


Vor einiger Zeit verdrängte der junge Falcon LLaMA in der LLM-Rangliste und löste damit Wellen in der gesamten Community aus.
Aber ist Falcon wirklich besser als LLaMA?
Kurze Antwort: Wahrscheinlich nicht.
Das Team von Fu Yao hat eine detailliertere Bewertung des Modells vorgenommen:
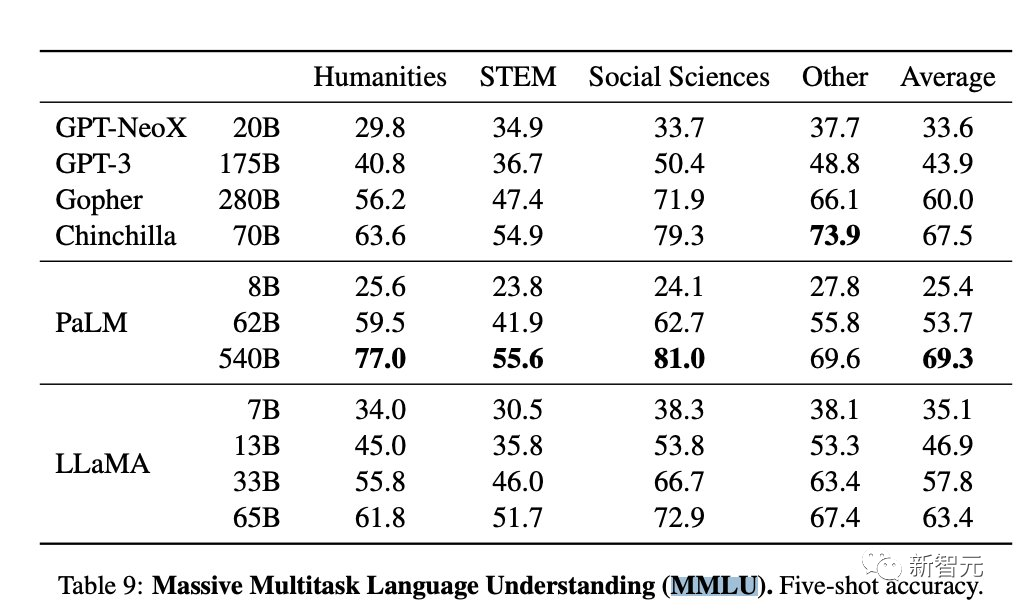
„Wir haben die Bewertung von LLaMA 65B auf MMLU reproduziert und einen Wert von 61,4 erhalten, was nahe am offiziellen Wert liegt.“ (63,4). Viel höher als die Punktzahl im Open LLM Leaderboard (48,8) und deutlich höher als die des Falcon (52,7).
Derzeit wurden der Code und die Testmethoden auf Github veröffentlicht. 
Es bestehen Zweifel daran, dass Falcon LLaMA übertrifft, LeCun äußerte seine Position, das Problem des Testskripts ...
Die wahre Stärke von LLaMA
Manche Menschen haben jedoch ihre Zweifel. 
Zuerst fragte ein Internetnutzer, woher diese LLaMA-Zahlen kämen. Sie schienen nicht mit den Papierzahlen übereinzustimmen ...
Später fragte OpenAI-Wissenschaftler Andrej Karpathy auch, warum LLaMA 65B in der Open LLM-Rangliste steht Die Punktzahl lag deutlich unter der offiziellen (48,8 vs. 63,4), um ihre Besorgnis auszudrücken. 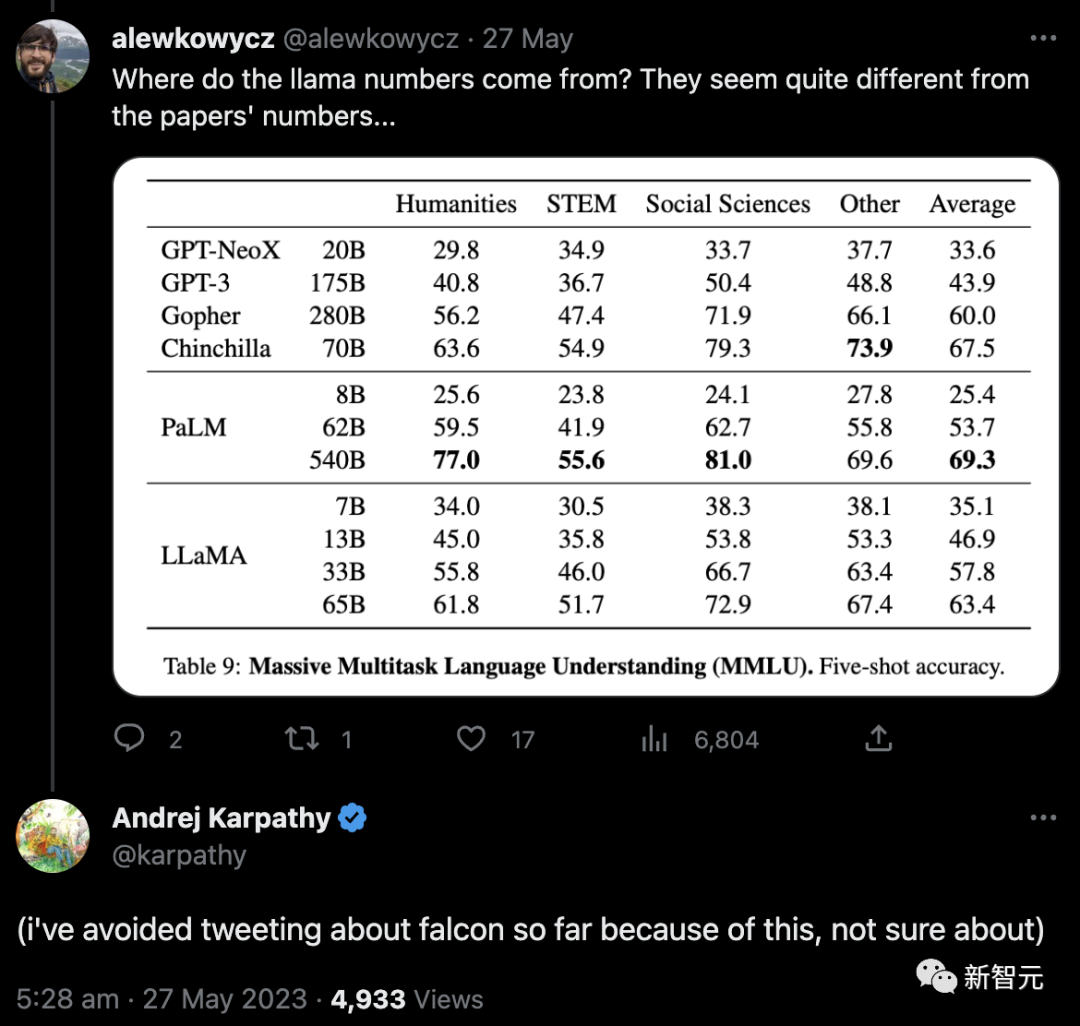
Und beim Posten habe ich es aus diesem Grund bisher vermieden, über Falcons zu twittern, ich bin mir nicht sicher.
Um dieses Problem zu klären, beschlossen Fu Yao und seine Teammitglieder, einen öffentlichen Test auf LLaMA 65B durchzuführen, und das Ergebnis war 61,4 Punkte.
Im Test verwendeten die Forscher keinen besonderen Mechanismus und LLaMA 65B konnte diesen Wert erreichen. 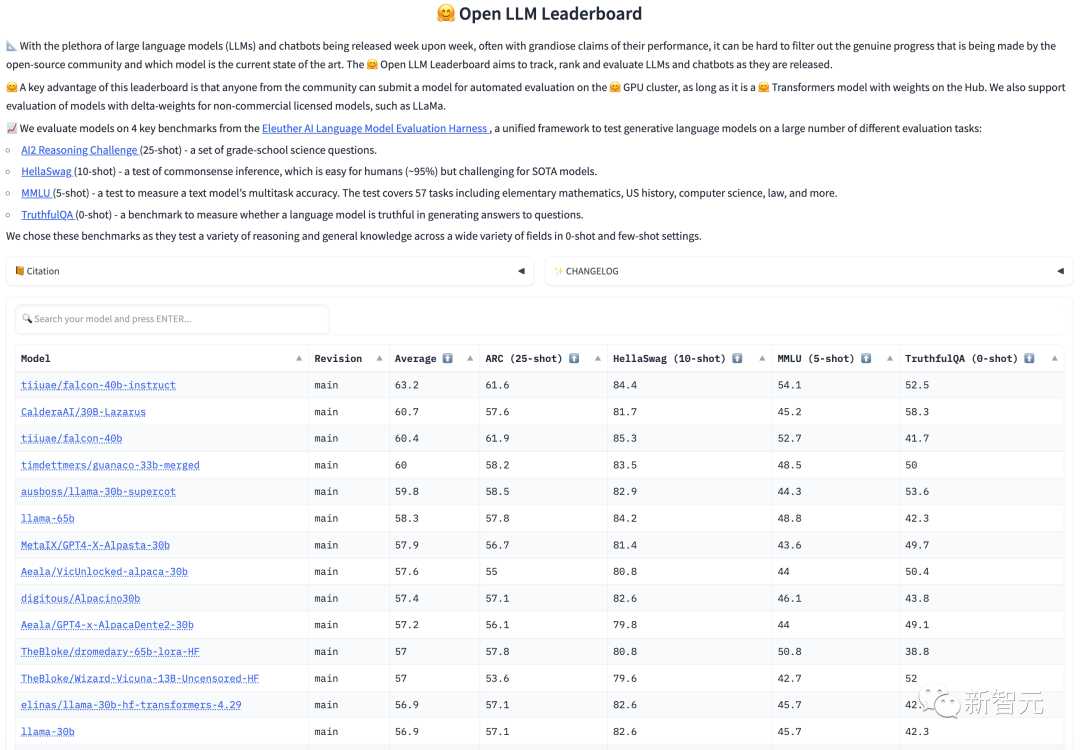
Dieses Ergebnis beweist nur, dass es am besten ist, RLHF auf LLaMA 65B zu verwenden, wenn Sie möchten, dass das Modell ein Niveau nahe GPT-3,5 erreicht.
Basierend auf den Ergebnissen eines Chain-of-Thought Hub-Artikels, der kürzlich von Fu Yaos Team veröffentlicht wurde.
Natürlich sagte Fu Yao, dass ihre Bewertung nicht dazu gedacht war, einen Streit zwischen LLaMA und Falcon auszulösen. Schließlich handelt es sich um großartige Open-Source-Modelle, die einen wesentlichen Beitrag zu diesem Bereich geleistet haben! 
Darüber hinaus verfügt Falcon über eine komfortablere Lizenz, was ihm auch großes Entwicklungspotenzial bietet.
Für diese neueste Rezension wies Netizen BlancheMinerva darauf hin, dass ein fairer Vergleich darin bestehen würde, Falcon auf MMLU mit Standardeinstellungen auszuführen.
Als Antwort sagte Fu Yao, dass dies richtig sei und daran gearbeitet werde und dass die Ergebnisse voraussichtlich in einem Tag vorliegen würden.

Egal wie das Endergebnis ausfällt, Sie müssen wissen, dass der Berg von GPT-4 das Ziel ist, das die Open-Source-Community wirklich verfolgen möchte.
Forscher von Meta lobten Fu Yao für die gute Wiedergabe der Ergebnisse von LLaMa und wiesen auf das Problem des OpenLLM-Rankings hin.
Gleichzeitig stellte er auch einige Fragen zum OpenLLM-Ranking.
Erstens die MMLU-Ergebnisse: LLaMa 65B MMLU-Ergebnisse sind 15 Punkte auf der Bestenliste, aber das Gleiche gilt für das 7B-Modell. Es gibt auch einen kleinen Leistungsunterschied zwischen den Modellen 13B und 30B.
OpenLLM muss sich das unbedingt ansehen, bevor es bekannt gibt, welches Modell das beste ist.
Benchmarks: Wie werden diese Benchmarks ausgewählt?
ARC 25-Schuss und Hellaswag 10-Schuss scheinen für LLM nicht besonders relevant zu sein. Noch besser wäre es, wenn einige generative Benchmarks einbezogen werden könnten. Obwohl generative Benchmarks ihre Grenzen haben, können sie dennoch nützlich sein.

Einzelne Durchschnittspunktzahl: Es ist immer verlockend, die Ergebnisse auf eine einzige Punktzahl zu reduzieren, und die Durchschnittspunktzahl ist am einfachsten.
Aber ist in diesem Fall der Durchschnitt von 4 Benchmarks wirklich nützlich? Ist 1 Punkt bei MMLU dasselbe wie 1 Punkt bei HellaSwag?
In der Welt der schnellen Iteration von LLM ist die Entwicklung einer solchen Rangliste definitiv von Nutzen.

Und auch Lucas Beyer, ein Forscher von Google, äußerte seine Meinung:
Das Verrückte ist, dass NLP-Forscher unterschiedliche Verständnisse für denselben Maßstab haben und dadurch zu völlig unterschiedlichen Ergebnissen führen. Gleichzeitig frage ich einen meiner Kollegen jedes Mal, wenn er eine Metrik implementiert, sofort, ob er tatsächlich prüft, ob der offizielle Code perfekt reproduziert wird, und wenn nicht, verwerfe ich seine Ergebnisse.

Außerdem sagte er, dass meines Wissens unabhängig vom Modell die Ergebnisse des ursprünglichen Benchmarks nicht wirklich reproduziert werden.

Die Internetnutzer wiederholten, dass dies die Realität des LLM-Benchmarks sei …

Apropos Falcon: Es ist tatsächlich unserer Bewertung wert .
Laut LeCun ist Open Source im Zeitalter großer Modelle am wichtigsten.
Nachdem der LLaMA-Code von Meta durchgesickert war, begannen Entwickler aus allen Gesellschaftsschichten, ihn eifrig auszuprobieren.
Falcon ist eine erstaunliche Waffe, die vom Technology Innovation Institute (TII) in Abu Dhabi, Vereinigte Arabische Emirate, entwickelt wurde.
In Bezug auf die Leistung schnitt Falcon bei der Erstveröffentlichung besser ab als LLaMA.
Derzeit gibt es „Falcon“ in drei Versionen – 1B, 7B und 40B.
TII sagte, Falcon sei das bislang leistungsstärkste Open-Source-Sprachmodell. Seine größte Version, Falcon 40B, verfügt über 40 Milliarden Parameter und ist damit immer noch etwas kleiner als LLaMA mit 65 Milliarden Parametern.
Allerdings hat TII zuvor erklärt, dass Falcon trotz seiner geringen Größe eine großartige Leistung bietet.
Faisal Al Bannai, Generalsekretär des Advanced Technology Research Council (ATRC), glaubt, dass die Veröffentlichung von „Falcon“ die Erwerbsmethode von LLM durchbrechen und es Forschern und Unternehmern ermöglichen wird, die innovativsten Anwendungsfälle vorzuschlagen.

Zwei Versionen von FalconLM, Falcon 40B Instruct und Falcon 40B, belegen die ersten beiden der Hugging Face OpenLLM-Rangliste, während Metas LLaMA auf dem dritten Platz liegt.
Und genau das ist das Problem mit den oben genannten Rankings.
Obwohl das „Falcon“-Papier noch nicht öffentlich veröffentlicht wurde, wurde Falcon 40B umfassend anhand eines sorgfältig geprüften 1-Billion-Token-Netzwerkdatensatzes trainiert.
Forscher haben herausgefunden, dass „Falcon“ großen Wert darauf legt, während des Trainingsprozesses eine hohe Leistung bei großen Datenmengen zu erzielen.
Was wir alle wissen ist, dass LLM sehr empfindlich auf die Qualität von Trainingsdaten reagiert, weshalb Forscher viel Mühe darauf verwenden, eine Datenpipeline aufzubauen, die eine effiziente Verarbeitung auf Zehntausenden von CPU-Kernen durchführen kann.
Der Zweck besteht darin, durch Filterung und Deduplizierung hochwertige Inhalte aus dem Internet zu extrahieren.
Derzeit hat TII einen verfeinerten Netzwerkdatensatz veröffentlicht, bei dem es sich um einen sorgfältig gefilterten und deduplizierten Datensatz handelt. Die Praxis hat gezeigt, dass es sehr effektiv ist.
Das Modell, das nur mit diesem Datensatz trainiert wird, kann mit anderen LLMs mithalten oder diese sogar in der Leistung übertreffen. Dies zeigt die hervorragende Qualität und den Einfluss von „Falcon“.

Darüber hinaus ist das Falcon-Modell auch mehrsprachig.
Es versteht Englisch, Deutsch, Spanisch und Französisch und beherrscht auch einige kleine europäische Sprachen wie Niederländisch, Italienisch, Rumänisch, Portugiesisch, Tschechisch, Polnisch und Schwedisch.
Falcon 40B ist nach der Veröffentlichung des H2O.ai-Modells auch das zweite wirklich Open-Source-Modell.
Darüber hinaus gibt es noch einen weiteren sehr wichtigen Punkt – Falcon ist derzeit das einzige Open-Source-Modell, das kommerziell kostenlos genutzt werden kann.
Zu Beginn verlangte TII, dass eine „Nutzungssteuer“ von 10 % erhoben wird, wenn Falcon für kommerzielle Zwecke genutzt wird und mehr als 1 Million US-Dollar an anrechenbarem Einkommen generiert.
Aber es dauerte nicht lange, bis die reichen Magnaten des Nahen Ostens diese Einschränkung aufhoben.
Zumindest vorerst wird die gesamte kommerzielle Nutzung und Feinabstimmung von Falcon kostenlos sein.
Die Reichen sagten, dass sie mit diesem Modell vorerst kein Geld verdienen müssen.
Darüber hinaus wirbt TII auch um Kommerzialisierungspläne aus der ganzen Welt.
Für potenzielle wissenschaftliche Forschungs- und Kommerzialisierungslösungen werden sie auch mehr „Trainingsrechenleistungsunterstützung“ bereitstellen oder weitere Kommerzialisierungsmöglichkeiten bieten.

Das heißt einfach: Solange das Projekt gut ist, ist das Modell kostenlos! Genug Rechenleistung! Wenn Sie nicht genug Geld haben, können wir es trotzdem für Sie einsammeln!
Für Start-ups ist dies einfach eine „One-Stop-Lösung für KI-Großmodell-Unternehmertum“ vom Nahost-Tycoon.
Ein wichtiger Aspekt des Wettbewerbsvorteils von FalconLM ist laut dem Entwicklungsteam die Auswahl der Trainingsdaten.
Das Forschungsteam hat einen Prozess entwickelt, um hochwertige Daten aus öffentlich gecrawlten Datensätzen zu extrahieren und doppelte Daten zu entfernen.
Nach der gründlichen Bereinigung redundanter und doppelter Inhalte blieben 5 Billionen Token erhalten – genug, um ein leistungsstarkes Sprachmodell zu trainieren.
Der 40B Falcon LM verwendet 1 Billion Token für das Training, und die 7B-Version des Modell-Trainingstokens erreicht 1,5 Billionen.
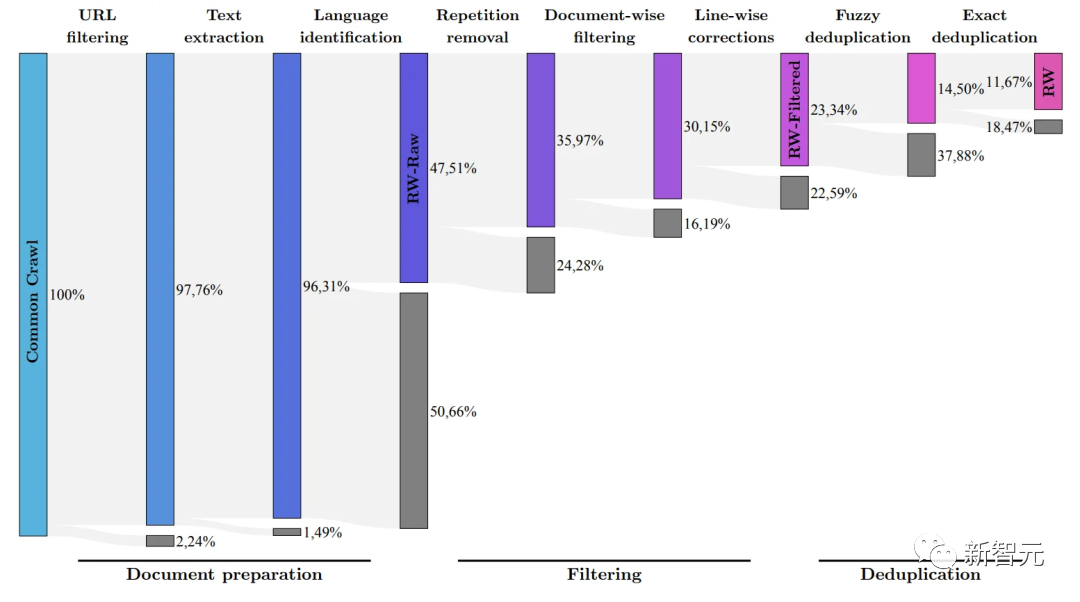
(Ziel des Forschungsteams ist es, mithilfe des RefinedWeb-Datensatzes nur Rohdaten höchster Qualität aus Common Crawl herauszufiltern)
Darüber hinaus sind die Trainingskosten von Falcon relativ besser kontrollierbar.
TII sagte, dass Falcon im Vergleich zu GPT-3 erhebliche Leistungsverbesserungen erzielte und dabei nur 75 % des Trainings-Rechenbudgets nutzte.
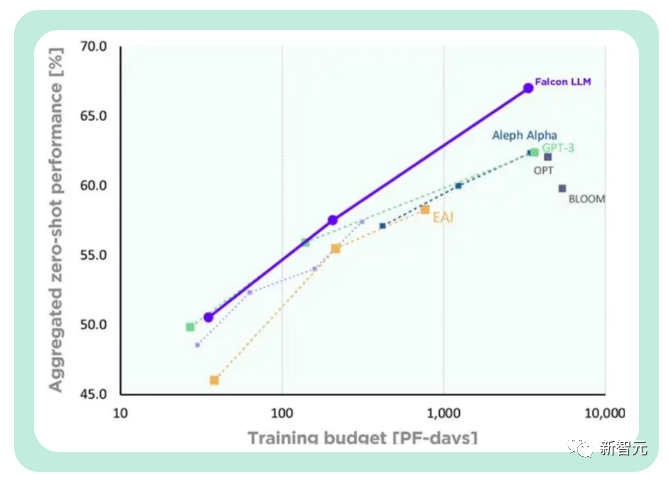
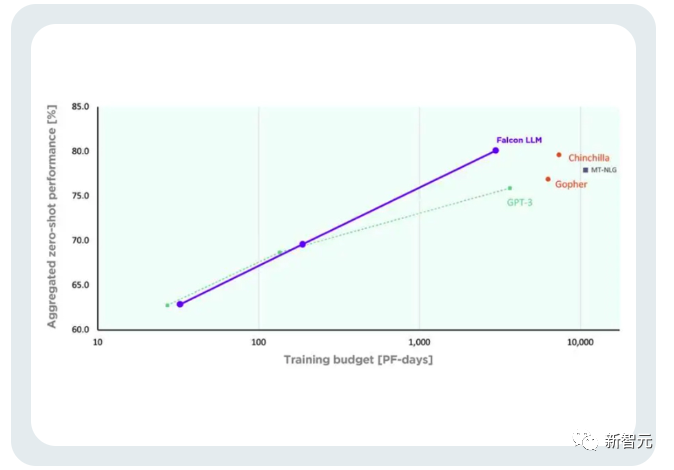
Und während der Inferenz werden nur 20 % der Rechenzeit benötigt, wodurch eine effiziente Nutzung der Rechenressourcen erfolgreich erreicht wird.
Das obige ist der detaillierte Inhalt vonLLaMA schlagen? Die Rangliste des mächtigsten „Falken' in der Geschichte ist fraglich. Fu Yao hat sieben Codezeilen persönlich getestet und LeCun hat sie als „Gefällt mir' weitergeleitet. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So nutzen Sie digitale Währungen
So nutzen Sie digitale Währungen
 So öffnen Sie PHP-Dateien auf einem Mobiltelefon
So öffnen Sie PHP-Dateien auf einem Mobiltelefon
 Was sind die häufig verwendeten Tastenkombinationen in WPS?
Was sind die häufig verwendeten Tastenkombinationen in WPS?
 So legen Sie ein geplantes Herunterfahren in UOS fest
So legen Sie ein geplantes Herunterfahren in UOS fest
 Java-Ausnahmebehandlung
Java-Ausnahmebehandlung
 So verwenden Sie Etikettenetiketten
So verwenden Sie Etikettenetiketten
 OuYi Exchange-App herunterladen
OuYi Exchange-App herunterladen
 Einführung in die Hauptarbeitsinhalte des Backends
Einführung in die Hauptarbeitsinhalte des Backends








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



