


Heart of Machine veröffentlicht
Heart of Machine-Redaktion
Heute beginnt offiziell die jährliche Hochschulaufnahmeprüfung.
Der Unterschied zu den Vorjahren besteht darin, dass Kandidaten im ganzen Land in den Prüfungsraum stürmen, einige große Sprachmodelle jedoch auch zu besonderen Akteuren in diesem Wettbewerb geworden sind.
Da große KI-Sprachmodelle zunehmend eine nahezu menschliche Intelligenz aufweisen, werden zunehmend sehr schwierige und umfassende Prüfungen für Menschen eingeführt, um den Intelligenzgrad von Sprachmodellen zu bewerten.
Zum Beispiel testet OpenAI im technischen Bericht zu GPT-4 hauptsächlich die Fähigkeiten des Modells durch Prüfungen in verschiedenen Bereichen, und auch die hervorragende „Testfähigkeit“, die GPT-4 zeigt, ist unerwartet.
Wie sind die Ergebnisse der Prüfungsarbeit zur College-Aufnahmeprüfung der Chinese Language Model Challenge? Kann es mit ChatGPT mithalten? Werfen wir einen Blick auf die Leistung eines „Kandidaten“.
Umfassender „großer Test“: „Scholar Puyu“ hat viele Ergebnisse vor ChatGPT
Kürzlich haben SenseTime und Shanghai AI Laboratory zusammen mit der Chinesischen Universität Hongkong, der Fudan-Universität und der Shanghai Jiao Tong-Universität das große Sprachmodell „Scholar Puyu“ (InternLM) mit 100 Milliarden Parametern veröffentlicht.
„Scholar Puyu“ verfügt über 104 Milliarden Parameter und wird anhand eines mehrsprachigen, hochwertigen Datensatzes trainiert, der 1,6 Billionen Token enthält.
Umfassende Bewertungsergebnisse zeigen, dass „Scholar Puyu“ nicht nur bei mehreren Testaufgaben wie Wissensbeherrschung, Leseverständnis, mathematisches Denken, mehrsprachige Übersetzung usw. gut abschneidet, sondern auch über starke umfassende Fähigkeiten verfügt und somit bei der umfassenden Prüfung hervorragende Ergebnisse erzielt Es hat in vielen chinesischen Prüfungen Ergebnisse erzielt, die ChatGPT übertreffen, einschließlich des Datensatzes (GaoKao) für verschiedene Fächer der chinesischen Hochschulaufnahmeprüfung.
Das gemeinsame Team von „Scholar·Puyu“ hat mehr als 20 Bewertungen ausgewählt, um es zu testen, darunter die weltweit einflussreichsten vier umfassenden Prüfungsbewertungssätze:
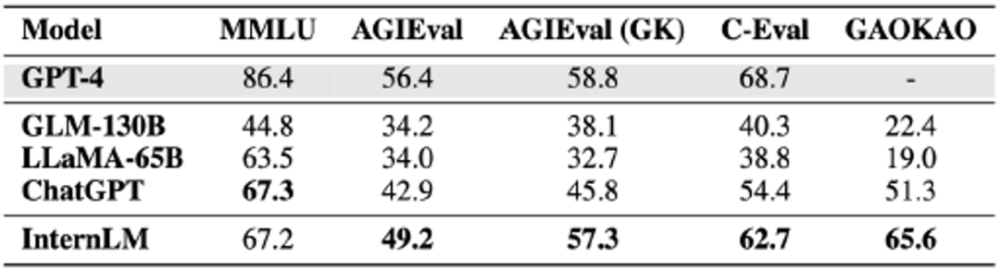
Obwohl „Scholar·Puyu“ bei der Prüfungsauswertung hervorragende Ergebnisse erzielte, zeigt sich in der Auswertung auch, dass große Sprachmodelle noch viele Einschränkungen aufweisen. „Scholar Puyu“ ist durch die Kontextfensterlänge von 2 KB begrenzt (die Kontextfensterlänge von GPT-4 beträgt 32 KB), und es gibt offensichtliche Einschränkungen beim Verständnis langer Texte, beim komplexen Denken, beim Schreiben von Code und beim Ableiten mathematischer Logik. Darüber hinaus weisen große Sprachmodelle in tatsächlichen Gesprächen immer noch häufige Probleme wie Illusion und konzeptionelle Verwirrung auf. Aufgrund dieser Einschränkungen ist die Verwendung großer Sprachmodelle in offenen Szenarien noch ein weiter Weg.
Ergebnisse von vier umfassenden Untersuchungsauswertungsdatensätzen
MMLU ist ein von der University of California, Berkeley (UC Berkeley), der Columbia University, der University of Chicago und der UIUC gemeinsam erstellter Testbewertungssatz für mehrere Aufgaben. Er umfasst Grundkenntnisse in Mathematik, Physik, Chemie, Informatik und US-Geschichte. Recht, Wirtschaft, Diplomatie usw. Fachgebiet.
Die Ergebnisse der unterteilten Fächer sind in der folgenden Tabelle aufgeführt.
Fett im Bild zeigt das beste Ergebnis an, und unterstrichen zeigt das zweite Ergebnis an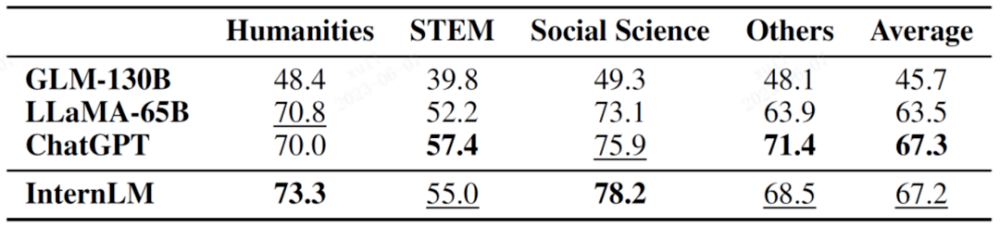
AGIEval ist ein neues Bewertungsset für Fachprüfungen, das dieses Jahr von Microsoft Research vorgeschlagen wurde. Sein Hauptziel besteht darin, die Fähigkeiten von Sprachmodellen durch orientierte Prüfungen zu bewerten und so einen Vergleich zwischen Modellintelligenz und menschlicher Intelligenz zu erreichen.
Dieser Bewertungssatz besteht aus 19 Bewertungspunkten, die auf verschiedenen Prüfungen in China und den Vereinigten Staaten basieren, darunter Chinas College-Aufnahmeprüfungen, juristische Prüfungen und wichtige Prüfungen wie SAT, LSAT, GRE und GMAT in den Vereinigten Staaten. Es ist erwähnenswert, dass 9 dieser 19 Hauptfächer aus der chinesischen Hochschulaufnahmeprüfung stammen und normalerweise als wichtige Bewertungsuntergruppe AGIEval (GK) aufgeführt sind.
In der folgenden Tabelle handelt es sich bei den mit GK gekennzeichneten Fächern um chinesische Fächer für die Hochschulaufnahmeprüfung.
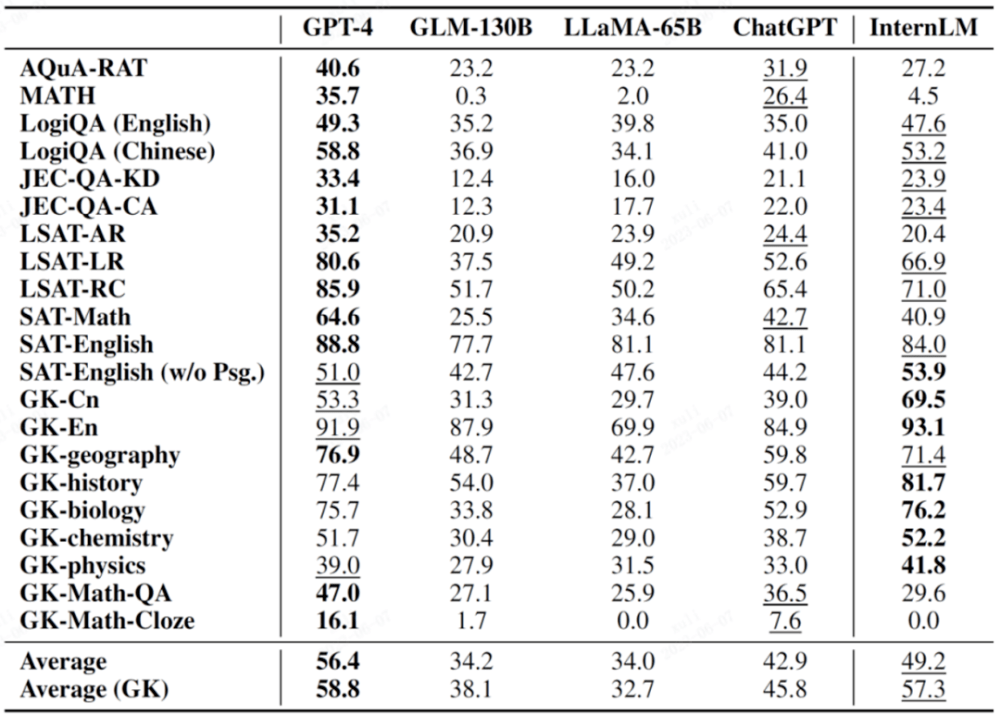
Fett im Bild zeigt das beste Ergebnis an, und unterstrichen zeigt das zweite Ergebnis an
C-Eval ist ein umfassender Prüfungsbewertungssatz für chinesische Sprachmodelle, der gemeinsam von der Shanghai Jiao Tong University, der Tsinghua University und der University of Edinburgh entwickelt wurde.
Es enthält fast 14.000 Prüfungsfragen in 52 Fächern, darunter Mathematik, Physik, Chemie, Biologie, Geschichte, Politik, Computer und andere Fachprüfungen sowie Berufsprüfungen für Beamte, Wirtschaftsprüfer, Rechtsanwälte und Ärzte.
Testergebnisse können über die Bestenliste abgerufen werden.
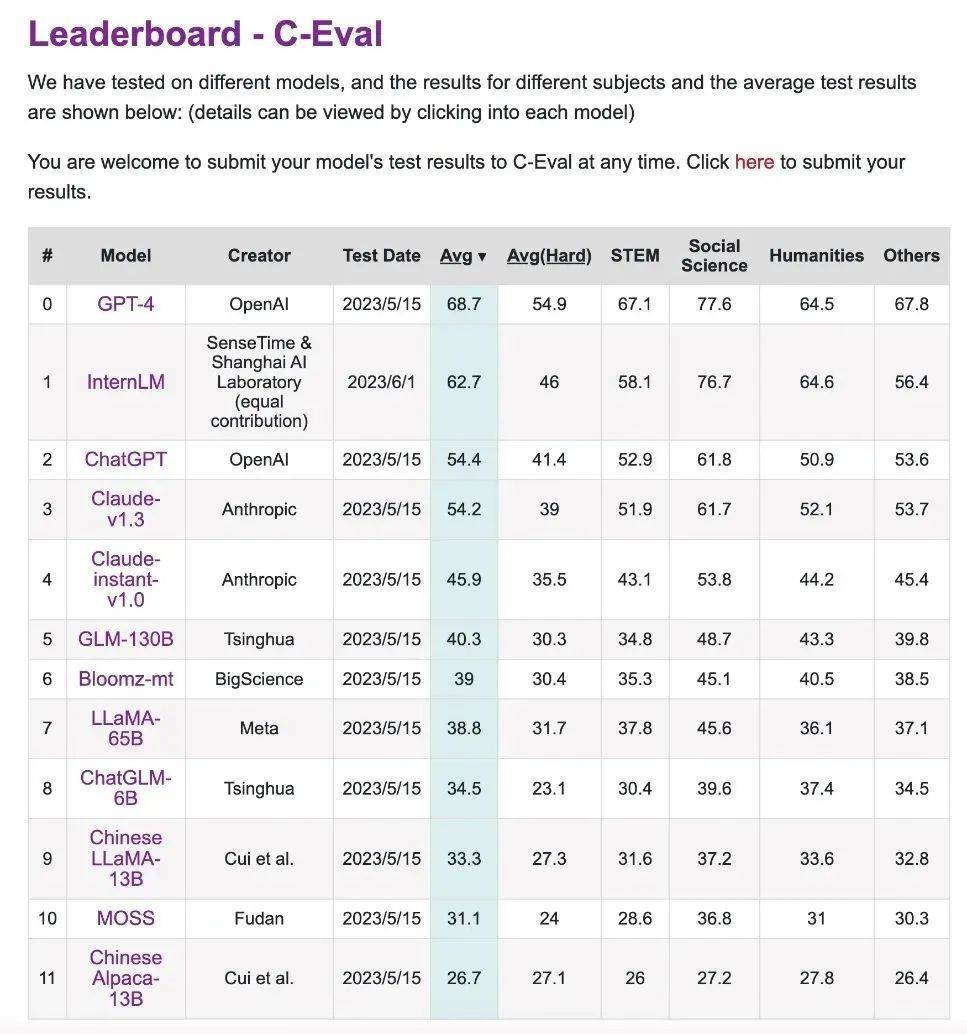
Dieser Link ist die Bestenliste des CEVA-Bewertungswettbewerbs
Gaokao ist ein umfassender Testbewertungssatz, der auf den vom Forschungsteam der Fudan-Universität erstellten Fragen für die chinesische Hochschulaufnahmeprüfung basiert. Er umfasst verschiedene Themen der chinesischen Hochschulaufnahmeprüfung sowie mehrere Fragetypen wie Multiple-Choice- und Ausfüllfragen. Freitext- und Frage-und-Antwort-Fragen.
In der GaoKao-Bewertung führt „Scholar·Puyu“ ChatGPT in mehr als 75 % der Projekte an.
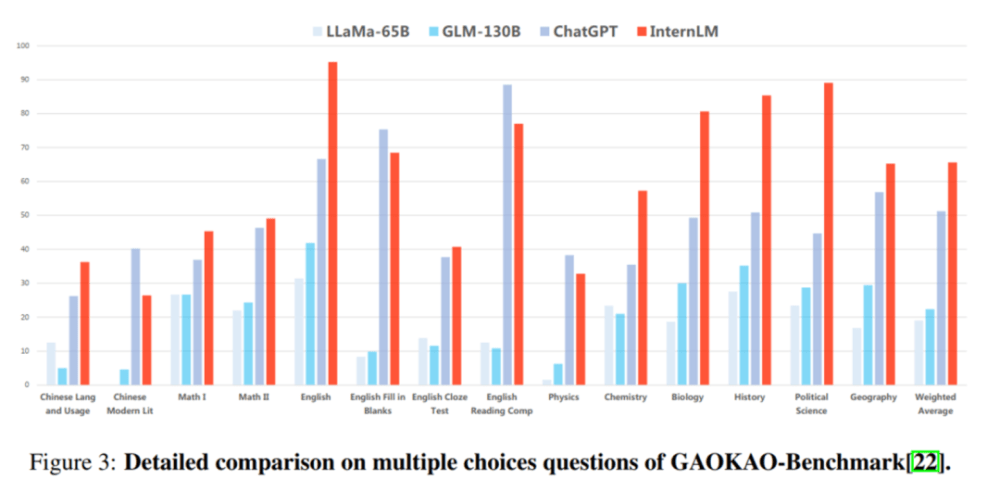
Teilbewertung: Hervorragende Leistung im Leseverständnis und in den Denkfähigkeiten
Um „Parteilichkeit“ zu vermeiden, bewerteten und verglichen die Forscher auch die Subscore-Fähigkeiten von Sprachmodellen wie „Scholar Puyu“ anhand mehrerer akademischer Bewertungssätze.
Die Ergebnisse zeigen, dass „Scholar·Puyu“ nicht nur beim Leseverständnis auf Chinesisch und Englisch gut abschneidet, sondern auch gute Ergebnisse beim mathematischen Denken, bei Programmierfähigkeiten und anderen Bewertungen erzielt.
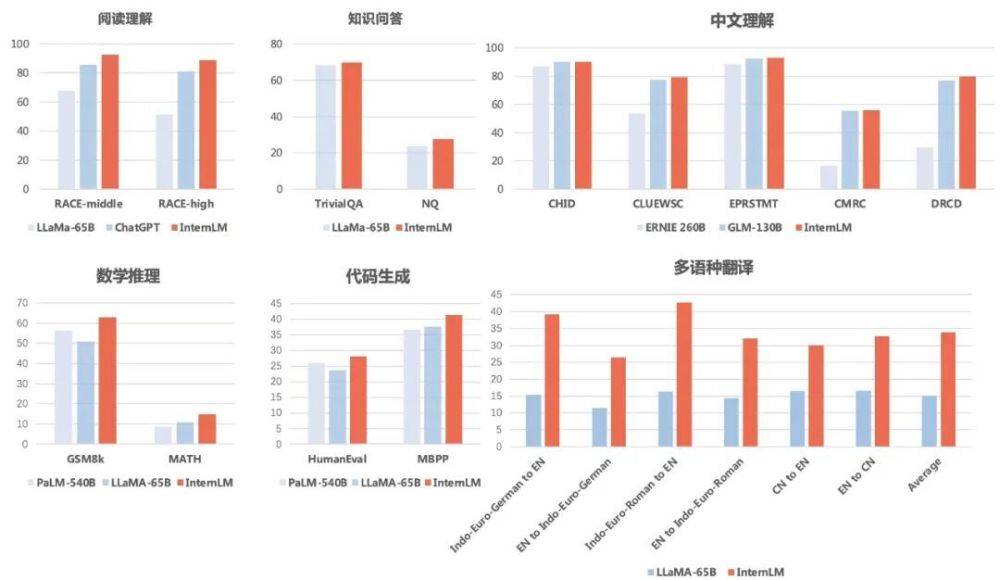
Fragen und AntwortenIn Bezug auf TriviaQA und NaturalQuestions erzielte „Scholar Puyu“ 69,8 und 27,6 und übertraf damit beide LLaMA-65B (Werte von 68,2 und 23,8).
In Sachen Leseverständnis (Englisch) liegt „Scholar·Puyu“ deutlich vor LLaMA-65B und ChatGPT. Puyu erzielte 92,7 bzw. 88,9 Punkte beim Leseverständnis für Englisch in der Mittel- und Oberstufe, 85,6 bzw. 81,2 bei ChatGPT und sogar noch weniger bei LLaMA-65B.
In Bezug auf das Chinesischverständnis übertrafen die Ergebnisse von „Scholar Puyu“ die beiden wichtigsten chinesischen Sprachmodelle ERNIE-260B und GLM-130B bei weitem.
In Bezug auf die mehrsprachige Übersetzung hat „Scholar Puyu“ eine durchschnittliche Punktzahl von 33,9 in der mehrsprachigen Übersetzung und übertrifft damit deutlich LLaMA (durchschnittliche Punktzahl 15,1).
Mathematisches DenkenIn Bezug auf mathematisches Denken erreichte „Scholar Puyu“ in GSM8K und MATH, zwei häufig zur Bewertung verwendeten Mathematiktests, Werte von 62,9 bzw. 14,9 und lag damit deutlich vor Googles PaLM-540B (Wertung von 56,5 und 8,8). ) im Vergleich zu LLaMA-65B (Werte von 50,9 und 10,9).
In Bezug auf die Programmierfähigkeit erzielte „Scholar Puyu“ in den beiden repräsentativsten Bewertungen, HumanEval und MBPP, jeweils 28,1 bzw. 41,4 (nach Feinabstimmung im Codierungsbereich kann die Punktzahl bei HumanEval deutlich auf 45,7 verbessert werden). vor PaLM-540B (Werte 26,2 und 36,8) und LLaMA-65B (Werte 23,7 und 37,7).
Darüber hinaus bewerteten die Forscher auch die Sicherheit von „Scholar Puyu“ im Hinblick auf TruthfulQA (hauptsächlich Bewertung der sachlichen Richtigkeit der Antworten) und CrowS-Pairs (hauptsächlich Bewertung, ob Antworten Voreingenommenheit enthalten).
Das obige ist der detaillierte Inhalt vonRush-Test für chinesische Sprachmodelle: SenseTime, Shanghai AI Lab und andere haben „Scholar·Puyu' neu veröffentlicht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



