


Eine Feinabstimmungsschulung, die 220 Stunden dauerte, wurde gestern abgeschlossen. Die Hauptaufgabe bestand darin, ein Dialogmodell auf CHATGLM-6B zu optimieren, das Datenbankfehlerinformationen genauer diagnostizieren kann.
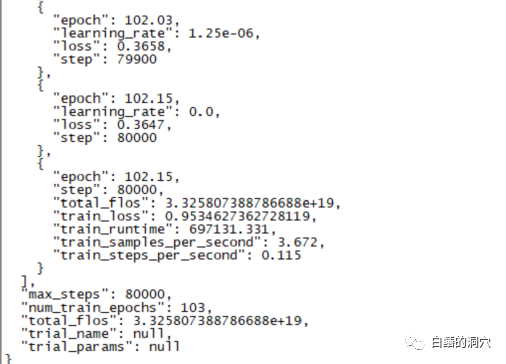
Allerdings war das Endergebnis dieser Schulung, auf die ich fast zehn Tage gewartet habe, enttäuschend. Im Vergleich zu der Schulung, die ich zuvor mit einer kleineren Stichprobenabdeckung durchgeführt habe, war der Unterschied ziemlich groß.
Dieses Ergebnis ist immer noch etwas enttäuschend. Dieses Modell hat grundsätzlich keinen praktischen Wert. Es scheint, dass die Parameter und der Trainingssatz neu angepasst werden müssen und das Training erneut durchgeführt werden muss. Das Training großer Sprachmodelle ist ein Wettrüsten, und ohne gute Ausrüstung ist es unmöglich zu spielen. Es scheint, dass wir auch die Laborausrüstung aufrüsten müssen, sonst werden wir ein paar zehn Tage verschwenden.
Nach den kürzlich gescheiterten Feinabstimmungsschulungen zu urteilen, ist die Feinabstimmungsschulung kein einfacher Weg. Verschiedene Aufgabenziele werden für das Training miteinander kombiniert. Unterschiedliche Aufgabenziele erfordern möglicherweise unterschiedliche Trainingsparameter, sodass der endgültige Trainingssatz nicht in der Lage ist, die Anforderungen bestimmter Aufgaben zu erfüllen. Daher ist PTUNING nur für eine sehr bestimmte Aufgabe geeignet und nicht unbedingt für gemischte Aufgaben. Modelle, die auf gemischte Aufgaben ausgerichtet sind, müssen möglicherweise FINETUNE verwenden. Das ähnelt dem, was alle sagten, als ich vor ein paar Tagen mit einem Freund kommunizierte.
Da das Trainieren des Modells relativ schwierig ist, haben einige Leute es tatsächlich aufgegeben, das Modell selbst zu trainieren, und vektorisieren stattdessen die lokale Wissensbasis für einen genaueren Abruf und verwenden dann AUTOPROMPT, um aus den Abrufergebnissen automatische Eingabeaufforderungen zu generieren . Fragen Sie nach dem Sprachmodell. Dieses Ziel lässt sich mit Langchain leicht erreichen.
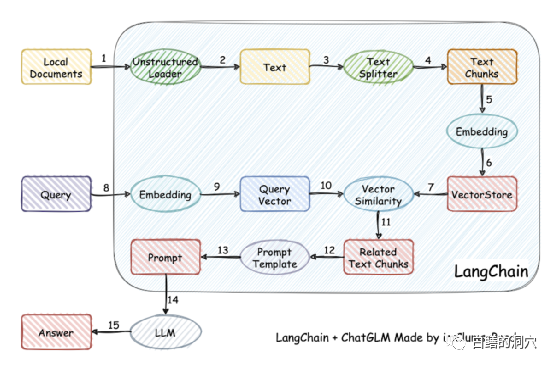
Das Arbeitsprinzip besteht darin, das lokale Dokument als Text über den Loader zu laden, den Text dann in Textfragmente aufzuteilen und diese nach der Codierung zur Verwendung in Abfragen in den Vektorspeicher zu schreiben. Nachdem die Abfrageergebnisse vorliegen, werden über die Eingabeaufforderungsvorlage automatisch Eingabeaufforderungen zum Stellen von Fragen an LLM erstellt, und LLM generiert die endgültige Antwort.
Ein weiterer wichtiger Punkt in dieser Arbeit ist die genauere Suche nach Wissen in der lokalen Wissensdatenbank. Dies wird durch die Vektorisierung und Suche nach lokalen Wissensdatenbanken in Chinesisch erreicht Es gibt viele Lösungen für Englisch. Sie können eine auswählen, die besser zu Ihrer Wissensbasis passt.
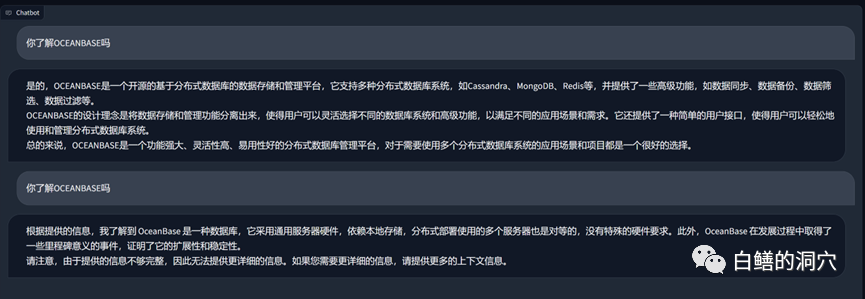
Das Obige ist eine Frage und Antwort, die auf Vicuna-13b über die Wissensdatenbank zu OB durchgeführt wurde. Das Obige ist die Antwort auf die Möglichkeit, LLM direkt zu nutzen, ohne die lokale Wissensdatenbank zu nutzen. Das Folgende ist die Ladeantwort nach dem Zugriff auf die lokale Wissensdatenbank. Es ist ersichtlich, dass die Leistungsverbesserung ziemlich offensichtlich ist.
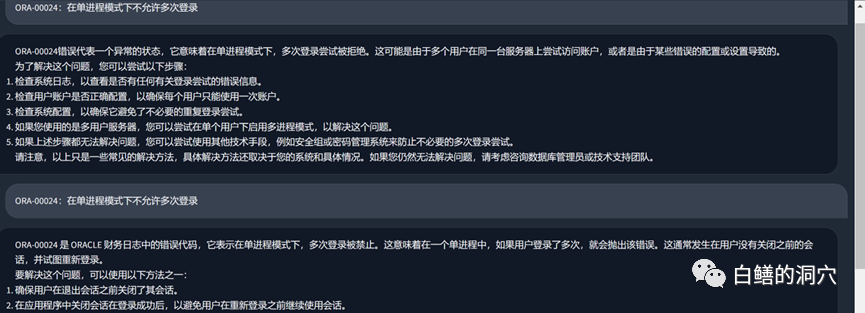
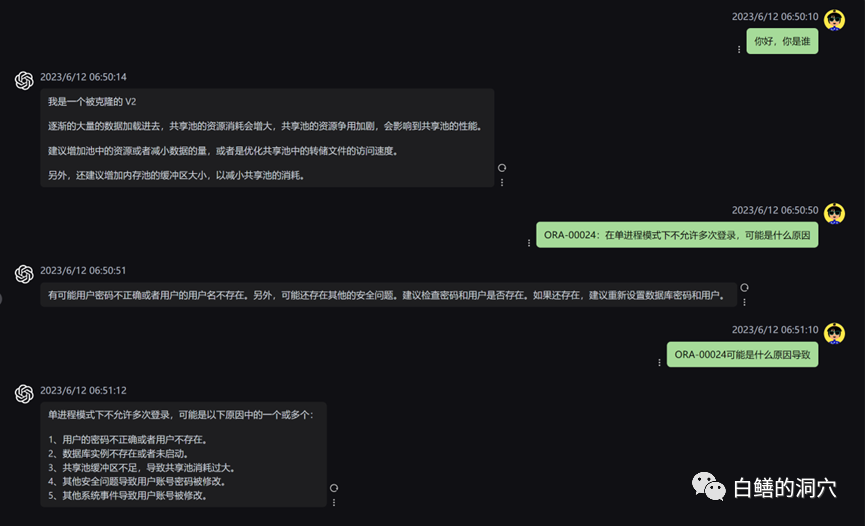
Schauen wir uns jetzt das ORA-Fehlerproblem an. Nach dem Laden der lokalen Wissensdatenbank war die Antwort immer noch recht zufriedenstellend Text sind ebenfalls Fehler in unserer Wissensdatenbank. Tatsächlich wird der von PTUNING verwendete Trainingssatz auch über diese lokale Wissensdatenbank generiert.
Wir können einige Erfahrungen aus den Fallstricken sammeln, auf die wir in letzter Zeit gestoßen sind. Erstens ist der Schwierigkeitsgrad des Ptunings viel höher als wir dachten. Obwohl für das Ptuning weniger Ausrüstung erforderlich ist als für das Finetuning, ist der Trainingsschwierigkeit überhaupt nicht gering. Zweitens ist es gut, die lokale Wissensdatenbank über Langchain und Autoprompt zu nutzen, um die LLM-Funktionen zu verbessern. Bei den meisten Unternehmensanwendungen sollten Sie in der Lage sein, entsprechende Ergebnisse zu erzielen, solange die lokale Wissensdatenbank sortiert und eine geeignete Vektorisierungslösung ausgewählt wird sind nicht schlechter als der PTUNING/FINETUNE-Effekt. Drittens ist, wie bereits beim letzten Mal erwähnt, die Fähigkeit des LLM von entscheidender Bedeutung. Als Basismodell muss ein leistungsfähiges LLM ausgewählt werden. Jedes eingebettete Modell kann die Fähigkeiten nur teilweise verbessern und kann keine entscheidende Rolle spielen. Viertens verfügt Vicuna-13b für datenbankbezogenes Wissen über wirklich gute Fähigkeiten.
Ich muss heute Morgen früh zum Kunden gehen, um eine Kommunikation zu führen, deshalb werde ich nur ein paar Sätze schreiben. Wenn Sie dazu eine Meinung haben, hinterlassen Sie bitte eine Nachricht zur Diskussion (die Diskussion ist nur für Sie und mich sichtbar). Ich hoffe, dass es Mitreisende gibt, die mir einen Rat geben können.
Das obige ist der detaillierte Inhalt vonEin Artikel darüber, wie Sie die Leistung von LLM mithilfe einer lokalen Wissensdatenbank optimieren können. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was ist Optimierung?
Was ist Optimierung?
 Keyword-Optimierungssoftware von Baidu
Keyword-Optimierungssoftware von Baidu
 Baidu SEO-Methode zur Optimierung des Keyword-Rankings
Baidu SEO-Methode zur Optimierung des Keyword-Rankings
 Wie ist die Leistung von PHP8?
Wie ist die Leistung von PHP8?
 Wie ist die Leistung von thinkphp?
Wie ist die Leistung von thinkphp?
 Welche Methoden der Fernwartung von Computern gibt es?
Welche Methoden der Fernwartung von Computern gibt es?
 Ethereum-Preisangebote
Ethereum-Preisangebote
 Einführung in die Verwendung der Achsenfunktion in Matlab
Einführung in die Verwendung der Achsenfunktion in Matlab

























