



Bevor wir die automatische Parallelität einführen, überlegen wir uns, warum automatische Parallelität erforderlich ist. Einerseits gibt es unterschiedliche Modellstrukturen und andererseits verschiedene parallele Strategien. Zwischen beiden besteht im Allgemeinen eine Viele-zu-Viele-Zuordnungsbeziehung. Unter der Annahme, dass wir eine einheitliche Modellstruktur implementieren können, um verschiedene Aufgabenanforderungen zu erfüllen, wird unsere Parallelstrategie dann eine Konvergenz auf dieser einheitlichen Modellstruktur erreichen?
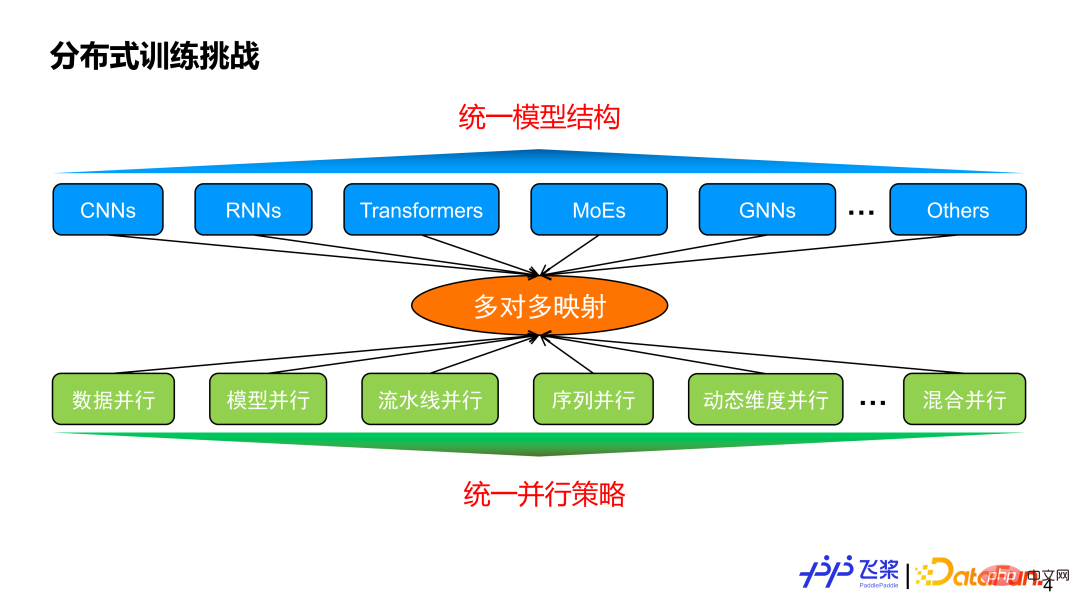
Die Antwort lautet Nein, da die Parallelstrategie nicht nur mit der Modellstruktur zusammenhängt, sondern auch eng mit dem Maßstab des Modells und den tatsächlich verwendeten Maschinenressourcen zusammenhängt. Dies spiegelt den Wert der automatischen Parallelität wider. Ihr Ziel besteht darin, dem Benutzer ein Modell und die verwendeten Maschinenressourcen zur Verfügung zu stellen und ihn automatisch bei der Auswahl einer besseren oder optimalen Parallelstrategie für eine effiziente Ausführung zu unterstützen.
Hier ist eine Liste einiger Jobs, die mich interessieren. Sie ist möglicherweise nicht vollständig. Ich würde gerne den aktuellen Status und die Geschichte der automatischen Parallelität mit Ihnen besprechen. Es ist grob in mehrere Dimensionen unterteilt: Die erste Dimension ist der Grad der automatischen Parallelität, der in vollautomatische und halbautomatische unterteilt ist; die zweite Dimension ist die parallele Granularität, die parallele Strategien für jede Ebene oder für jeden Operator bereitstellt Tensoren zur Bereitstellung paralleler Strategien; die dritte ist die Darstellungsfähigkeit, die in zwei Kategorien vereinfacht wird: SPMD-Parallelität (Single Program Multiple Data) und Pipeline-Parallelität; die vierte ist die Charakteristik; hier ist eine Liste verwandter Arbeiten, die ich persönlich für markanter halte An fünfter Stelle steht die unterstützende Hardware, wobei hauptsächlich die Art und Menge der von der entsprechenden Arbeit unterstützten Hardware geschrieben wird. Darunter sind die rot markierten Teile hauptsächlich aufschlussreiche Punkte für die automatische parallele Entwicklung von Flugpaddeln.
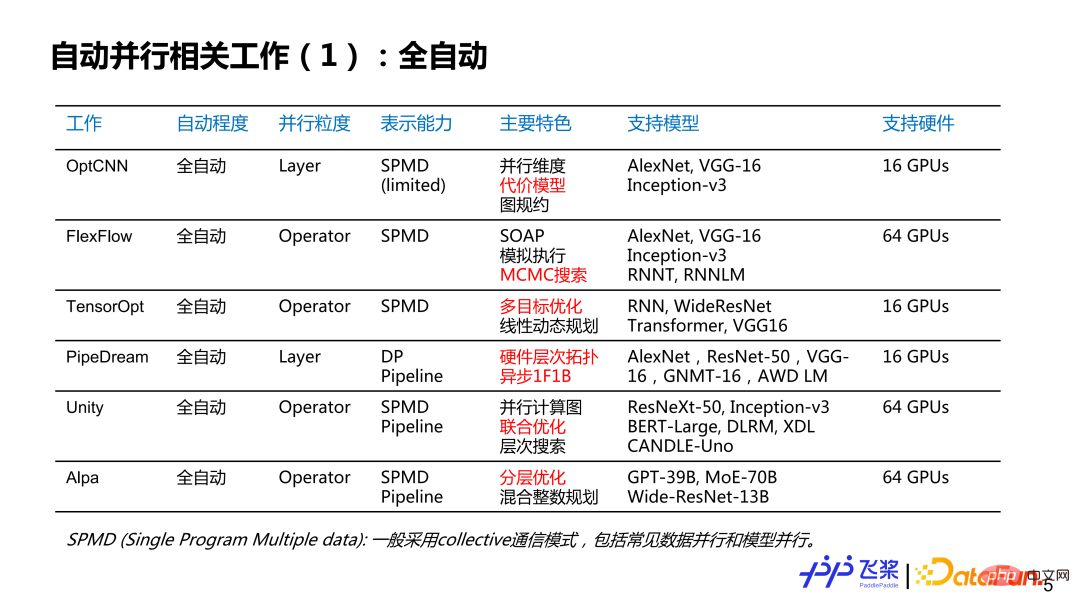
Für die vollautomatische Parallelität können wir sehen, dass parallele Granularität der Entwicklungsprozess von grobkörnig zu feinkörnig ist; die Darstellungsfähigkeit reicht von relativ einfachem SPMD bis hin zu sehr allgemeinen SPMD- und Pipeline-Methoden Die unterstützten Modelle reichen von einfachen CNN über RNN bis hin zu komplexeren GPT. Obwohl mehrere Maschinen und Karten unterstützt werden, ist der Gesamtumfang nicht besonders groß.
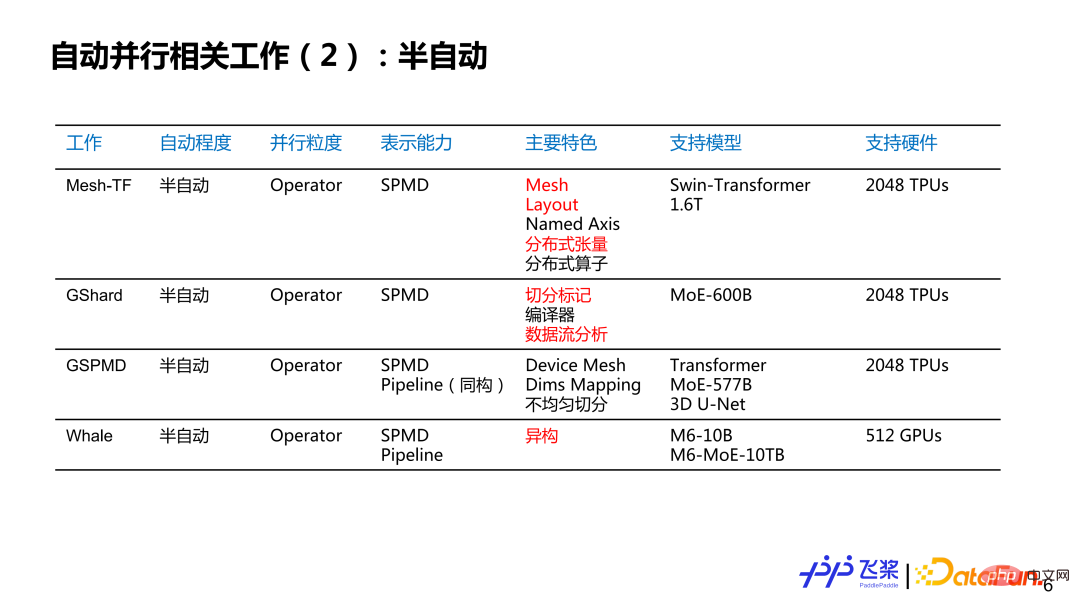
Bei der halbautomatischen Parallelität basiert die parallele Granularität im Wesentlichen auf Operatoren, und die Darstellungsmöglichkeiten reichen von einfachem SPMD bis hin zu vollständigem SPMD plus Parallelstrategie der Pipeline und Modellunterstützung. Die Skala erreicht Hunderte von Milliarden und Billionen, und die Menge der verwendeten Hardware erreicht das Kilokalorien-Niveau.
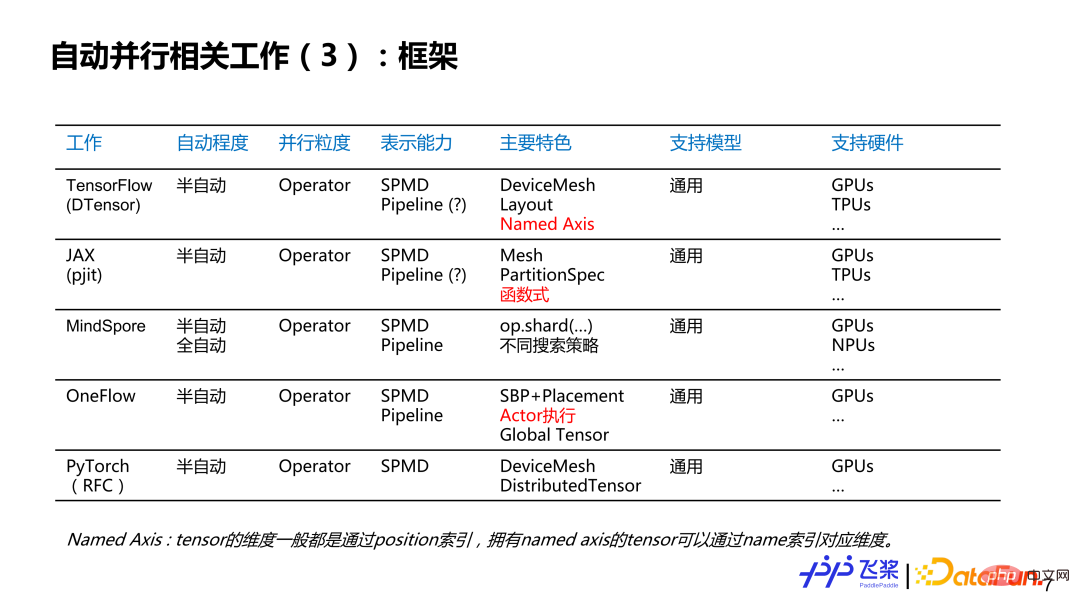
Aus Framework-Sicht können wir sehen, dass bestehende Frameworks diesen halbautomatischen Modus grundsätzlich bereits unterstützen oder dies planen, und dass sich die parallele Granularität auch zu Operator-Granularität und Darstellungsfunktionen entwickelt hat. Sie alle nutzen den vollständigen Ausdruck von SPMD plus Pipeline und sind auf unterschiedliche Modelle und unterschiedliche Hardware ausgerichtet.

Hier ist eine Zusammenfassung einiger persönlicher Gedanken:
① Der erste Punkt ist, dass verteilte Strategien nach und nach in der zugrunde liegenden Darstellung vereinheitlicht werden.
② Zweiter Punkt: Die Halbautomatik wird nach und nach zu einem verteilten Programmierparadigma des Frameworks, während die Vollautomatik auf der Grundlage spezifischer Szenarien und empirischer Regeln erforscht und implementiert wird.
③ Der dritte Punkt besteht darin, die ultimative End-to-End-Leistung zu erreichen, was eine gemeinsame Abstimmung paralleler Strategien und Optimierungsstrategien erfordert.
Im Allgemeinen umfasst eine vollständige verteilte Schulung 4 spezifische Prozesse. Die erste ist die Modellsegmentierung, unabhängig davon, ob es sich um eine manuelle Parallelisierung oder eine automatische Parallelisierung handelt. Die zweite ist die Ressourcenbeschaffung, die wir für das Training benötigen Anschließend erfolgt die Aufgabenplatzierung (oder Aufgabenzuordnung), was bedeutet, dass die aufgeteilten Aufgaben auf den entsprechenden Ressourcen platziert werden und schließlich die Aufgaben auf jedem Gerät parallel ausgeführt und über Nachrichten synchronisiert werden Kommunikation.
Einige aktuelle Mainstream-Lösungen haben einige Probleme: Einerseits berücksichtigen sie möglicherweise nur Teile der Prozesse im verteilten Training oder konzentrieren sich nur auf einen Teil der Prozesse; zweitens verlassen sie sich zu sehr auf Expertenregeln Faktoren wie Modellsegmentierung und Ressourcenverteilung mangelt es an Bewusstsein für Aufgaben und Ressourcen im gesamten Trainingsprozess.
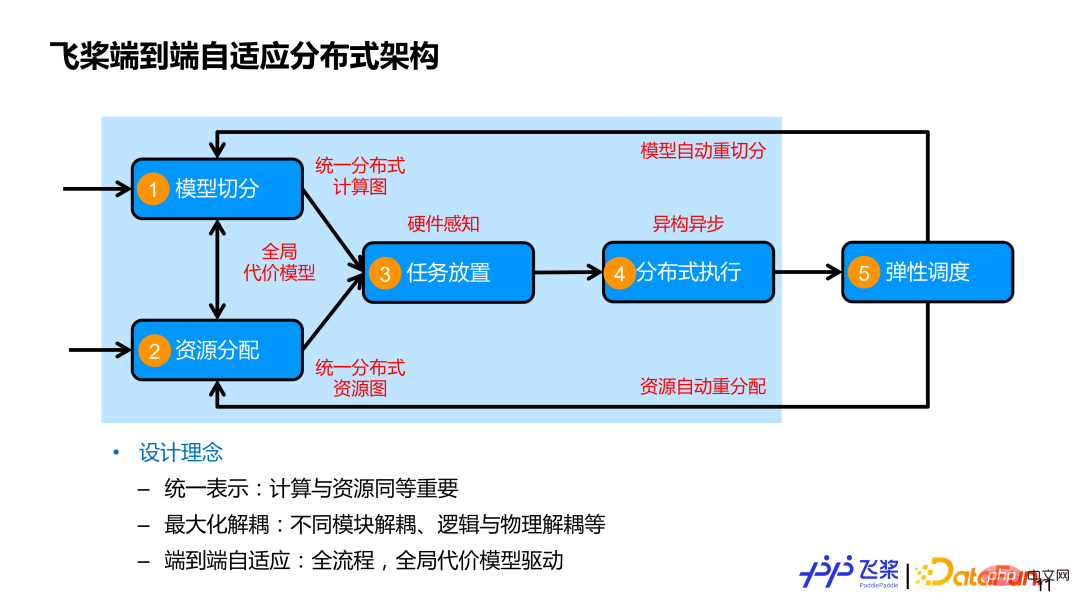
Die von Feipiao entworfene durchgängige adaptive verteilte Trainingsarchitektur berücksichtigt die vier Prozesse vollständig und fügt einen fünften Prozess hinzu, nämlich die elastische Planung. Unsere Kerndesignkonzepte umfassen hauptsächlich diese drei Punkte:
Erstens werden Computer und Ressourcen auf einheitliche Weise ausgedrückt, und Computer und Ressourcen sind gleichermaßen wichtig. Oft geht es den Leuten mehr um die Segmentierung des Modells, den Ressourcen wird jedoch weniger Aufmerksamkeit geschenkt. Einerseits verwenden wir einen einheitlichen verteilten Rechengraphen, um verschiedene parallele Strategien darzustellen. Andererseits verwenden wir einen einheitlichen verteilten Ressourcengraphen, um verschiedene Maschinenressourcen darzustellen, die isomorphe darstellen können. Es kann auch heterogene Ressourcenverbindungsbeziehungen darstellen. und umfasst auch die Rechen- und Speicherkapazitäten der Ressourcen selbst.
Zweitens: Maximieren Sie die Entkopplung zwischen Modulen und entkoppeln Sie die logische Segmentierung von der physischen Platzierung und der verteilten Ausführung, um die effiziente Ausführung verschiedener Modelle auf verschiedenen Clusterressourcen zu erreichen.
Drittens deckt die End-to-End-Anpassung die umfassenden Prozesse ab, die mit verteiltem Training verbunden sind, und verwendet ein globales repräsentatives Modell, um adaptive Entscheidungen über parallele Strategien oder die Platzierung von Ressourcen voranzutreiben und manuelle, individuelle Entscheidungen so weit wie möglich zu ersetzen. Der im obigen Bild hellblau umrahmte Teil ist die in diesem Bericht vorgestellte automatische Parallelitätsarbeit.
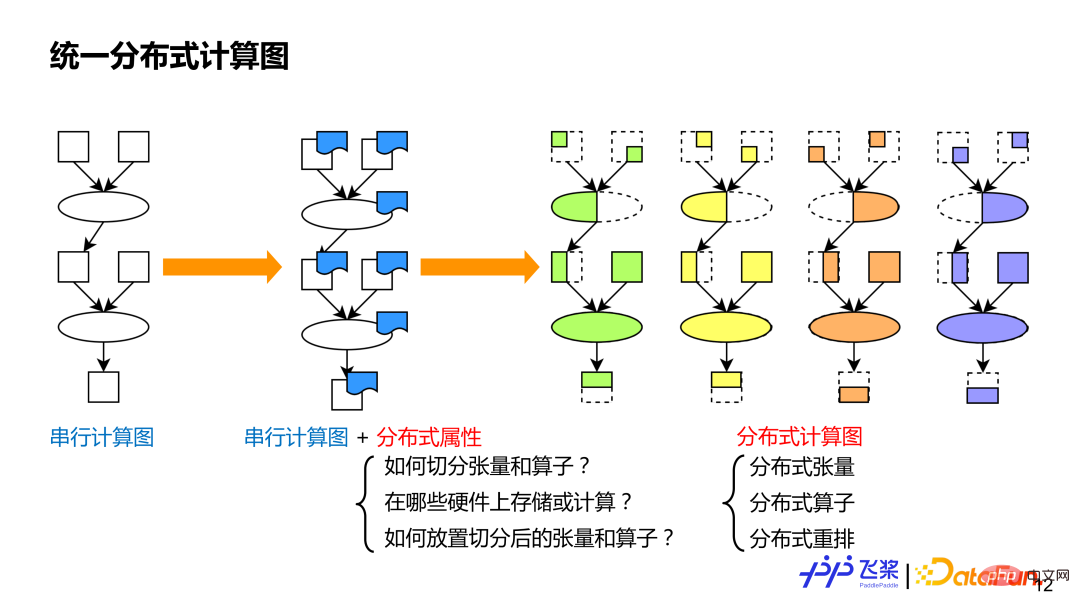
Der erste ist ein einheitlicher verteilter Computergraph. Der Zweck der Vereinheitlichung besteht darin, es uns zu erleichtern, verschiedene bestehende parallele Strategien auf einheitliche Weise auszudrücken, was der automatisierten Verarbeitung förderlich ist. Wie wir alle wissen, können serielle Berechnungsdiagramme verschiedene Modelle darstellen. Basierend auf seriellen Berechnungsdiagrammen fügen wir jedem Operator und Tensor verteilte Attribute hinzu, um als verteilte Berechnungsdiagramme zu dienen Parallelstrategien und die Semantik werden umfangreicher und allgemeiner und können auch neue Parallelstrategien darstellen. Die verteilten Attribute im verteilten Rechendiagramm umfassen hauptsächlich drei Aspekte von Informationen: 1) Es muss angegeben werden, wie der Tensor oder der Operator aufgeteilt wird. 2) Es muss angegeben werden, welche Ressourcen für das verteilte Rechnen verwendet werden um es aufzuteilen Der resultierende Tensor oder Operator wird der Ressource zugeordnet. Im Vergleich zu seriellen Rechendiagrammen gibt es bei verteilten Rechendiagrammen drei Grundkonzepte: verteilte Tensoren, die seriellen verteilten Operatoren ähneln, die seriellen verteilten Umlagerungen ähneln und einzigartig für rechnerische Diagramme sind. (1) Verteilter Tensor
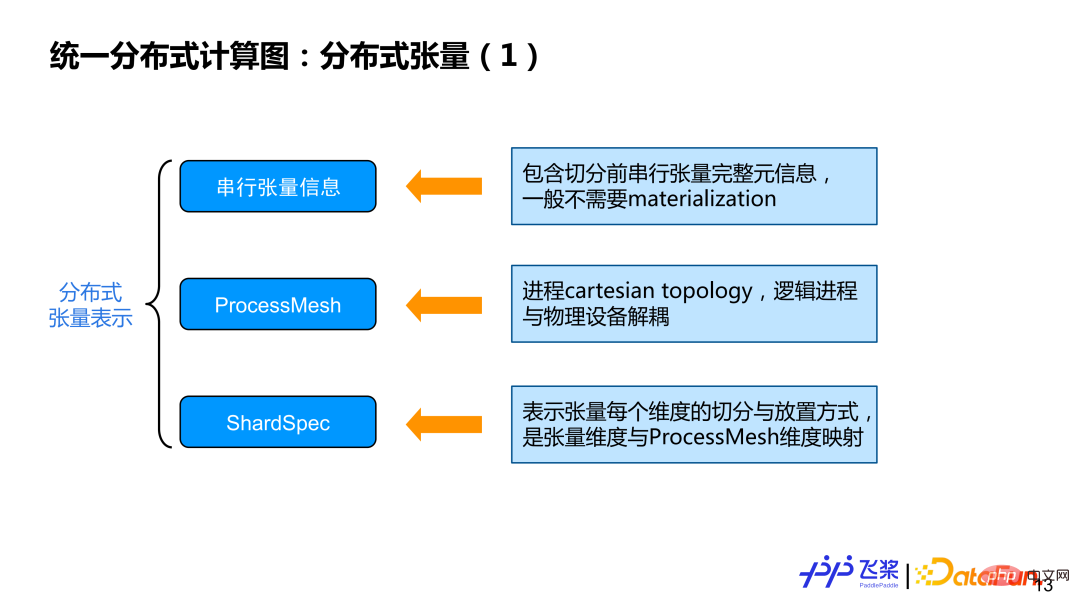 Stellen Sie zunächst die drei Aspekte der im verteilten Tensor enthaltenen Informationen vor:
Stellen Sie zunächst die drei Aspekte der im verteilten Tensor enthaltenen Informationen vor:
Hauptsächlich enthält einige Metainformationen wie Tensorform, D-Typ usw. Im Allgemeinen erfordern tatsächliche Berechnungen keine Instanziierung serieller Tensoren.
② ProcessMesh: Die Kartesionstopologie des Prozesses zeigt an, dass im Gegensatz zu DeviceMesh der Hauptgrund ist, warum wir ProcessMesh verwenden ist zu Der logische Prozess ist vom physischen Gerät entkoppelt, was eine effizientere Aufgabenzuordnung ermöglicht.
③ ShardSpec: wird verwendet, um serielle Tensoren darzustellen Welche Dimension von ProcessMesh zur Segmentierung jeder Dimension verwendet wird? Weitere Informationen finden Sie im folgenden Beispiel.
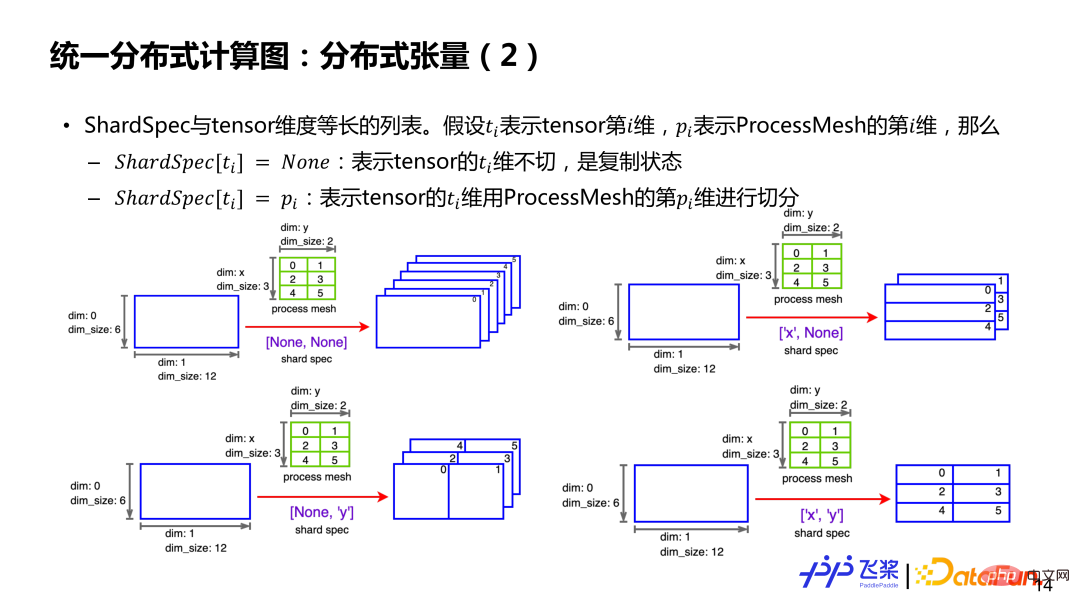
Angenommen, es gibt einen zweidimensionalen 6*12-Tensor und einen 3 *2 ProcessMesh (die erste Dimension ist x, die zweite Dimension ist y und das Element ist die Prozess-ID). Wenn ShardSpec [None, None] ist, bedeutet dies, dass die 0. und 2. Dimension des Tensors nicht geteilt sind und es für jeden Prozess einen vollständigen Tensor gibt. Wenn ShardSpec ['x', 'y'] ist, bedeutet dies, dass die x-Achse von ProcessMesh zum Schneiden der 0. Dimension des Tensors und die y-Achse von ProcessMesh zum Schneiden der 1. Dimension des Tensors verwendet wird , sodass jeder Prozess einen lokalen Tensor der Größe 2*6 hat. Kurz gesagt, durch ProcessMesh und ShardSpec sowie die seriellen Informationen vor der Aufteilung des Tensors ist es möglich, die Aufteilung eines Tensors im relevanten Prozess darzustellen.
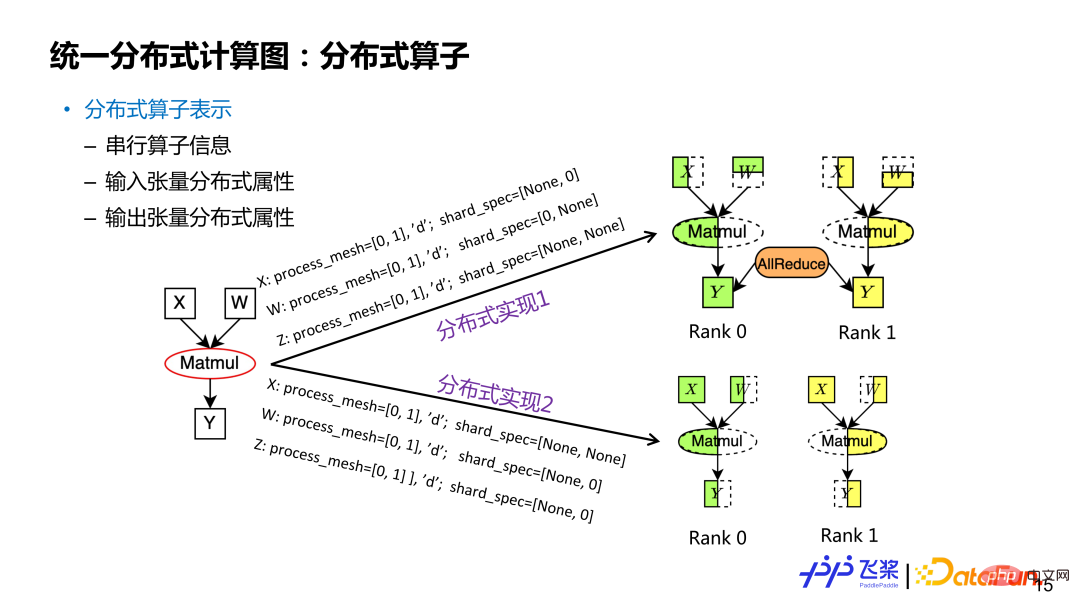
Die Darstellung verteilter Operatoren basiert auf verteilten Tensoren, einschließlich Informationen zu seriellen Operatoren und verteilten Attributen von Eingabe- und Ausgabetensoren. Ebenso kann ein verteilter Tensor mehreren Slicing-Methoden entsprechen. Die verteilten Attribute in verteilten Operatoren sind unterschiedlich und entsprechen unterschiedlichen Slicing-Methoden. Nehmen wir als Beispiel den rechteckigen Multiplikationsoperator Y=X*W: Wenn die Eingabe- und Ausgabeverteilungsattribute unterschiedlich sind, entsprechen sie unterschiedlichen verteilten Operatorimplementierungen (zu den Verteilungsattributen gehören ProcessMesh und ShardSpec). Für einen verteilten Operator ist das ProcessMesh seiner Eingabe- und Ausgabetensoren dasselbe.
(3) Verteilte Umlagerung#🎜🎜 ## 🎜🎜#
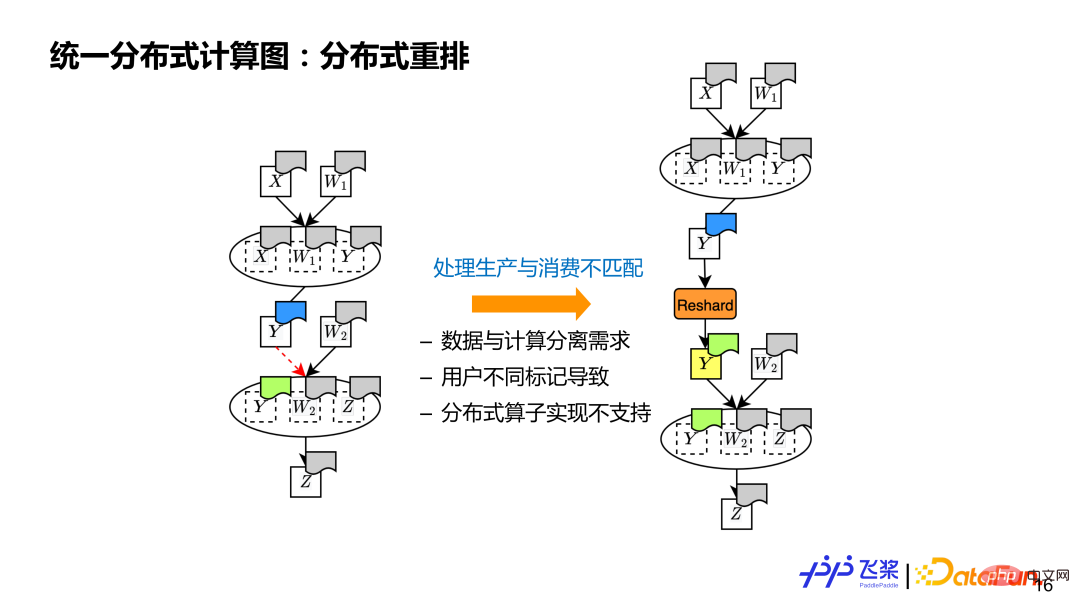
Es gibt drei Hauptgründe für die Nichtübereinstimmung: 1) Es unterstützt die Trennung von Daten und Berechnung, also verwenden Sie es für Tensoren und Die Operatoren verfügen über unterschiedliche verteilte Attribute. 2) Benutzer können unterschiedliche verteilte Attribute für Tensoren und Operatoren markieren, die sie verwenden. 3) Die zugrunde liegende Implementierung verteilter Attribute ist begrenzt Verteilte Attribute werden nicht unterstützt, eine verteilte Neuanordnung ist ebenfalls erforderlich.
2. Einheitliche verteilte Ressourcenkarte
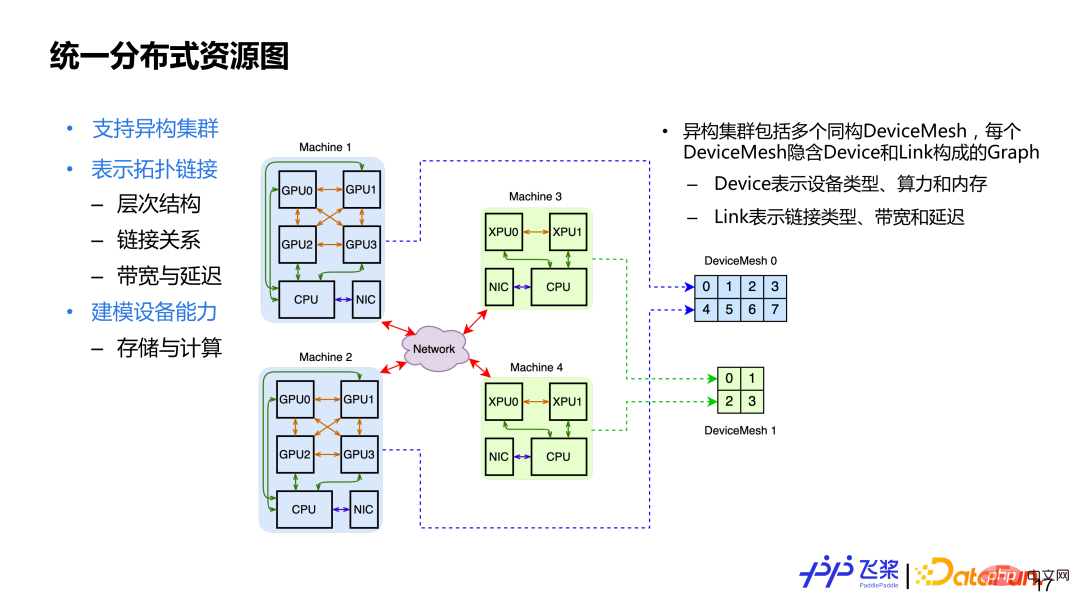 Nachdem wir die drei Grundkonzepte des einheitlichen verteilten Rechendiagramms vorgestellt haben, schauen wir uns das einheitliche verteilte Ressourcendiagramm an. Die wichtigsten Designüberlegungen sind: 1) Unterstützung für heterogene Cluster Ein heterogener Cluster bedeutet, dass sich im Cluster möglicherweise CPU-, GPU- und 3) Das Gerät selbst ist ein Modul, einschließlich der Speicher- und Rechenfunktionen eines Geräts. Um die oben genannten Designanforderungen zu erfüllen, verwenden wir Cluster zur Darstellung verteilter Ressourcen, die mehrere isomorphe DeviceMesh enthalten. Jedes DeviceMesh enthält ein Diagramm, das aus Geräteverknüpfungen besteht.
Nachdem wir die drei Grundkonzepte des einheitlichen verteilten Rechendiagramms vorgestellt haben, schauen wir uns das einheitliche verteilte Ressourcendiagramm an. Die wichtigsten Designüberlegungen sind: 1) Unterstützung für heterogene Cluster Ein heterogener Cluster bedeutet, dass sich im Cluster möglicherweise CPU-, GPU- und 3) Das Gerät selbst ist ein Modul, einschließlich der Speicher- und Rechenfunktionen eines Geräts. Um die oben genannten Designanforderungen zu erfüllen, verwenden wir Cluster zur Darstellung verteilter Ressourcen, die mehrere isomorphe DeviceMesh enthalten. Jedes DeviceMesh enthält ein Diagramm, das aus Geräteverknüpfungen besteht.
Hier ist ein Beispiel. Im Bild oben sehen Sie, dass es 4 Maschinen gibt, darunter 2 GPU-Maschinen und 2 XPU-Maschinen. Für 2 GPU-Maschinen wird ein isomorphes DeviceMesh verwendet, und für 2 XPU-Maschinen wird ein weiteres isomorphes DeviceMesh verwendet. Für einen festen Cluster ist sein DeviceMesh festgelegt und der Benutzer betreibt ProcessMesh, was als Abstraktion von DeviceMesh verstanden werden kann. Der Benutzer kann nach Belieben umformen und segmentieren, und schließlich wird der ProcessMesh-Prozess einheitlich dem DeviceMesh-Gerät zugeordnet.
... Datenparallelität besteht darin, die Batch-Dimension des Datentensors aufzuteilen. Das Modell segmentiert gewichtsbezogene Maße parallel. Pipeline-Parallelität wird durch unterschiedliche ProcessMesh dargestellt, die als flexiblere Pipeline-Parallelität ausgedrückt werden können. Beispielsweise kann eine Pipeline-Stufe mehrere Pipeline-Stufen verbinden, und die Formen von ProcessMesh, die von verschiedenen Stufen verwendet werden, können unterschiedlich sein. Die Pipeline-Parallelität einiger anderer Frameworks wird durch Stufennummer oder Platzierung erreicht, was nicht flexibel und vielseitig genug ist. Hybridparallelität ist eine Mischung aus Datenparallelität, Tensormodellparallelität und Pipelineparallelität.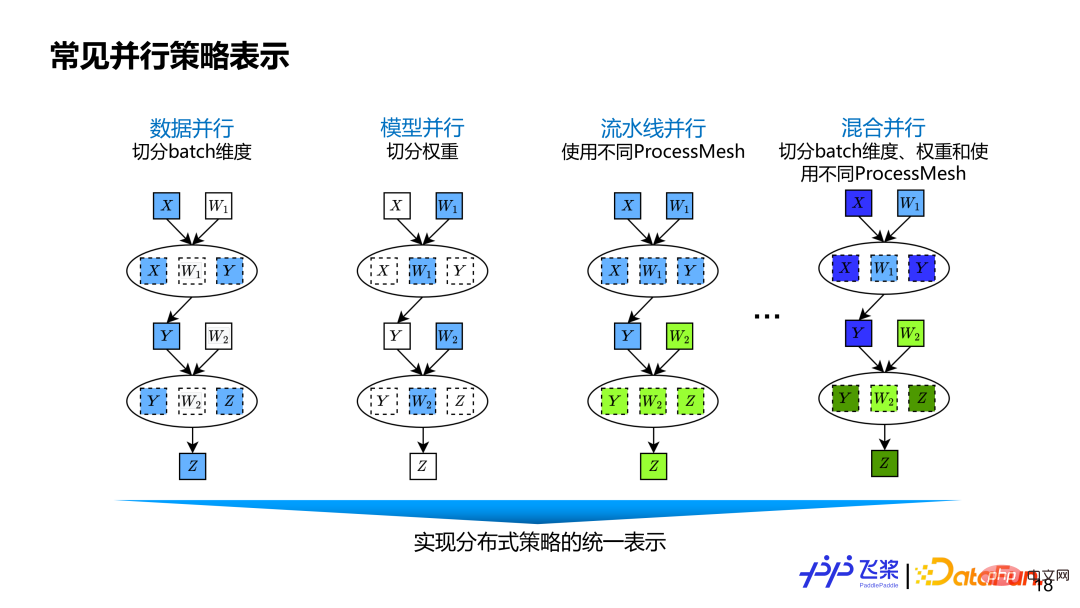
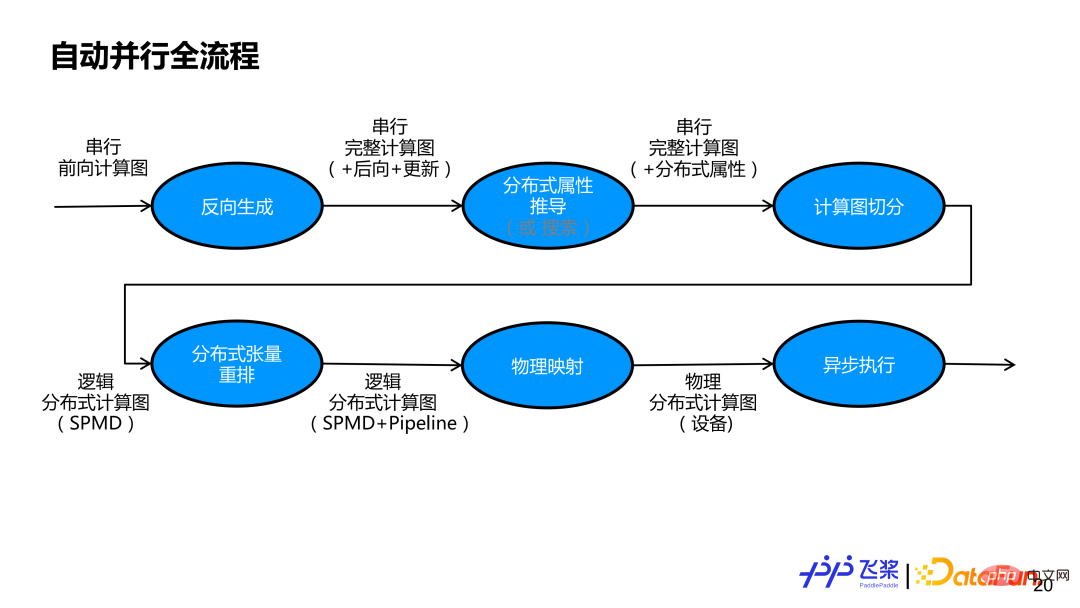
Die Vorderseite ist das automatische parallele Architekturdesign des Flugpaddels und die Einführung einiger abstrakter Konzepte. Basierend auf der vorherigen Grundlage stellen wir den internen Implementierungsprozess der automatischen Parallelisierung von Flying Paddles am Beispiel eines Layer-2-FC-Netzwerks vor.
Das obige Bild ist das gesamte automatische Parallelflussdiagramm des Flugpaddels. Zuerst führen wir eine Rückwärtsgenerierung basierend auf einem seriellen Vorwärtsberechnungsgraphen durch, um einen vollständigen Berechnungsgraphen einschließlich Vorwärts-, Rückwärts- und Aktualisierungsuntergraphen zu erhalten. Anschließend müssen die verteilten Eigenschaften jedes Tensors und jedes Operators im Netzwerk geklärt werden. Es kann entweder eine halbautomatische Ableitungsmethode oder eine vollautomatische Suchmethode verwendet werden. In diesem Bericht wird hauptsächlich die halbautomatische Ableitungsmethode erläutert, bei der die verteilten Eigenschaften anderer unbeschrifteter Tensoren und Operatoren basierend auf einer kleinen Anzahl von Benutzerbezeichnungen abgeleitet werden. Nach der Ableitung durch verteilte Eigenschaften hat jeder Tensor und jeder Operator im seriellen Berechnungsdiagramm seine eigenen verteilten Eigenschaften. Basierend auf den verteilten Attributen wird das serielle Berechnungsdiagramm zunächst durch automatische Segmentierungsmodule in ein logisch verteiltes Berechnungsdiagramm umgewandelt, das SPMD-Parallelität unterstützt. Anschließend wird durch verteilte Neuanordnung ein logisch verteiltes Berechnungsdiagramm realisiert, das Pipeline-Parallelität unterstützt. Der generierte logische verteilte Computergraph wird durch physische Zuordnung in einen physischen verteilten Computergraphen umgewandelt. Derzeit wird nur eine Eins-zu-eins-Zuordnung eines Prozesses und eines Geräts unterstützt. Schließlich wird der physische verteilte Rechengraph in einen tatsächlichen Aufgabenabhängigkeitsgraphen umgewandelt und zur tatsächlichen Ausführung an den asynchronen Executor übergeben.
1. Ableitung verteilter Attribute
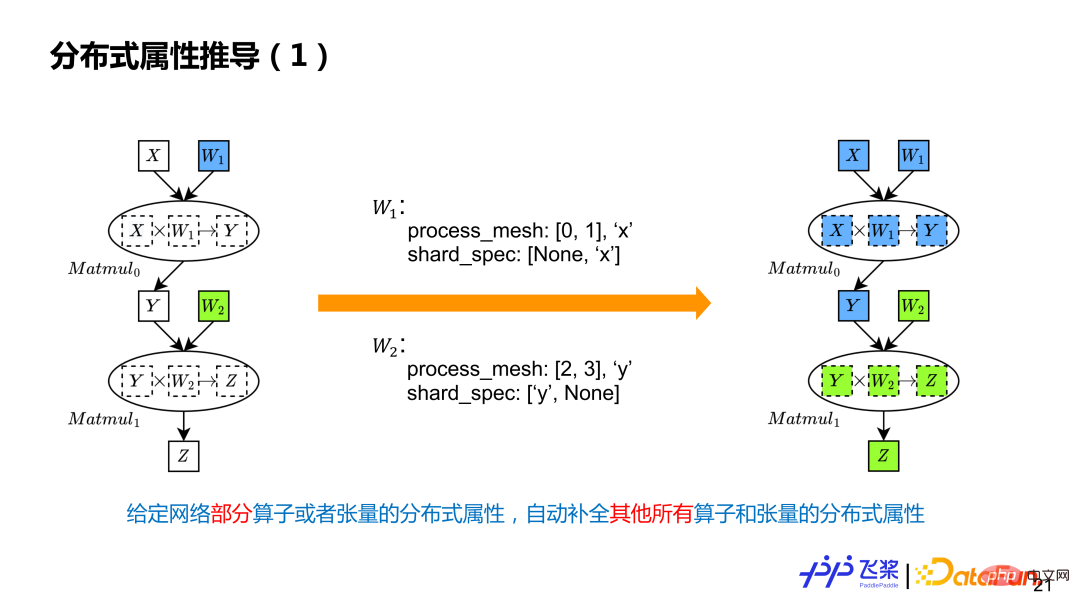
Die Ableitung verteilter Attribute ist in zwei Schritte unterteilt: 1) Führen Sie zunächst eine ProcessMesh-Übertragung durch, um die Pipeline-Segmentierung zu implementieren. 2) Führen Sie dann eine ShardSpec-Übertragung durch, um die SPMD-Segmentierung innerhalb einer Stufe zu implementieren. Die ProcessMesh-Ableitung verwendet das lineare Flying-Paddle-Programm lR und verwendet die nächste Auswahlstrategie für die Ableitung gemäß der statischen Programmreihenfolge. Es unterstützt eingeschlossene Berechnungen, das heißt, wenn zwei ProcessMesh vorhanden sind, ist eines größer und das andere kleiner Das größere wird als endgültiges ProcessMesh ausgewählt. Die ShardSpec-Ableitung verwendet Flying Paddle SSA Graph IR, um eine Vorwärts- und Rückwärts-Datenflussanalyse zur Ableitung durchzuführen. Der Grund, warum die Datenflussanalyse verwendet werden kann, liegt darin, dass die ShardSpec-Semantik die Semilattice-Eigenschaft der Datenflussanalyse erfüllt. Durch die Kombination von Vorwärts- und Rückwärtsanalyse kann die Datenflussanalyse theoretisch eine Konvergenz gewährleisten, sodass alle Positionsmarkierungsinformationen im Berechnungsdiagramm auf das gesamte Berechnungsdiagramm übertragen werden können, anstatt nur in eine Richtung. 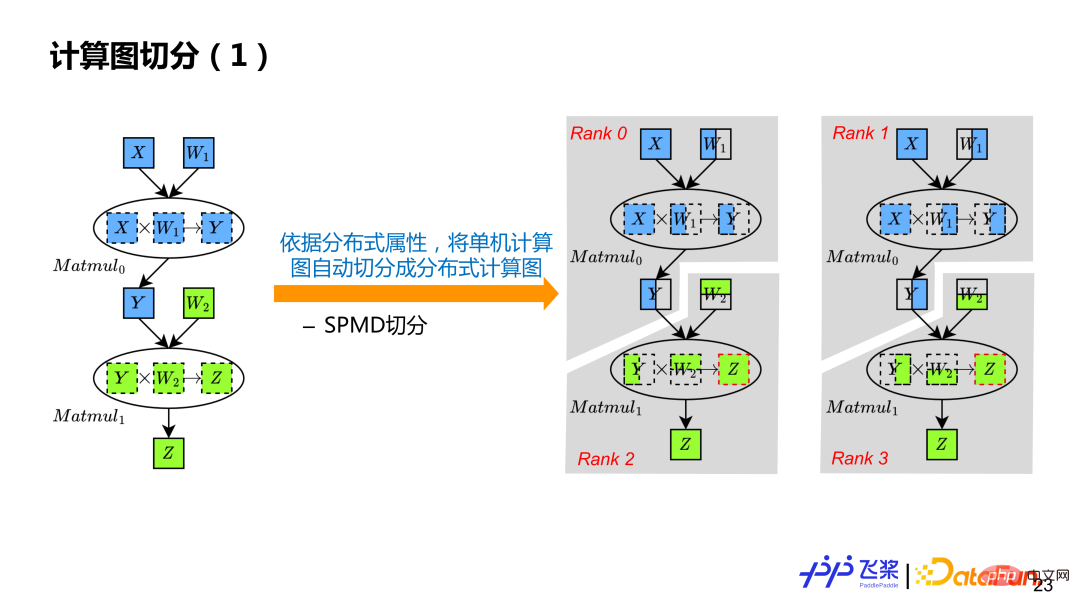
Basierend auf der Ableitung verteilter Attribute verfügt jeder Tensor und Operator im seriellen Berechnungsdiagramm über ein eigenes verteiltes Attribut, sodass das Berechnungsdiagramm basierend auf verteilten Attributen automatisch abgeleitet werden kann. Gemäß dem Beispiel wird der serielle Berechnungsgraph einer einzelnen Maschine in vier Berechnungsgraphen Rang0, Rang1, Rang2 und Rang3 umgewandelt.
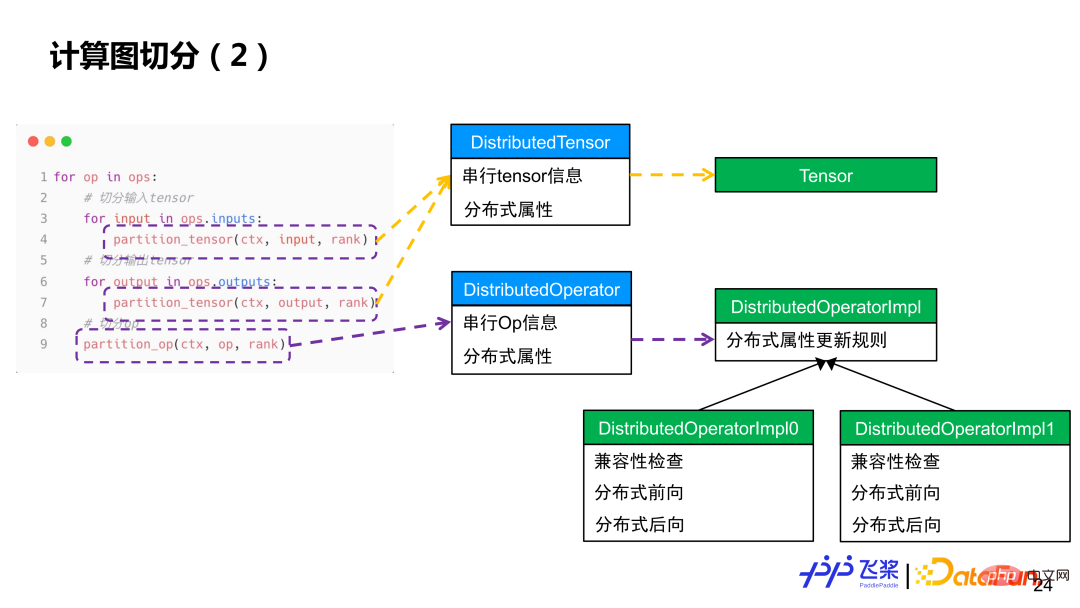
Einfach ausgedrückt wird jeder Operator durchlaufen, die Eingabe und Ausgabe des Operators werden zuerst in Tensoren unterteilt und dann wird jeder Operator berechnet und unterteilt. Die Tensorsegmentierung verwendet das Distributed Tensor-Objekt, um ein lokales Tensorobjekt zu erstellen, während die Operatorsegmentierung das Distributed Operator-Objekt verwendet, um die entsprechende verteilte Implementierung basierend auf den Verteilungsattributen der tatsächlichen Eingabe und Ausgabe auszuwählen, ähnlich der Verteilung von Operatoren aus a Einzelmaschinen-Framework für den Kernel-Prozess.
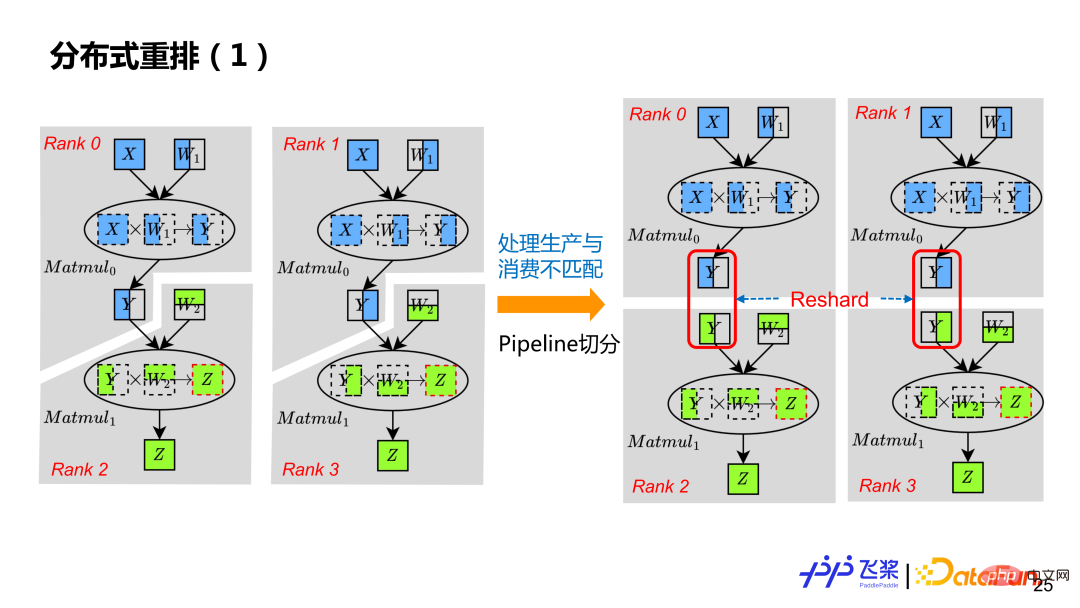
Durch die vorherige automatische Segmentierung können Sie nur ein verteiltes Rechendiagramm erhalten, das SPMD-Parallelität unterstützt. Um die Pipeline-Parallelität zu unterstützen, muss sie auch durch verteilte Neuanordnung verarbeitet werden, sodass durch Einfügen einer geeigneten Reshard-Operation jeder Rang im Beispiel über einen eigenen, wirklich unabhängigen Berechnungsgraphen verfügt. Obwohl das Y von Rang0 im linken Bild mit dem Y von Rang2 übereinstimmt, befinden sie sich auf unterschiedlichen ProcessMeshs, was zu einer Nichtübereinstimmung der Verteilungsattribute von Produktion und Verbrauch führt, sodass auch Reshard eingefügt werden muss.
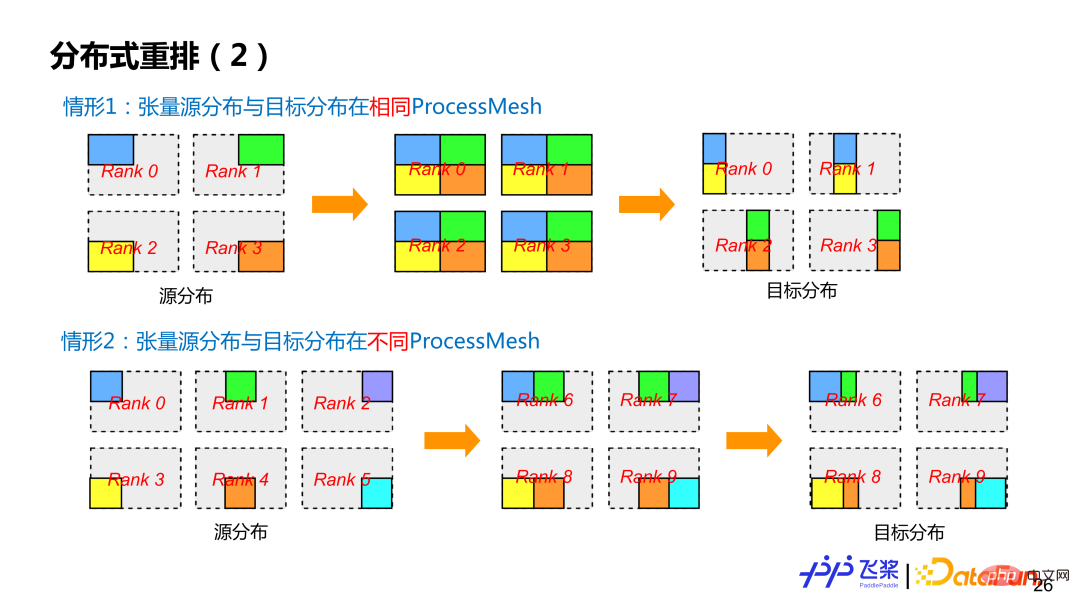
Flying Paddle unterstützt derzeit zwei Arten der verteilten Neuordnung. Die erste Kategorie ist die häufigere Quell-Tensor-Verteilung und Ziel-Tensor-Verteilung auf demselben ProcessMesh, aber die Quell-Tensor-Verteilung und die Ziel-Tensor-Verteilung verwenden unterschiedliche Slicing-Methoden (das heißt, die ShardSpec ist unterschiedlich). Die zweite Kategorie besteht darin, dass die Quelltensorverteilung und der Zieltensor auf unterschiedlichen ProcessMesh verteilt sind und die ProcessMesh-Größe unterschiedlich sein kann, z. B. der 0-5-Prozess und der 6-9-Prozess im Fall 2 in der Abbildung. Um die Kommunikation so weit wie möglich zu reduzieren, führt Flying Paddle auch entsprechende Optimierungen für Reshard-Operationen durch.
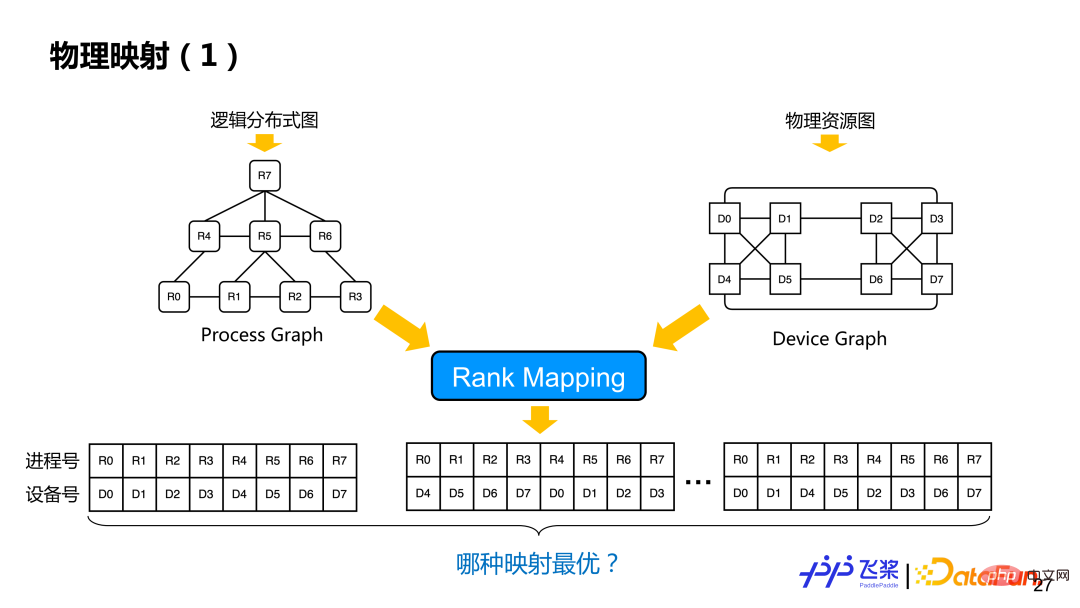
Nach der verteilten Neuanordnung wird ein logisches verteiltes Rechendiagramm erhalten. Zu diesem Zeitpunkt sind der Prozess und die spezifische Gerätezuordnung noch nicht entschieden. Basierend auf dem logischen verteilten Rechendiagramm und dem zuvor vereinheitlichten Ressourcendarstellungsdiagramm werden physische Zuordnungsvorgänge durchgeführt, bei denen es sich um eine Rank-Zuordnung handelt, bei der aus mehreren Zuordnungslösungen (welchem Gerät ein Prozess speziell zugeordnet wird) eine optimale Zuordnungslösung gefunden wird.
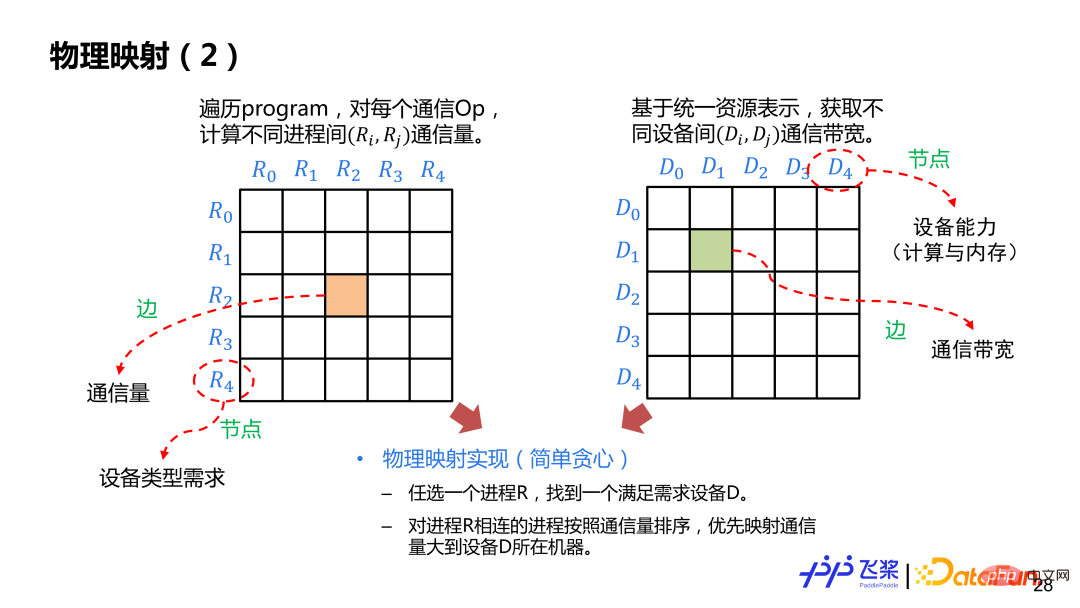
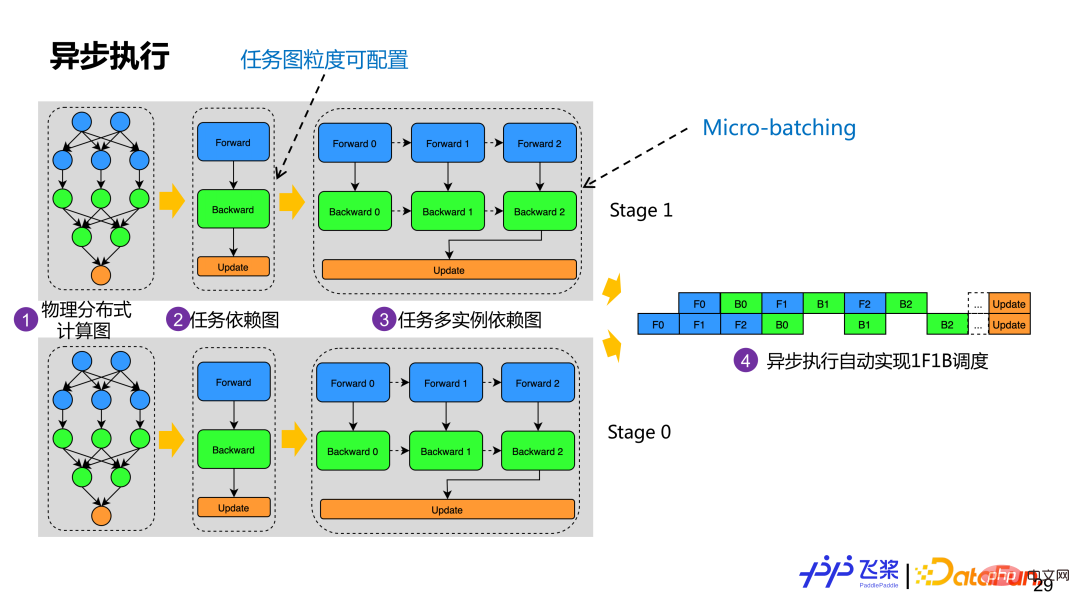
Hier ist eine relativ einfache Implementierung, die auf gierigen Regeln basiert. Erstellen Sie zunächst die Adjazenztabelle zwischen Prozessen und der Kommunikation zwischen Prozessen. Die Kanten stellen das Kommunikationsvolumen und die Knoten dar. Erstellen Sie dann die Adjazenztabelle zwischen Geräten Erinnerung. Wir wählen zufällig einen Prozess R aus und platzieren ihn auf dem Gerät D, das den Anforderungen entspricht. Anschließend wählen wir den Prozess mit dem größten Kommunikationsvolumen mit R aus und platzieren ihn auf anderen Geräten der Maschine, auf denen sich D befindet Die Methode wird verwendet, bis alle Prozesszuordnungen abgeschlossen sind. Während des Zuordnungsprozesses muss festgestellt werden, ob das ausgewählte Gerät dem vom Prozessdiagramm geforderten Gerätetyp sowie der erforderlichen Berechnungsmenge und dem erforderlichen Speicher entspricht. Nach der physischen Zuordnung erstellen wir das tatsächliche Aufgabenabhängigkeitsdiagramm basierend auf dem erhaltenen physischen verteilten Netzwerk. Das Beispiel in der Abbildung besteht darin, ein Aufgabenabhängigkeitsdiagramm basierend auf den Vorwärts-, Rückwärts- und Aktualisierungsrollen des Berechnungsdiagramms zu erstellen. Operatoren mit derselben Rolle bilden eine Aufgabe. Um die Micro-Batching-Optimierung zu unterstützen, generiert ein Aufgabenabhängigkeitsdiagramm mehrere Aufgabeninstanzabhängigkeitsdiagramme. Obwohl jede Instanz über dieselbe Berechnungslogik verfügt, verwendet sie einen unterschiedlichen Speicher. Derzeit erstellt Flying Paddle automatisch ein Aufgabendiagramm basierend auf den Rollen des Berechnungsdiagramms, Benutzer können die Aufgabenerstellung jedoch entsprechend der entsprechenden Granularität anpassen. Nachdem jeder Prozess über ein Task-Multi-Instanz-Abhängigkeitsdiagramm verfügt, wird er basierend auf dem Akteurmodus asynchron ausgeführt, und die 1F1B-Ausführungsplanung kann automatisch über die nachrichtengesteuerte Methode realisiert werden. Basierend auf dem gesamten Prozess oben haben wir eine automatische Parallelisierung mit relativ vollständigen Funktionen implementiert. Aber nur die parallele Strategie kann keine bessere End-to-End-Leistung erzielen, daher müssen wir auch entsprechende Optimierungsstrategien hinzufügen. Für die automatische Parallelisierung von Flugpaddeln werden wir vor der automatischen Segmentierung und nach der Netzwerksegmentierung einige Optimierungsstrategien hinzufügen. Dies liegt daran, dass einige Optimierungen natürlicher in der seriellen Logik implementiert werden können und einige Optimierungen nach der Segmentierung einfacher zu implementieren sind Managementmechanismus können wir die freie Kombination von Parallelstrategien und Optimierungsstrategien bei der automatischen Parallelisierung von Flugpaddeln sicherstellen. 4. Anwendungspraxis . Das erste ist die Schnittstelle Unabhängig von der Implementierung nutzen Benutzer endlich die automatischen Parallelfunktionen, die wir über die Schnittstelle bereitstellen. Wenn die verteilten Anforderungen des Benutzers zerlegt werden, umfasst dies die Modellnetzwerksegmentierung, die Ressourcendarstellung, das verteilte Laden von Daten, die Steuerung des verteilten Ausführungsprozesses, die verteilte Speicherung und Wiederherstellung usw. Um diesen Anforderungen gerecht zu werden, bieten wir eine Engine-Klasse an, die Benutzerfreundlichkeit mit Flexibilität kombiniert. Im Hinblick auf die Benutzerfreundlichkeit bietet es High-Level-APIs, kann benutzerdefinierte Rückrufe unterstützen und der verteilte Prozess ist für Benutzer transparent. Im Hinblick auf die Flexibilität bietet es Low-Level-APIs, einschließlich verteilter Dataloader-Konstruktion, automatisches paralleles Schneiden und Ausführen von Diagrammen sowie andere Schnittstellen, die Benutzern eine detailliertere Steuerung ermöglichen. Die beiden teilen sich Schnittstellen wie shard_tensor, shard_op, Speichern und Laden.
Es gibt zwei beschriftete Schnittstellen shard_op und shard_tensor. Unter anderem kann shard_op entweder einen einzelnen Operator oder das gesamte Modul markieren und ist eine Funktionsformel. Das Bild oben ist ein sehr einfaches Anwendungsbeispiel. Verwenden Sie zunächst die vorhandene API von Flying Paddle, um ein serielles Netzwerk zu leiten, in dem wir shard_tensor oder shard_op für die nicht-intrusive verteilte Attributmarkierung verwenden. Erstellen Sie dann eine automatische Parallel-Engine und übergeben Sie modellbezogene Informationen und Konfigurationen. Zu diesem Zeitpunkt hat der Benutzer zwei Optionen: Eine Option besteht darin, die Schnittstelle „fit/evaluate/predict“ hoher Ordnung direkt zu verwenden, und die andere Option besteht darin, die Schnittstelle „dataloader+prepare+run“ zu verwenden. Wenn Sie die Fit-Schnittstelle wählen, muss der Benutzer nur den Datensatz übergeben, und das Framework lädt automatisch den verteilten Datensatz, kompiliert automatisch den Parallelprozess und führt verteiltes Training aus. Wenn Sie die Schnittstelle „Dataloader+Prepare+Run“ wählen, können Benutzer das verteilte Laden von Daten, die automatische parallele Kompilierung und die verteilte Ausführung entkoppeln, was ein besseres Debuggen in einem Schritt ermöglicht.
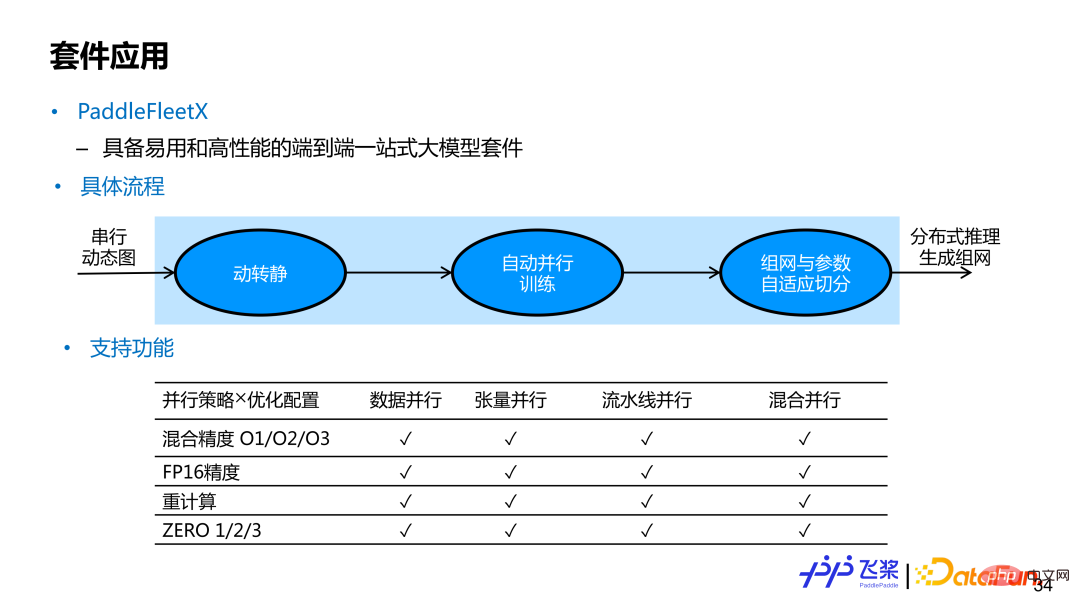
PaddleFleetX ist eine durchgängige, große Modellsuite aus einer Hand mit einfacher Bedienung und hoher Leistung, die die automatische Parallelisierung unterstützt. Wenn Benutzer die automatische parallele End-to-End-Funktion des Flugpaddels nutzen möchten, müssen sie lediglich ein serielles dynamisches Diagrammmodellnetzwerk bereitstellen. Nach Erhalt des dynamischen grafischen seriellen Netzwerks des Benutzers verwendet die interne Implementierung das Modul „Flying Paddle Dynamic to Static“, um das dynamische Diagramm-Einzelkartennetzwerk in ein statisches Diagramm-Einzelkartennetzwerk umzuwandeln, das dann automatisch parallel kompiliert und schließlich verteilt wird Ausbildung. . Während der Inferenzgenerierung können sich die verwendeten Maschinenressourcen von denen unterscheiden, die während des Trainings verwendet werden. Die interne Implementierung führt auch eine adaptive Parametersegmentierung und Vernetzung durch. Derzeit deckt die automatische Parallelität in PaddleFleetX häufig verwendete Parallelstrategien und Optimierungsstrategien ab und unterstützt jede Kombination dieser beiden. Für generierte Aufgaben unterstützt sie auch die automatische Segmentierung des While-Kontrollflusses.

Es gibt noch viel Arbeit für automatische Parallelflugpaddel. Die aktuellen Funktionen lassen sich in folgenden Aspekten zusammenfassen:
Erstens kann die Vereinheitlichung des verteilten Rechendiagramms vollständige verteilte SPMD- und Pipeline-Strategien sowie die getrennte Darstellung von Speicher und Rechenleistung unterstützen. Zweitens kann das einheitliche verteilte Ressourcendiagramm die heterogene Ressourcenmodellierung unterstützen und Darstellung;
Drittens unterstützt es die organische Kombination von Parallelstrategien und Optimierungsstrategien;
Viertens bietet es ein relativ vollständiges Schnittstellensystem;
Komponenten unterstützen die durchgängige adaptive verteilte Architektur des Flugpaddels.
Parallel kann im Allgemeinen in zwei Bereiche unterteilt werden (ohne klare Abgrenzung), eines ist traditionelles verteiltes Rechnen und das andere ist traditionelles Hochleistungsrechnen, die beide ihre eigenen Vorteile haben und Nachteile. Das repräsentative Framework, das auf traditionellem verteiltem Rechnen basiert, ist TensorFlow, das sich auf den MPMD-Parallelmodus (Multiple Program-Multiple Data) konzentriert und Elastizität und Fehlertoleranz gut unterstützen kann Verwenden Sie im Allgemeinen die Programmierung aus einer seriellen globalen Perspektive. Das repräsentative Framework, das auf traditionellem Hochleistungsrechnen basiert, konzentriert sich mehr auf den SPMD-Modus (Single Program-Multiple Data) und strebt nach der ultimativen Leistung, die Benutzer benötigen, um sich direkt dem physischen Cluster zu stellen Programmieren und für die Segmentierung des Modells selbst verantwortlich sind und entsprechende Kommunikation einfügen, sind die Benutzeranforderungen höher. Automatische Parallelität oder adaptives verteiltes Rechnen können als Kombination aus beidem angesehen werden. Natürlich haben unterschiedliche Architekturen unterschiedliche Designprioritäten und müssen entsprechend den tatsächlichen Anforderungen abgewogen werden. Wir hoffen, dass die adaptive Architektur mit fliegenden Paddeln die Vorteile beider Bereiche berücksichtigen kann. 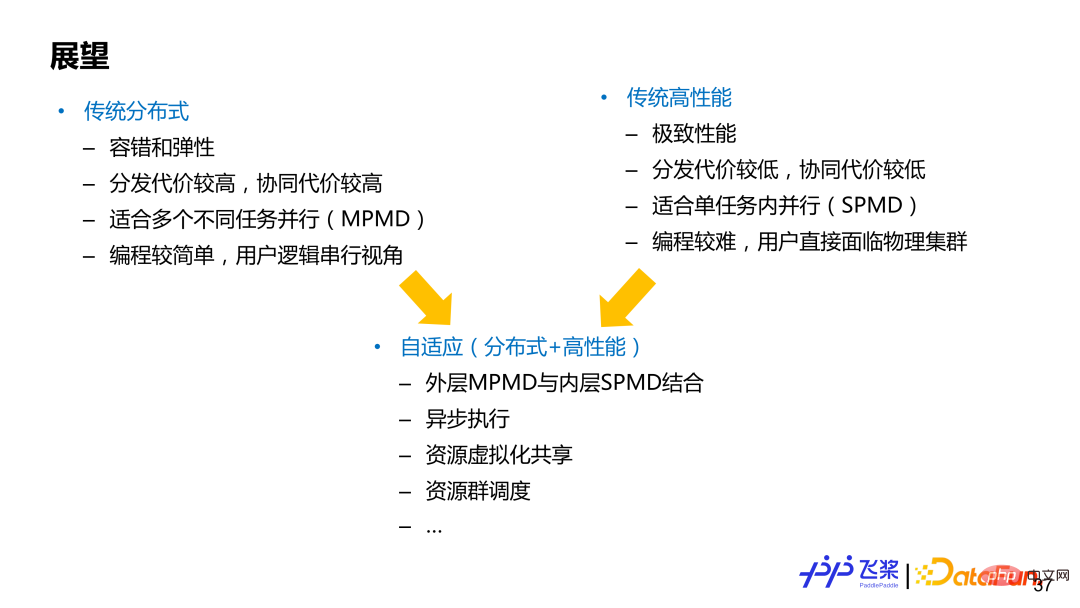
Das obige ist der detaillierte Inhalt vonFlying Paddle ist für die automatische Parallelität in heterogenen Szenarien konzipiert und praktiziert.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 PR-Tastenkombination
PR-Tastenkombination
 Der Unterschied zwischen Python-Kursen und C+-Kursen
Der Unterschied zwischen Python-Kursen und C+-Kursen
 Gängige Methoden zur Erkennung von Website-Schwachstellen
Gängige Methoden zur Erkennung von Website-Schwachstellen
 Was sind die GSM-Verschlüsselungsalgorithmen?
Was sind die GSM-Verschlüsselungsalgorithmen?
 Was tun, wenn Ihre IP-Adresse angegriffen wird?
Was tun, wenn Ihre IP-Adresse angegriffen wird?
 Der Unterschied zwischen insertbefore und before
Der Unterschied zwischen insertbefore und before
 Welche Protokolle umfasst das SSL-Protokoll?
Welche Protokolle umfasst das SSL-Protokoll?
 So öffnen Sie eine XML-Datei
So öffnen Sie eine XML-Datei








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



