


1 Einführung und Anwendung von Numpy Eine leistungsstarke N-dimensionale Array-Objekt-Ndarray-Broadcast-Funktion, die C/C++/Fortran-Code-Tools mit linearer Algebra, Fourier-Transformation, Zufallszahlengenerierung und anderen Funktionen integriert. 1-2 Warum Numpy wählen
Numpy berechnet direkt mit Arrays und Matrizen als Granularität und unterstützt eine große Anzahl mathematischer Funktionen, während Python dazu eine for-Schleife verwenden muss Implementieren Sie es von Grund auf.
Effizientere Leistung:
Numpys Array-Speichereffizienz sowie die Eingabe- und Ausgabeberechnungsleistung sind viel besser als bei Python, das Liste oder verschachtelte Listen verwendet.
Hinweis: Numpys Datenspeicherung unterscheidet sich von Pythons nativer Liste
Darüber hinaus sind die meisten Numpy-Codes in der C-Sprache implementiert, weshalb Numpy effizienter ist als reiner Python-CodeRelevantes Lernen und Code sind wie folgt: Numpy, Pandas und Matplotlib müssen im Voraus installiert werden
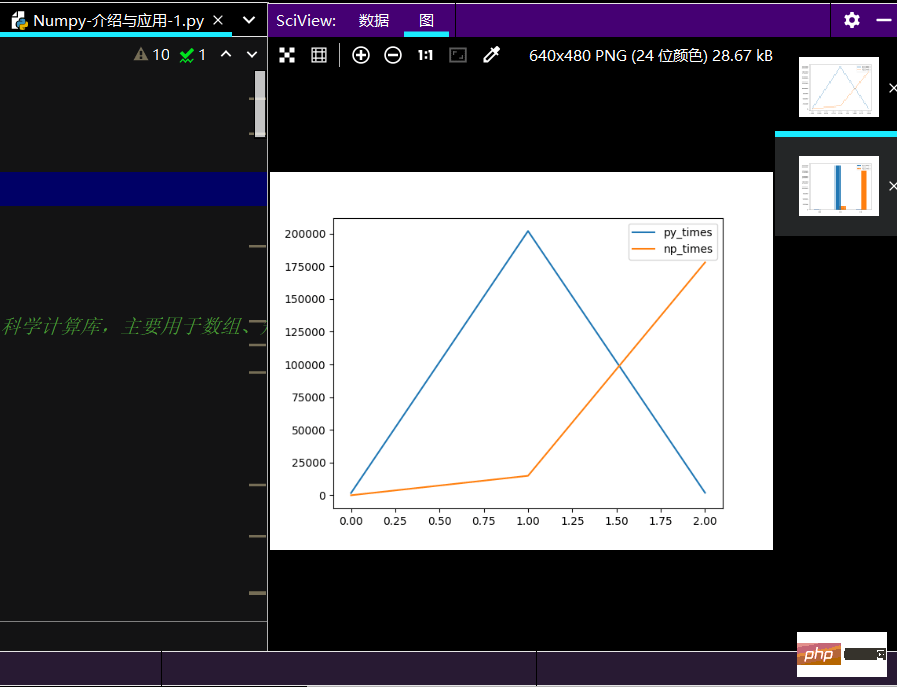
🔜 Der Laufeffekt des linearen Diagramms ist wie folgt :
Der laufende Effekt des Histogramms ist wie folgt:
2 NumPy Ndarray-Objekt
Das wichtigste Merkmal von NumPy ist sein N-dimensionales Array-Objekt ndarray, bei dem es sich um eine Sammlung handelt einer Reihe von Daten desselben Typs, tiefgestellt mit 0. Der Index, an dem das Element in der Sammlung beginnen soll.
ndarray-Objekt ist ein mehrdimensionales Array, das zum Speichern von Elementen desselben Typs verwendet wird. Jedes darin enthaltene Element hat den gleichen Speicherbereich im Speicher. Das ndarray-Objekt verwendet den Indexierungsmechanismus des Arrays, um jedes Element im Array einem Speicherblock zuzuordnen, und sortiert die Speicherblöcke nach einem bestimmten Layout (Zeilen oder Spalten).
ndarray besteht intern aus dem folgenden Inhalt:
 Ein Zeiger auf Daten (ein Datenelement im Speicher oder eine speicherzugeordnete Datei);
Ein Zeiger auf Daten (ein Datenelement im Speicher oder eine speicherzugeordnete Datei);
Datentyp oder dtype, der ein Raster von Werten fester Größe in einem Array beschreibt;
Ein Spannen-Tupel (Schritt), wobei sich die Ganzzahl auf die Anzahl der Bytes bezieht, die „überquert“ werden müssen, um zu gelangen das nächste Element der aktuellen Dimension.
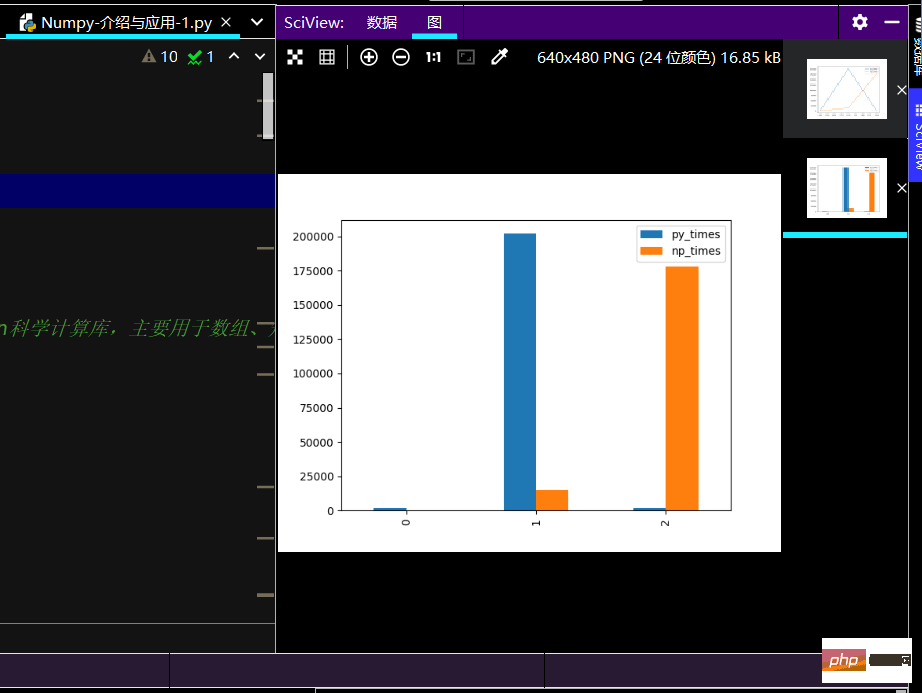
numpy unterstützt viel mehr Datentypen als Pythons integrierte Typen. Es kann grundsätzlich den Datentypen der C-Sprache entsprechen davon Der Typ entspricht dem integrierten Typ von Python3 Numpy-Datentyp# @Software : PyCharm # Numpy是Python各种数据科学类库的基础库 # 比如:Pandas,Scipy,Scikit_Learn等 # Numpy应用: ''' NumPy 通常与 SciPy(Scientific Python)和 Matplotlib(绘图库)一起使用, 这种组合广泛用于替代 MatLab,是一个强大的科学计算环境,有助于我们通过 Python 学习数据科学或者机器学习。 SciPy 是一个开源的 Python 算法库和数学工具包。 SciPy 包含的模块有最优化、线性代数、积分、插值、特殊函数、快速傅里叶变换、信号处理和图像处理、常微分方程求解和其他科学与工程中常用的计算。 Matplotlib 是 Python 编程语言及其数值数学扩展包 NumPy 的可视化操作界面。它为利用通用的图形用户界面工具包,如 Tkinter, wxPython, Qt 或 GTK+ 向应用程序嵌入式绘图提供了应用程序接口(API)。 ''' # 安装 NumPy 最简单的方法就是使用 pip 工具: # pip3 install --user numpy scipy matplotlib # --user 选项可以设置只安装在当前的用户下,而不是写入到系统目录。 # 默认情况使用国外线路,国外太慢,我们使用清华的镜像就可以: # pip install numpy scipy matplotlib -i.csv https://pypi.tuna.tsinghua.edu.cn/simple # 这种pip安装是一种最简单、最轻量级的方法,当然,这里的前提是有Python包管理器 # 如若不行,可以安装Anaconda【目前应用较广泛】,这是一个开源的Python发行版 # 安装Anaconda地址:https://www.anaconda.com/ # 安装验证 # 测试是否安装成功 from numpy import * # 导入 numpy 库 print(eye(4)) # 生成对角矩阵 # 查看版本: import numpy as np print(np.__version__) # 实现2个数组的加法: # 1-原生Python实现 def Py_sum(n): a = [i**2 for i in range(n)] b = [i**3 for i in range(n)] # 创建一个空列表,便于后续存储 ab_sum = [] for i in range(n): # 将a、b中对应的元素相加 ab_sum.append(a[i]+b[i]) return ab_sum # 调用实现函数 print(Py_sum(10)) # 2-Numpy实现: def np_sum(n): c = np.arange(n) ** 2 d = np.arange(n) ** 3 return c+d print(np_sum(10)) # 易看出使用Numpy代码简洁且运行效率快 # 测试1000,10W,以及100W的运行时间 # 做绘图对比: import pandas as pd # 输入数据 py_times = [1.72*1000, 202*1000, 1.92*1000] np_times = [18.8, 14.9*1000, 17.8*10000] # 创建Pandas的DataFrame类型数据 ch_lxw = pd.DataFrame({ 'py_times': py_times, 'np_times': np_times # 可加逗号 }) print(ch_lxw)Nach dem Login kopieren
Häufig verwendete NumPy-Grundtypen:
intp:【Integer-Typ, der für die Indizierung verwendet wird (ähnlich wie ssize_t von C, im Allgemeinen immer noch int32 oder int64)]
int8: [Byte (-128 bis 127)]int64: [Ganzzahl (-92233720368547). 75808 bis 9223372036854775807 )]
uint8: [Ganzzahl ohne Vorzeichen (0 bis 255)]uint64: [Ganzzahl ohne Vorzeichen (0 bis 1844674407370955161 5) ]float_ float64: [Abkürzung des Typs]float16: [Gleitkommazahl mit halber Genauigkeit, einschließlich: 1 Vorzeichenbit, 5 Exponentenbits, 10 Mantissenbits]
float32: [Gleitkommazahl mit einfacher Genauigkeit, einschließlich: 1 Vorzeichen Bit, 8 Exponentenbits, 23 Mantissenbits]complex64: [Komplexe Zahl, die eine doppelte 32-Bit-Gleitkommazahl (Realteil und Imaginärteil) darstellt]complex128: [Komplexe Zahl, die eine doppelte 64-Bit-Gleitkommazahl (Realteil und Imaginärteil) darstellt Teil)]
Verwandtes Lernen und Code sind wie folgt:
''' # numpy 的数值类型实际上是 dtype 对象的实例,并对应唯一的字符,包括 np.bool_,np.int32,np.float32,等等。 ''' # Numpy 类型对象: ''' dtype 对象是使用以下语法构造的: numpy.dtype(object, align, copy) object - 要转换为的数据类型对象 align - 如果为 true,填充字段使其类似 C 的结构体。 copy - 复制 dtype 对象 ,如果为 false,则是对内置数据类型对象的引用 ''' # 1: 使用标量类型 import numpy as np lxw = np.dtype(np.int32) print(lxw) print() # 2: int8, int16, int32, int64 四种数据类型可以使用字符串 'i1', 'i2','i4','i8' 代替 import numpy as np lxw2 = np.dtype('i8') # int64 print(lxw2) print() # 3: 字节顺序标注 import numpy as np lxw3 = np.dtype('<i4') # int32 print(lxw3) print() # 4: 首先创建结构化数据类型 import numpy as np lxw4 = np.dtype([('age', np.int8)]) # i1 print(lxw4) print() # 5: 将数据类型应用于 ndarray 对象 import numpy as np lxw5 = np.dtype([('age', np.int32)]) a = np.array([(10,), (20,), (30,)], dtype=lxw5) print(a) print() # 6: 类型字段名可以用于存取实际的 age 列 import numpy as np lxw6 = np.dtype([('age', np.int64)]) a = np.array([(10,), (20,), (30,)], dtype=lxw6) print(a['age']) print() # 7: 定义一个结构化数据类型 student,包含字符串字段 name,整数字段 age,及浮点字段 marks,并将这个 dtype 应用到 ndarray 对象 import numpy as np student = np.dtype([('name', 'S20'), ('age', 'i2'), ('marks', 'f4')]) print(student) # 运行结果:[('name', 'S20'), ('age', '<i2'), ('marks', '<f4')] print() # 8: import numpy as np student2 = np.dtype([('name','S20'), ('age', 'i1'), ('marks', 'f4')]) lxw = np.array([('lxw', 21, 52), ('cw', 22, 58)], dtype=student2) print(lxw) # 运行结果:[(b'lxw', 21, 52.) (b'cw', 22, 58.)] # 每个内建类型都有一个唯一定义它的字符代码,如下: ''' 字符 对应类型 b 布尔型 i.csv (有符号) 整型 u 无符号整型 integer f 浮点型 c 复数浮点型 m timedelta(时间间隔) M datetime(日期时间) O (Python) 对象 S, a (byte-)字符串 U Unicode V 原始数据 (void) '''
在 NumPy中,每一个线性的数组称为是一个轴(axis),也就是维度(dimensions)。
比如说,二维数组相当于是两个一维数组,其中第一个一维数组中每个元素又是一个一维数组。
相关代码学习、如下:
# NumPy 的数组中比较重要 ndarray 对象属性有:
'''
属性 说明
ndarray.ndim 秩,即轴的数量或维度的数量
ndarray.shape 数组的维度,对于矩阵,n 行 m 列
ndarray.size 数组元素的总个数,相当于 .shape 中 n*m 的值
ndarray.dtype ndarray 对象的元素类型
ndarray.itemsize ndarray 对象中每个元素的大小,以字节为单位
ndarray.flags ndarray 对象的内存信息
ndarray.real ndarray元素的实部
ndarray.imag ndarray 元素的虚部
ndarray.data 包含实际数组元素的缓冲区,由于一般通过数组的索引获取元素,所以通常不需要使用这个属性。
'''
# ndarray.ndim
# ndarray.ndim 用于返回数组的维数,等于秩。
import numpy as np
lxw = np.arange(36)
print(lxw.ndim) # a 现只有一个维度
# 现调整其大小
a = lxw.reshape(2, 6, 3) # 现在拥有三个维度
print(a.ndim)
print()
# ndarray.shape
# ndarray.shape 表示数组的维度,返回一个元组,这个元组的长度就是维度的数目,即 ndim 属性(秩)。比如,一个二维数组,其维度表示"行数"和"列数"。
# ndarray.shape 也可以用于调整数组大小。
import numpy as np
lxw2 = np.array([[169, 175, 165], [52, 55, 50]])
print(lxw2.shape) # shape: 数组的维度
print()
# 调整数组大小:
import numpy as np
lxw3 = np.array([[123, 234, 345], [456, 567, 789]])
lxw3.shape = (3, 2)
print(lxw3)
print()
# NumPy 也提供了 reshape 函数来调整数组大小:
import numpy as np
lxw4 = np.array([[23, 543, 65], [32, 54, 76]])
c = lxw4.reshape(2, 3) # reshape: 调整数组大小
print(c)
print()
# ndarray.itemsize
# ndarray.itemsize 以字节的形式返回数组中每一个元素的大小。
# 例如,一个元素类型为 float64 的数组 itemsize 属性值为 8(float64 占用 64 个 bits,
# 每个字节长度为 8,所以 64/8,占用 8 个字节),又如,一个元素类型为 complex32 的数组 item 属性为 4(32/8)
import numpy as np
# 数组的 dtype 为 int8(一个字节)
x = np.array([1, 2, 3, 4, 5], dtype=np.int8)
print(x.itemsize)
# 数组的dtypy现在为float64(八个字节)
y = np.array([1, 2, 3, 4, 5], dtype=np.float64)
print(y.itemsize) # itemsize: 占用字节个数
# 拓展:
# 整体转化为整数型
print(np.array([3.5, 6.6, 8.9], dtype=int))
# 设置copy参数,默认为True
a = np.array([2, 5, 6, 8, 9])
b = np.array(a) # 复制a
print(b) # 控制台打印b
print(f'a: {id(a)}, b: {id(b)}') # 可打印出a和b的内存地址
print('='*20)
# 类似于列表的引用赋值
b = a
print(f'a: {id(a)}, b: {id(b)}')
# 创建一个矩阵
lxw5 = np.mat([1, 2, 3, 4, 5])
print(type(lxw5)) # 矩阵类型: <class 'numpy.matrix'>
# 复制出副本,并保持原类型
yy = np.array(lxw5, subok=True)
print(type(yy))
# 只复制副本,不管其类型
by = np.array(lxw5, subok=False) # False: 使用数组的数据类型
print(type(by))
print(id(yy), id(by))
print('='*20)
# 使用数组的copy()方法:
c = np.array([2, 5, 6, 2])
cp = c.copy()
print(id(c), id(cp))
print()
# ndarray.flags
'''
ndarray.flags 返回 ndarray 对象的内存信息,包含以下属性:
属性 描述
C_CONTIGUOUS (C) 数据是在一个单一的C风格的连续段中
F_CONTIGUOUS (F) 数据是在一个单一的Fortran风格的连续段中
OWNDATA (O) 数组拥有它所使用的内存或从另一个对象中借用它
WRITEABLE (W) 数据区域可以被写入,将该值设置为 False,则数据为只读
ALIGNED (A) 数据和所有元素都适当地对齐到硬件上
UPDATEIFCOPY (U) 这个数组是其它数组的一个副本,当这个数组被释放时,原数组的内容将被更新
'''
import numpy as np
lxw4 = np.array([1, 3, 5, 6, 7])
print(lxw4.flags) # flags: 其内存信息当然,做这些的前提是首先把文件准备好
文件准备:
文件太长,故只截取了部分,当然,此文件可自行弄类似的也可以!
在进行数据分析时,经常需要按照一定条件创造新的数据列,然后再进一步分析
直接赋值
df.apply()方法
df.assign()方法
按条件进行分组分别赋值
# 1:
import pandas as pd
# 读取数据
lxw = pd.read_csv('sites.csv')
# print(lxw.head())
df = pd.DataFrame(lxw)
# print(df)
df['lrl'] = df['lrl'].map(lambda x: x.rstrip('%'))
# print(df)
df.loc[:, 'jf'] = df['yye'] - df['sku_cost_prc']
# 返回的是Series
# print(df.head())
# 2:
def get_cha(n):
if n['yye'] > 5:
return '高价'
elif n['yye'] < 2:
return '低价'
else:
return '正常价'
df.loc[:, 'yye_type'] = df.apply(get_cha, axis=1)
# print(df.head())
print(df['yye_type'].value_counts())
# 3:
# 可同时添加多个新列
print(df.assign(
yye_bh=lambda x: x['yye']*2-3,
sl_zj=lambda x: x['sku_cnt']*6
).head(10))
# 4:
# 按条件先选择数据,然后对这部分数据赋值新列
# 先创建空列
df['zyye_type'] = ''
df.loc[df['yye'] - df['sku_cnt']>8, 'zyye_type'] = '高'
df.loc[df['yye'] - df['sku_cnt'] <= 8, 'zyye_type'] = '低'
print(df.head())下面分别是每个小问对应运行效果:
1:
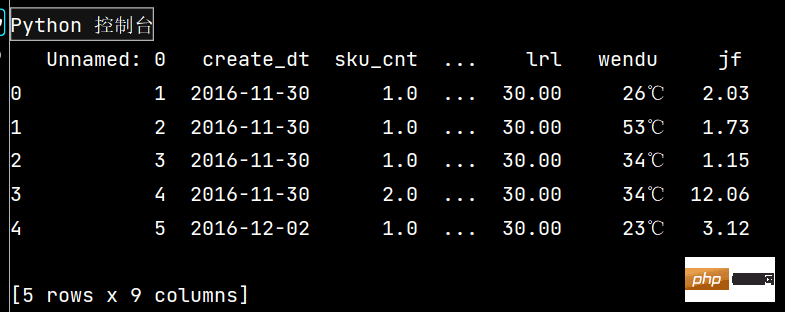
2:
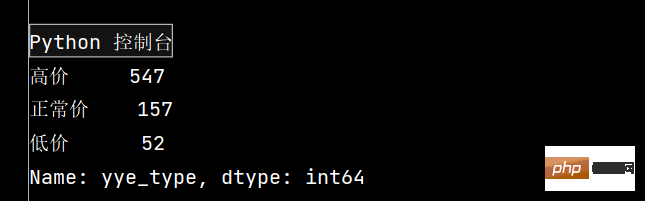
3:
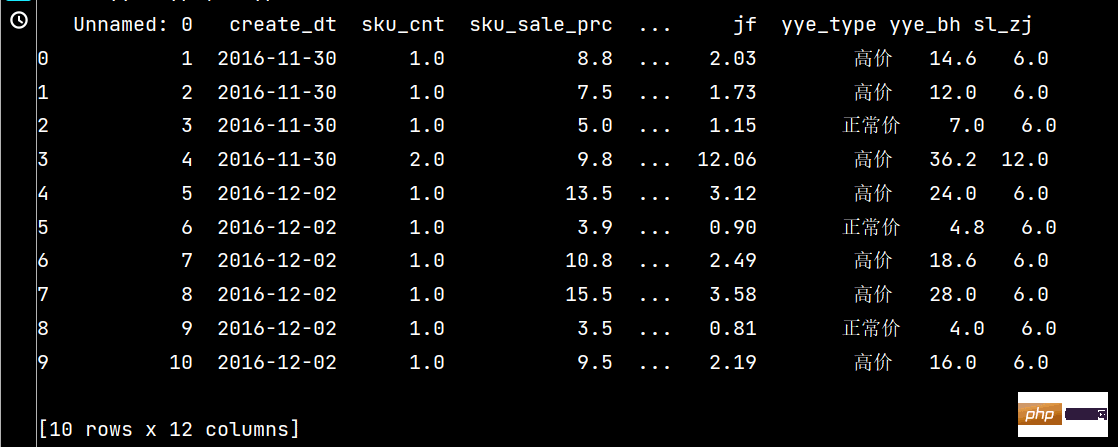
4:
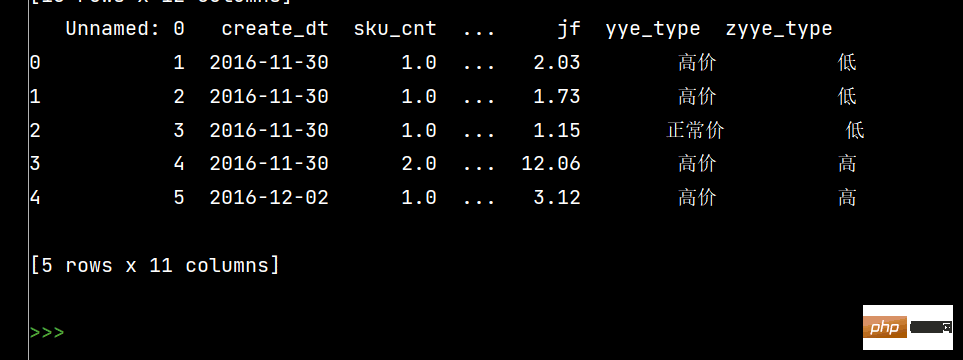
# Pandas数据统计函数
'''
1-汇总类统计
2-唯一去重和按值计数
3-相关系数和协方差
'''
import pandas as pd
lxw = pd.read_csv('nba.csv')
# print(lxw.head(3))
# 1:
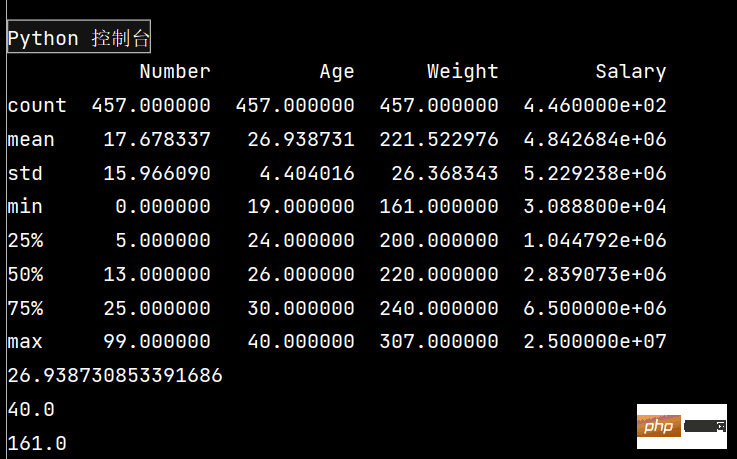
# 一下子提取所有数字列统计结果
print(lxw.describe())
# 查看单个Series的数据
print(lxw['Age'].mean())
# 年龄最大
print(lxw['Age'].max())
# 体重最轻
print(lxw['Weight'].min())
# 2:
# 2-1 唯一性去重【一般不用于数值项,而是枚举、分类项】
print(lxw['Height'].unique())
print(lxw['Team'].unique())
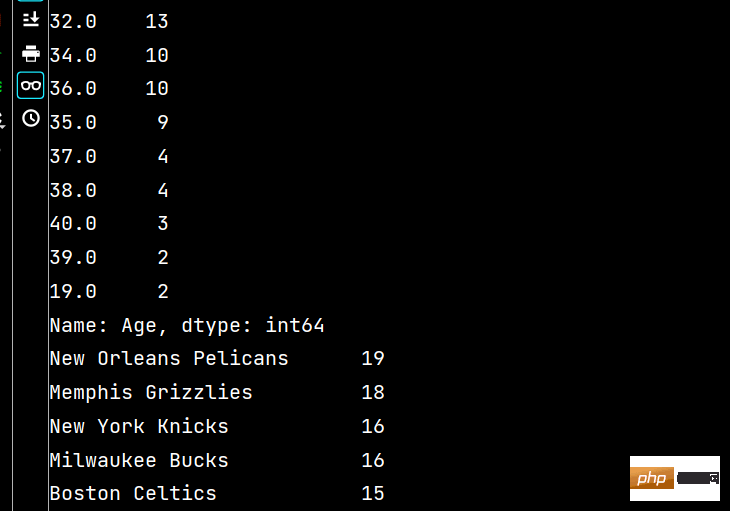
# 2-2 按值计算
print(lxw['Age'].value_counts())
print(lxw['Team'].value_counts())
# 3:
# 应用:股票涨跌、产品销量波动等等
'''
对于两个变量X、Y:
1-协方差:衡量同向程度程度,如果协方差为正,说明X、Y同向变化,协方差越大说明同向程度越高;
如果协方差为负,说明X、Y反向运动,协方差越小说明方向程度越高。
2-相关系数:衡量相似度程度,当他们的相关系数为1时,说明两个变量变化时的正向相似度最大,
当相关系数为-1,说明两个变化时的反向相似度最大。
'''
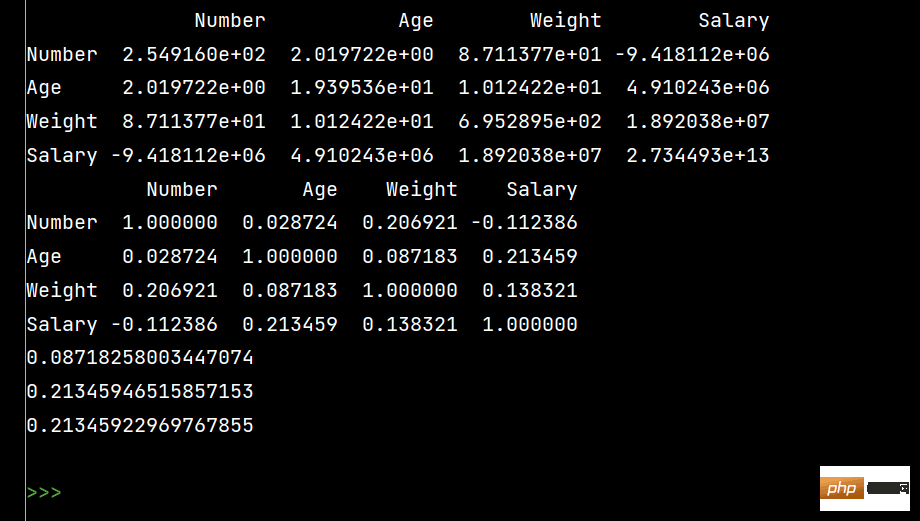
# 协方差矩阵:
print(lxw.cov())
# 相关系数矩阵:
print(lxw.corr())
# 单独查看年龄和体重的相关系数
print(lxw['Age'].corr(lxw['Weight']))
# Age和Salary的相关系数
print(lxw['Age'].corr(lxw['Salary']))
# 注意看括号内的相减
print(lxw['Age'].corr(lxw['Salary']-lxw['Weight']))1:
2-1:

部分2-2:
3:
特殊Excel的读取、清洗、处理:
# Pandas对缺失值的处理
'''
函数用法:
1-isnull和notnull: 检测是否有控制,可用于dataframe和series
2-dropna: 丢弃、删除缺失值
2-1 axis: 删除行还是列,{0 or 'index', 1 or 'columns'}, default()
2-2 how: 如果等于any, 则任何值都为空,都删除;如果等于all所有值都为空,才删除
2-3 inplace: 如果为True,则修改当前dataframe,否则返回新的dataframe
2-4 value: 用于填充的值,可以是单个值,或者字典(key是列名,value是值)
2-5 method: 等于ffill使用前一个不为空的值填充forword fill;等于bfill使用后一个不为空的值填充backword fill
2-6 axis: 按行还是按列填充,{0 or "index", 1 or "columns"}
2-7 inplace: 如果为True则修改当前dataframe,否则返回新的dataframe
'''
# 特殊Excel的读取、清洗、处理
import pandas as pd
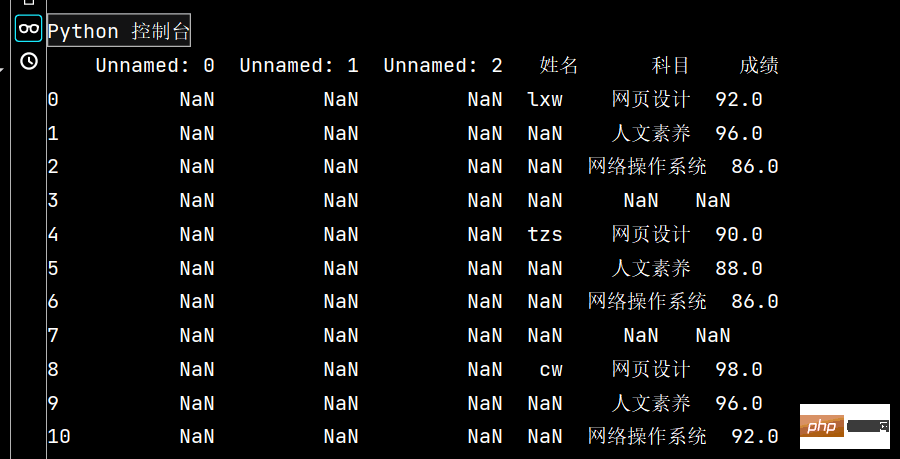
# 1: 读取excel时,忽略前几个空行
stu = pd.read_excel("Score表.xlsx", skiprows=14) # skiprows: 控制在几行以下
print(stu)
# 2: 检测空值
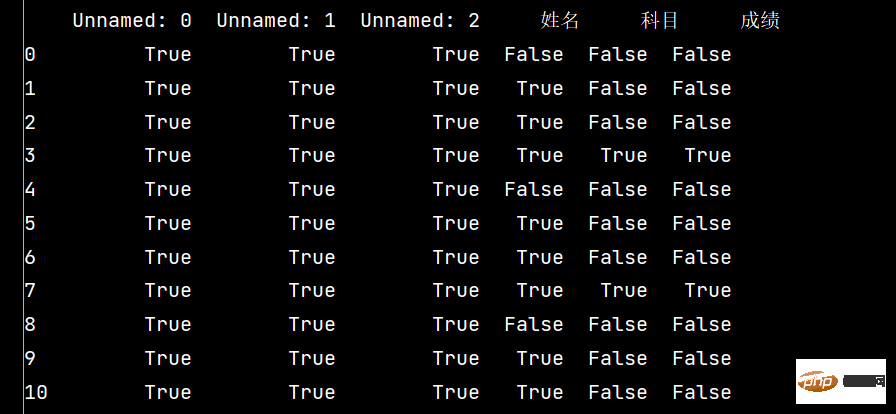
print(stu.isnull())
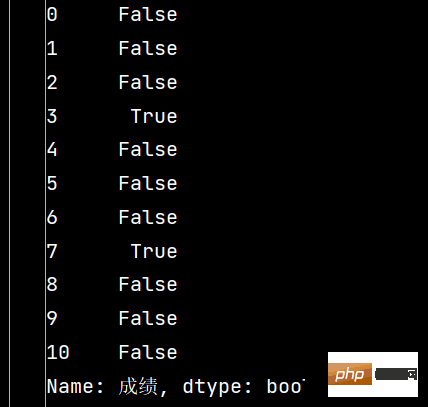
print(stu['成绩'].isnull())
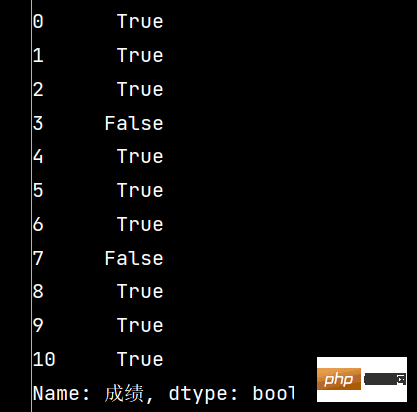
print(stu['成绩'].notnull())
# 筛选没有空成绩的所有行
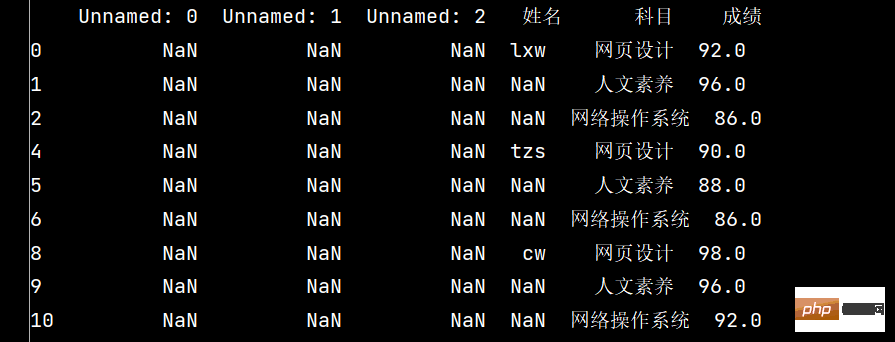
print(stu.loc[stu['成绩'].notnull(), :])
# 3: 删除全是空值的列:
# axis: 删除行还是列,{0 or 'index', 1 or 'columns'}, default()
# how: 如果等于any, 则任何值都为空,都删除;如果等于all所有值都为空,才删除
# inplace: 如果为True则修改当前dataframe,否则返回新的dataframe
stu.dropna(axis="columns", how="all", inplace=True)
print(stu)
# 4: 删除全是空值的行:
stu.dropna(axis="index", how="all", inplace=True)
print(stu)
# 5: 将成绩列为空的填充为0分:
stu.fillna({"成绩": 0})
print(stu)
# 同上:
stu.loc[:, '成绩'] = stu['成绩'].fillna(0)
print(stu)
# 6: 将姓名的缺失值填充【使用前面的有效值填充,用ffill: forward fill】
stu.loc[:, '姓名'] = stu['姓名'].fillna(method='ffill')
print(stu)
# 7: 将清洗好的Excel保存:
stu.to_excel("Score成绩_clean.xlsx", index=False)1:
2
3:
4:
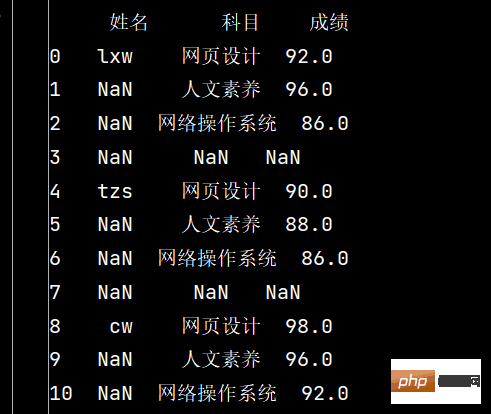
5:
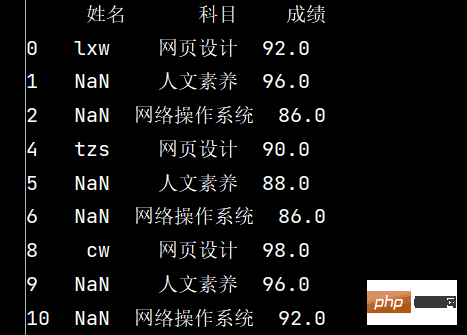
6:
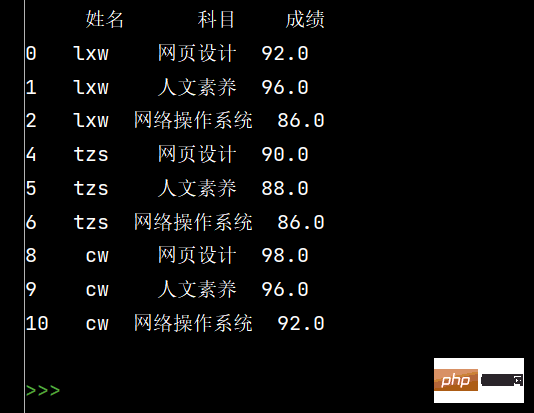
Das obige ist der detaillierte Inhalt vonWie verwende ich die Python-Bibliotheken Numpy und Pandas?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



