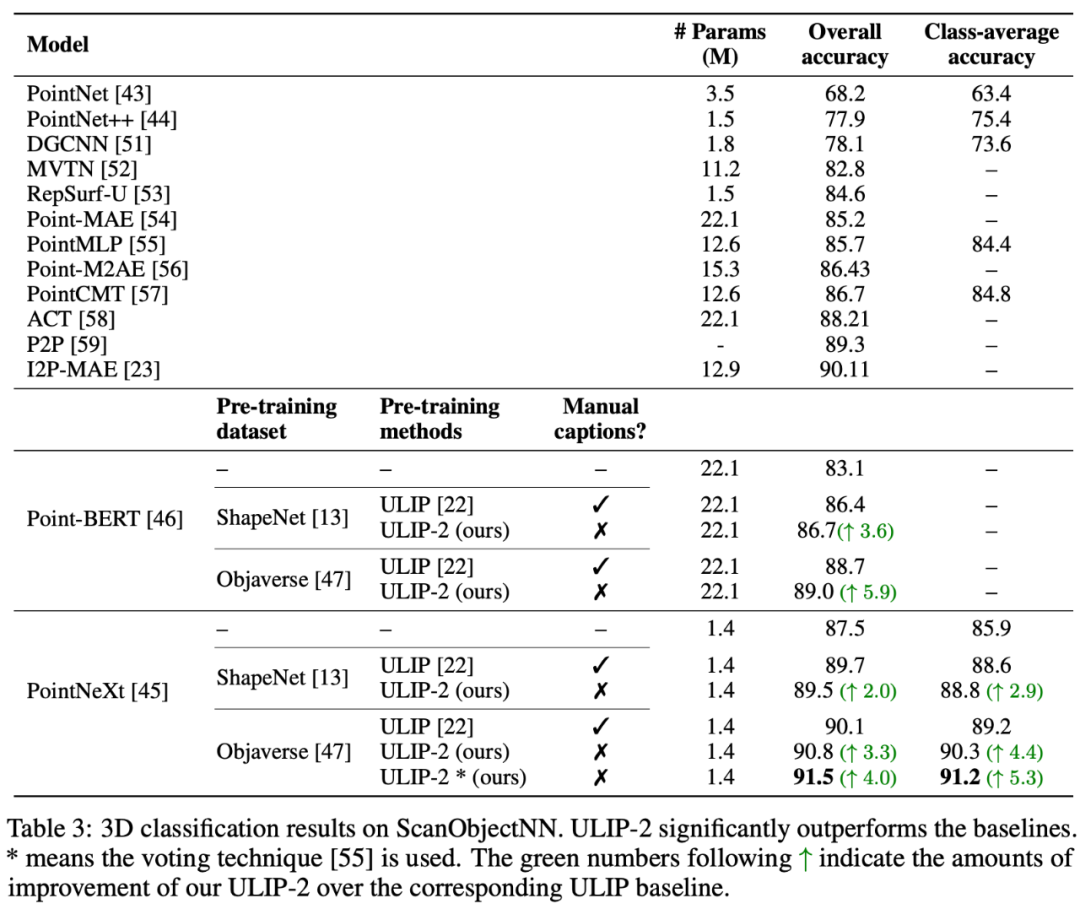
ULIP-2 erzielte erhebliche Leistungsverbesserungen bei der Downstream-Zero-Shot-Klassifizierung von ModelNet40 und erreichte die höchste Genauigkeit von 74,0 %; beim realen ScanObjectNN-Benchmark erreichte es 91,5 % Die Gesamtgenauigkeit stellt einen Durchbruch beim Erlernen skalierbarer multimodaler 3D-Darstellungen dar, ohne dass menschliche 3D-Annotationen erforderlich sind.
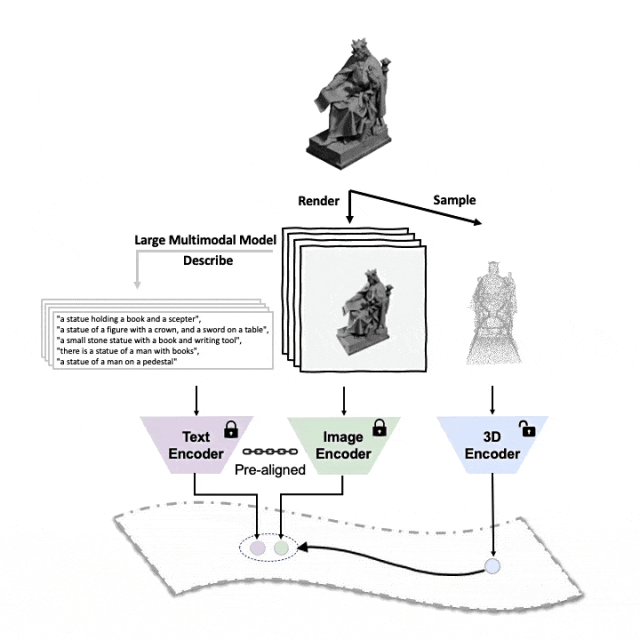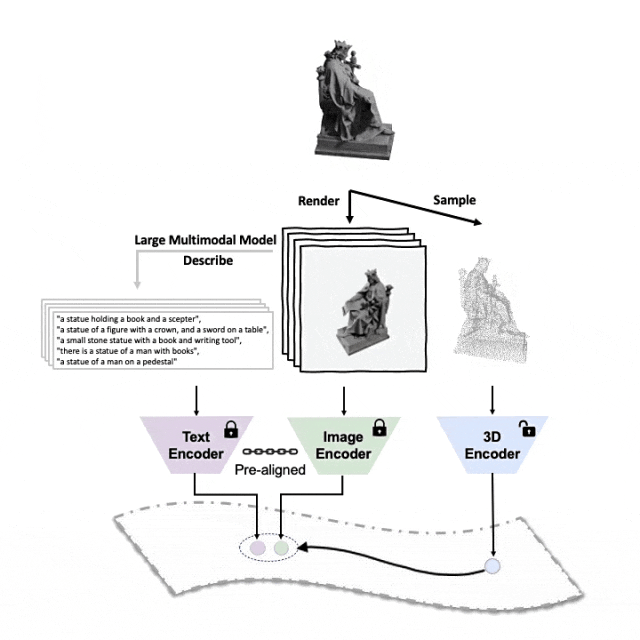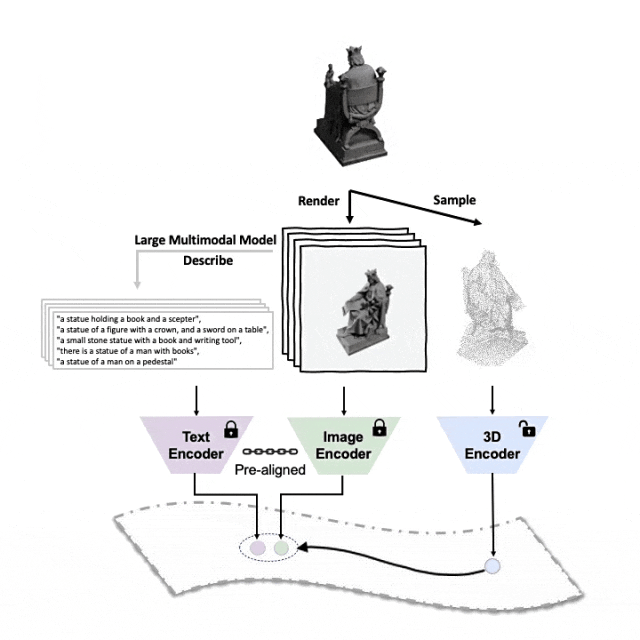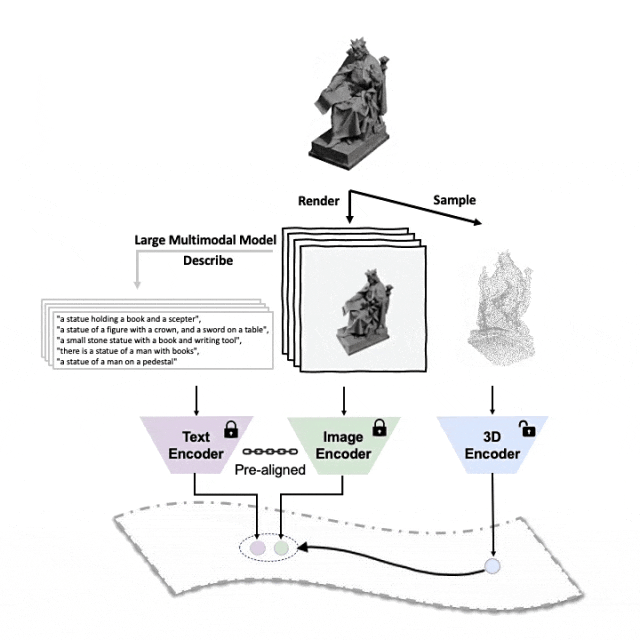
Schematische Darstellung des Pre-Training-Frameworks zum Ausrichten dieser drei Funktionen (3D, Bild, Text)
Code und der veröffentlichte große trimodale Datensatz (" ULIP – Objaverse Triplets“ und „ULIP – ShapeNet Triplets“) sind Open Source.Hintergrund
3D-Verständnis ist ein wichtiger Teilbereich der künstlichen Intelligenz, der es Maschinen ermöglicht, wie Menschen im dreidimensionalen Raum wahrzunehmen und zu interagieren. Diese Fähigkeit hat wichtige Anwendungen in Bereichen wie autonomen Fahrzeugen, Robotik, virtueller Realität und erweiterter Realität.Allerdings stand das 3D-Verständnis aufgrund der Komplexität der Verarbeitung und Interpretation von 3D-Daten sowie der Kosten für das Sammeln und Kommentieren von 3D-Daten schon immer vor großen Herausforderungen.
ULIP
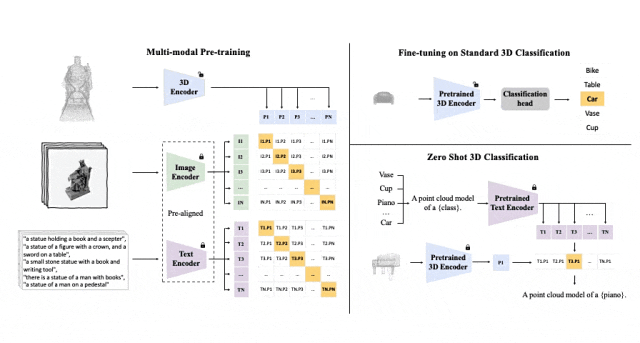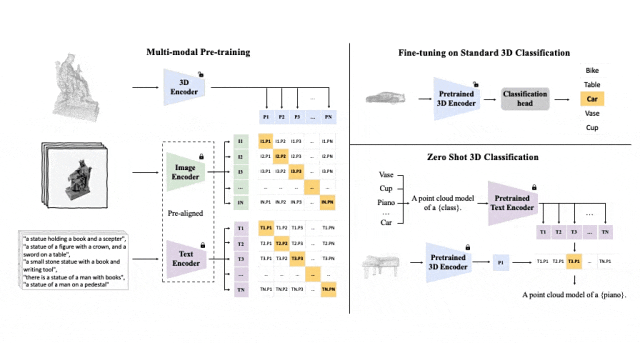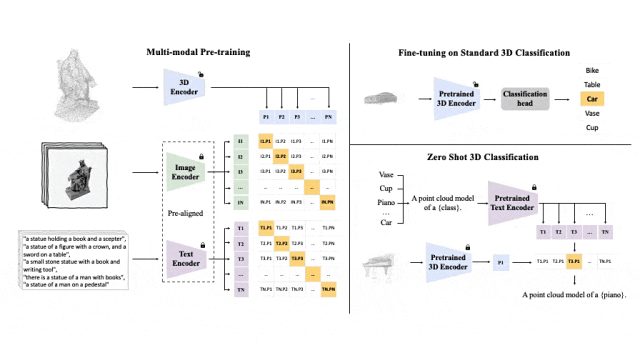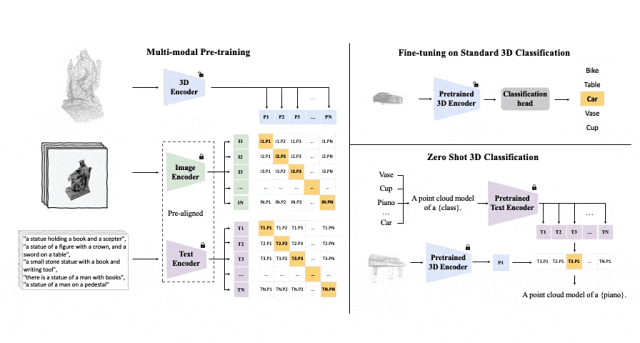
Trimodales Pre-Training-Framework und seine nachgelagerten Aufgaben
ULIP (bereits von CVPR2023 akzeptiert) verfolgt einen einzigartigen Ansatz, bei dem 3D-Punktwolken, Bilder und Text vorab verwendet werden -Training am Modell, um sie in einem einheitlichen Darstellungsraum auszurichten.Dieser Ansatz erzielt modernste Ergebnisse bei 3D-Klassifizierungsaufgaben und eröffnet neue Möglichkeiten für domänenübergreifende Aufgaben wie die Bild-zu-3D-Retrieval.
Der Schlüssel zum Erfolg von ULIP liegt in der Verwendung eines vorab ausgerichteten Bild- und Text-Encoders wie CLIP, der auf eine große Anzahl von Bild-Text-Paaren vortrainiert ist.
Diese Encoder richten die Merkmale der drei Modalitäten in einem einheitlichen Darstellungsraum aus, sodass das Modell 3D-Objekte effektiver verstehen und klassifizieren kann.
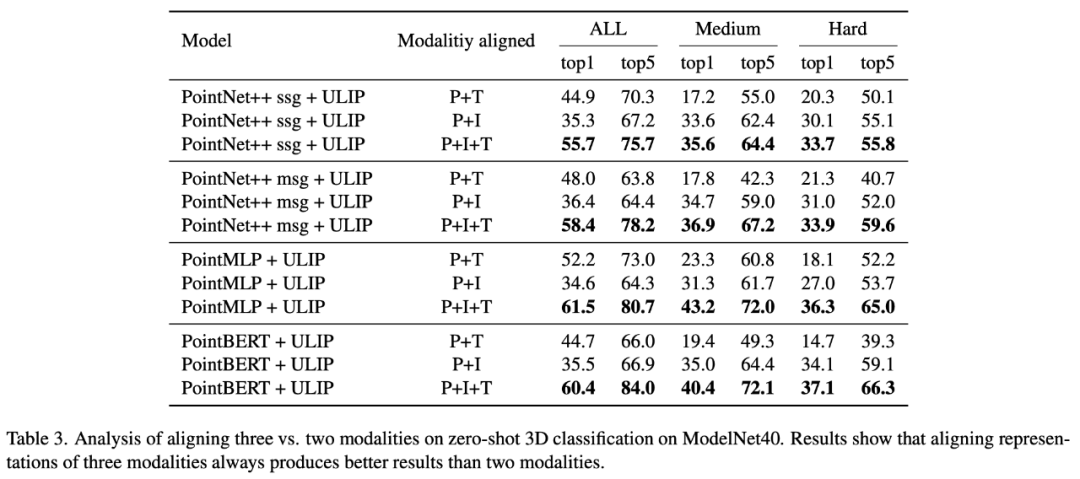
Dieses verbesserte 3D-Darstellungslernen verbessert nicht nur das Verständnis des Modells für 3D-Daten, sondern ermöglicht auch modalübergreifende Anwendungen wie Zero-Shot-3D-Klassifizierung und Bild-zu-3D-Abruf, da der 3D-Encoder multimodalen Kontext erhält. ULIPs Verlustfunktion vor dem Training lautet wie folgt: In den Standardeinstellungen von ULIP ist α auf 0, β und θ auf 1 eingestellt und der Kontrast zwischen den beiden Modalitäten beträgt gelernt Die Definition der Verlustfunktion lautet wie folgt, wobei sich M1 und M2 auf zwei der drei Modi beziehen: ULIP hat auch ein Experiment zum Abrufen von Bildern in 3D durchgeführt, und der Effekt ist wie folgt: Die experimentellen Ergebnisse zeigen, dass das vorab trainierte ULIP-Modell in der Lage war, sinnvolle multimodale Merkmale zwischen Bildern und 3D-Punktwolken zu lernen. Überraschenderweise ähnelt im Vergleich zu den anderen abgerufenen 3D-Modellen das erste abgerufene 3D-Modell dem Abfragebild am nächsten. Wenn wir beispielsweise Bilder von verschiedenen Flugzeugtypen (Kampfflugzeuge und Verkehrsflugzeuge) zum Abruf verwenden (zweite und dritte Reihe), behält die nächstgelegene abgerufene 3D-Punktwolke immer noch die subtilen Unterschiede des Abfragebilds bei. Hier ist ein Beispiel für die Erstellung von Mehrwinkel-Textbeschreibungen von 3D-Objekten. Wir rendern zunächst 3D-Objekte aus einer Reihe von Ansichten in 2D-Bilder und verwenden dann groß angelegte multimodale Modelle, um Beschreibungen für alle generierten Bilder zu generieren ULIP-2 Basierend auf ULIP verwenden wir groß angelegte multimodale Modelle. Modalmodelle für 3D-Objekte generieren rundum entsprechende Sprachbeschreibungen, um skalierbare multimodale Pre-Training-Daten ohne manuelle Anmerkungen zu sammeln, wodurch der Pre-Training-Prozess und das trainierte Modell effizienter werden und seine Anpassungsfähigkeit verbessert wird. Die Methode von ULIP-2 umfasst die Generierung von Mehrwinkel- und verschiedenen Sprachbeschreibungen für jedes 3D-Objekt und die anschließende Verwendung dieser Beschreibungen zum Trainieren des Modells, sodass die 3D-Objekte, 2D-Bilder und Sprachbeschreibungen im Funktionsraum ausgerichtet sind. Dieses Framework ermöglicht die Erstellung großer trimodaler Datensätze ohne manuelle Annotation und schöpft so das Potenzial des multimodalen Vortrainings voll aus. ULIP-2 veröffentlichte auch die generierten groß angelegten dreimodalen Datensätze: „ULIP – Objaverse Triplets“ und „ULIP – ShapeNet Triplets“. Einige Statistiken von zwei trimodalen Datensätzen Die ULIP-Serie hat erstaunliche Ergebnisse bei der Feinabstimmung von Experimenten zu multimodalen Downstream-Aufgaben und 3D-Ausdruck erzielt, insbesondere vor -Training in ULIP-2 kann ohne manuelle Anmerkungen erreicht werden. ULIP-2 erzielte erhebliche Verbesserungen (74,0 % Top-1-Genauigkeit) gegenüber der Downstream-Zero-Shot-Klassifizierungsaufgabe von ModelNet40; beim realen ScanObjectNN-Benchmark erreichte es eine Gesamtgenauigkeit von 91,5 % markiert einen Durchbruch beim skalierbaren multimodalen 3D-Darstellungslernen, ohne dass manuelle 3D-Annotationen erforderlich sind. In beiden Artikeln wurden detaillierte Ablationsexperimente durchgeführt. In „ULIP: Erlernen einer einheitlichen Darstellung von Sprache, Bildern und Punktwolken für das 3D-Verstehen“ untersuchte der Autor mithilfe von Experimenten, ob nur zwei davon ausgerichtet werden sollten, da das Pre-Training-Framework von ULIP die Teilnahme von drei Modalitäten beinhaltet Ist es besser, einen Modus oder alle drei Modi auszurichten? Die experimentellen Ergebnisse sind wie folgt: Wie aus den experimentellen Ergebnissen hervorgeht, ist die Ausrichtung von drei Modi konsistenter als die Ausrichtung Nur zwei Diese Modalität ist gut, was auch die Rationalität des Pre-Training-Frameworks von ULIP beweist. Die experimentellen Ergebnisse zeigen, dass die Wirkung des Vortrainings des ULIP-2-Frameworks durch die Aktualisierung des verwendeten groß angelegten multimodalen Modells verbessert werden kann und ein gewisses Wachstumspotenzial aufweist.
Experimentelle Ergebnisse Es wird gezeigt, dass mit zunehmender Anzahl der verwendeten Ansichten auch der Effekt der Zero-Shot-Klassifizierung des vorab trainierten Modells zunimmt. Darüber hinaus untersuchte ULIP-2 auch die Auswirkungen der nach CLIP sortierten Sprachbeschreibungen verschiedener Topk auf das multimodale Vortraining. Die experimentellen Ergebnisse sind wie folgt:
Die experimentellen Ergebnisse Zeigen Sie Folgendes: Das ULIP-2-Framework weist eine gewisse Robustheit gegenüber verschiedenen Top-5-Standards auf. Fazit Das von Salesforce AI, der Stanford University und der University of Texas at Austin gemeinsam veröffentlichte ULIP-Projekt (CVPR2023) und ULIP-2 verändern den Bereich des 3D-Verständnisses. ULIP-2 wurde weiterentwickelt, um allgemeine Sprachbeschreibungen für 3D-Objekte zu generieren, eine große Anzahl dreimodaler Datensätze zu erstellen und als Open Source bereitzustellen, und dieser Prozess erfordert keine manuelle Annotation. Diese Projekte setzen neue Maßstäbe im 3D-Verständnis und ebnen den Weg für eine Zukunft, in der Maschinen unsere dreidimensionale Welt wirklich verstehen. Team Salesforce AI: Stanford University: Prof. Silvio Savarese, Prof. Juan Carlos Niebles, Prof. Jiajun Wu (Wu Jiajun). UT Austin: Prof. Roberto Martín-Martín. 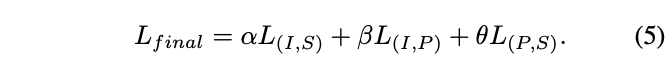
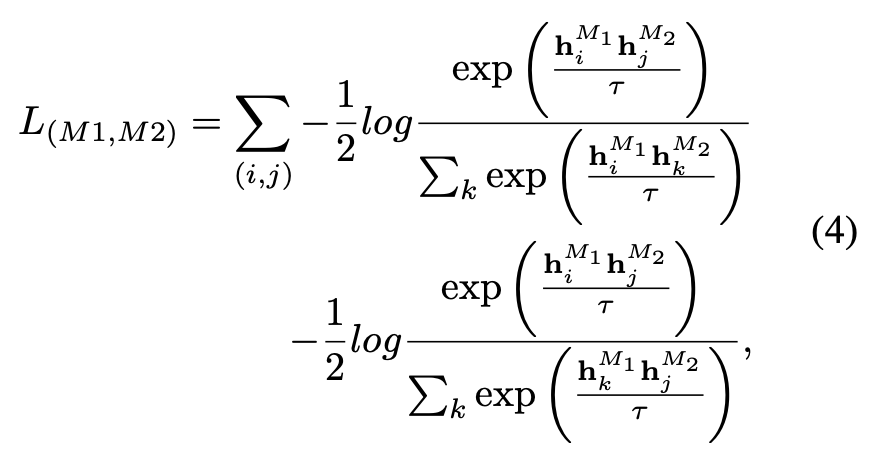

ULIP-2

Experimentelle Ergebnisse
Ablationsexperiment
 In „ULIP-2: Towards Scalable Multimodal Pre-training for 3D Understanding“ untersuchte der Autor die Auswirkungen verschiedener groß angelegter multimodaler Modelle auf das vorab trainierte Framework. Die Ergebnisse sind wie folgt:
In „ULIP-2: Towards Scalable Multimodal Pre-training for 3D Understanding“ untersuchte der Autor die Auswirkungen verschiedener groß angelegter multimodaler Modelle auf das vorab trainierte Framework. Die Ergebnisse sind wie folgt: 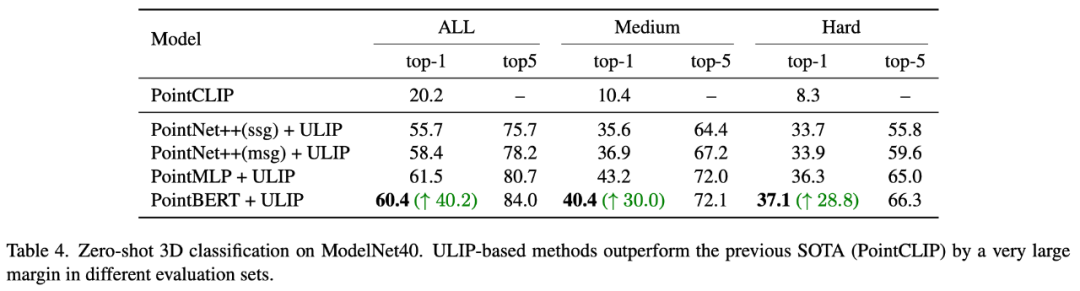 In ULIP-2 untersuchte der Autor auch, wie sich die Verwendung einer unterschiedlichen Anzahl von Ansichten zur Generierung des trimodalen Datensatzes auf die Gesamtleistung vor dem Training auswirken würde:
In ULIP-2 untersuchte der Autor auch, wie sich die Verwendung einer unterschiedlichen Anzahl von Ansichten zur Generierung des trimodalen Datensatzes auf die Gesamtleistung vor dem Training auswirken würde: 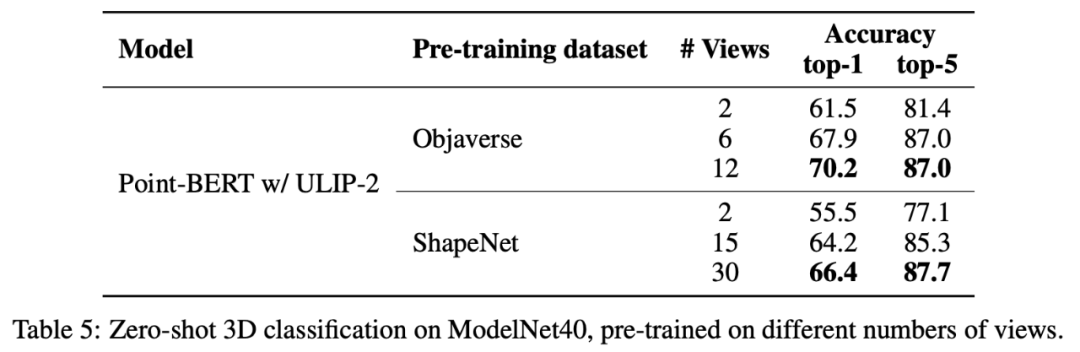 Dies unterstützt auch den Punkt in ULIP-2, dass sich eine umfassendere und vielfältigere Sprachbeschreibung positiv auf das multimodale Vortraining auswirken wird.
Dies unterstützt auch den Punkt in ULIP-2, dass sich eine umfassendere und vielfältigere Sprachbeschreibung positiv auf das multimodale Vortraining auswirken wird. 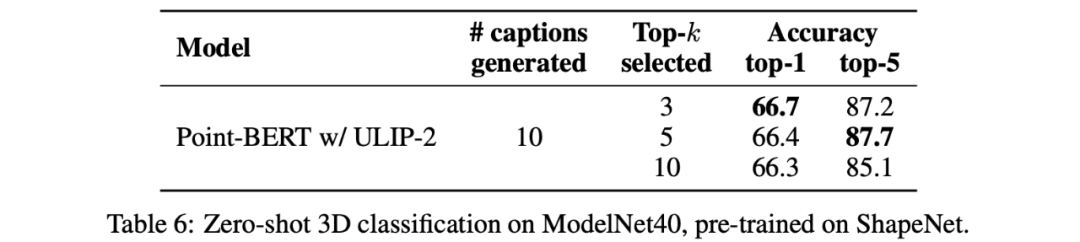
ULIP vereint verschiedene Modalitäten in einem einheitlichen Raum, verbessert das Lernen von 3D-Funktionen und ermöglicht modalübergreifende Anwendungen.
Le Xue, Mingfei Gao, Chen Xing, Ning Yu, Shu Zhang, Junnan Li (Li Junnan), Caiming Xiong (Xiong Caiming), Ran Xu (Xu Ran), Juan Carlos Niebles, Silvio Savarese.
Das obige ist der detaillierte Inhalt vonDaten müssen nicht beschriftet werden, „3D-Verständnis' tritt in die Ära des multimodalen Vortrainings ein! Die ULIP-Serie ist vollständig Open Source und aktualisiert SOTA. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 vscode erstellt eine HTML-Dateimethode
vscode erstellt eine HTML-Dateimethode
 So erhalten Sie eine URL-Adresse
So erhalten Sie eine URL-Adresse
 Was tun, wenn der Ordner „Dokumente' beim Einschalten des Computers angezeigt wird?
Was tun, wenn der Ordner „Dokumente' beim Einschalten des Computers angezeigt wird?
 So überspringen Sie die Netzwerkverbindung während der Win11-Installation
So überspringen Sie die Netzwerkverbindung während der Win11-Installation
 Was sind die Grundkomponenten eines Computers?
Was sind die Grundkomponenten eines Computers?
 So heben Sie Bargeld bei Yiouokex ab
So heben Sie Bargeld bei Yiouokex ab
 Einführung in Java-Zugriffskontrollmodifikatoren
Einführung in Java-Zugriffskontrollmodifikatoren
 Eine vollständige Liste häufig verwendeter öffentlicher DNS
Eine vollständige Liste häufig verwendeter öffentlicher DNS

























