


Spring-Kafka basiert auf der Integration der Java-Version von Kafka-Client und Spring. Es bietet KafkaTemplate, das den Kafka-Client von Apache kapselt und keine Client-Abhängigkeiten importiert YML-Konfiguration
<!-- kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>kafka:
#bootstrap-servers: server1:9092,server2:9093 #kafka开发地址,
#生产者配置
producer:
# Kafka提供的序列化和反序列化类
key-serializer: org.apache.kafka.common.serialization.StringSerializer #序列化
value-serializer: org.apache.kafka.common.serialization.StringSerializer
retries: 1 # 消息发送重试次数
#acks = 0:设置成 表示 producer 完全不理睬 leader broker 端的处理结果。此时producer 发送消息后立即开启下 条消息的发送,根本不等待 leader broker 端返回结果
#acks= all 或者-1 :表示当发送消息时, leader broker 不仅会将消息写入本地日志,同时还会等待所有其他副本都成功写入它们各自的本地日志后,才发送响应结果给,消息安全但是吞吐量会比较低。
#acks = 1:默认的参数值。 producer 发送消息后 leader broker 仅将该消息写入本地日志,然后便发送响应结果给producer ,而无须等待其他副本写入该消息。折中方案,只要leader一直活着消息就不会丢失,同时也保证了吞吐量
acks: 1 #应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
batch-size: 16384 #批量大小
properties:
linger:
ms: 0 #提交延迟
buffer-memory: 33554432 # 生产端缓冲区大小
# 消费者配置
consumer:
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 分组名称
group-id: web
enable-auto-commit: false
#提交offset延时(接收到消息后多久提交offset)
# auto-commit-interval: 1000ms
#当kafka中没有初始offset或offset超出范围时将自动重置offset
# earliest:重置为分区中最小的offset;
# latest:重置为分区中最新的offset(消费分区中新产生的数据);
# none:只要有一个分区不存在已提交的offset,就抛出异常;
auto-offset-reset: latest
properties:
#消费会话超时时间(超过这个时间consumer没有发送心跳,就会触发rebalance操作)
session.timeout.ms: 15000
#消费请求超时时间
request.timeout.ms: 18000
#批量消费每次最多消费多少条消息
#每次拉取一条,一条条消费,当然是具体业务状况设置
max-poll-records: 1
# 指定心跳包发送频率,即间隔多长时间发送一次心跳包,优化该值的设置可以减少Rebalance操作,默认时间为3秒;
heartbeat-interval: 6000
# 发出请求时传递给服务器的 ID。用于服务器端日志记录 正常使用后解开注释,不然只有一个节点会报错
#client-id: mqtt
listener:
#消费端监听的topic不存在时,项目启动会报错(关掉)
missing-topics-fatal: false
#设置消费类型 批量消费 batch,单条消费:single
type: single
#指定容器的线程数,提高并发量
#concurrency: 3
#手动提交偏移量 manual达到一定数据后批量提交
#ack-mode: manual
ack-mode: MANUAL_IMMEDIATE #手動確認消息
# 认证
#properties:
#security:
#protocol: SASL_PLAINTEXT
#sasl:
#mechanism: SCRAM-SHA-256
#jaas:config: 'org.apache.kafka.common.security.scram.ScramLoginModule required username="username" password="password";'Durch das Senden und Konsumieren an ein nicht vorhandenes Thema wird ein neues Thema erstellt. In vielen Fällen führt die unerwartete Themenerstellung zu vielen unerwarteten Problemen. Es wird empfohlen, diese Funktion zu deaktivieren. Thementhemen werden verwendet, um verschiedene Arten von Nachrichten zu unterscheiden. Standardmäßig werden Nachrichten für eine Woche gespeichert.
Unter demselben Thementhema ist die Standardeinstellung eine Partition bedeutet, dass es nur einen Verbraucher geben kann. Wenn Sie die Verbrauchskapazität verbessern möchten, müssen Sie Partitionen hinzufügen.
Für mehrere Partitionen desselben Themas gibt es drei Möglichkeiten, Nachrichten (Schlüssel, Wert) auf verschiedene Partitionen zu verteilen , designierte Partition, HASH-Routing, Standard, gleich Die Nachrichten-ID in der Partition ist eindeutig und sequentiell.
Wenn Verbraucher Nachrichten in der Partition konsumieren, verwenden sie den Offset, um den Speicherort der Nachricht zu identifizieren Das Problem des wiederholten Konsums unter demselben Thema, z. B. einem Konsumbedarf, kann durch Festlegen unterschiedlicher GroupIds erreicht werden.
Die eigentliche Nachricht wird in einer Kopie gespeichert und kann nur durch logisches Festlegen unterschieden werden Das System zeichnet es unter dem Topic-Thema „GroupId-Gruppierung“ unter der Partition auf, um festzustellen, ob es verbraucht wurde.
Hohe Verfügbarkeit beim Senden von Nachrichten –
Cluster-Modus, Mehrfachkopie-Implementierung; durch Setzen des Acks-Flags kann eine unterschiedliche Verfügbarkeit erreicht werden, wenn das Senden erfolgreich ist. Der Master antwortet erfolgreich. Nur OK, wenn =alle, mehr als die Hälfte der Antworten ist OK (echte Hochverfügbarkeit)
Hohe Verfügbarkeit konsumierender Nachrichten – Sie können den automatischen Identifikations-Offset-Modus deaktivieren, die Nachricht zuerst abrufen und dann festlegen Der Offset nach Abschluss des Verbrauchs wird verwendet, um die Hochverfügbarkeit des Verbrauchs zu lösen konsumieren
Sie können auch verschiedene Nachrichten mit derselben Methode anhören Thema, spezifizierte VerschiebungsüberwachungDie gleiche Gruppe wird gleichmäßig konsumieren, und verschiedene Gruppen werden wiederholt konsumieren.
1. Unicast-Modus, es gibt nur eine Verbrauchergruppe
(1) Das Thema hat nur eine Partition. Wenn es mehrere Verbraucher in der Gruppe gibt, kann die Nachricht in derselben Partition nur von einem aus der Gruppe gesendet werden. Verbraucherkonsum. Wenn die Anzahl der Verbraucher die Anzahl der Partitionen übersteigt, sind die überschüssigen Verbraucher im Leerlauf, wie in Abbildung 1 dargestellt. Thema und Test haben nur eine Partition und nur eine Gruppe, G1. Diese Gruppe enthält mehrere Verbraucher und kann nur von einem von ihnen genutzt werden, während die anderen inaktiv sind.
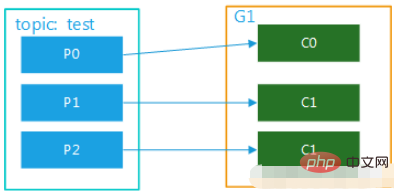
Abbildung 1 (2) Das Thema hat mehrere Partitionen und es gibt mehrere Verbraucher in der Gruppe. Wenn der Test beispielsweise 3 Partitionen hat und es 2 Verbraucher in der Gruppe gibt, entspricht dies möglicherweise C0 p0, die Daten in p1, c1 entsprechen dem Verbrauch der Daten von p2; wenn es drei Verbraucher gibt, entspricht ein Verbraucher dem Verbrauch der Daten in einer Partition. Die Diagramme sind in Abbildung 2 und Abbildung 3 dargestellt. Dieser Modus ist im Cluster-Modus sehr verbreitet. Beispielsweise können wir drei Dienste starten und drei Partitionen für das entsprechende Thema festlegen, sodass eine parallele Nutzung und eine effizientere Nachrichtenverarbeitung erreicht werden können kann die Effizienz erheblich verbessert werden.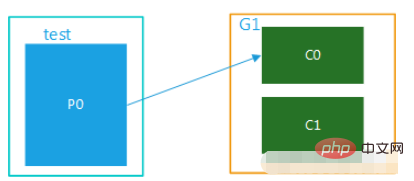 Bild 3
Bild 3
2. Broadcast-Modus, mehrere Verbrauchergruppen
Wenn Sie den Broadcast-Modus implementieren möchten, müssen Sie mehrere Verbrauchergruppen einrichten, sodass eine Verbrauchergruppe entsteht konsumiert Nach Abschluss dieser Nachricht hat dies überhaupt keine Auswirkungen auf den Konsum von Verbrauchern in anderen Gruppen. Dies ist das Konzept des Rundfunks.
(1) Mehrere Verbrauchergruppen, 1 Partition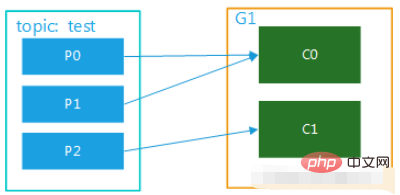
注意: 消费者的数量并不能决定一个topic的并行度。它是由分区的数目决定的。
再多的消费者,分区数少,也是浪费!
一个组的最大并行度将等于该主题的分区数。
@Component
@Slf4j
public class Consumer {
// 监听主题 分组a
@KafkaListener(topics =("${spring.kafka.topic}") ,groupId = "a")
public void getMessage(ConsumerRecord message, Acknowledgment ack) {
//确认收到消息
ack.acknowledge();
}
// 监听主题 分组a
@KafkaListener(topics = ("${spring.kafka.topic}"),groupId = "a")
public void getMessage2(ConsumerRecord message, Acknowledgment ack) {
//确认收到消息
ack.acknowledge();
}
// 监听主题 分组b
@KafkaListener(topics = ("${spring.kafka.topic}"),groupId = "b")
public void getMessage3(ConsumerRecord message, Acknowledgment ack) {
//确认收到消息//确认收到消息
ack.acknowledge();
}
// 监听主题 分组b
@KafkaListener(topics = ("${spring.kafka.topic}"),groupId = "b")
public void getMessage4(ConsumerRecord message, Acknowledgment ack) {
//确认收到消息//确认收到消息
ack.acknowledge();
}
// 指定监听分区1的消息
@KafkaListener(topicPartitions = {@TopicPartition(topic = ("${spring.kafka.topic}"),partitions = {"1"})})
public void getMessage5(ConsumerRecord message, Acknowledgment ack) {
Long id = JSONObject.parseObject(message.value().toString()).getLong("id");
//确认收到消息//确认收到消息
ack.acknowledge();
}
/**
* @Title 指定topic、partition、offset消费
* @Description 同时监听topic1和topic2,监听topic1的0号分区、topic2的 "0号和1号" 分区,指向1号分区的offset初始值为8
* 注意:topics和topicPartitions不能同时使用;
**/
@KafkaListener(id = "c1",groupId = "c",topicPartitions = {
@TopicPartition(topic = "t1", partitions = { "0" }),
@TopicPartition(topic = "t2", partitions = "0", partitionOffsets = @PartitionOffset(partition = "1", initialOffset = "8"))})
public void getMessage6(ConsumerRecord record,Acknowledgment ack) {
//确认收到消息
ack.acknowledge();
}
/**
* 批量消费监听goods变更消息
* yml配置listener:type 要改为batch
* ymk配置consumer:max-poll-records: ??(每次拉取多少条数据消费)
* concurrency = "2" 启动多少线程执行,应小于等于broker数量,避免资源浪费
*/
@KafkaListener(id="sync-modify-goods", topics = "${spring.kafka.topic}",concurrency = "4")
public void getMessage7(List<ConsumerRecord<String, String>> records){
for (ConsumerRecord<String, String> msg:records) {
GoodsChangeMsg changeMsg = null;
try {
changeMsg = JSONObject.parseObject(msg.value(), GoodsChangeMsg.class);
syncGoodsProcessor.handle(changeMsg);
}catch (Exception exception) {
log.error("解析失败{}", msg, exception);
}
}
}
}Das obige ist der detaillierte Inhalt vonWie SpringBoot die Kafka-Konfigurationstoolklasse integriert. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Schritte zur SpringBoot-Projekterstellung
Schritte zur SpringBoot-Projekterstellung
 Welche Rolle spielt die Kafka-Verbrauchergruppe?
Welche Rolle spielt die Kafka-Verbrauchergruppe?
 Welche Rolle spielt die Kafka-Verbrauchergruppe?
Welche Rolle spielt die Kafka-Verbrauchergruppe?
 Was ist der Unterschied zwischen RabbitMQ und Kafka?
Was ist der Unterschied zwischen RabbitMQ und Kafka?
 Was ist der Unterschied zwischen j2ee und springboot?
Was ist der Unterschied zwischen j2ee und springboot?
 Was tun, wenn Ihre IP-Adresse angegriffen wird?
Was tun, wenn Ihre IP-Adresse angegriffen wird?
 Im Gerätemanager gibt es keinen Netzwerkadapter
Im Gerätemanager gibt es keinen Netzwerkadapter
 Fakepath-Pfadlösung
Fakepath-Pfadlösung








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



