


Laut Nachrichten vom 8. Juni wurde das inländische multimodale große Sprachmodell TigerBot kürzlich offiziell veröffentlicht, einschließlich zwei Versionen mit 7 Milliarden Parametern und 180 Milliarden Parametern. Es ist jetzt Open Source auf GitHub.
▲ Bildquelle GitHub-Seite von TigerBot
Es wird berichtet, dass die von TigerBot eingeführten Innovationen hauptsächlich in Folgendem liegen:
Darüber hinaus hat dieses Modell auch geeignetere Optimierungen vom Tokenizer bis zum Trainingsalgorithmus für die unregelmäßigere Verteilung der chinesischen Sprache vorgenommen.
Forscher Chen Ye sagte auf der offiziellen Website von Hubo Technology: „Dieses Modell kann mit nur einer kleinen Anzahl von Parametern schnell verstehen, welche Art von Fragen Menschen stellen.“ Laut der automatischen Auswertung des OpenAI InstructGPT-Papiers zum öffentlichen NLP-Datensatz , TigerBot-7B hat 96 % der Gesamtleistung des OpenAI-Modells gleicher Größe erreicht.“ Modell“ enthält der Open-Source-Code grundlegenden Trainings- und Inferenzcode, Quantisierungs- und Inferenzcode für das Dual-Card-Inferenz-180B-Modell. Die Daten umfassen 100 G Vortrainingsdaten und 1 G oder 1 Million Daten für die überwachte Feinabstimmung.
IT House-Freunde können 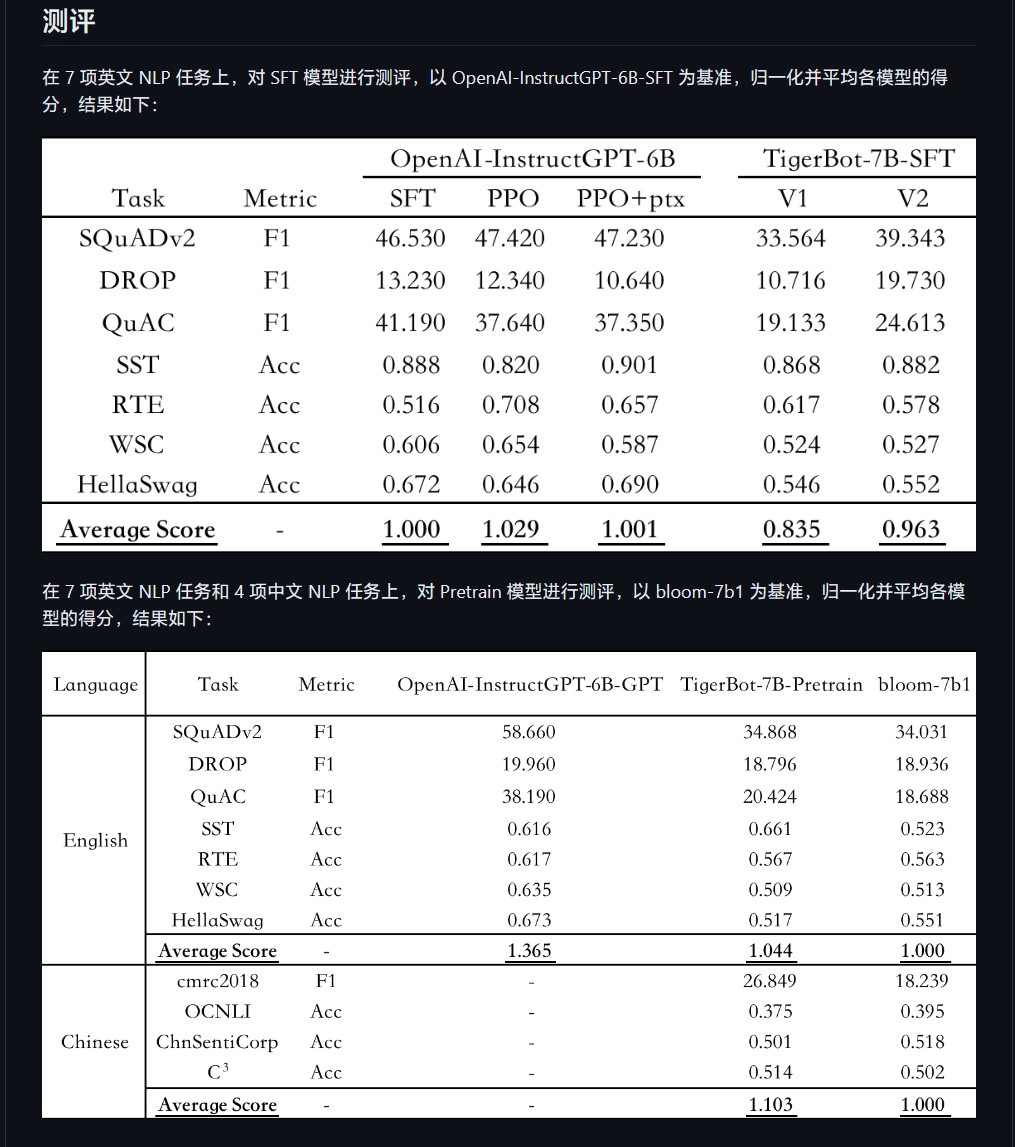 die Open-Source-Projekte von GitHub hier finden
die Open-Source-Projekte von GitHub hier finden
Das obige ist der detaillierte Inhalt vonDer Effekt kann 96 % des entsprechenden Modells von OpanAI erreichen, und das inländische Open-Source-KI-Sprachmodell TigerBot wird veröffentlicht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So lösen Sie das Problem, dass Dateien auf dem Computer nicht gelöscht werden
So lösen Sie das Problem, dass Dateien auf dem Computer nicht gelöscht werden
 vcruntime140.dll kann nicht gefunden werden und die Codeausführung kann nicht fortgesetzt werden
vcruntime140.dll kann nicht gefunden werden und die Codeausführung kann nicht fortgesetzt werden
 So verwenden Sie Cloud-Speicher
So verwenden Sie Cloud-Speicher
 So sperren Sie den Bildschirm auf oppo11
So sperren Sie den Bildschirm auf oppo11
 Netzwerkkabel ist abgezogen
Netzwerkkabel ist abgezogen
 Tutorial zum Anpassen des Zeilenabstands in Word-Dokumenten
Tutorial zum Anpassen des Zeilenabstands in Word-Dokumenten
 Verwendung der Resample-Funktion
Verwendung der Resample-Funktion
 Quantitative Handelsplattform für digitale Währungen
Quantitative Handelsplattform für digitale Währungen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



