


Eine „ultimative Bettlerversion“ des „Turing-Tests“, die alle wichtigen Sprachmodelle übertrifft.
Menschen können den Test mühelos bestehen.
Die Forscher verwendeten eine sehr einfache Methode.
Mischen Sie das eigentliche Problem in einige chaotische Wörter in Großbuchstaben und übermitteln Sie es dem großen Sprachmodell.
Für große Sprachmodelle gibt es keine Möglichkeit, die tatsächlich gestellten Fragen effektiv zu identifizieren.
Menschen können die „Großbuchstaben“-Wörter leicht aus den Fragen entfernen, die echten Fragen identifizieren, die in den chaotischen Großbuchstaben verborgen sind, Antworten geben und den Test bestehen.
Die Frage im Bild selbst ist ganz einfach: Ist Wasser nass oder trocken?

Menschen antworten einfach nass und das war’s.
Aber ChatGPT hat keine Möglichkeit, die Beeinträchtigung dieser Großbuchstaben bei der Beantwortung der Frage zu beseitigen.
So wurden den Fragen viele bedeutungslose Wörter beigemischt, wodurch die Antworten sehr lang und bedeutungslos wurden.
Zusätzlich zu ChatGPT führten die Forscher auch ähnliche Tests mit GPT-3 und Metas LLaMA sowie mehreren Open-Source-Feinabstimmungsmodellen durch, und alle haben den „Großbuchstabentest“ nicht bestanden.

Das Prinzip des Tests ist eigentlich einfach: KI-Algorithmen verarbeiten Textdaten typischerweise ohne Berücksichtigung der Groß- und Kleinschreibung.
Wenn also versehentlich ein Großbuchstabe in einen Satz eingefügt wird, kann das zu Verwirrung führen.
KI weiß nicht, ob sie es als Eigennamen oder Fehler behandeln oder einfach ignorieren soll.

Damit können wir unter den Menschen, mit denen wir sprechen, leicht zwischen echten Menschen und Chatbots unterscheiden.
Wie kann man KI wissenschaftlicher aufdecken?
Um schwerwiegende illegale Aktivitäten wie Betrug mithilfe von Chatbots zu bekämpfen, die in Zukunft möglicherweise in großer Zahl auftauchen.
Zusätzlich zum oben erwähnten Großbuchstabentest versuchen Forscher, einen Weg zu finden, um in einer Online-Umgebung effizienter zwischen Menschen und Chatbots zu unterscheiden.

Papier: //m.sbmmt.com/link/f30a31bcad7560324b3249ba66ccf7aa
Forscher konzentrieren sich auf die Gestaltung der Schwächen großer Sprachmodelle.
Um zu verhindern, dass das große Sprachmodell den Test besteht, ergreifen Sie die „sieben Zoll“ der KI und sprengen Sie sie.
Wir haben die folgenden Testmethoden entwickelt.
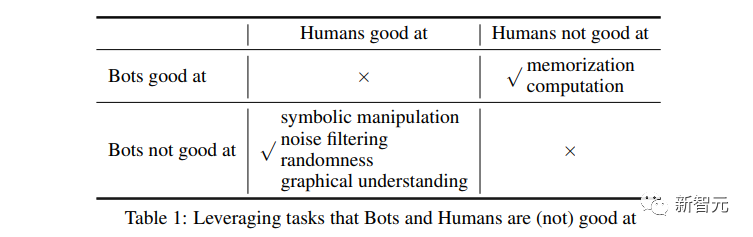
Solange das große Model nicht gut darin ist, Fragen zu beantworten, werden wir sie wie verrückt ins Visier nehmen.
Zählen
Das Erste ist das Zählen, zu wissen, dass das Zählen mit großen Modellen nicht ausreicht.

Tatsächlich kann ich alle drei Buchstaben falsch zählen.
Textersetzung
Dann gibt es noch einige Textersetzungen Buchstaben ersetzen einander und lassen das große Modell ein neues Wort buchstabieren.
KI hatte lange Zeit Probleme, aber das Ausgabeergebnis war immer noch falsch.

Positionsersatz
Das ist auch nicht die Stärke von ChatGPT.
Sogar der Brieffilter-Chatbot, der von Grundschülern genau ausgefüllt werden kann, kann nicht ausgefüllt werden.

Frage: Bitte nach dem zweiten „S“ ausgeben Der 4. Buchstabe von , die richtige Antwort ist „c“ Es erfordert für Menschen fast keine Anstrengung, es zu vervollständigen, aber die KI kann immer noch nicht bestehen.
Geräuschimplantation
#🎜 🎜 # Dies ist der „Großbuchstabentest“, den wir eingangs erwähnt haben.
Dies ist der „Großbuchstabentest“, den wir eingangs erwähnt haben.
Durch das Hinzufügen verschiedener Geräusche (z. B. irrelevanter Wörter in Großbuchstaben) zur Frage kann der Chatbot die Frage nicht genau identifizieren und besteht daher den Test nicht.
# 🎜 🎜#
Und für Menschen ist es wirklich schwierig, in diesen chaotischen Großbuchstaben das eigentliche Problem zu erkennen.

Symboltext

Ein weiteres Projekt für Menschen Es gibt fast keine herausfordernden Missionen.
Aber für Chatbots wollen sie diese Symboltexte verstehen können Ohne viel Fachtraining dürfte es schwierig sein.
Nach einer Reihe „unmöglicher Aufgaben“, die von Forschern speziell für große Sprachmodelle entwickelt wurden.
Speicher und Berechnung
Durch frühes Training, große Sprache Das Modell schneidet in beiden Aspekten relativ gut ab.
Menschen sind grundsätzlich nicht in der Lage, effektiv auf große Speichermengen und 4-stellige Berechnungen zu reagieren, da sie nicht in der Lage sind, verschiedene Hilfsgeräte zu verwenden.
Menschliches vs. großes Sprachmodell
Die Forscher führten diesen „menschlichen Unterschiedstest“ an GPT3, ChatGPT und drei anderen großen Open-Source-Modellen durch: LLaMA, Alpaca und Vicuna
Dies ist aus den Ergebnissen ersichtlich Es ist deutlich zu erkennen, dass sich das große Modell nicht erfolgreich in die Menschheit integriert hat. ?
Und andere große Sprachmodelle schneiden in diesen speziell für sie entwickelten Tests sehr schlecht ab.
 Völlig unmöglich, die Prüfung zu bestehen.
Völlig unmöglich, die Prüfung zu bestehen.
Aber für Menschen ist es ganz einfach, fast zu 100 % bestanden.
Was die Probleme betrifft, in denen Menschen nicht gut sind, so sind die Menschen fast vollständig ausgelöscht und völlig besiegt.
KI ist eindeutig fähig.
Es scheint, dass die Forscher dem Testdesign tatsächlich große Aufmerksamkeit geschenkt haben.
„Lass keine KI gehen, aber tue keinem Menschen Unrecht“
Das ist eine tolle Auszeichnung!
Referenz:
//m.sbmmt.com/link/5e632913bf096e49880cf8b92d53c9ad
Das obige ist der detaillierte Inhalt vonEine Frage unterscheidet Mensch und KI! „Bettlerversion' Turing-Test, schwierig für alle großen Modelle. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 OuYi Exchange USDT-Preis
OuYi Exchange USDT-Preis
 Was ist der Unterschied zwischen dem TCP-Protokoll und dem UDP-Protokoll?
Was ist der Unterschied zwischen dem TCP-Protokoll und dem UDP-Protokoll?
 Localstorage-Nutzung
Localstorage-Nutzung
 So fügen Sie Audio in ppt ein
So fügen Sie Audio in ppt ein
 Welche Software ist Twitter?
Welche Software ist Twitter?
 So konfigurieren Sie die Pfadumgebungsvariable in Java
So konfigurieren Sie die Pfadumgebungsvariable in Java
 Der Unterschied zwischen vivox100s und x100
Der Unterschied zwischen vivox100s und x100
 Java-Multithread-Programmierung
Java-Multithread-Programmierung








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



