



Das Sichtfeld der Tesla-Kamera kann 360° um die Karosserie herum abdecken, mit einem 120°-Fisch Die nach vorne gerichteten Augen und Teleobjektive werden verwendet, um die Beobachtung zu verbessern, und die Anordnung ist wie oben gezeigt. 2. Tesla-Bilddaten-Vorverarbeitung Die dynamische Position wird um das 16-fache erweitert. Es gibt zwei Gründe, warum Tesla dies tut:
 2) Die Existenz eines ISP ist einer Hochgeschwindigkeits-Datenübertragung nicht förderlich und beeinträchtigt die Bildrate von Bildern. Es ist viel schneller, das Originalsignal im Netzwerkbetrieb zu verarbeiten.
2) Die Existenz eines ISP ist einer Hochgeschwindigkeits-Datenübertragung nicht förderlich und beeinträchtigt die Bildrate von Bildern. Es ist viel schneller, das Originalsignal im Netzwerkbetrieb zu verarbeiten.
Diese Methode geht über traditionelles ISP-ähnliches Fachwissen hinaus und erlernt direkt stärkere ISP-Fähigkeiten vom nachfragegesteuerten Back-End-Netzwerk, wodurch die Wahrnehmungsfähigkeiten des Systems bei schlechten Lichtverhältnissen und schlechten Sichtverhältnissen über das menschliche Auge hinaus verbessert werden können. Basierend auf diesem Prinzip sollte es eine bessere Möglichkeit sein, Lidar- und Radar-Rohdaten für die Netzwerkanpassung zu nutzen. 3.backbone-Netzwerk: Entwerfen von Netzwerk-Designräumen Faltung, Pooling und andere Module: Verbindungskombination/Trainingsbewertung/Auswahl des Besten), was den Nachteil hat, dass es nicht in der Lage ist, neue Module zu erstellen. Es kann neue Designraumparadigmen erstellen und mehr Szenenanpassungsromane erkunden. Dadurch entfällt die Notwendigkeit, die Architektur neuronaler Netzwerke gezielt zu erforschen und zu entwerfen. Sollte ein besseres BackBone herauskommen, kann dieses Teil ausgetauscht werden. 4. Neckwork: EfficientDet: Skalierbare und effiziente Objekterkennung Es wird ein zusätzlicher Bottom-Up-Pfadfluss hinzugefügt, der höhere Parameter und Berechnungen mit sich bringt.
BiFPN entfernt Knoten mit nur einer Eingabe (die obere und untere Ebene), da der Zweck des Netzwerks Fusionsfunktionen sind, also Knoten ohne Fusionsfähigkeiten direkt anschließbar.
BiFPN verbindet den Eingabeknoten direkt mit dem Ausgabeknoten und integriert so mehr Funktionen, ohne die Berechnungen zu erhöhen.
BiFPN stapelt die Grundstruktur in mehreren Schichten und kann höherdimensionale Features integrieren. 5.BEV Fusion: Räumliches Verständnis der FSD-Wahrnehmung.
Vor dem Aufkommen von BEV basierten die gängigen Lösungen für die autonome Fahrwahrnehmung alle auf dem 2D-Bildraum der Kamera, aber die nachgelagerten Wahrnehmungsanwendungen – Entscheidungsfindung und Wegplanung – werden alle darin durchgeführt der 2D-BEV-Raum, in dem sich das Fahrzeug befindet. Die Barriere zwischen Wahrnehmung und Regulierung behindert die Entwicklung von FSD. Um diese Barriere zu beseitigen, ist es notwendig, die Wahrnehmung vom 2D-Bildraum auf den 2D-Raum des Selbstfahrzeug-Referenzsystems, also den BEV-Raum, umzustellen.
Basierend auf traditioneller Technologie:
verwendet IPM (Inverse Perspektivische Zuordnung) Nehmen Sie an, dass der Boden eine Ebene ist, und konvertieren Sie den 2D-Bildraum mithilfe der externen Parameter des Kamera-Selbstfahrzeugs in den 2D-Selbstfahrzeugraum, dh den BEV-Vogelperspektivenraum. Hier gibt es einen offensichtlichen Fehler: Die Flugzeugannahme gilt nicht mehr, wenn es auf der Straße Höhen und Tiefen gibt.
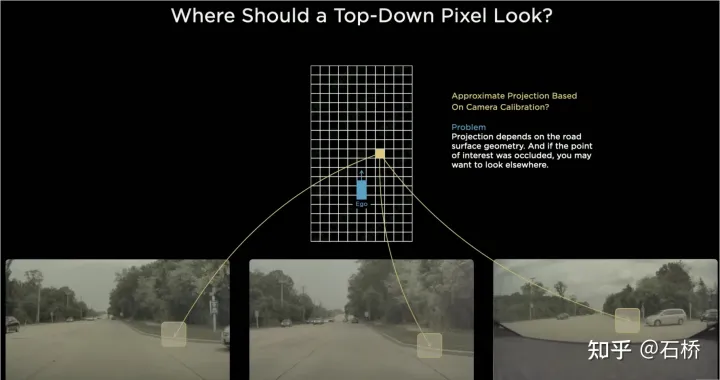
Multikamera-Kantenstichproblem
Da das Sichtfeld jeder Kamera begrenzt ist, müssen Sie auch dann, wenn Sie IPM zum Konvertieren des 2D-Bildraums in den 2D-BEV-Raum verwenden, die BEV-Raumspleißung mehrerer Kamerabilder lösen. Dies erfordert tatsächlich einen hochpräzisen Multikamera-Kalibrierungsalgorithmus und einen Online-Echtzeit-Korrekturalgorithmus. Zusammenfassend muss erreicht werden, dass die Merkmale des 2D-Bildraums mit mehreren Kameras dem BEV-Raum zugeordnet werden und gleichzeitig das Problem der Transformationsüberlappung gelöst wird, das durch Kalibrierung und nichtplanare Annahmen verursacht wird.
Teslas Implementierung der BEV-Schicht basierend auf Transformer:
 # 🎜🎜#
# 🎜🎜#
BEV_FUSION
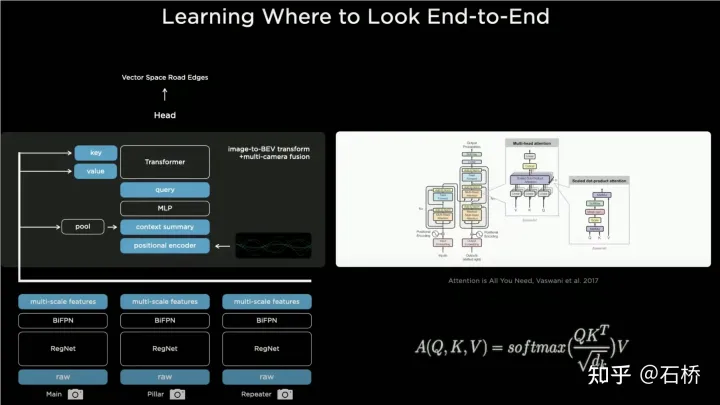
Zunächst extrahiert jede Kamera mehrere Signale über das CNN-Backbone-Netzwerk bzw. BiFPN. Die Multiskalen-Feature-Schicht generiert einerseits den in der Transformer-Methode erforderlichen Schlüssel und Wert über die MLP-Schicht und führt andererseits eine globale Pooling-Operation für die Multi-Maßstabs-Feature-Map durch, um eine zu erhalten globaler Beschreibungsvektor (d. h. Kontext in der Abbildung) Zusammenfassung) und rastern Sie gleichzeitig den Zielausgabe-BEV-Raum, führen Sie dann eine Positionscodierung für jedes BEV-Raster durch, verketten Sie diese Positionscodes mit dem globalen Beschreibungsvektor (Concatenate) und übergeben Sie sie dann eine MLP-Schicht, um die vom Transformer benötigte Abfrage zu erhalten.
In der Cross-Attention-Operation bestimmt der Maßstab der Abfrage den Ausgabemaßstab nach der letzten BEV-Ebene (d. h. den Maßstab des BEV-Rasters) und Schlüssel und Die Werte werden im 2D-Bild entsprechend dem Prinzip des Transformers verwendet, um das Einflussgewicht jedes BEV-Rasters zu ermitteln, das die Pixel der 2D-Bildebene empfängt, und so die Zuordnung vom BEV zum zu ermitteln Das Eingabebild wird dann mit diesen Gewichten gewichtet, um die Bildebene zu gewichten. Der aus den Merkmalen erhaltene Wert wird schließlich als Feature-Map unter dem BEV-Koordinatensystem erhalten, wodurch die Mission der BEV-Koordinatenkonvertierungsebene später abgeschlossen wird Unter BEV können ausgereifte Sensorfunktionsköpfe verwendet werden, um die Erfassung direkt im BEV-Raum durchzuführen. Die Wahrnehmungsergebnisse im BEV-Raum werden mit dem Koordinatensystem der Entscheidungsplanung vereinheitlicht, sodass Wahrnehmung und Folgemodule durch die BEV-Transformation eng verknüpft sind.

Kalibrierung#🎜🎜 ## 🎜🎜#Durch diese Methode werden tatsächlich Änderungen der externen Kameraparameter und der Bodengeometrie während des Trainingsprozesses vom neuronalen Netzwerkmodell in Parameter internalisiert. Ein Problem besteht darin, dass es geringfügige Unterschiede in den extrinsischen Kameraparametern verschiedener Autos gibt, die denselben Satz von Modellparametern verwenden. Karparthy hat für Tesla eine Methode hinzugefügt, um mit den extrinsischen Parameterunterschieden umzugehen: Sie verwenden die kalibrierten extrinsischen Parameter zum Vergleich Die gesammelten Bilder werden durch Entzerrung, Drehung und Wiederherstellung der Verzerrung einheitlich in die Layoutposition desselben Satzes virtueller Standardkameras umgewandelt, wodurch die geringfügigen Unterschiede in den externen Parametern verschiedener Fahrzeugkameras beseitigt werden.
BEVs Methode ist ein sehr effektives Multikamera-Fusions-Framework. Durch die BEV-Lösung ist die Größenschätzung und Verfolgung großer Ziele in unmittelbarer Nähe über mehrere Kameras hinweg besser geworden ist genauer und stabiler. Gleichzeitig macht diese Lösung den Algorithmus robuster gegenüber der kurzfristigen Okklusion und dem Verlust einer oder mehrerer Kameras. Kurz gesagt, BEV löst das Problem der Bildfusion und des Zusammenfügens mehrerer Kameras und erhöht die Robustheit.

löst die Mehrkamera-Spurlinien- und Grenzfusion

Die Hindernisse werden stabiler
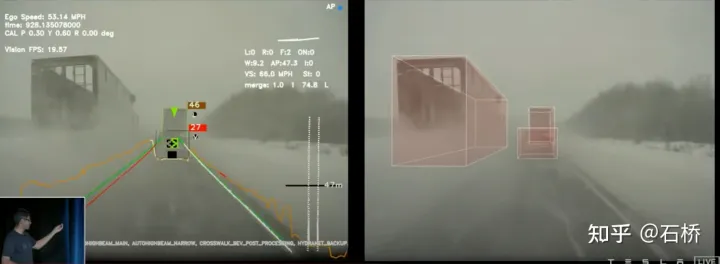
# 🎜🎜#(Der PPT nach zu urteilen, sollte Teslas ursprüngliche Lösung hauptsächlich nach vorne gerichtete Kameras zur Wahrnehmung und Spurlinienvorhersage verwenden.)
#🎜🎜 #6.Architektur neuronaler Netze für Videos: Raum-Zeit-Sequenz-Funktionskonstruktion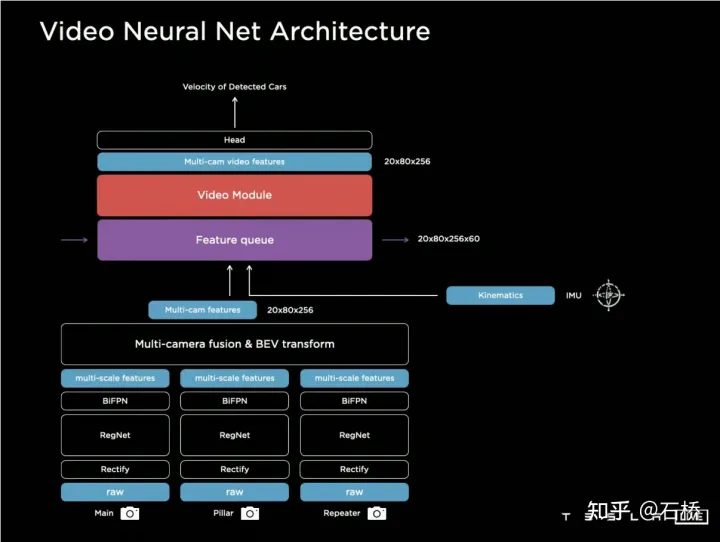
In Bezug auf die Zusammenführung von Timing-Informationen hat Tesla drei gängige Lösungen ausprobiert: 3D-Faltung, Transformer und RNN. Diese drei Methoden müssen alle die Bewegungsinformationen des eigenen Fahrzeugs mit der Einzelbildwahrnehmung kombinieren, wobei die Bewegungsinformationen des eigenen Fahrzeugs nur vierdimensionale Informationen einschließlich Geschwindigkeit und Beschleunigung verwenden können Kombiniert mit dem BEV-Raum (20 x 80 x 256) und der Positionskodierung werden sie zu einer 20 x 80 x 300 x 12-dimensionalen Merkmalsvektorwarteschlange kombiniert. Die dritte Dimension besteht hier aus 256-dimensionalen visuellen Merkmalen + 4-dimensionalen kinematischen Merkmalen (vx, vy). , ax, ay) und 40-dimensionale Position. Es besteht aus Positionskodierung, also 300 = 256 + 4 + 40, und die letzte Dimension ist die 12-Frame-Zeit-/Raumdimension nach Downsampling. 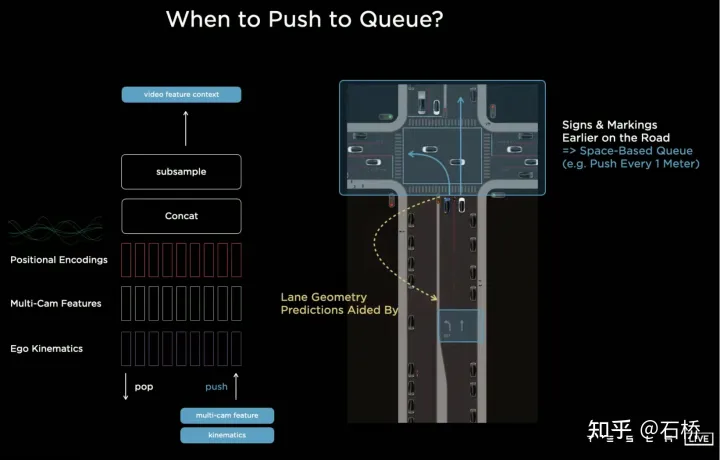
3D Conv, Transformer und RNN können alle Sequenzinformationen verarbeiten Aber meistens gibt es keinen großen Unterschied darin, welche Lösung verwendet wird. Am AI Day stellte Karparthy jedoch auch eine einfache, effektive und sehr interessante und erklärbare Lösung vor. Der Unterschied zu den oben genannten drei Methoden liegt darin, dass RNN ursprünglich Sequenzinformationen seriell verarbeitet und die Reihenfolge zwischen Frames erhalten bleibt. Daher können BEV-visuelle Merkmale ohne Positionscodierung direkt in das RNN-Netzwerk eingespeist werden, sodass Sie hier sehen können Die Eingabe Die Informationen umfassen nur die visuelle Feature-Map des BEV im Format 20 x 80 x 256 und die Bewegungsinformationen des eigenen Fahrzeugs im Format 1 x 1 x 4. 
Räumliche Merkmale beziehen sich in CNN oft auf Merkmale in der Breite und Höhe auf der Bildebene, hier in Spatial RNN Spatial bezieht sich auf zwei Dimensionen in einem lokalen Koordinatensystem basierend auf den BEV-Koordinaten zu einem bestimmten Zeitpunkt. Zur Veranschaulichung wird hier die RNN-Schicht von LSTM verwendet. Der Vorteil von LSTM ist seine starke Interpretierbarkeit. 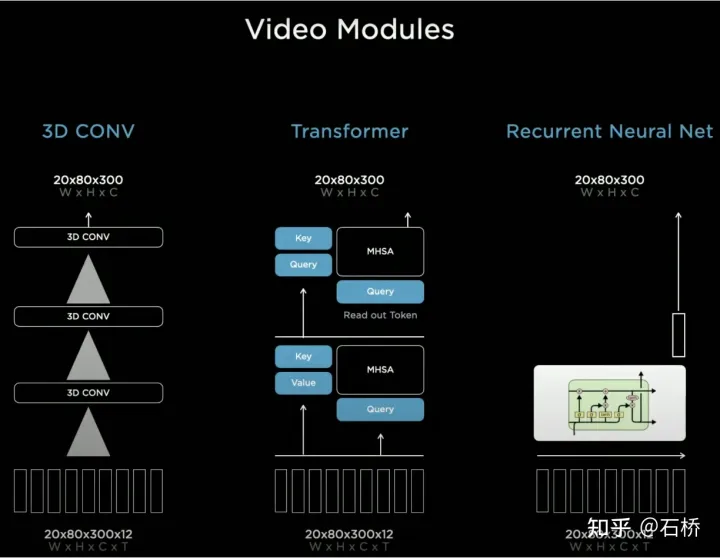
Das Merkmal von LSTM besteht darin, dass der verborgene Zustand die Codierung des Zustands der vorherigen N Momente mit variabler Länge (dh Kurzzeitgedächtnis) beibehalten kann und dann der aktuelle Moment bestimmen kann, welcher Teil des Speicherzustands benötigt wird verwendet werden soll und welcher Teil durch den Eingabe- und Hidden-State-Teil davon vergessen werden muss und so weiter. In Spatial RNN ist der Hidden State ein rechteckiger Gitterbereich, der größer als der BEV-Gitterraum ist, mit einer Größe von (BxHxC) (siehe Abbildung oben, BxH ist größer als die BEV-Größe von 20x80). Welcher Teil des Hidden State-Gitters ist betroffen, sodass die kontinuierlichen BEV-Daten den großen rechteckigen Bereich des Hidden State kontinuierlich aktualisieren und die Position jeder Aktualisierung mit der Bewegung von übereinstimmt das Selbstfahrzeug. Nach kontinuierlichen Aktualisierungen wird eine Hidden State Feature Map ähnlich einer lokalen Karte erstellt, wie in der folgenden Abbildung dargestellt.

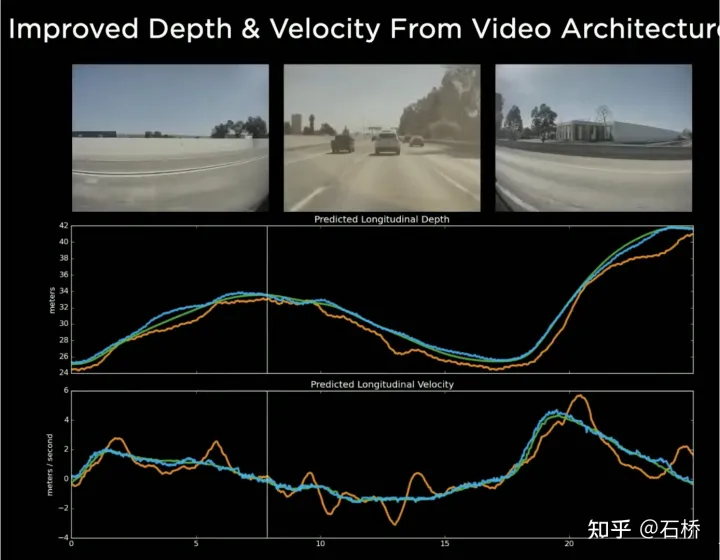
Die Verwendung von Timing-Warteschlangen gibt dem neuronalen Netzwerk die Möglichkeit, kontinuierliche Wahrnehmungsergebnisse zwischen Frames zu erhalten. In Kombination mit BEV kann FSD selektiv mit toten Winkeln und Verdeckungen im Sichtfeld umgehen Durch die Fähigkeit, lokale Karten zu lesen und zu schreiben, kann FSD autonomes Fahren in Städten durchführen, ohne auf hochpräzise Karten angewiesen zu sein. Es verfügt nicht nur über 3D-Kartenfunktionen, sondern auch über lokale 4D-Szenenkonstruktionsfunktionen, die für Vorhersagen usw. verwendet werden können. Nach der Veröffentlichung von Occupancy wurde allgemein angenommen, dass die auf Spatial RNN basierende Lösung in die oben erwähnte Transformatorlösung geändert wurde.

Die 2D-Vogelperspektive von BEV liegt offensichtlich immer noch weit hinter den 3D-Szenen, mit denen echtes autonomes Fahren konfrontiert ist, daher muss es bestimmte Szenarien geben wo die BEV2D-Wahrnehmung versagt. Im Jahr 2021 wird Tesla in der Lage sein, in die Tiefe zu bauen, sodass es nur eine Frage der Zeit von 2D auf 3D ist. Im Jahr 2022 wird es das Occupancy Network bringen, das eine weitere Erweiterung des BEV-Netzwerks in die Höhenrichtung darstellt. Herunterfahren des BEV-Koordinatensystems. Die durch die 2D-Rasterpositionskodierung generierte Abfrage wird auf die durch die 3D-Rasterpositionskodierung generierte Abfrage aktualisiert und das BEV-Feature wird durch das Belegungsmerkmal ersetzt.
Auf der CVPR2022 gab Ashork die Gründe für die Verwendung der Belegungsfunktion anstelle der bildbasierten Tiefenschätzung an:

1) Die Tiefenschätzung ist in der Nähe in Ordnung, aber in der Ferne ist die Tiefe inkonsistent. Es gibt weniger Der Tiefenwert zeigt näher am Boden (dies ist durch das Abbildungsprinzip des Bildes begrenzt. Der durch ein Pixel in 20 m Entfernung dargestellte vertikale Abstand kann 30 cm überschreiten), und die Daten sind im nachfolgenden Planungsprozess nur schwer zu verwenden.
2) Das tiefe Netzwerk basiert auf Regression und ist durch Okklusion schwer vorherzusagen, sodass es an der Grenze schwer vorherzusagen ist und möglicherweise reibungslos vom Fahrzeug in den Hintergrund übergeht.
Die Vorteile der Verwendung von Occupancy sind wie folgt:
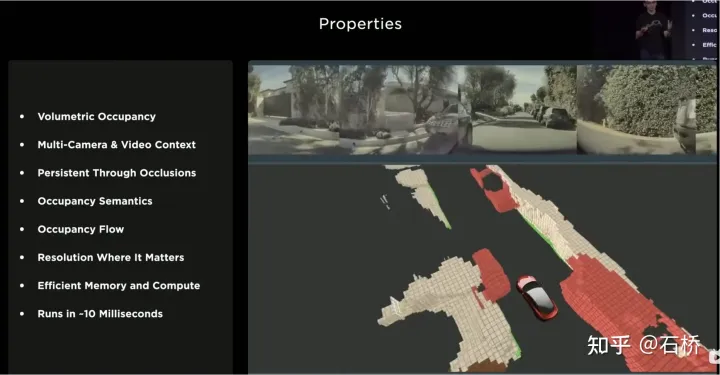
Occupancy-Vorteile
1) Im BEV-Raum werden einheitliche Voxel generiert, und die Belegungswahrscheinlichkeit jedes Voxels kann vorhergesagt werden
2) Die Videostreams aller Kameras werden abgerufen und vereinheitlicht (es gibt kein Lidar-Kamera-Fusionsproblem und die Informationsdimension ist höher als die von Lidar)
3) Kann den Status von vorhersagen verdeckte Objekte in Echtzeit (die Dynamik der Belegung. Die Beschreibungsfähigkeit ist der Übergang von 3D zu 4D)
4) Für jedes Voxel können entsprechende semantische Kategorien generiert werden (die Erkennungsfähigkeit von Bildern ist viel stärker als bei Lidar)

auch wenn die Kategorie nicht erkannt wird. Umgang mit sich bewegenden Objekten
5) Der Bewegungszustand kann für jedes Voxel vorhergesagt und zufällige Bewegungen modelliert werden
6) Die Auflösung jeder Position kann angepasst werden (d. h. sie verfügt über BEV-Räumlichkeitszoomfunktion)
7) Dank der Hardware von Tesla bietet Occupancy effiziente Speicher- und Rechenvorteile )
Der Vorteil der Occupancy-Lösung im Vergleich zur Bounding-Box-Wahrnehmungslösung besteht darin, dass
unbekannte Objekte beschreiben kann, die keinen festen Bounding-Box haben, ihre Form nach Belieben ändern und sich nach Belieben bewegen können, was die Verbesserung der Beschreibung der Granularität von Hindernissen von der Box bis zur Voxel-Granularität kann viele Long-Tail-Probleme in der Wahrnehmung lösen.
Werfen wir einen Blick auf die Gesamtlösung von Occupancy:

1) Bildeingabe: Geben Sie Originalbildinformationen ein und erweitern Sie die Datendimension und den Dynamikbereich
2) Bildmerkmale: RegNet+BiFPN extrahiert mehrskalige Bildmerkmale
3) Räumliche Aufmerksamkeit: Aufmerksamkeitsbasierte Multikamera-Fusion von 2D-Bildmerkmalen durch räumliche Abfrage mit räumlicher 3D-Position
Implementierungsplan 1: Gemäß den internen und externen Parametern jeder Kamera projizieren Sie die räumliche 3D-Abfrage auf die 2D-Feature-Karte, um die Features der entsprechenden Position zu extrahieren.
Implementierungsplan 2: Verwenden Sie die Positionseinbettung, um eine implizite Zuordnung durchzuführen, dh fügen Sie jeder Position der 2D-Feature-Map eine angemessene Positionseinbettung hinzu, z. B. interne und externe Parameter der Kamera, Pixelkoordinaten usw., und lassen Sie sie dann Modell lernt von selbst 2D zu 3D Korrespondenz von Features
4) Zeitliche Ausrichtung: Verwenden Sie Trajektorieninformationen, um die 3D-Belegungsmerkmale jedes Frames in der räumlichen Kanaldimension in zeitlicher Reihenfolge zu verbinden. Im Laufe der Zeit kommt es zu einer Gewichtsabschwächung Die kombinierten Funktionen werden in das Deconvolutions-Modul eingegeben, um die Auflösung zu verbessern
5) Volumenausgaben: Geben Sie die Belegung und den Belegungsfluss von Rastern fester Größe aus
6) Abfragbare Ausgaben: Ein implizit abfragbarer MLP-Decoder ist für die Eingabe beliebiger Koordinaten ausgelegt Wert (x, y, z), der verwendet wird, um kontinuierliche Voxelsemantik, Belegungsrate und Belegungsflussinformationen mit höherer Auflösung zu erhalten, wodurch die Beschränkung der Modellauflösung aufgehoben wird
7) Befahrbares Flächenpflaster mit dreidimensionaler Geometrie und Semantik generieren, Fördert die Kontrolle an Steigungen und kurvigen Straßen.
 Der Boden stimmt mit der Belegung überein
Der Boden stimmt mit der Belegung überein
8) NeRF-Status: Nerf baut die geometrische Struktur der Szene auf, kann Bilder aus jeder Perspektive erzeugen und hochauflösende reale Szenen wiederherstellen.
Wenn es durch Nerf aufgerüstet oder ersetzt werden kann, ist es in der Lage, echte Szenen wiederherzustellen, und diese Szenenwiederherstellungsfunktion wird Vergangenheit, Gegenwart und Zukunft sein. Es sollte eine großartige Ergänzung und Verbesserung der 4D-Szene des autonomen Fahrens sein, die von Teslas technischen Lösungen verfolgt wird.
8. FSD Lanes Neural Network: Vorhersage der topologischen Verbindungsbeziehung von Lanes
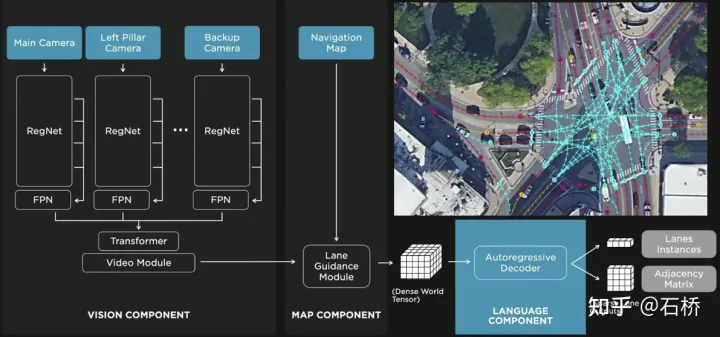 FSD-Bewusstsein für topologische Beziehungen zwischen Spurlinien und Linien
FSD-Bewusstsein für topologische Beziehungen zwischen Spurlinien und Linien
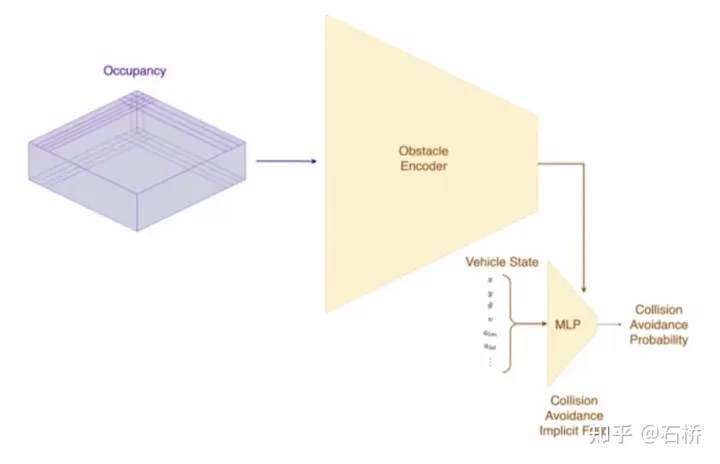
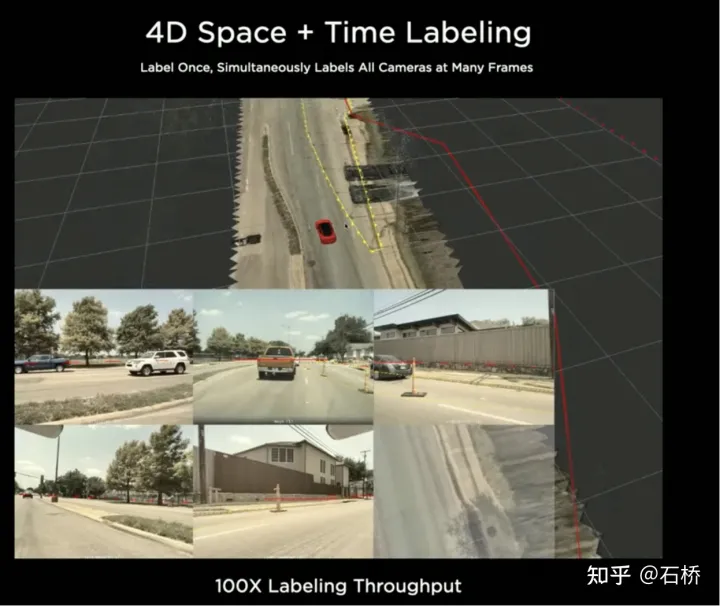
1) Spurführungsmodul: Verwendet die geometrische und topologische Beziehung der Straße in der Navigationskarte, Spurebene, Menge, Breite und Attributinformationen und integriert diese Informationen mit der Belegungsfunktion, um einen dichten Welttensor zu kodieren und zu generieren, um die Topologie festzulegen Beziehung Das Modul analysiert die dichten Merkmale des Videostreams mithilfe des Sequenzgenerierungsparadigmas in die spärlichen Informationen zur Straßentopologie (Spurknotensegment und angrenzende Verbindungsbeziehung). 2) Sprachkomponente: Codieren Sie spurbezogene Informationen, einschließlich Spurknotenpositionen, Attribute (Startpunkt, Zwischenpunkt, Endpunkt usw.), Gabelungspunkte, Konvergenzpunkte und geometrische Spline-Parameter der Spur, um eine ähnliche Sprache zu erstellen Das Wort-Token im Modell wird codiert und dann mithilfe von Timing-Verarbeitungsmethoden verarbeitet. Der spezifische Prozess ist wie folgt: Prozess der Sprache der Spuren Sprache der Spuren Die endgültige Sprache der Spuren repräsentiert die topologische Verbindungsbeziehung im Diagramm. Die Objektwahrnehmung von FSD ist eine zweistufige Methode. Die erste Stufe beginnt mit der Position des Hindernisses im 3D-Raum wird in Occupancy identifiziert. In der zweiten Stufe werden die Tensoren dieser 3D-Objekte verkettet, um einige kinematische Informationen zu kodieren (z. B. eigene Fahrzeugbewegung, Zielfahrspurlinien, Ampeln, Verkehrssignale usw.). .) und dann verbunden Geben Sie Flugbahnvorhersage, Objektmodellierung, Fußgängerposenvorhersage und andere Köpfe ein. Durch die Fokussierung komplexer Sensorköpfe auf einen begrenzten ROI-Bereich werden Verarbeitungsverzögerungen reduziert. Wie Sie der obigen Abbildung entnehmen können, gibt es zwei Schritte des Videomoduls, die der Vorhersage des eigenen Fahrzeugs bzw. anderer Fahrzeuge dienen. Hinterlassen Sie hier eine Frage: Was ist der Unterschied zwischen den beiden Videomodulen im Bild oben? Wird es Probleme mit der Effizienz geben? 02 Entscheidungsplanung Die Interaktionsentscheidung mit Ersterem wirkt sich direkt auf die Interaktionsstrategie mit Letzterem aus. Die hier gewählte Endlösung lautet: Versuchen Sie, die Bewegung anderer Verkehrsteilnehmer nicht zu behindern. Entscheidungsplanungsprozess Tesla verwendet „Interaktionssuche“, eine Reihe möglicher Bewegungen Flugbahnen sind parallel durchsucht und der entsprechende Zustandsraum umfasst das eigene Fahrzeug, Hindernisse, befahrbare Flächen, Fahrspuren, Ampeln usw. Der Lösungsraum verwendet eine Reihe von Zielbewegungskandidaten-Trajektorien, die sich nach der Teilnahme an der interaktiven Entscheidungsfindung mit anderen Verkehrsteilnehmern verzweigen, dann mit der progressiven Entscheidungsfindung und Planung fortfahren und schließlich die optimale Trajektorie auswählen Abbildung oben: 1) Erhalten Sie den Zielpunkt oder seine Wahrscheinlichkeitsverteilung (Big-Data-Trajektorie) a priori basierend auf der Straßentopologie oder menschlichen Fahrdaten 2) Generieren Sie Kandidatentrajektorien basierend auf dem Zielpunkt (Optimierungsalgorithmus). + neuronales Netzwerk) 3) Verfolgen Sie die Flugbahn des Kandidaten. Rollout und interaktive Entscheidungsfindung, Neuplanung des Pfades, Bewertung des Risikos und der Punktzahl jedes Pfades, Priorisierung der Suche nach dem besten Pfad, um den Zielpunkt zu ermitteln Der Optimierungsausdruck der gesamten Entscheidungsplanung: Der Optimierungsausdruck der Entscheidungsplanung Lightweight-Planungstrajektorien-Abfragenetzwerk Tesla verwendet einen inkrementellen Ansatz Fügen Sie kontinuierlich neue Entscheidungsbeschränkungen hinzu und verwenden Sie die optimale Lösung unter weniger Einschränkungen als Ausgangswert, um weitere Probleme zu lösen. Komplexe Optimierungsprobleme führen letztendlich zu optimalen Lösungen. Aufgrund der Vielzahl möglicher Zweige muss der gesamte Entscheidungs- und Planungsprozess jedoch sehr effizient sein. Jede Entscheidungsplanung des Planers auf der Grundlage des herkömmlichen Optimierungsalgorithmus dauert 1 bis 5 ms, was offensichtlich nicht sicher genug ist Es gibt eine hohe Verkehrsteilnehmerdichte. Der von Tesla verwendete Neural Planner ist ein leichtgewichtiges Netzwerk, das anhand der Fahrdaten menschlicher Fahrer in der Tesla-Flotte trainiert und den wahren Wert des globalen optimalen Pfads unter Offline-Bedingungen ohne zeitliche Einschränkungen plant Die Planung dauert nur 100us. Planungsentscheidungsbewertung Die nach jeder Entscheidung abgefragten mehreren Kandidatenverläufe müssen bewertet werden. Die Bewertung basiert auf Spezifikationen wie Kollisionsprüfung, Komfortanalyse, Übernahmemöglichkeit und menschlicher Interaktion. Der Grad der Ähnlichkeit usw. hilft dabei, den Suchzweig zu beschneiden, um zu verhindern, dass der gesamte Entscheidungsbaum zu groß wird, und kann gleichzeitig die Rechenleistung auf den wahrscheinlichsten Zweig konzentrieren. Tesla betonte, dass diese Lösung auch auf Verdeckungsszenen anwendbar sei. Während des Planungsprozesses werde der Bewegungsstatus des verdeckten Objekts berücksichtigt und die Planung durch das Hinzufügen von „Geistern“ durchgeführt. Geisterverdeckungsszene CVPR teilte auch den Netzwerkprozess zur Kollisionsvermeidung und den entsprechenden Planungsprozess mit, der nicht detailliert beschrieben wird. 03 Szenenrekonstruktion und automatische Anmerkung Teslas leistungsstarke Wahrnehmungsfähigkeit erfordert leistungsstarke Beschriftungsfähigkeiten. Als Unterstützung Die Beschriftung von Tesla hat von 2018 bis heute 4 Phasen durchlaufen: Teslas Beschriftungsiteration Phase 4 ( 2021): Für die Annotation werden mehrere Rekonstruktionen verwendet, und die Genauigkeit, Effizienz und topologischen Beziehungen haben ein extrem hohes Niveau erreicht Teslas automatisches Annotationssystem kann 5 Millionen Stunden manuelle Arbeit ersetzen, nur einen sehr kleinen Teil der manuellen Inspektion und Leckkorrektur ( Der Prozess dieser Multi-Travel-Trajektorien-Rekonstruktionslösung ist wie folgt: (ähnlich einem Offline-Semantic-Slam-System) Automatisches Etikettierungssystem Schritt 1: VIO generiert hochpräzise Trajektorien. Führen Sie den Videostream, die IMU und die Odometrie in das neuronale Netzwerk ein, leiten Sie Punkte, Linien, Boden- und Segmentierungsmerkmale ab und extrahieren Sie sie und verwenden Sie dann Multikamera-VIO zur Verfolgung und Optimierung im BEV-Raum, um 100 Hz 6dof-Trajektorien und 3dof-Strukturen auszugeben und Straßen, und kann auch den Kalibrierungswert der Kamera ausgeben. Die Genauigkeit der rekonstruierten Flugbahn beträgt 1,3 cm/m, 0,45 rad/m, was nicht sehr hoch ist. Alle FSDs können diesen Prozess ausführen, um die vorverarbeiteten Flugbahn- und Strukturinformationen einer bestimmten Fahrt zu erhalten. (Wenn ich mir das Video ansehe, habe ich das Gefühl, dass Vio nur Punktmerkmale explizit verwendet und möglicherweise implizit Linien- und Oberflächenmerkmale verwendet.)
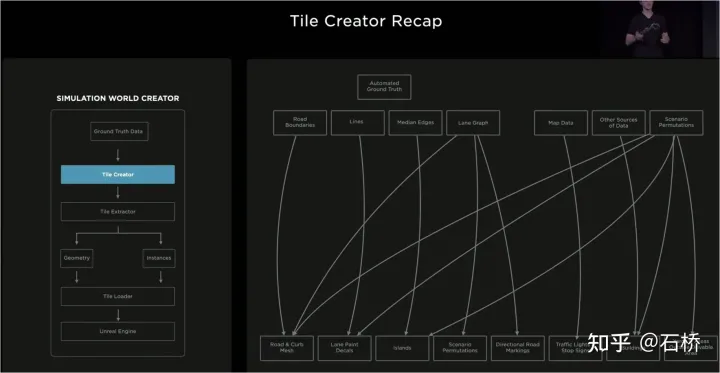
Multi-Pass-Trajektorienrekonstruktion Schritt 2: Multi-Pass-Trajektorie Wiederaufbau. Mehrere rekonstruierte Daten verschiedener Fahrzeuge werden für die grobe Ausrichtung -> Merkmalsabgleich -> Gelenkoptimierung -> Verfeinerung der Straßenoberfläche gruppiert. Anschließend ist eine manuelle Teilnahme erforderlich, um die Beschriftungsergebnisse abschließend zu überprüfen und zu bestätigen. Hier wurde auch eine Straßenoberflächenoptimierung durchgeführt. Es wird vermutet, dass der Fehler der visuellen Rekonstruktion nach der globalen Optimierung relativ groß ist, um den Fehler dieses Teils zu beseitigen Globale Optimierung Fehlzuordnung, Straßenoberflächenoptimierung wurde hinzugefügt. Aus algorithmischer Logik ist eine globale Optimierung gefolgt von einer lokalen Optimierung ein Muss, denn die Voraussetzung für autonomes Fahren besteht darin, überall fahren zu können. Der gesamte Prozess wird auf dem Cluster parallelisiert. Grobausrichtung Schritt 3: Neue Flugbahndaten automatisch kennzeichnen. Auf der vorgefertigten Karte wird derselbe Rekonstruktionsprozess wie bei mehreren Trajektorienrekonstruktionen für die neuen Fahrtrajektoriendaten durchgeführt, sodass die ausgerichteten neuen Trajektoriendaten automatisch semantische Anmerkungen aus der vorgefertigten Karte erhalten können. Dabei handelt es sich tatsächlich um einen Verschiebungsprozess, um semantische Tags zu erhalten. Diese automatische Beschriftung kann eigentlich nur statische Objekte, wie Fahrspurlinien, Straßenbegrenzungen usw., automatisch beschriften. Durch das Wahrnehmungsmodell können tatsächlich semantische Kategorien wie Fahrspurlinien ermittelt werden. In rauen Szenarien treten jedoch Integritäts- und Fehlerkennungsprobleme auf. Diese Probleme können durch diese automatische Annotation gelöst werden. Der Nachteil besteht jedoch darin, dass es möglicherweise nicht für dynamische Hindernisse wie fahrende Fahrzeuge, Fußgänger usw. geeignet ist. Im Folgenden sind Nutzungsszenarien aufgeführt: Nutzungsszenarien automatisch kennzeichnen Viele der von Tesla gezeigten Bilder weisen ein Merkmal auf: Es gibt Unschärfen oder Flecken, die jedoch die wahrgenommenen Ergebnisse nicht ernsthaft beeinträchtigen . Bei normalem Gebrauch kann die Kameralinse des Fahrzeugs leicht verschmutzen, aber mit dieser automatischen Kennzeichnung wird die Wahrnehmung von Tesla sehr robust sein und die Wartungskosten der Kamera werden reduziert. Automatische Kennzeichnung ist nicht für dynamische Fahrzeuge geeignet Rückblickend auf den KI-Tag im Jahr 2021 können wir sehen, dass die obige Rekonstruktion eine statische Welt aufbaut, aber nicht nur Fahrspurlinien und Fahrbahnlinien, aber auch Fahrzeuge und Gebäude. 3D-Rekonstruktion 3D-Rekonstruktion statische Welt rekonstruieren und kommentieren Notation In Bezug auf die Szenenrekonstruktion entsprechen die aktuellen Rekonstruktionsfähigkeiten und -genauigkeiten möglicherweise immer noch nicht den Erwartungen der Tesla-Ingenieure. Ihr ultimatives Ziel besteht darin, alle Szenen, die Tesla-Autos gefahren sind, wirklich wiederherzustellen und zu rekonstruieren Die Szene erzeugt eine neue reale Szene, was das ultimative Ziel ist. Stellen Sie die reale Welt wieder her. Bauen Sie die reale Welt neu auf Szenensimulation Simulation kann eine absolut korrekte Bezeichnung erhalten Die auf der Grundlage der Rekonstruktion erstellte reale Szene ist durch Daten, Algorithmen usw. begrenzt. Sie ist derzeit schwer in großem Maßstab umzusetzen und dauert lange. Zum Beispiel: die Simulation einer realen Kreuzung Das Bild oben dauert 2 Wochen. Die Umsetzung des autonomen Fahrens erfordert jedoch Schulungen und Tests in verschiedenen Szenarien. Daher hat Tesla ein Simulationssystem zur Simulation autonomer Fahrszenarien entwickelt. Dieses System kann reale Szenarien nicht wirklich simulieren, aber der Vorteil besteht darin, dass es 1.000-mal schneller ist als die oben genannten echten gängigen Rekonstruktionslösungen Training des autonomen Fahrens. Simulationsbasierte Architektur Die Architektur dieses Emulators ist wie oben gezeigt. Die folgenden Schritte sind während des Szenenerstellungsprozesses erforderlich: Schritt 1: Auslegen im Simulationswelt Öffnen Sie die Straße, erstellen Sie mithilfe der Grenzbeschriftung das solide Straßennetz und verknüpfen Sie es erneut mit der Straßentopologiebeziehung. Konstruieren Sie im Auffahrtsabschnitt die Fahrspurdetails Schritt 7 Schritt: Generieren Sie zufällige Verkehrsflusskombinationen basierend auf Spurbeziehungen Im obigen Prozess basierend auf einer Reihe wahrer Werte Auf der Spurnavigationskarte können die Simulationsparameter geändert werden, um Änderungen zu generieren, was zu mehreren Kombinationsszenarien führt. Darüber hinaus können je nach Schulungsbedarf einige Attribute des wahren Werts sogar geändert werden, um neue Szenarien zu erstellen und den Schulungszweck zu erreichen.
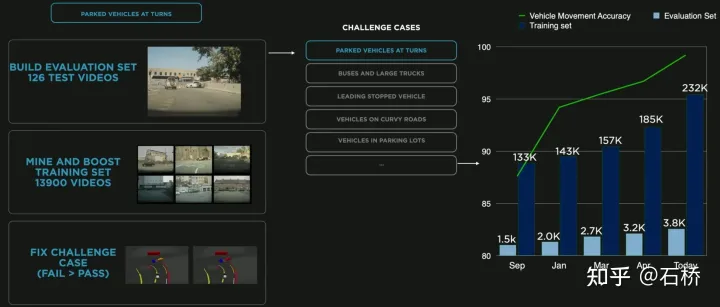
Daten sind in Kachelspeicher unterteilt # 🎜🎜# Eine Welt, die auf Kachelgranularität basiert #🎜🎜 #Oben Die erstellte Simulation basiert auf realen Straßeninformationen, sodass viele praktische Probleme mithilfe der Simulation gelöst werden können. Beispielsweise können autonome Fahrfunktionen in einer simulierten Straßenumgebung in Los Angeles getestet werden. (Die obige Speichermethode wird beim Simulations-Mapping, Speichern und Laden verwendet) Gefühle zum autonomen Fahren unter 05 Daten-Engine: Eckfalldaten abbauen #🎜 🎜#Daten-Closed-Loop-Prozess Die Daten-Engine extrahiert die vom Modell falsch eingeschätzten Daten aus dem Schattenmodus. Ruft es ab und verwendet automatische Annotationstools, um Beschriftungen zu korrigieren und sie dann zu den Trainings- und Testsätzen hinzuzufügen, um das Netzwerk kontinuierlich zu optimieren. Dieser Prozess ist der Schlüsselknoten des geschlossenen Datenkreislaufs und generiert weiterhin Eckfallbeispieldaten. Data Mining für das Parken in Kurven Das Bild oben zeigt eine Modellverbesserung durch Data Mining für das Parken in Kurven. Da dem Training kontinuierlich Daten hinzugefügt werden, verbessert sich der Genauigkeitsindex weiter. 

9. Objektwahrnehmung: Wahrnehmung und Vorhersage anderer Verkehrsteilnehmer

1. Die Schwierigkeit der Entscheidungsfindung und Planung im obigen Szenario besteht darin, dass:
Wenn das Fahrzeug ungeschützt nach links abbiegt und das Kreuzungsszenario passiert, muss es mit Fußgängern und normalen geradeaus fahrenden Fahrzeugen interagieren und die Zusammenhänge zwischen ihnen verstehen mehrere Parteien.
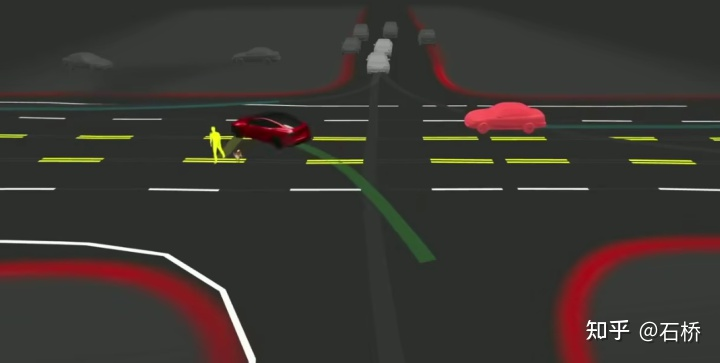
2. Traditionelle Optimierungsmethode: [Gemeinsame Multi-Objekt-Trajektorienplanung]: Multi-Objekt-MPC

3. Parallele Pfadplanung und Bewertungsbeschneidung


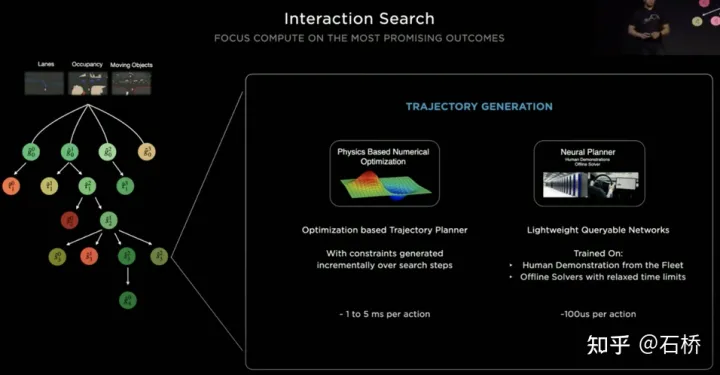
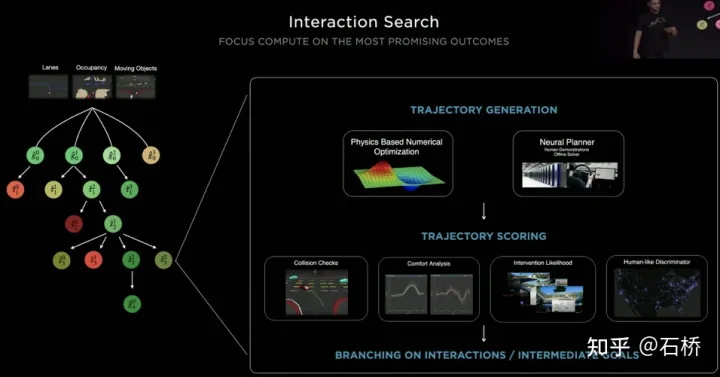


Phase 1 (2018): nur rein künstliches 2D. Die Effizienz der Bildbeschriftung ist sehr gering







Das obige ist der detaillierte Inhalt vonEine ausführliche Analyse der autonomen Fahrtechnologielösungen von Tesla. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Der Unterschied zwischen IPv4 und IPv6
Der Unterschied zwischen IPv4 und IPv6
 Fehlerberichtslösung für den MySQL-Import einer SQL-Datei
Fehlerberichtslösung für den MySQL-Import einer SQL-Datei
 Was bedeutet CX im Währungskreis?
Was bedeutet CX im Währungskreis?
 setInterval
setInterval
 Lösung für den Computer-Anzeigefehlercode 651
Lösung für den Computer-Anzeigefehlercode 651
 Kann ich ein gelöschtes Douyin-Kurzvideo wiederherstellen?
Kann ich ein gelöschtes Douyin-Kurzvideo wiederherstellen?
 Was soll ich tun, wenn die sekundäre Webseite nicht geöffnet werden kann?
Was soll ich tun, wenn die sekundäre Webseite nicht geöffnet werden kann?
 So öffnen Sie die Hosts-Datei
So öffnen Sie die Hosts-Datei

























