


Im Jahr 2022 schlug der ehemalige chinesische Google Brain-Wissenschaftler Jason Wei in einer bahnbrechenden Arbeit der Denkkette erstmals vor, dass CoT die Denkfähigkeit von LLM verbessern kann.
Aber trotz der Denkkette macht LLM bei sehr einfachen Fragen manchmal Fehler.
Kürzlich haben Forscher der Princeton University und Google DeepMind ein neues Argumentationsrahmen für Sprachmodelle vorgeschlagen – „Tree of Thinking“ (ToT).
ToT verallgemeinert die derzeit beliebte Methode der „Denkkette“, um Sprachmodelle zu leiten und die Zwischenschritte des Problems durch die Erforschung kohärenter Texteinheiten (Denken) zu lösen.

Papieradresse: https://arxiv.org /abs/2305.10601
Projektadresse: https://github.com/kyegomez/tree-of-thoughts
Einfach ausgedrückt ermöglicht „Thinking Tree“ LLM:
· mehrere eigene Gegenstände zu geben Verschiedene Argumentationspfade
· Nach separaten Bewertungen die nächste Vorgehensweise festlegen
· In Trace vorwärts oder rückwärts, wenn nötig, um eine globale Entscheidungsfindung zu erreichen, kreatives Schreiben, Mini-Kreuzworträtsel).
Zum Beispiel löste GPT-4 im 24-Punkte-Spiel nur 4 % der Aufgaben, aber die Erfolgsquote der ToT-Methode erreichte 74 %.
Lassen Sie LLM „immer wieder nachdenken“
Die großen Sprachmodelle GPT und PaLM, die zur Textgenerierung verwendet wurden, haben sich mittlerweile als fähig erwiesen ein breites Aufgabenspektrum ausführen.Die Grundlage für den Fortschritt all dieser Modelle ist immer noch der „autoregressive Mechanismus“, der ursprünglich verwendet wurde, um Text und Token nacheinander von links nach rechts zu generieren Ebenenentscheidungen.
 Kann also ein so einfacher Mechanismus ausreichen, um einen Weg zu finden? „Sprachmodell zur Lösung allgemeiner Probleme“? Wenn nicht, welche Probleme stellen das aktuelle Paradigma in Frage und was sollten die wirklichen alternativen Mechanismen sein?
Kann also ein so einfacher Mechanismus ausreichen, um einen Weg zu finden? „Sprachmodell zur Lösung allgemeiner Probleme“? Wenn nicht, welche Probleme stellen das aktuelle Paradigma in Frage und was sollten die wirklichen alternativen Mechanismen sein?
Gerade die Literatur zum Thema „menschliche Kognition“ liefert einige Hinweise zu diesem Thema.
Forschungen zum „Dual Process“-Modell zeigen, dass Menschen über zwei Arten der Entscheidungsfindung verfügen: den schnellen, automatischen, unbewussten Modus – „System 1“ und den langsamen, bewussten Modus , bewusster Modus Modus - „System 2“. #? 1“, daher kann diese Fähigkeit durch den Planungsprozess „System 2“ erweitert werden.
„System 1“ ermöglicht es LLM, mehrere Alternativen zur aktuellen Auswahl beizubehalten und zu erkunden, anstatt nur eine auszuwählen, während „System 2“ seinen aktuellen Status bewertet, und Aktiv antizipieren und zurückblicken, um umfassendere Entscheidungen zu treffen.
Um einen solchen Planungsprozess zu entwerfen, gingen Forscher zu den Ursprüngen der künstlichen Intelligenz und der Kognitionswissenschaft zurück, beginnend mit den Wissenschaftlern Newell, Shaw und Simon in den 1950er Jahren. Entdecken Sie den Planungsprozess und lassen Sie sich von ihm inspirieren. 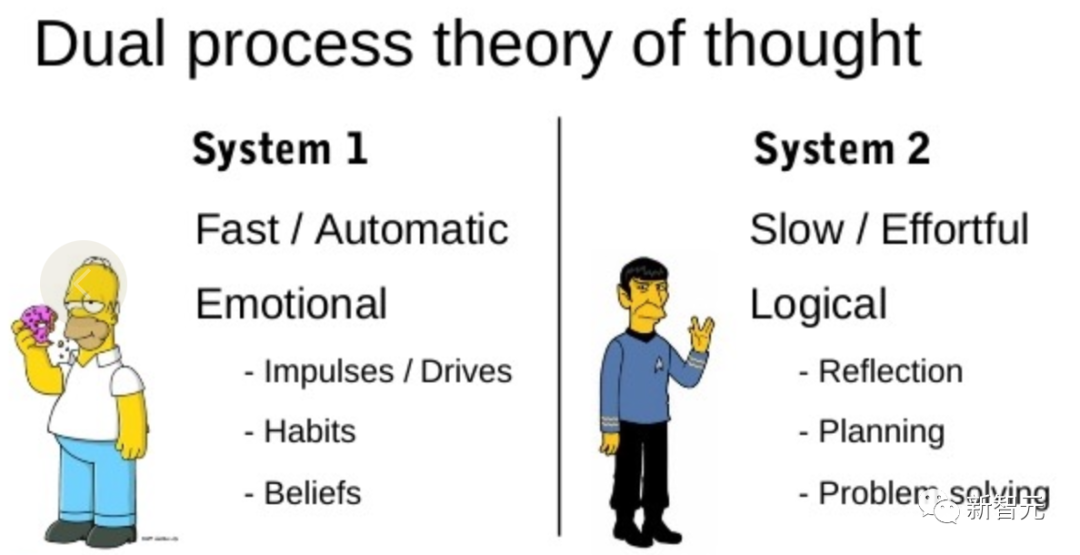
Newell und Kollegen beschreiben Problemlösung als „Suchen durch Kombinieren des Problemraums“, dargestellt als Baum.
Im Prozess der Problemlösung müssen Sie immer wieder vorhandene Informationen nutzen, um weitere Informationen zu erhalten, bis Sie schließlich eine Lösung finden.

Diese Perspektive beleuchtet zwei der bestehenden Methoden zur Verwendung von LLM zur Lösung gemeinsamer Probleme Probleme Zwei große Mängel:
1 Aus lokaler Sicht untersucht LLM nicht verschiedene Fortsetzungen im Denkprozess – die Zweige des Baumes.
2. Insgesamt beinhaltet LLM keinerlei Planung, Vorwärts- oder Rückblick, um diese verschiedenen Optionen zu bewerten.
Um diese Probleme zu lösen, schlugen Forscher ein Thinking Tree Framework (ToT) vor, das Sprachmodelle zur Lösung allgemeiner Probleme verwendet und es LLM ermöglicht, mehrere Denk- und Argumentationspfade zu erkunden. Nr lösen.
Und ToT pflegt aktiv einen „Denkbaum“. Jedes rechteckige Kästchen stellt einen Gedanken dar, und jeder Gedanke ist eine zusammenhängende Wortfolge, die als Zwischenschritt bei der Lösung eines Problems dient.
ToT definiert jedes Problem als eine Suche in einem Baum, in dem jeder Knoten vorhanden ist ist ein Zustand, der die Teillösung der bisherigen Eingabe- und Gedankenfolge darstellt.
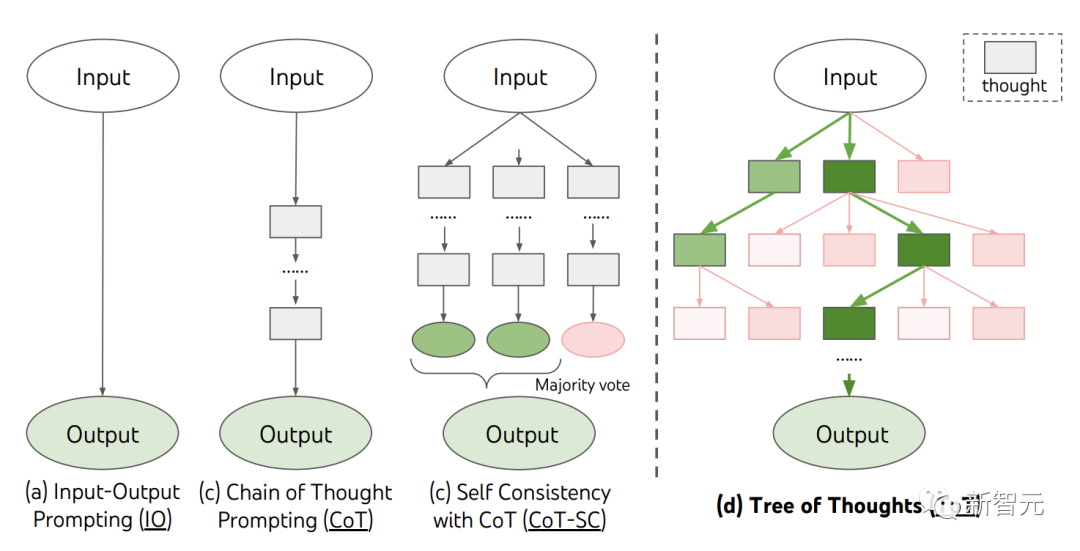
Wie man den Zwischenprozess zerlegt in Denkschritte; wie man aus jedem Zustand potenzielle Ideen generiert; wie man Zustände heuristisch auswertet;
1. Denkzusammenbruch
#🎜 🎜#CoT erprobt kohärent das Denken ohne explizite Zerlegung, während ToT die Eigenschaften des Problems nutzt, um Zwischenschritte des Denkens zu entwerfen und zu zerlegen. Je nach Frage kann eine Idee aus ein paar Wörtern (Kreuzworträtsel), einer Gleichung (24 Punkte) oder einem ganzen Schreibplan (kreatives Schreiben) bestehen.
Generell sollte eine Idee „klein“ genug sein, damit LLM aussagekräftige, vielfältige Beispiele produzieren kann. Beispielsweise ist die Generierung eines kompletten Buches oft zu „umfangreich“, um zusammenhängend zu sein.
Aber eine Idee sollte auch „groß“ genug sein, damit LLM ihre Aussichten für die Lösung des Problems bewerten kann. Beispielsweise ist die Generierung eines Tokens oft zu „klein“, um ausgewertet zu werden.
2. Denkgenerator
# 🎜 🎜#Angesichts des Baumzustands werden 2 Strategien verwendet, um k Kandidaten für den nächsten Denkschritt zu generieren. 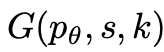
(a) Probenahme aus einer CoT-Eingabeaufforderung 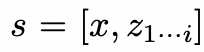 Denken:
Denken:
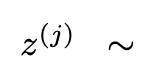
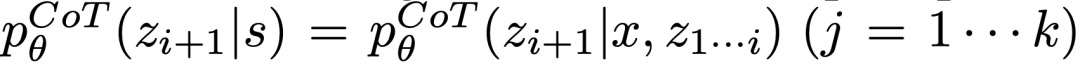
funktioniert besser, wenn der Denkraum reichhaltig ist (so wie jede Idee ein Absatz ist) und 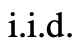 zu Vielfalt führt.
zu Vielfalt führt.
(b) Verwenden Sie „Vorschlagsaufforderung“, um Ideen in der folgenden Reihenfolge vorzuschlagen: 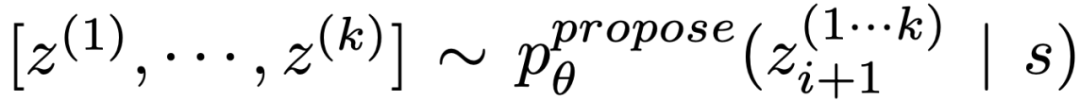
. Dies funktioniert besser, wenn der Denkraum begrenzt ist (z. B. jeder Gedanke nur aus einem Wort oder einer Zeile besteht), sodass durch die Präsentation verschiedener Ideen im gleichen Kontext Doppelarbeit vermieden wird. 3. State Evaluator Welche Zustände müssen untersucht werden und in welcher Reihenfolge.
Während Heuristiken die Standardmethode zur Lösung von Suchproblemen sind, werden sie normalerweise programmiert (DeepBlue) oder erlernt (AlphaGo). Hier schlagen Forscher eine dritte Möglichkeit vor, durch LLM bewusst über Zustände nachzudenken.
Gegebenenfalls kann diese durchdachte Heuristik flexibler als Verfahrensregeln und effizienter als erlernte Modelle sein. Mit dem Thought Generator betrachteten die Forscher auch zwei Strategien, um Staaten unabhängig oder gemeinsam zu bewerten: jedem Staat unabhängig Werte zuzuweisen und staatsübergreifend abzustimmen;
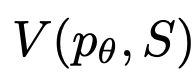 4. Suchalgorithmus
4. Suchalgorithmus
Schließlich können Benutzer im ToT-Framework verschiedene Suchalgorithmen basierend auf der Struktur des Baums anschließen und abspielen.
Die Forscher haben hier zwei relativ einfache Suchalgorithmen untersucht:
Algorithmus 1 – Breadth First Search (BFS), der bei jedem Schritt eine Reihe der vielversprechendsten Zustände von b verwaltet. Algorithmus 2 – Depth First Search (DFS) untersucht zunächst die vielversprechendsten Zustände, bis die endgültige Ausgabe erreicht ist oder der Zustandsbewerter es für unmöglich hält, das Problem ausgehend vom aktuellen Schwellenwert zu lösen. In beiden Fällen kehrt DFS zum übergeordneten Zustand von s zurück, um die Erkundung fortzusetzen.
Darüber hinaus ist die Methode von LLM zur Implementierung einer heuristischen Suche durch Selbstbewertung und bewusste Entscheidungsfindung neu.
ExperimenteZu diesem Zweck schlug das Team drei Aufgaben zum Testen vor – selbst das fortschrittlichste Sprachmodell GPT-4 ist unter Standard-IO-Eingabeaufforderungen oder Chain of Thought (CoT)-Eingabeaufforderungen sehr anspruchsvoll.

24 ist ein mathematisches Denkspiel, bei dem das Ziel darin besteht, mithilfe von 4 Zahlen und Grundrechenarten (+-*/) 24 zu erhalten.
Beispielsweise bei der Eingabe „4 9 10 13“ könnte die Ausgabe der Antwort „(10-4)*(13-9)=24“ sein.
ToT-Setup
Das Team hat den Denkprozess des Modells in drei Schritte unterteilt, wobei jeder Schritt eine Zwischengleichung ist.
Wie in Abbildung 2(a) gezeigt, extrahieren Sie an jedem Knoten die Zahl auf der „linken“ Seite und fordern Sie LLM auf, einen möglichen nächsten Schritt zu generieren. (Die bei jedem Schritt gegebenen „Vorschlagsaufforderungen“ sind die gleichen)
Dabei führt das Team eine Breitensuche (BFS) in ToT durch und behält bei jedem Schritt die besten b=5 Kandidaten.
Wie in Abbildung 2(b) dargestellt, wird LLM aufgefordert, jeden denkenden Kandidaten bis zu 24 als „definitiv/möglicherweise/unmöglich“ zu bewerten. Eliminieren Sie unmögliche Teillösungen basierend auf dem gesunden Menschenverstand „zu groß/zu klein“ und behalten Sie die verbleibenden „möglichen“ Elemente bei.
Ergebnisse
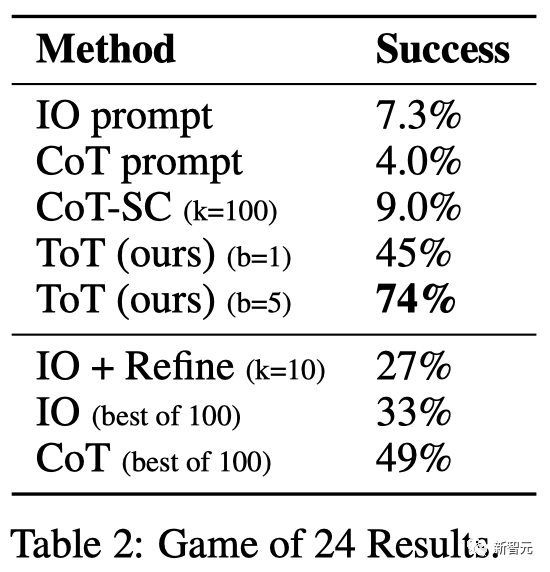
Wie in Tabelle 2 gezeigt, schnitten die Aufforderungsmethoden IO, CoT und CoT-SC bei der Aufgabe schlecht ab, mit Erfolgsraten von nur 7,3 %, 4,0 % und 9,0 %. Im Vergleich dazu hat ToT eine Erfolgsquote von 45 % erreicht, wenn die Breite b=1 ist, und 74 %, wenn b=5.
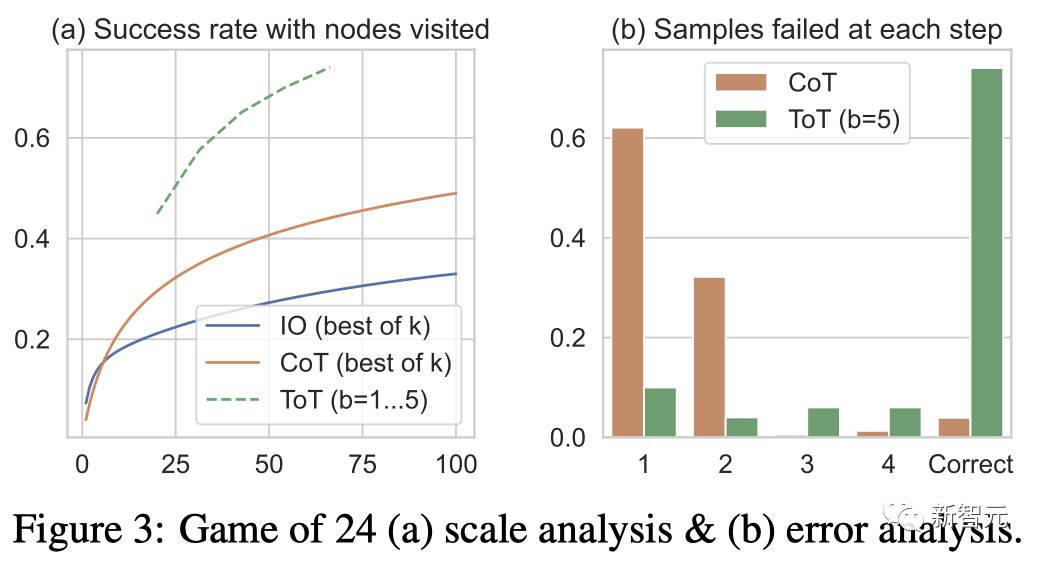
Das Team berücksichtigte auch die Vorhersageeinstellung von IO/CoT, indem es die besten k Stichproben (1≤k≤100) zur Berechnung der Erfolgsquote verwendete und die 5 Erfolgsquoten in Abbildung 3(a) grafisch darstellte.
Wie erwartet skaliert CoT besser als IO, wobei die besten 100 CoT-Proben eine Erfolgsquote von 49 % erreichen, aber immer noch schlechter als die Erkundung von mehr Knoten (b>1) in ToT.
Fehleranalyse
Abbildung 3(b) analysiert die CoT- und ToT-Stichproben, bei welchem Schritt sie die Aufgabe nicht bestanden haben, d. h. Denken (in CoT) oder nur B-Denken (in ToT) sind ungültig oder können 24 nicht erreichen.
Es ist erwähnenswert, dass etwa 60 % der CoT-Proben im ersten Schritt, also bei den ersten drei Wörtern (z. B. „4+9“), fehlgeschlagen sind.
Als nächstes entwarf das Team eine kreative Schreibaufgabe.
Unter diesen besteht die Eingabe aus vier zufälligen Sätzen und die Ausgabe sollte ein zusammenhängender Absatz sein, wobei jeder Absatz mit jeweils vier Eingabesätzen endet. Solche Aufgaben sind ergebnisoffen und explorativ und fordern kreatives Denken und fortgeschrittene Planung heraus.
Es ist erwähnenswert, dass das Team auch eine iterative Optimierungsmethode (k≤5) für zufällige IO-Stichproben jeder Aufgabe verwendet, bei der LLM anhand von Eingabebeschränkungen und dem letzten bestimmt, ob der Absatz „völlig kohärent“ ist generierten Absatz, falls nicht, generieren Sie einen optimierten.
ToT-Setup
Das Team hat ein ToT mit einer Tiefe von 2 erstellt (nur 1 Zwischen-Denkschritt).
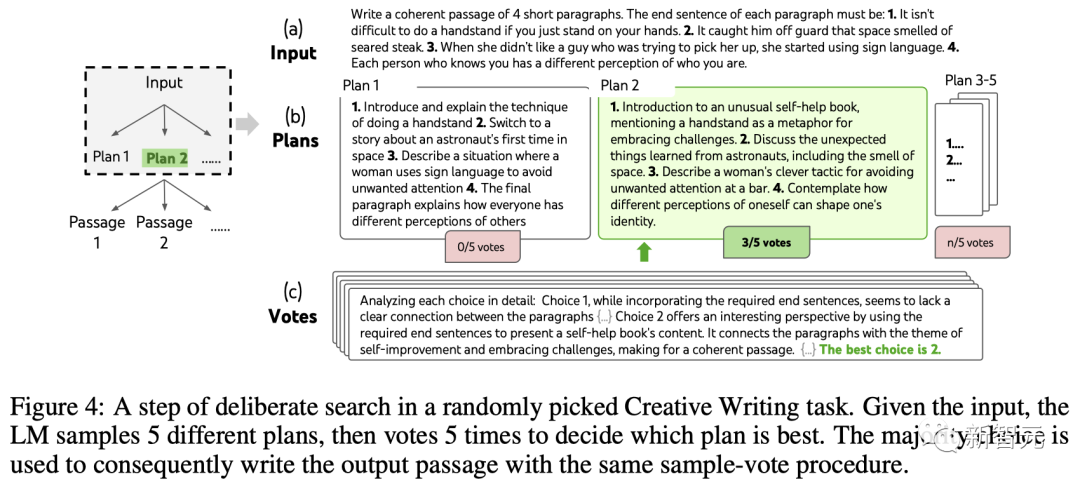
LLM generiert zunächst k=5 Pläne und stimmt ab, um den besten Plan auszuwählen (Abbildung 4), generiert dann k=5 Absätze basierend auf dem besten Plan und stimmt dann ab, um den besten Plan auszuwählen.
Eine einfache Zero-Shot-Abstimmungsaufforderung („Analysieren Sie die folgenden Entscheidungen und entscheiden Sie, welche die Richtlinie am wahrscheinlichsten umsetzen wird“) wurde verwendet, um in zwei Schritten 5 Stimmen zu ziehen.
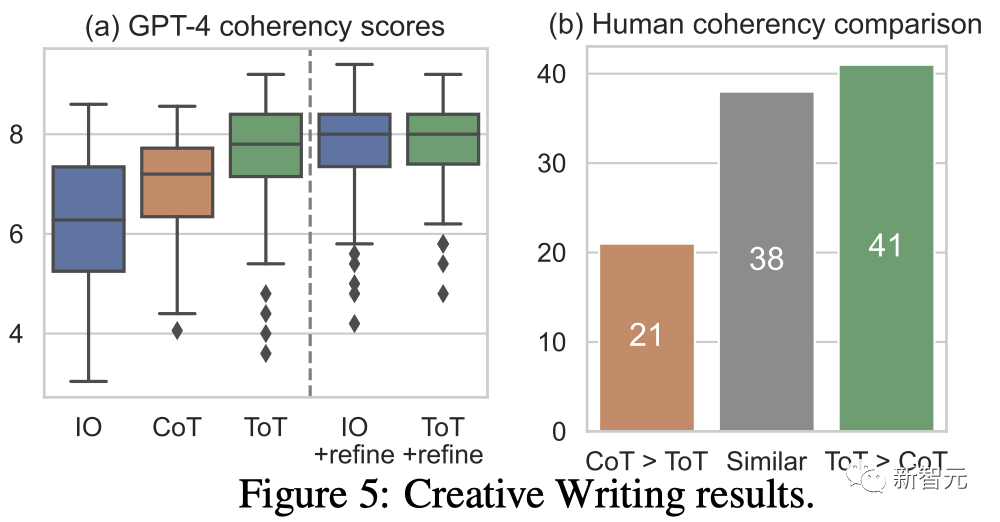
Ergebnis
# 🎜🎜# Abbildung 5(a) zeigt den durchschnittlichen GPT-4-Score über 100 Aufgaben hinweg, wobei davon ausgegangen wird, dass ToT (7,56) im Durchschnitt kohärentere Absätze generiert als IO (6,19) und CoT (6,93).
Während solche automatisierten Auswertungen verrauscht sein können, zeigt Abbildung 5(b) dies, indem sie zeigt, dass Menschen ToT in 41 von 100 Absatzpaaren bevorzugen, während nur 21 Personen CoT bevorzugen (Die anderen 38 Paare wurden als „gleich kohärent“ angesehen), um diesen Befund zu bestätigen.
Schließlich ist die iterative Optimierung bei dieser Aufgabe in natürlicher Sprache effektiver – sie verbessert den IO-Kohärenzwert von 6,19 auf 7,67 und den ToT-Kohärenzwert von 7,56 auf 7,91.
Das Team ist davon überzeugt, dass es als dritte Methode zur Denkgenerierung im Rahmen des ToT-Frameworks angesehen werden kann, indem altes Denken anstelle von i.i.d. optimiert wird Generation.
ToT ist in 24-Punkte-Spielen und kreativem Schreiben relativ oberflächlich – –Es Es dauert bis zu 3 Denkschritte, um die Ausgabe abzuschließen.
Schließlich beschloss das Team, eine schwierigere Frage durch ein 5×5 Mini-Kreuzworträtsel zu stellen.
Auch hier besteht das Ziel nicht nur darin, die Aufgabe zu lösen, sondern die Grenzen von LLM als allgemeinem Problemlöser zu untersuchen. Leiten Sie Ihre Erkundung, indem Sie einen Blick in Ihren eigenen Geist werfen und zielgerichtetes Denken als Inspiration nutzen.
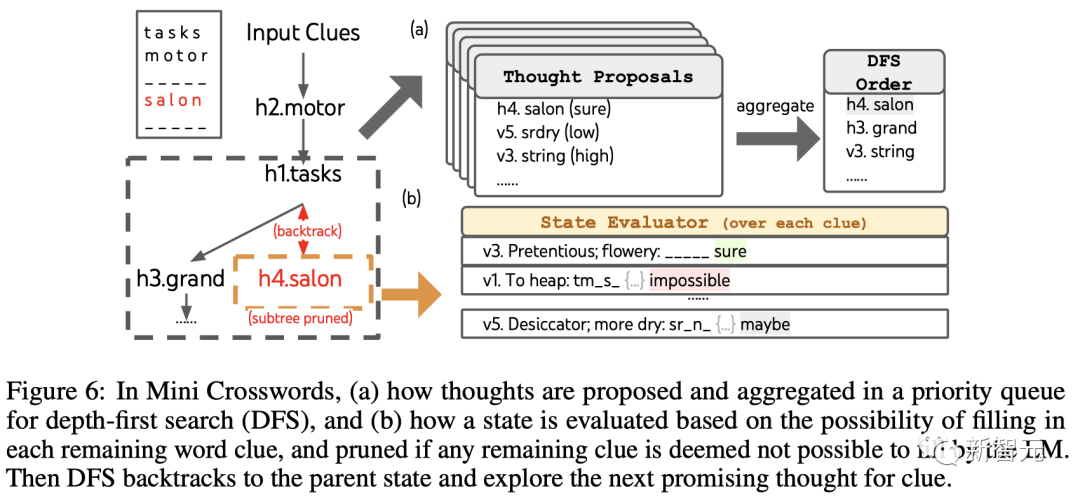
ToT. Einstellungen#🎜🎜 #
Das Team verwendet eine Tiefensuche, um nachfolgende Worthinweise, die am wahrscheinlichsten erfolgreich sind, weiter zu untersuchen, bis der Zustand nicht mehr vielversprechend ist, und kehrt dann zum übergeordneten Zustand zurück, um alternative Gedanken zu erkunden.Um die Suche zu ermöglichen, dürfen nachfolgende Gedanken keine ausgefüllten Wörter oder Buchstaben ändern, sodass das ToT maximal 10 Zwischenschritte hat.
Zur Gedankengenerierung kombiniert das Team alle vorhandenen Gedanken in jedem Zustand (zum Beispiel „h2.motor; h1.tasks“ für Abbildung 6(a) Der Zustand in ) wird in die Buchstabenbeschränkung der verbleibenden Hinweise umgewandelt (z. B. „v1.To heap: tm___;...“), wodurch Kandidaten zum Ausfüllen der Position und des Inhalts des nächsten Wortes erhalten werden.
Wichtig ist, dass das Team den LLM auch auffordert, Konfidenzniveaus für verschiedene Ideen anzugeben, und diese im Vorschlag zusammenfasst, um eine Rangliste der als nächstes zu untersuchenden Ideen zu erhalten (Abbildung 6). (A)).
Zur Statusbewertung wandelt das Team auf ähnliche Weise jeden Status in ein Buchstabenlimit für die verbleibenden Hinweise um und bewertet dann, ob jeder Hinweis wahrscheinlich innerhalb des vorgegebenen Limits gefüllt wird .
Wenn verbleibende Hinweise als „unmöglich“ erachtet werden (z. B. „v1. To heap: tm_s_“), wird die Erkundung des Teilbaums dieses Zustands beschnitten. und DFS kehrt zu seinem übergeordneten Knoten zurück, um den nächsten möglichen Kandidaten zu untersuchen.
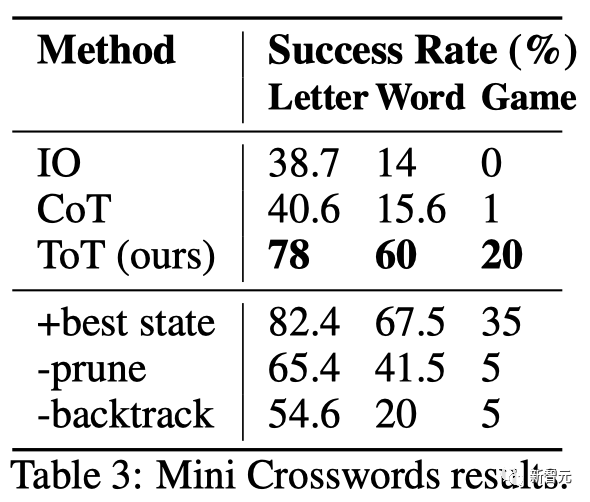
Ergebnis# 🎜🎜#Wie in Tabelle 3 gezeigt, schnitten die Aufforderungsmethoden von IO und CoT bei der Erfolgsquote auf Wortebene schlecht ab, unter 16 %, während ToT alle Metriken deutlich verbesserte und 60 % auf Wortebene erreichte Erfolgsquote und löste 4 von 20 Spielen.
Diese Verbesserung ist nicht überraschend, da IO und CoT über Mechanismen verfügen, um verschiedene Hinweise auszuprobieren, Entscheidungen zu ändern oder einen Rückzieher zu machen.
ToT ist ein Framework, das es LLM ermöglicht, autonomer und intelligenter Entscheidungen zu treffen und Probleme zu lösen.
Es verbessert die Interpretierbarkeit von Modellentscheidungen und die Möglichkeit der Übereinstimmung mit Menschen, da die von ToT generierte Darstellungstabellenform eine lesbare, hochsprachliche Argumentation ist, anstatt ein impliziter Tokenwert auf niedriger Ebene.
ToT ist möglicherweise nicht für die Aufgaben erforderlich, bei denen GPT-4 bereits sehr gut ist.
Darüber hinaus erfordern Suchmethoden wie ToT mehr Ressourcen (z. B. GPT-4-API-Kosten), um die Aufgabenleistung zu verbessern, aber die modulare Flexibilität von ToT ermöglicht diese Leistung. Der Kostenausgleich kann vom Benutzer angepasst werden.
Da LLM jedoch in eher realen Entscheidungsanwendungen (wie Programmierung, Datenanalyse, Robotik usw.) eingesetzt wird, kann ToT Einblicke in diese Bereiche liefern die anstehenden komplexeren Aufgaben und bieten so neue Möglichkeiten. #🎜🎜 ##### 🎜🎜 ## 🎜🎜##🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#Shunyu yao (Yao Shunyu)#🎜🎜 ## 🎜🎜 # # 🎜🎜#
Der Erstautor der Arbeit Shunyu Yao ist Doktorand im vierten Jahr an der Princeton University und hat zuvor seinen Abschluss an der Tsinghua gemacht Universitäts-Yao-Klasse in der Universität. Seine Forschungsrichtung besteht darin, die Interaktion zwischen Sprachagenten und der Welt zu etablieren, beispielsweise beim Spielen von Wortspielen (CALM), beim Online-Shopping (WebShop) und beim Durchsuchen von Wikipedia (ReAct) oder, basierend auf der gleichen Idee, die Verwendung eines beliebigen Tools zur Erledigung einer beliebigen Aufgabe.
 Im Leben liebt er Lesen, Basketball, Billard, Reisen und Rappen. #🎜🎜 ##### 🎜🎜 ## 🎜🎜 ## 🎜🎜#dian yu#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜
Im Leben liebt er Lesen, Basketball, Billard, Reisen und Rappen. #🎜🎜 ##### 🎜🎜 ## 🎜🎜 ## 🎜🎜#dian yu#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜
Seine Forschungsinteressen sind die Eigenschaftsdarstellung von Sprache sowie mehrsprachiges und multimodales Verstehen, wobei er sich hauptsächlich auf die Konversationsforschung (sowohl offene Domäne als auch aufgabenorientiert) konzentriert.
Yuan Cao
Yuan Cao ist auch Mitglied von Google DeepMind-Forscher. Zuvor erhielt er seinen Bachelor- und Master-Abschluss von der Shanghai Jiao Tong University und seinen Doktortitel von der Johns Hopkins University. Er fungierte auch als Chefarchitekt von Baidu. #🎜🎜 ##### 🎜🎜 ## 🎜🎜 ## 🎜🎜#jeffrey zhao#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜# #🎜 🎜## 🎜🎜#Jeffrey Zhao ist Softwareentwickler bei Google DeepMind. Zuvor erhielt er seinen Bachelor- und Master-Abschluss von der Carnegie Mellon University.
Das obige ist der detaillierte Inhalt vonGPT-4-Argumentation um 1750 % verbessert! Der Absolvent der Princeton-Tsinghua Yao-Klasse schlug ein neues „Thinking Tree ToT'-Framework vor, um LLM immer wieder neu denken zu lassen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Welche Plattform ist besser für den Handel mit virtuellen Währungen?
Welche Plattform ist besser für den Handel mit virtuellen Währungen?
 oicq
oicq
 Wie man negative Zahlen binär darstellt
Wie man negative Zahlen binär darstellt
 So löschen Sie einen Ordner unter Linux
So löschen Sie einen Ordner unter Linux
 Linux-Suchbefehlsverwendung
Linux-Suchbefehlsverwendung
 Was ist der Unterschied zwischen Hardware-Firewall und Software-Firewall?
Was ist der Unterschied zwischen Hardware-Firewall und Software-Firewall?
 Welche Funktion hat Huawei NFC?
Welche Funktion hat Huawei NFC?
 So ändern Sie den Text auf dem Bild
So ändern Sie den Text auf dem Bild








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



