


Als ChatGPT zum ersten Mal veröffentlicht wurde, war die Leistung des Modells im Dialog so menschlich, dass die Illusion entstand, dass das Sprachmodell „Denkfähigkeit“ habe.
Nachdem Forscher jedoch ein tiefgreifendes Verständnis von Sprachmodellen erlangt hatten, stellten sie nach und nach fest, dass die Reproduktion auf der Grundlage von Sprachmustern mit hoher Wahrscheinlichkeit immer noch weit von der erwarteten „allgemeinen künstlichen Intelligenz“ entfernt ist.
In den meisten aktuellen Forschungen generieren groß angelegte Sprachmodelle hauptsächlich Denkketten unter der Leitung spezifischer Aufforderungen zur Ausführung von Denkaufgaben, ohne Berücksichtigung menschlicher kognitiver Rahmenbedingungen, wodurch sich die Fähigkeit von Sprachmodellen, komplexe Denkprobleme zu lösen, von denen von Menschen unterscheidet bleiben.
Wenn Menschen mit komplexen Denkproblemen konfrontiert sind, nutzen sie normalerweise verschiedene kognitive Fähigkeiten und müssen mit allen Aspekten von Werkzeugen, Wissen und externen Umgebungsinformationen interagieren. Können Sprachmodelle menschliche Denkprozesse simulieren, um komplexe Probleme zu lösen?
Die Antwort ist natürlich ja! Das erste OlaGPT-Modell, das den menschlichen kognitiven Verarbeitungsrahmen simuliert, ist da!

Papier-Link: https://arxiv.org/abs/2305.16334
Code-Link: //m.sbmmt.com/link/73a1c863a54653d5e184b790fee14754
OlaGPT umfasst mehrere kognitive Module, einschließlich Aufmerksamkeit, Gedächtnis, Argumentation, Lernen und entsprechende Planungs- und Entscheidungsmechanismen; inspiriert durch menschliches aktives Lernen, enthält das Framework auch eine Lerneinheit, um frühere Fehler und Expertenmeinungen aufzuzeichnen und dynamisch darauf zu verweisen, um die Fähigkeit zur Lösung ähnlicher Probleme zu verbessern.
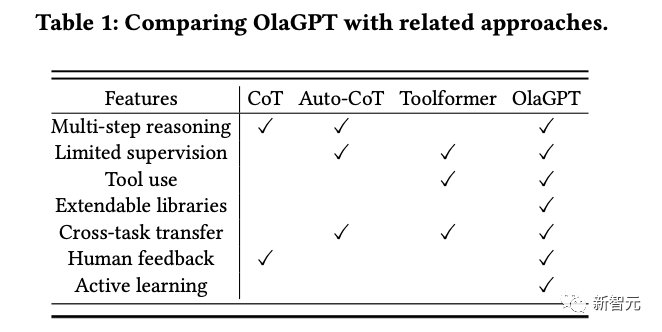
Der Artikel beschreibt außerdem gängige effektive Denkrahmen für Menschen zur Lösung von Problemen und entwirft die Chain of Thought (CoT)-Vorlage entsprechend. Außerdem wird ein umfassender Entscheidungsmechanismus vorgeschlagen, der die Genauigkeit des Modells maximieren kann.
Experimentelle Ergebnisse, die nach einer strengen Auswertung mehrerer Inferenzdatensätze erzielt wurden, zeigen, dass OlaGPT frühere Benchmarks auf dem neuesten Stand der Technik übertrifft und seine Wirksamkeit unter Beweis stellt.
Es besteht immer noch eine große Lücke zwischen dem aktuellen Sprachmodell und der erwarteten allgemeinen künstlichen Intelligenz. Die wichtigsten Erscheinungsformen sind:
1. In einigen Fällen ist der generierte Inhalt bedeutungslos oder weicht vom menschlichen Wert ab kann sogar einige sehr gefährliche Vorschläge liefern. Die aktuelle Lösung besteht darin, Verstärkungslernen mit menschlichem Feedback (RLHF) einzuführen, um die Modellausgabe zu bewerten.
2. Das Wissen des Sprachmodells beschränkt sich auf Konzepte und Fakten, die explizit in den Trainingsdaten erwähnt werden.
Wenn Sprachmodelle mit komplexen Problemen konfrontiert werden, können sie sich nicht an veränderte Umgebungen anpassen, vorhandenes Wissen oder Werkzeuge nutzen, über historische Lehren nachdenken, Probleme zerlegen und von Menschen in der langfristigen Entwicklung zusammengefasste Denkmuster (wie Analogie, induktives Denken, deduktives Denken usw.), um Probleme zu lösen.
Allerdings gibt es immer noch viele Systemprobleme, die es Sprachmodellen ermöglichen, den Prozess menschlicher Gehirnverarbeitungsprobleme zu simulieren:
1. Wie man die Hauptmodule im menschlichen kognitiven Rahmen systematisch nachahmt und kodiert und gleichzeitig darauf aufbaut menschliches allgemeines Denken in einem erreichbaren Modus für die Terminplanung?
2. Wie kann man Sprachmodelle dazu anleiten, aktiv wie Menschen zu lernen, das heißt, aus historischen Fehlern oder Expertenlösungen für schwierige Probleme zu lernen und sich weiterzuentwickeln?
Obwohl es möglich ist, das Modell neu zu trainieren, um korrigierte Antworten zu kodieren, ist dies offensichtlich sehr kostspielig und unflexibel.
3. Wie können Sprachmodelle flexibel verschiedene vom Menschen entwickelte Denkweisen nutzen, um ihre Denkleistung zu verbessern?
Ein festes und universelles Denkmodell lässt sich nur schwer an unterschiedliche Probleme anpassen. Genauso wie Menschen, die mit unterschiedlichen Arten von Problemen konfrontiert sind, normalerweise flexibel unterschiedliche Denkweisen wählen, wie zum Beispiel analoges Denken, deduktives Denken usw.
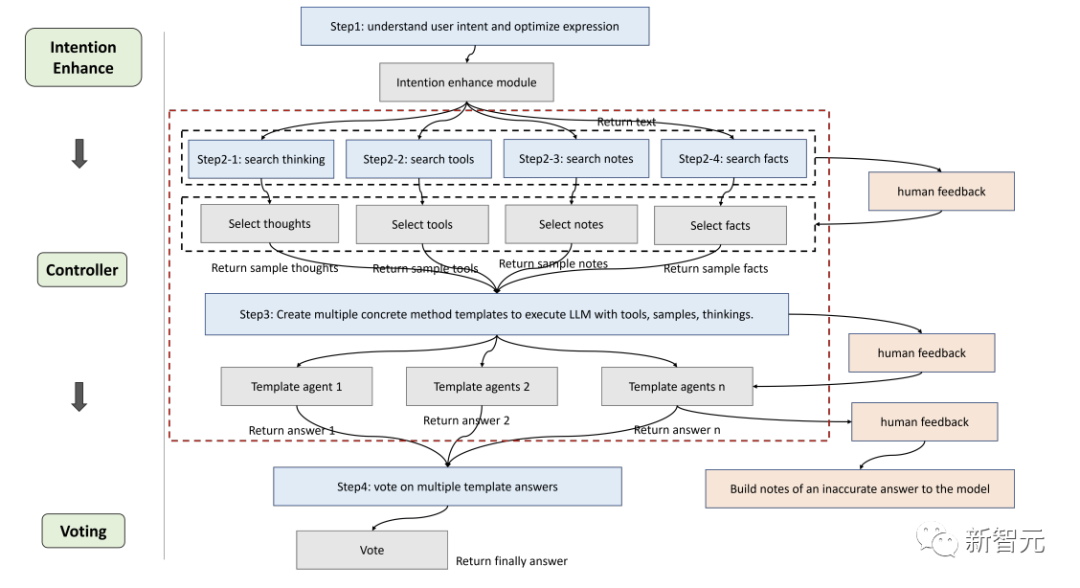
OlaGPT ist ein Problemlösungs-Framework, das menschliches Denken simuliert und die Fähigkeiten großer Sprachmodelle verbessern kann.
OlaGPT stützt sich auf die Theorie der kognitiven Architektur und modelliert die Kernfähigkeiten des kognitiven Rahmens wie Aufmerksamkeit, Gedächtnis, Lernen, Argumentation und Handlungsauswahl.
Die Forscher haben das Framework auf der Grundlage spezifischer Implementierungsanforderungen verfeinert und einen für Sprachmodelle geeigneten Prozess zur Lösung komplexer Probleme vorgeschlagen, der insbesondere sechs Module umfasst: Absichtsverbesserungsmodul (Aufmerksamkeit), Gedächtnismodul (Speicher), aktives Lernmodul ( Lernen), Argumentationsmodul (Argumentation), Controller-Modul (Aktionsauswahl) und Abstimmungsmodul.
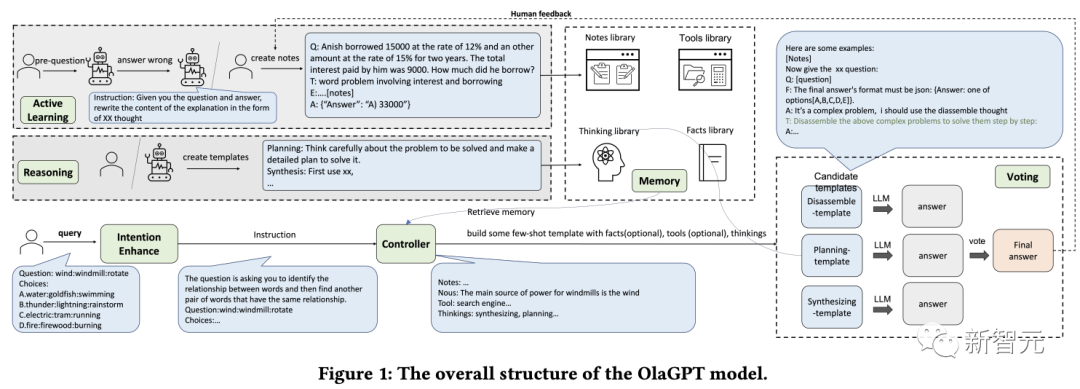
Aufmerksamkeit ist ein wichtiger Teil der menschlichen Wahrnehmung, da sie relevante Informationen identifiziert und irrelevante Daten herausfiltert.
In ähnlicher Weise haben die Forscher ein entsprechendes Aufmerksamkeitsmodul für das Sprachmodell entworfen, nämlich die Absichtsverbesserung, das darauf abzielt, die relevantesten Informationen zu extrahieren und eine stärkere Korrelation zwischen der Benutzereingabe und dem Sprachmuster des Modells herzustellen, das betrachtet werden kann als optimierter Konverter von Benutzerausdrucksgewohnheiten zu Modellausdrucksgewohnheiten.
Ermitteln Sie zunächst die Fragetypen von LLMs im Voraus durch spezifische Aufforderungswörter und rekonstruieren Sie dann die Art und Weise, Fragen zu stellen.

Fügen Sie beispielsweise am Anfang der Frage einen Satz hinzu: „Geben Sie nun XX (Fragetyp), Frage und Auswahlmöglichkeiten:“ an Um die Analyse zu erleichtern, müssen Sie außerdem Folgendes hinzufügen: „Die Antwort muss im JSON-Format enden: Antwort: eine der Optionen[A,B,C,D,E].“

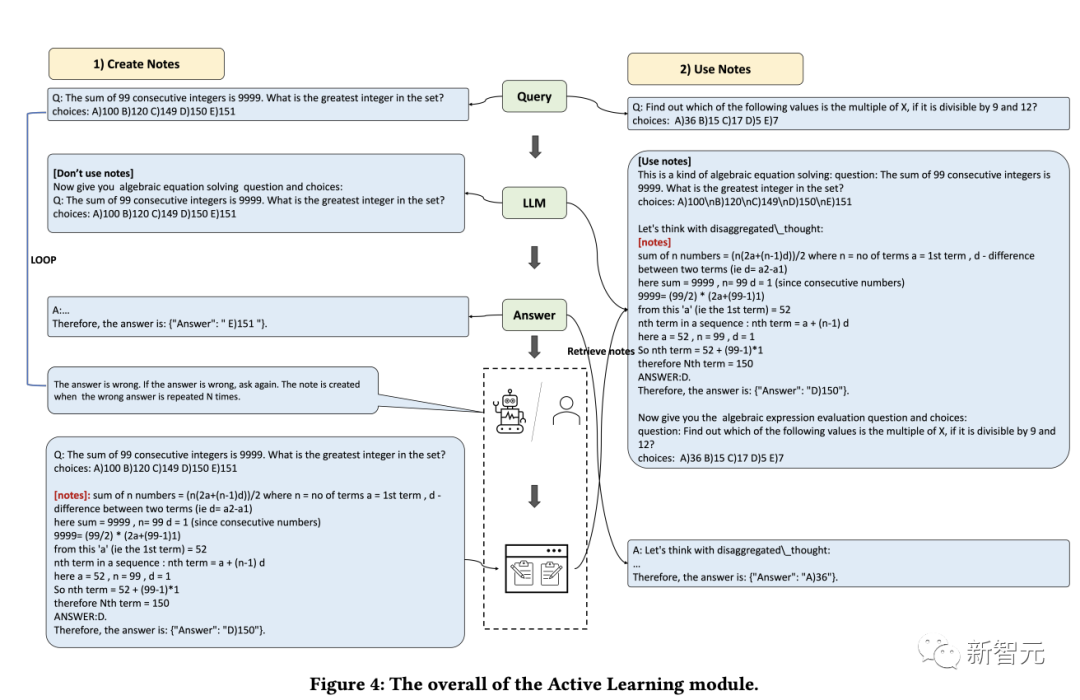
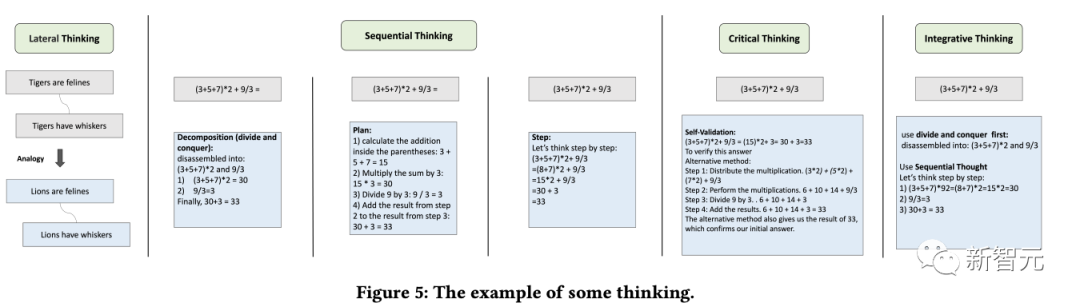
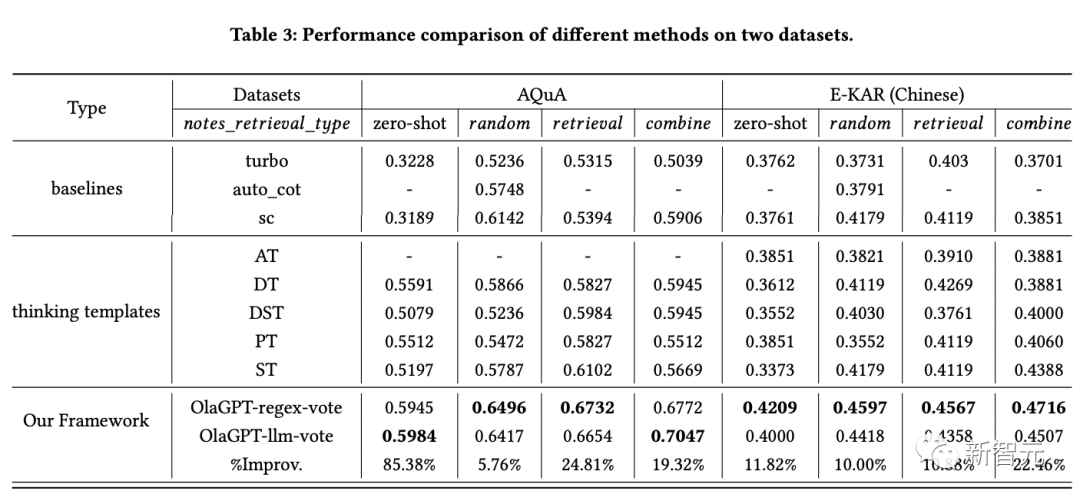
Aus den Ergebnissen geht hervor:
1. SC (Selbstkonsistenz) schneidet besser ab als GPT-3.5-Turbo, was darauf hinweist Die Anwendung eines Ensemble-Ansatzes trägt in gewissem Maße dazu bei, die Wirksamkeit großmaßstäblicher Modelle zu verbessern.
2. Die Leistung der im Artikel vorgeschlagenen Methode übertrifft die von SC, was in gewissem Maße die Wirksamkeit der Denkvorlagenstrategie beweist.
Die Antworten auf unterschiedliche Denkmuster weisen erhebliche Unterschiede auf, und eine Abstimmung nach unterschiedlichen Denkmustern führt letztendlich zu besseren Ergebnissen, als einfach mehrere Abstimmungsrunden durchzuführen.
3. Unterschiedliche Denkvorlagen haben unterschiedliche Auswirkungen und Schritt-für-Schritt-Lösungen sind möglicherweise besser für Argumentationsprobleme geeignet.
4. Die Leistung des aktiven Lernmoduls ist deutlich besser als die Nullstichprobenmethode.
Das Einbeziehen anspruchsvoller Fälle in die Notizenbibliothek sowie die Verwendung von Zufalls-, Abruf- und Kombinationslisten zur Verbesserung der Leistung ist eine praktikable Strategie.
5. Unterschiedliche Abrufschemata haben unterschiedliche Auswirkungen auf unterschiedliche Datensätze. Im Allgemeinen führt die Kombinationsstrategie zu besseren Ergebnissen.
6. Die Methode in diesem Artikel ist offensichtlich besser als andere Lösungen. Dies liegt an der angemessenen Gestaltung des Gesamtrahmens, einschließlich der effektiven Gestaltung des aktiven Lernmoduls Unter verschiedenen Denkvorlagen sind die Ergebnisse unterschiedlich. Das Controller-Modul spielt eine sehr gute Kontrollrolle und wählt Inhalte aus, die mit den vom Abstimmungsmodul entworfenen Integrationsmethoden übereinstimmen.
Referenz:
//m.sbmmt.com/link/73a1c863a54653d5e184b790fee14754
Das obige ist der detaillierte Inhalt vonOlaGPT, das erste Denkframework, das die menschliche Kognition simuliert: Sechs Module verbessern das Sprachmodell und steigern die Denkfähigkeit um bis zu 85 %. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Welche Software ist Penguin?
Welche Software ist Penguin?
 Wie man im Währungskreis aus Tausenden Hunderttausende macht
Wie man im Währungskreis aus Tausenden Hunderttausende macht
 Einführung in Festplattenleistungsindikatoren
Einführung in Festplattenleistungsindikatoren
 Ursachen und Lösungen von Laufzeitfehlern
Ursachen und Lösungen von Laufzeitfehlern
 Standby-Tastenkombination
Standby-Tastenkombination
 Der aktuelle Preis der Fil-Währung
Der aktuelle Preis der Fil-Währung
 So zeigen Sie den Tomcat-Quellcode an
So zeigen Sie den Tomcat-Quellcode an
 WeChat stellt den Chatverlauf wieder her
WeChat stellt den Chatverlauf wieder her








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



