



In Szenarien mit hoher Parallelität weist die Datenbank ohne Berücksichtigung anderer Middleware die folgenden Szenarien auf:
Lesen: Es gibt kein Problem und es ist auch keine Parallelitätskontrolle erforderlich.
Lesen und Schreiben: Es gibt Thread-Sicherheitsprobleme, die zu Problemen bei der Transaktionsisolation führen können und zu Dirty Reads, Phantom Reads und nicht wiederholbaren Reads führen können.
Geschrieben: Es gibt Thread-Sicherheitsprobleme und es kann zu Problemen mit Update-Verlusten kommen, z. B. dass der erste Update-Typ verloren geht und der zweite Update-Typ verloren geht.
Angesichts der oben genannten Probleme legt der SQL-Standard fest, dass die Probleme, die unter verschiedenen Isolationsstufen auftreten können, unterschiedlich sind:
MySQL vier Hauptisolationsstufen:
| Isolationsstufe | Dirty Read | Nicht -wiederholbares Lesen | Phantom-Lesen | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| READ UNCOMMITTED: Uncommitted read | kann passieren | kann passieren | kann passieren | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| READ COMMITTED: readcommitted | aufgelöst | kann passieren | kann passieren | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| REPEATABLE READ: Wiederholbares Lesen | Gelöst | Gelöst | Kann passieren | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SERIALIZABLE: Serialisierbar | Gelöst | Gelöst |
| Seitensperre |
Granularität sperren | Klein | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Verriegelungseffizienz | Langsam | Schnell | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Groß | Klein | Zwischen den zwei | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Ja | Nein | Ja | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
X | IX | S | Kompatibel | ||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Nicht kompatibel | IS | Kompatibel | Kompatibel | ||||||||||||||||||||||||||||||||||
| Nicht kompatibel | Nicht kompatibel | Nicht kompatibel | |||||||||||||||||||||||||||||||||||
| IS | Kompatibel | Kompatibel | Nicht kompatibel | ||||||||||||||||||||||||||||||||||
4.3 Sperren für LesevorgängeFür MySQL-Lesevorgänge gibt es zwei Möglichkeiten zum Sperren. 1️⃣ SELECT * FROM table LOCK IN SHARE MODE Wenn die aktuelle Transaktion diese Anweisung ausführt, fügt sie S-Sperren zu den Datensätzen hinzu, die sie liest, sodass andere Transaktionen weiterhin S-Sperren für diese Datensätze erwerben können (Für Andere Transaktionen verwenden beispielsweise auch die Anweisung 如果别的事务想要获取这些记录的 X 锁,那么它们会阻塞,直到当前事务提交之后将这些记录上的 S 锁释放掉 2️⃣ SELECT FROM table FOR UPDATE 如果当前事务执行了该语句,那么它会为读取到的记录加 X 锁,这样既不允许别的事务获取这些记录的 S 锁(比方说别的事务使用 Wenn andere Transaktionen die S- oder 4.4 Sperren für SchreibvorgängeDELETE, UPDATE und INSERT sind gängige Schreibvorgänge in MySQL. Implizites Sperren, automatisches Sperren und Entsperren. 1️⃣ DELETE Der Vorgang zum Durchführen einer DELETE-Operation für einen Datensatz besteht darin, zuerst den Datensatz im B+-Baum zu suchen, dann die X-Sperre des Datensatzes zu erhalten und dann den Löschmarkierungsvorgang auszuführen. Wir können diesen Prozess auch so verstehen, dass die X-Sperre mithilfe der gesperrten Lesemethode erworben wird, um die Position des zu löschenden Datensatzes im B+-Baum zu lokalisieren. 2️⃣ EINFÜGEN Normalerweise ist der Vorgang des Einfügens eines neuen Datensatzes nicht gesperrt, um diesen neu eingefügten Datensatz vor der Verwendung durch andere zu schützen, bevor der Transaktionszugriff ausgeführt wird. 3️⃣ UPDATE Beim Durchführen einer UPDATE-Operation für einen Datensatz gibt es drei Situationen: ① Wenn der Schlüsselwert des Datensatzes nicht geändert wurde und der von der aktualisierten Spalte belegte Speicherplatz sich vorher und nachher nicht geändert hat Ändern Sie dann zuerst den Speicherort dieses Datensatzes im B + -Baum, erhalten Sie dann die X-Sperre des Datensatzes und führen Sie schließlich Änderungsvorgänge am Speicherort des ursprünglichen Datensatzes durch. Wir können uns den Prozess des Aufzeichnens des zu ändernden Speicherorts im B+-Baum auch als Sperrlesevorgang zum Erlangen der X-Sperre vorstellen. ② Wenn der Schlüsselwert des Datensatzes nicht geändert wurde und sich der von mindestens einer aktualisierten Spalte belegte Speicherplatz vor und nach der Änderung geändert hat, suchen Sie zuerst die Position des Datensatzes im B+-Baum und rufen Sie dann das X ab Sperren Sie den Datensatz, löschen Sie den Datensatz vollständig (dh verschieben Sie ihn vollständig in die Müllliste) und fügen Sie schließlich einen neuen Datensatz ein. Dieser Vorgang zum Auffinden der Position des zu ändernden Datensatzes im B+-Baum wird als gesperrter Lesevorgang zum Erhalten der X-Sperre betrachtet. Der neu eingefügte Datensatz wird durch die implizite Sperre geschützt, die durch die INSERT-Operation bereitgestellt wird. ③ Wenn der Schlüsselwert des Datensatzes geändert wird, entspricht dies dem Ausführen einer DELETE-Operation für den ursprünglichen Datensatz und der anschließenden Ausführung einer INSERT-Operation. Der Sperrvorgang muss gemäß den Regeln von DELETE und INSERT ausgeführt werden. PS: Warum können andere Transaktionen trotzdem gelesen werden, wenn die Schreibsperre gesperrt ist? Da InnoDB über einen MVCC-Mechanismus (Multi-Version Concurrency Control) verfügt, können Snapshot-Lesevorgänge verwendet werden, ohne blockiert zu werden. 4. SperrgranularitätsklassifizierungWas ist Sperrgranularität? Die sogenannte Sperrgranularität bezieht sich auf den Umfang dessen, was Sie sperren möchten. Wenn Sie beispielsweise zu Hause auf die Toilette gehen, müssen Sie nur das Badezimmer abschließen. Sie müssen nicht das gesamte Haus abschließen, um zu verhindern, dass Familienmitglieder das Badezimmer betreten. Was ist eine sinnvolle Sperrgranularität? Tatsächlich wird das Badezimmer nicht nur zum Toilettengang genutzt, sondern auch zum Duschen und Händewaschen. Dabei geht es um die Optimierung der Sperrgranularität. Wenn Sie im Badezimmer duschen, können andere tatsächlich gleichzeitig hineingehen und sich die Hände waschen, solange sie isoliert sind, wenn Toilette, Badewanne und Waschbecken alle getrennt und relativ unabhängig (nass und trocken) sind sind getrennt), tatsächlich kann das Badezimmer von drei Personen gleichzeitig genutzt werden, aber natürlich können die drei Personen nicht dasselbe tun. Dadurch wird die Granularität des Schlosses verfeinert. Sie müssen die Badezimmertür nur dann schließen, wenn Sie duschen, und andere können trotzdem hineingehen und sich die Hände waschen. Wenn bei der Gestaltung eines Badezimmers verschiedene Funktionsbereiche nicht getrennt werden, können die Badezimmerressourcen nicht maximiert werden. In ähnlicher Weise gibt es auch in MySQL eine Sperrgranularität. Normalerweise in drei Typen unterteilt:Zeilensperren, Tabellensperren und Seitensperren. 4.1 ZeilensperreBei der Einführung gemeinsamer Sperren und exklusiver Sperren werden diese tatsächlich für eine bestimmte Zeile aufgezeichnet, sodass sie auch als Zeilensperren bezeichnet werden können. Das Sperren eines Datensatzes betrifft nur diesen Datensatz, daher ist die Sperrgranularität von Zeilensperren die feinste in MySQL.Die Standardsperre der InnoDB-Speicher-Engine ist die Zeilensperre. Es verfügt über folgende Funktionen:
4.2 TabellensperreDie Sperre auf Tabellenebene ist eine Sperre auf Tabellenebene, die die gesamte Tabelle sperrt. Sie kann Deadlocks sehr gut vermeiden und ist außerdem der größte granulare Sperrmechanismus in MySQL. Die Standardsperre der MyISAM-Speicher-Engine ist die Tabellensperre. Es hat die folgenden Eigenschaften:
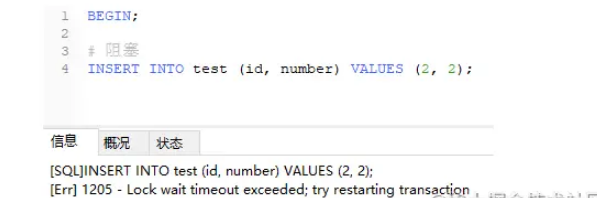
1、开启 A、B 两个事务; 2、首先 A 先查询 3、在 B 没释放锁的情况下,A 尝试对 4、若此时,事务 B 在没释放锁的情况下尝试对
此时,MySQL 检测到了死锁,并结束了 B 中事务的执行,此时,切回事务 A,发现原本阻塞的 SQL 语句执行完成了。可通过 如何避免 从上面的案例可以看出,死锁的关键在于:两个(或以上)的 Session 加锁的顺序不一致,所以我们在执行 SQL 操作的时候要让加锁顺序一致,尽可能一次性锁定所需的数据行。 |
Das obige ist der detaillierte Inhalt vonWas sind MySQL-Sperren und -Klassifizierungen?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen







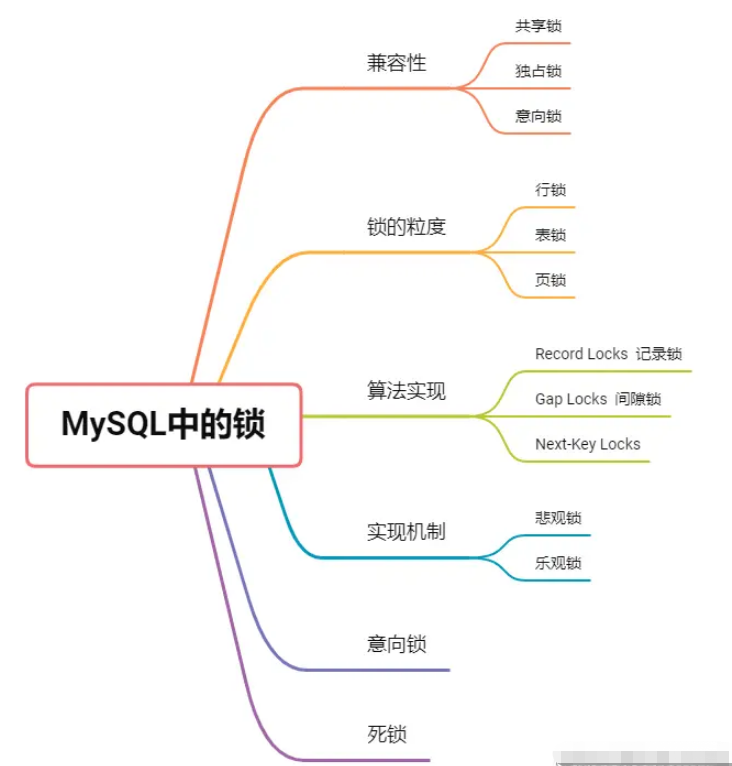 2. Sperren und Klassifizierungen in MySQL
2. Sperren und Klassifizierungen in MySQL 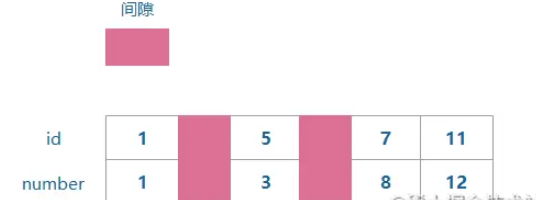



![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



