


Ich habe heute einen Artikel gesehen, in dem es heißt, dass Google ein Dokument durchgesickert hat: „Wir haben keinen Wassergraben, und OpenAI auch nicht.“ Es beschreibt die Ansichten eines bestimmten Google-Mitarbeiters (Nicht-Google-Unternehmen) zu Open-Source-KI. Die Ansicht ist sehr interessant , und die allgemeine Bedeutung ist:
Nachdem ChatGPT populär wurde, strömen alle großen Hersteller zu LLM und investieren wahnsinnig.
Google arbeitet ebenfalls hart und hofft auf ein Comeback, aber niemand kann dieses Wettrüsten gewinnen, weil Dritte stillschweigend diesen großen Kuchen essen.
Dieser Drittanbieter ist ein großes Open-Source-Modell.
Große Open-Source-Modelle haben dies bereits getan:
1. Führen Sie das Basismodell auf Pixel 6 mit einer Geschwindigkeit von 5 Token pro Sekunde aus.
2. Sie können die personalisierte KI in einer Nacht auf Ihrem PC optimieren:
Obwohl die Modelle von OpenAI und Google einen Qualitätsvorteil haben, schließt sich die Lücke besorgniserregend schnell:
Open-Source-Modelle sind schneller, anpassbarer, privater und leistungsfähiger.
Das Open-Source-Großmodell schafft Dinge mit 100-Dollar- und 13-Milliarden-Dollar-Parametern und schafft es in ein paar Wochen, während Google mit 10-Millionen-Dollar- und 540-Milliarden-Dollar-Parametern in ein paar Monaten zu kämpfen hat.
Wenn kostenlose, uneingeschränkte Alternativen so gut sind wie das geschlossene Modell, werden die Leute das geschlossene Modell definitiv aufgeben.
Alles begann, als Facebook Anfang März dieses wirklich leistungsfähige Grundmodell herausbrachte. Obwohl es keine Anleitung, Konversationsoptimierung oder RLHF gab, erkannte die Community sofort die Bedeutung dieser Sache.
Die folgende Neuerung ist einfach verrückt, selbst wenn man sie in Tagen misst:
2-24: Facebook startet LLaMA, das derzeit nur an Forschungseinrichtungen und Regierungsorganisationen zur Nutzung lizenziert ist
3-03: LLaMA ist durchgesickert Internet war zwar nicht kommerziell nutzbar, doch plötzlich konnte jeder spielen.
3-12: Das Ausführen von LLaMA auf Raspberry Pi ist sehr langsam und unpraktisch.
3-13: Stanford hat Alpaca veröffentlicht, das die Befehlsoptimierung für LLaMA hinzugefügt hat. Was noch „beängstigender“ ist, ist, dass Eric J. Wang von Stanford einen RTX verwendet Mit der 4090-Grafikkarte dauerte das Trainieren eines Alpaca-äquivalenten Modells nur 5 Stunden, wodurch der Rechenleistungsbedarf solcher Modelle auf Verbraucherniveau gesenkt wurde.
3-18: 5 Tage später nutzt Georgi Gerganov die 4-Bit-Quantisierungstechnologie, um LLaMA auf der MacBook-CPU auszuführen, was die erste „GPUless“-Lösung ist.
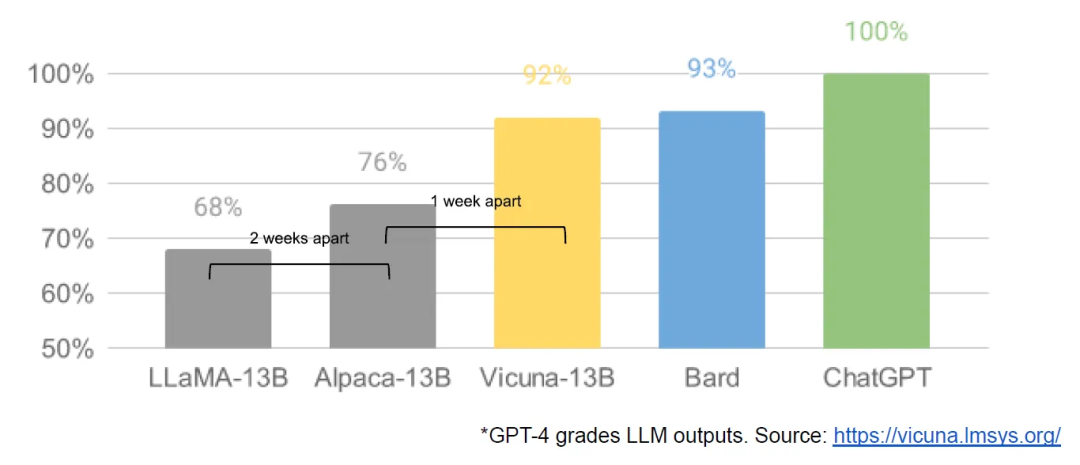
3-19: Nur einen Tag später starteten Forscher der University of California, Berkeley, CMU, der Stanford University und der University of California, San Diego gemeinsam Vicuna, das angeblich mehr als 90 % der Qualität erreicht hat OpenAI ChatGPT und Google Bard, und gleichzeitig übertrifft es in mehr als 90 % der Fälle andere Modelle wie LLaMA und Stanford Alpaca.
3-25: Nomic hat GPT4all erstellt, das sowohl ein Modell als auch ein Ökosystem ist, und zum ersten Mal sehen wir mehrere Modelle an einem Ort gesammelt
...
In nur einem Monat wurden Befehlsoptimierung, Quantisierung, Qualitätsverbesserungen, menschliche Evaluierungen, Multimodalität, RLHF usw. sind alle erschienen.
Noch wichtiger ist, dass die Open-Source-Community das Skalierbarkeitsproblem gelöst hat und die Schwelle für die Schulung von einem großen Unternehmen auf eine Person, eine Nacht und einen leistungsstarken Personalcomputer gesenkt wurde.
Also sagte der Autor am Ende: OpenAI hat auch Fehler gemacht wie wir und kann den Auswirkungen von Open Source nicht standhalten. Wir müssen ein Ökosystem aufbauen, damit Open Source für Google funktioniert.
Google hat dieses Paradigma bereits mit großem Erfolg auf Android und Chrome implementiert. Sie sollten sich als Marktführer im Bereich großer Open-Source-Modelle etablieren und Ihre Position als Vordenker und Führungspersönlichkeit weiter festigen.
Um ehrlich zu sein, war die Entwicklung großer Sprachmodelle im letzten Monat wirklich umwerfend und überwältigend und ich werde jeden Tag bombardiert.
Das erinnert mich an die frühen Jahre, als das Internet gerade erst begann, und morgen taucht eine andere auf. Und wenn das mobile Internet explodiert, ist heute eine App beliebt und morgen ist eine andere App beliebt ...
Ich persönlich möchte nicht, dass diese großen Sprachmodelle von Riesen kontrolliert werden. Wir können diese riesigen Modelle nur „parasitieren“, ihre APIs aufrufen und einige Anwendungen entwickeln, was sehr unangenehm ist. Es ist am besten, hundert Blumen blühen zu lassen und für die breite Masse zugänglich zu machen, damit jeder sein eigenes Privatmodell bauen kann.
Jetzt sollten die Schulungskosten für kleine Unternehmen erschwinglich sein. Wenn Programmierer die Möglichkeit haben, sich weiterzubilden, kann dies in Kombination mit bestimmten Branchen und Bereichen eine gute Gelegenheit sein.
Wenn Programmierer privatisierte Großmodelle kompetent beherrschen wollen, müssen sie zusätzlich zu den Prinzipien noch selbst üben. Es gibt auch Dutzende von Menschen auf unserem Planeten, die in Teams üben, obwohl die Open-Source-Community die Kosten erheblich gesenkt hat. Aber wenn Sie ein nützliches Modell trainieren möchten, stellt dieses Ding immer noch zu hohe Anforderungen an die Hardwareumgebung. Die RTX4090 kostet auf jeden Fall Zehntausende, was für die Miete einer GPU schmerzhaft ist Das Training in der Cloud ist noch unkontrollierbarer, das Geld wird verschwendet, es ist nicht so, als würde man eine Sprache oder ein Framework herunterladen und es kostet fast nichts.
Ich hoffe, dass die Schwelle noch weiter gesenkt wird!
Das obige ist der detaillierte Inhalt vonInterne Dokumente von Google sind durchgesickert: Open-Source-Großmodelle sind zu gruselig, selbst OpenAI kann es nicht ertragen!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



