


Nach dem Eintritt in die Ära vor dem Training hat sich die Leistung visueller Erkennungsmodelle schnell entwickelt, aber Bilderzeugungsmodelle wie Generative Adversarial Networks (GAN) scheinen ins Hintertreffen zu geraten.
Normalerweise wird das GAN-Training von Grund auf unbeaufsichtigt durchgeführt, was zeitaufwändig und arbeitsintensiv ist. Das durch Big Data im groß angelegten Vortraining erlernte Wissen wird nicht genutzt Ist das nicht ein großer Verlust?
Darüber hinaus muss die Bilderzeugung selbst in der Lage sein, komplexe statistische Daten in realen visuellen Phänomenen zu erfassen und zu simulieren. Andernfalls entsprechen die erzeugten Bilder nicht den Gesetzen der physischen Welt und sind direkt auf den ersten Blick als „gefälscht“ identifiziert.

Das vorab trainierte Modell stellt Wissen bereit und das GAN-Modell bietet Generierungsfunktionen. Die Kombination der beiden ist wahrscheinlich eine schöne Sache!
Die Frage ist: Welche vorab trainierten Modelle und wie man sie kombiniert, kann die Generierungsfähigkeit des GAN-Modells verbessern?
Kürzlich haben Forscher von CMU und Adobe einen Artikel in CVPR 2022 veröffentlicht, in dem sie das Training vorab trainierter Modelle mit GAN-Modellen durch „Auswahl“ kombinieren.

Papierlink: https://arxiv.org/abs/2112.09130
Projektlink: https://github .com/nupurkmr9/vision-aided-gan
Videolink: https://www.youtube.com/watch?v=oHdyJNdQ9E4
Der Trainingsprozess des GAN Das Modell besteht aus einem Diskriminator und einem Generator, wobei der Diskriminator zum Erlernen der relevanten Statistiken verwendet wird, die reale Proben von generierten Proben unterscheiden. Das Ziel des Generators besteht darin, die generierten Bilder so konsistent wie möglich mit der realen Verteilung zu machen.
Idealerweise sollte der Diskriminator in der Lage sein, die Verteilungslücke zwischen dem generierten Bild und dem realen Bild zu messen.
Wenn die Datenmenge jedoch sehr begrenzt ist, kann die direkte Verwendung eines groß angelegten vorab trainierten Modells als Diskriminator leicht dazu führen, dass der Generator „gnadenlos zerquetscht“ und dann „überpasst“ wird. .
Durch Experimente mit dem FFHQ 1k-Datensatz wird der Diskriminator immer noch überangepasst sein, selbst wenn die neueste differenzierbare Datenverbesserungsmethode verwendet wird, und die Leistung des Trainingssatzes ist sehr stark, aber die Leistung ist schlecht Validierungssatz Sehr schlecht. Darüber hinaus kann sich der Diskriminator auf Verkleidungen konzentrieren, die für Menschen nicht erkennbar, für Maschinen jedoch offensichtlich sind.
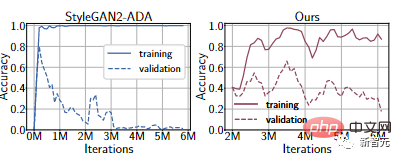
Diese Methode hat zwei Vorteile:
1. Trainieren Sie einen flachen Klassifikator für vorab trainierte Funktionen. Es handelt sich um eine gängige Methode um tiefe Netzwerke an kleine Datensätze anzupassen und gleichzeitig die Überanpassung zu reduzieren. 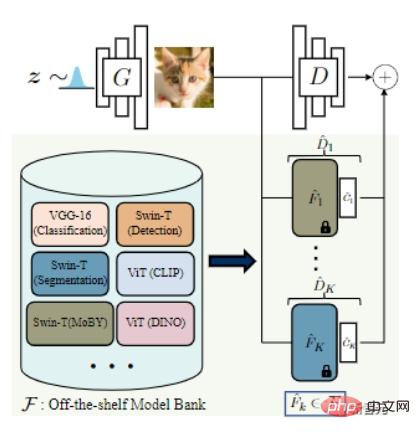
Anschließend wird eine automatische Modellsuchstrategie vorgeschlagen, die auf der linearen Segmentierung von echten und gefälschten Bildern im Merkmalsraum basiert und Etikettenglättung und differenzierbare Verbesserung verwendet. Technologie zur weiteren Stabilisierung des Modelltrainings und zur Reduzierung von Überanpassungen.
Konkret wird die Vereinigung realer Trainingsmuster und generierter Bilder in einen Trainingssatz und einen Validierungssatz unterteilt. 
Forscher Wir haben das GAN-Training empirisch anhand von 1000 Trainingsbeispielen aus den FFHQ- und LSUN-CAT-Datensätzen verifiziert.
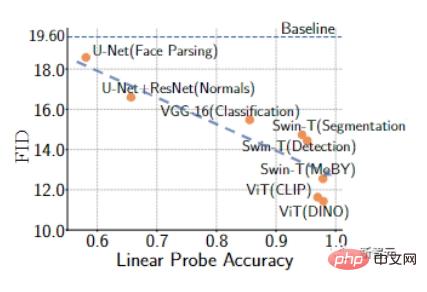
 Die Ergebnisse zeigen, dass mit vorab trainierten Modellen trainierte GANs eine höhere lineare Erkennungsgenauigkeit aufweisen und im Allgemeinen bessere FID-Indikatoren erzielen können.
Die Ergebnisse zeigen, dass mit vorab trainierten Modellen trainierte GANs eine höhere lineare Erkennungsgenauigkeit aufweisen und im Allgemeinen bessere FID-Indikatoren erzielen können.
Um das Feedback mehrerer Standardmodelle einzubeziehen, werden in dem Artikel auch zwei Modellauswahl- und Integrationsstrategien untersucht.
1) K-feste Modellauswahlstrategie, die die K besten Standardmodelle gleichzeitig auswählt Beginn des Trainings und Training bis zur Konvergenz;
2) K-progressive Modellauswahlstrategie, wählt iterativ das leistungsstärkste und ungenutzte Modell aus und fügt es nach einer festen Anzahl von Iterationen hinzu.
Experimentelle Ergebnisse zeigen, dass der progressive Ansatz im Vergleich zur K-fixed-Strategie eine geringere Rechenkomplexität aufweist und auch bei der Auswahl vorab trainierter Modelle hilfreich ist, um Unterschiede in der Datenverteilung zu erfassen. Beispielsweise handelt es sich bei den ersten beiden von der progressiven Strategie ausgewählten Modellen normalerweise um ein Paar selbstüberwachter und überwachter Modelle.
Die Experimente im Artikel sind überwiegend fortschrittlich.
Der endgültige Trainingsalgorithmus trainiert zunächst ein GAN mit einem standardmäßigen gegnerischen Verlust.

 Mit einem Basisliniengenerator kann das beste vorab trainierte Modell mithilfe linearer Sondierung und Einführung einer Verlustzielfunktion während des Trainings gesucht werden.
Mit einem Basisliniengenerator kann das beste vorab trainierte Modell mithilfe linearer Sondierung und Einführung einer Verlustzielfunktion während des Trainings gesucht werden.
Bei der K-progressiven Strategie wird nach dem Training für eine feste Anzahl von Iterationen proportional zur Anzahl der verfügbaren echten Trainingsbeispiele ein neuer visuell unterstützter Diskriminator zum Snapshot mit dem besten Trainingssatz-FID aus der vorherigen Stufe hinzugefügt.
Während des Trainings wird die Datenerweiterung durch horizontales Spiegeln durchgeführt, und differenzierbare Erweiterungstechniken und einseitige Etikettenglättung werden als Regularisierungsbegriffe verwendet.
Es ist auch zu beobachten, dass die Verwendung ausschließlich von Standardmodellen als Diskriminatoren zu Divergenz führt, während die Kombination von Originaldiskriminatoren und vorab trainierten Modellen diese Situation verbessern kann.
Das letzte Experiment zeigt die Ergebnisse, wenn die Trainingsbeispiele der Datensätze FFHQ, LSUN CAT und LSUN CHURCH zwischen 1.000 und 10.000 variieren.
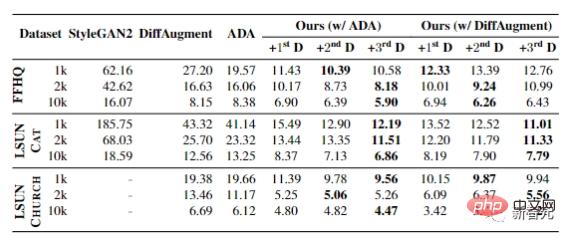
 In allen Situationen kann FID erhebliche Verbesserungen erzielen und die Wirksamkeit dieser Methode in Szenarien mit begrenzten Daten beweisen.
In allen Situationen kann FID erhebliche Verbesserungen erzielen und die Wirksamkeit dieser Methode in Szenarien mit begrenzten Daten beweisen.
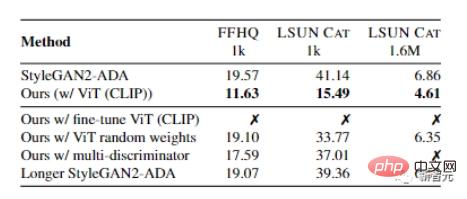
Um die Unterschiede zwischen dieser Methode und StyleGAN2-ADA qualitativ zu analysieren, kann die im Artikel vorgeschlagene neue Methode entsprechend der Qualität der mit den beiden Methoden generierten Proben die Qualität der schlechtesten Proben verbessern, insbesondere für FFHQ und LSUN CAT

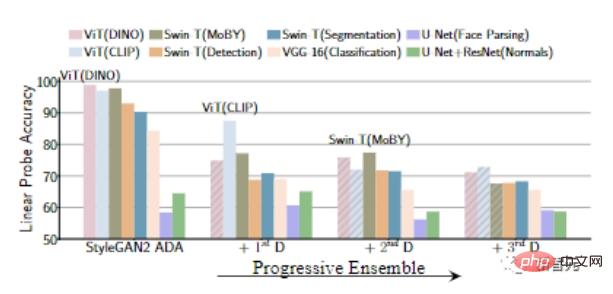
 Wenn wir nach und nach den nächsten Diskriminator hinzufügen, können wir sehen, dass die Genauigkeit der linearen Erkennung der Merkmale des vorab trainierten Modells allmählich abnimmt, was bedeutet, dass der Generator stärker ist.
Wenn wir nach und nach den nächsten Diskriminator hinzufügen, können wir sehen, dass die Genauigkeit der linearen Erkennung der Merkmale des vorab trainierten Modells allmählich abnimmt, was bedeutet, dass der Generator stärker ist.
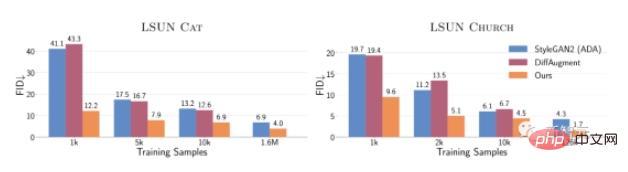
 Insgesamt ist der FID dieser Methode auf LSUN CAT mit nur 10.000 Trainingsbeispielen ungefähr der gleiche wie der von StyleGAN2, der auf 1,6 Millionen Bildern trainiert wurde.
Insgesamt ist der FID dieser Methode auf LSUN CAT mit nur 10.000 Trainingsbeispielen ungefähr der gleiche wie der von StyleGAN2, der auf 1,6 Millionen Bildern trainiert wurde.
 Im gesamten Datensatz verbessert diese Methode die FID in den LSUN-Kategorien Katze, Kirche und Pferd um das 1,5- bis 2-fache.
Im gesamten Datensatz verbessert diese Methode die FID in den LSUN-Kategorien Katze, Kirche und Pferd um das 1,5- bis 2-fache.

Der Autor Richard Zhang erhielt seinen Doktortitel von der University of California, Berkeley und seinen Bachelor- und Masterabschluss von der Cornell University. Zu den Hauptforschungsinteressen zählen Computer Vision, maschinelles Lernen, Deep Learning, Grafik und Bildverarbeitung, wobei er häufig im Rahmen von Praktika oder an der Universität mit akademischen Forschern zusammenarbeitet.

 Der Autor Jun-Yan Zhu ist Assistenzprofessor an der School of Computer Science der Carnegie Mellon University. Er ist auch in der Abteilung für Informatik und in der Abteilung für maschinelles Lernen tätig Zu den Bereichen gehören Computer Vision, Computergrafik, maschinelles Lernen und Computerfotografie.
Der Autor Jun-Yan Zhu ist Assistenzprofessor an der School of Computer Science der Carnegie Mellon University. Er ist auch in der Abteilung für Informatik und in der Abteilung für maschinelles Lernen tätig Zu den Bereichen gehören Computer Vision, Computergrafik, maschinelles Lernen und Computerfotografie.
Bevor er zur CMU kam, war er wissenschaftlicher Mitarbeiter bei Adobe Research. Er schloss sein Studium an der Tsinghua University mit einem Bachelor-Abschluss und einem Ph.D. an der University of California, Berkeley ab und arbeitete anschließend als Postdoktorand am MIT CSAIL.


Das obige ist der detaillierte Inhalt vonCMU schließt sich mit Adobe zusammen: GAN-Modelle läuten die Ära des Vortrainings ein und erfordern nur 1 % der Trainingsbeispiele. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Windows kann die Formatierung der Festplatte nicht abschließen
Windows kann die Formatierung der Festplatte nicht abschließen
 Rangliste der Kryptowährungsbörsen
Rangliste der Kryptowährungsbörsen
 So verwenden Sie die Print()-Funktion in Python
So verwenden Sie die Print()-Funktion in Python
 Software zur Verschlüsselung von Mobiltelefonen
Software zur Verschlüsselung von Mobiltelefonen
 Warum kann der Himalaya keine Verbindung zum Internet herstellen?
Warum kann der Himalaya keine Verbindung zum Internet herstellen?
 Wo kann man Bitcoin kaufen?
Wo kann man Bitcoin kaufen?
 Warum der Computer immer wieder automatisch neu startet
Warum der Computer immer wieder automatisch neu startet
 So lesen Sie den Wagenrücklauf in Java
So lesen Sie den Wagenrücklauf in Java








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



