


json wird für den Datenaustausch zwischen verschiedenen Sprachen verwendet, z. B. zwischen C und Python usw., der sprachübergreifend sein kann. Pickle kann nur für den Datenaustausch zwischen Python und Python verwendet werden.
Wir nennen den Prozess von Objekten (Variablen) aus dem Speicher in speicherbare oder übertragbare Objekte, die in Python als Beizen bezeichnet werden, und werden in anderen Sprachen auch als Serialisierung bezeichnet die gleiche Bedeutung. Nach der Serialisierung kann der serialisierte Inhalt auf die Festplatte geschrieben oder über das Netzwerk an andere Maschinen übertragen werden. Das erneute Einlesen des Variableninhalts aus dem serialisierten Objekt in den Speicher wird wiederum Deserialisierung genannt, also Unpickling.
Wenn wir Objekte zwischen verschiedenen Programmiersprachen übertragen möchten, müssen wir das Objekt in ein Standardformat wie XML serialisieren. Eine bessere Möglichkeit besteht jedoch darin, es in JSON zu serialisieren, da JSON als Zeichenfolge dargestellt wird und alle Sprachen sein kann werden gelesen und können problemlos auf der Festplatte gespeichert oder über das Netzwerk übertragen werden. JSON ist nicht nur ein Standardformat und schneller als XML, sondern kann auch direkt in Webseiten gelesen werden, was sehr praktisch ist.
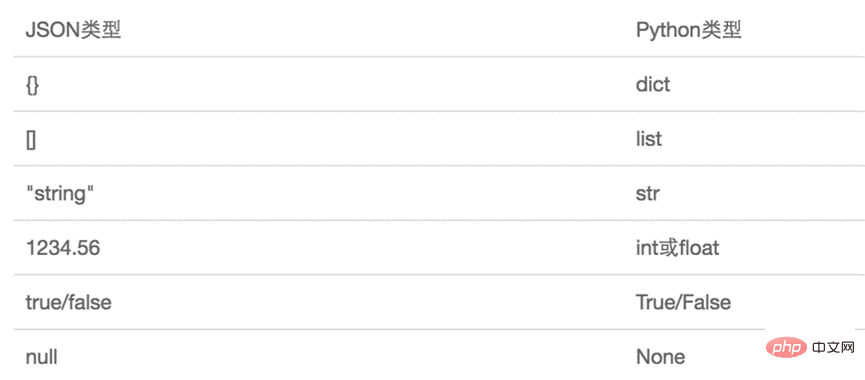
Das durch JSON dargestellte Objekt ist ein Standard-JavaScript-Sprachobjekt. Die Entsprechung zwischen JSON und den integrierten Datentypen von Python ist wie folgt:
Daten in die Datei schreiben und lesen – Wörterbuch
dic =' {‘string1':'hello'}' #写文件只能写入字符串 - 手动把字典变成字符串
f = open(‘hello', ‘w')
f.write(dic)f_read = open(‘hello', ‘r') data = f_read.read() #从文件中读出的都是字符串 data = eval(data) #提取出字符串中的字典 print(data[‘name'])
json implementiert das oben Gesagte Funktionen – JSON kann in verwendet werden. Es gibt einen Unterschied zwischen der Übertragung von Daten in einer beliebigen JSON-Zeichenfolge und der Zeichenfolge, die wir manuell hinzufügen. Es folgt der JSON-Zeichenfolgenspezifikation, d doppelte Anführungszeichen.
dumps wandelt jeden Datentyp, den wir übergeben, in eine Zeichenfolge um, die in doppelte Anführungszeichen gesetzt ist
dic = {‘string1':'hello'}
data = json.dumps(dic)
print(data)
print(type(data)) #dumps()会把我们的变量变成一个json字符串
f = open(“new_hello”, “w”)
f.write(data)Wir konvertieren die Daten beim Speichern oder Übertragen in eine JSON-Zeichenfolge, die in jeder Sprache implementiert werden kann
Wir packen eine Liste l = [1, 2, 3] in einen JSON-String in Python und speichern oder versenden ihn. Wenn wir JSON-Parsing in der C-Sprache verwenden, erhalten wir den entsprechenden Wert in der C-Sprache. Die Datenstruktur wird extrahiert als Array buf[3] = {1, 2, 3}. Dies bedeutet nicht, dass Dumps und Loads zusammen verwendet werden müssen, solange der JSON-String der JSON-Spezifikation entspricht, können Loads zum Verarbeiten und Extrahieren der Datenstruktur verwendet werden. Es spielt keine Rolle, ob Dumps verwendet werden oder nicht.# {‘string1':'hello'} ---> “{“string1”:”hello”}”
# 8 ---> “8”
# ‘hello' ---> ““hello”” – 被json包装后的数据内部只能有双引号
#[1, 2] ---> “[1, 2]”f_read = open(“new_hello”, “r”) data = json.loads(f_read.read()) #这个data直接就是字典类型 print(data) print(type(data))
json.dumps() # 把数据包装成json字符串 – 序列化 json.loads() # 从json字符串中提取出原来的数据 – 反序列化
json.dump(data, f) #转换成json字符串并写入文件 #相当于 data = json.dumps(dic) + f.write(data) data = json.load(f) #先读取文件,再提取出数据 #相当于data = json.loads(f_read.read())
#----------------------------序列化
import json
dic={'name':'alvin','age':23,'sex':'male'}
print(type(dic))#<class 'dict'>
j=json.dumps(dic)
print(type(j))#<class 'str'>
f=open('序列化对象','w')
f.write(j) #-------------------等价于json.dump(dic,f)
f.close()#-----------------------------反序列化<br> import json f=open('序列化对象') data=json.loads(f.read())# 等价于data=json.load(f)
Das obige ist der detaillierte Inhalt vonSo verwenden Sie das JSON-Modul und das Pickle-Modul von Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



