


Erstellen Sie einen Index für das Filterfeld nach „wo“ (die „wo“ nach „Auswählen/Aktualisieren/Löschen“ sind alle anwendbar), verwenden Sie den Index, um die Geschwindigkeit zu erhöhen Filtereffizienz, es ist nicht erforderlich, einen vollständigen Tabellenscan durchzuführen 🎜##🎜🎜 #
In Für das Geschäft mit häufigen Abfragen können Sie einen Index für die nach „Wo“ gefilterten Felder erstellen. Wenn es viele nach „Wo“ gefilterte Felder gibt, können Sie auch einen gemeinsamen Index erstellen.
-- 描述:当where中有多个条件需要进行匹配的时候,那么可以创建联合索引,这样所有的条件都可以使用索引,大大提高了检索的效率 select * from student_info where student_id = 1; -- 当然数据量比较大的时候给where后面的字段添加索引 create index student_id_index on student_info (student_id)
Bevor der Index erstellt wird, dauert es 0,501 Sekunden, um alle Daten im Speicher zu sortieren
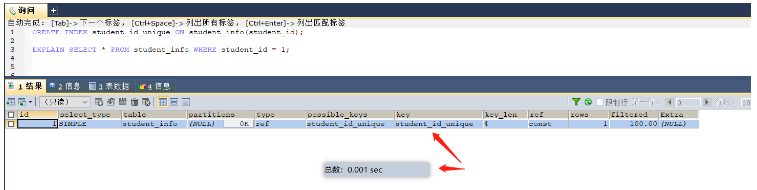
select * from student_info where id = 1001; -- 因为学号是唯一的,所以可以在学号这个字段上添加唯一所用 create index id_unique on student_info(id);
select * from student_info order by name; -- 这里就可以给name字段进行索引的添加 select * from student_info group by class_id; -- 这里就可以给class_id字段添加索引

 Szenario 6: Verwenden Sie das Präfix der Zeichenfolge, um einen Index zu erstellen
Szenario 6: Verwenden Sie das Präfix der Zeichenfolge, um einen Index zu erstellen
select distinct(student_id) from student_info; -- 这里就可以根据student_id字段建立索引 create index student_id_index on student_info;
Gründe für das Präfix, um einen Index zu erstellen: # 🎜🎜##🎜🎜 #
Da einige Zeichenfolgen sehr lang sind, nimmt der Index viel Platz ein, wenn die gesamte Zeichenfolge indiziert wird Die gesamte Zeichenfolge muss gespeichert werden, die Datenelemente werden sehr groß, die Tiefe des Indexbaums wird vertieft und die Abrufgeschwindigkeit nimmt ab
Obwohl es sein kann auftreten Die beiden Zeichenfolgen im Index sind gleich, aber die auf dem Primärschlüssel basierende Tabellenrückgabeoperation ist noch effizienter
如何确定前缀索引中前缀的长度呢?(也就是如果前缀的长度太短,那么索引的区分度就很低,从多个字符串截取的前缀数据可能都是一样的,但是如果前缀索引的前缀过长,那么前缀索引的优点就消失了)
引入了区别度的概念,select count(distinct left(索引字段,前缀索引长度) / count(*) from xxx),该值越接近1,那么区分度就越明显,那么该索引长度就是所求的前缀索引长度
场景七:在频繁使用的列上建立索引或联合索引(频繁使用的字段应该在索引的左侧)
select * from xiaoyuanhao where age = 18; select * from xiaoyuanhao where age = 19 and sex = 'man'; select * from xiaoyuanhao where age = 10 and sex = 'man' and password = '123456'; -- 在这里实际上就可以建立age,sex,password的联合索引,只需要建立一个索引,这三个查询都是可以使用的 create index age_sex_password_index on xiaoyuanhao(age,sex,password); select * from student_info group by class_id order by name; -- 在这里可以建立class_id和name的联合索引,但是一定要注意索引的顺序,一定是要class_id在前,name在后,因为在select语句中执行的顺序是先group by 之后才是 order by 索引如果索引的字段顺序是相反的,那么就无法使用索引 create index class_id_name_index on student(class_id,name);
索引建立需要符合顺序的原因:
索引字段的顺序如果是错误的,那么索引就会失效,因为索引实际上是排好序的,如果索引建立的时候是现根据name排好序之后在根据class_id进行排序,那么在面对需要先根据class_id排序再根据name排序的业务就无法进行使用
补充:
在select * from xxx where age = 19 and sex = ‘man’ and password = '123456’这里索引建立的顺序不一定是(age,sex,password)因为在实际执行的过程中,优化器会优化执行步骤会按照索引的顺序进行查询,但是group by 和 order by的执行顺序是无法改变的,索引必须严格的按照顺序建立索引,否则索引失效
Das obige ist der detaillierte Inhalt vonIn welchen Situationen eignet sich die MySQL-Indexoptimierung zum Erstellen von Indizes?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



