


Diesen Dezember, wenn ChatGPT von OpenAI an Fahrt gewinnt, ist AlphaCode, das einst die Hälfte der Programmierer überwältigte, auf dem Cover von Science!

Link zum Papier: https://www.science.org/doi/10.1126/science.abq1158
Apropos AlphaCode: Jeder muss damit vertraut sein.
Bereits im Februar dieses Jahres nahm es still und leise an 10 Programmierwettbewerben auf den berühmten Codeforces teil und besiegte die Hälfte der menschlichen Programmierer auf einen Schlag.
Die Hälfte der Programmierer liegt im Liegen
Wir alle wissen, dass ein solcher Test bei Programmierwettbewerben sehr beliebt ist.
Im Wettbewerb ist der Haupttest die Fähigkeit des Programmierers, anhand von Erfahrungen kritisch zu denken und Lösungen für unvorhergesehene Probleme zu finden.
Dies verkörpert den Schlüssel zur menschlichen Intelligenz, und es ist oft schwierig, diese Art menschlicher Intelligenz mit Modellen des maschinellen Lernens zu imitieren.
Aber Wissenschaftler von DeepMind haben diese Regel gebrochen.
YujiA Li et al. haben AlphaCode mithilfe einer selbstüberwachten Lern- und Encoder-Decoder-Konverterarchitektur entwickelt.

Die Entwicklungsarbeit von AlphaCode wurde zu Hause abgeschlossen
Obwohl AlphaCode auch auf der Standard-Transformer-Codec-Architektur basiert, hat DeepMind sie auf ein „episches Niveau“ verbessert ——
Es verwendet ein Transformer-basiertes Sprachmodell, um Code in einem beispiellosen Umfang zu generieren, und filtert dann geschickt einen kleinen Satz verfügbarer Programme heraus.
Die spezifischen Schritte sind:
1) Multi-Ask-Aufmerksamkeit: Lassen Sie jeden Aufmerksamkeitsblock den Schlüssel- und Wertheader teilen und kombinieren Sie ihn gleichzeitig mit dem Encoder-Decoder-Modell, um die Abtastgeschwindigkeit von zu erhöhen AlphaCode Mehr als 10 Mal.
2) Masked Language Modeling (MLM): Durch Hinzufügen eines MLM-Verlusts zum Encoder wird die Lösungsrate des Modells verbessert.
3) Temperierung: Machen Sie die Trainingsverteilung schärfer und verhindern Sie so den Regularisierungseffekt einer Überanpassung.
4) Wertkonditionierung und Vorhersage: Stellen Sie ein zusätzliches Trainingssignal bereit, indem Sie im CodeContests-Datensatz zwischen korrekten und falschen Frageneinsendungen unterscheiden.
5) Exemplarische Out-of-Strategy-Learning-Generierung (GOLD): Lassen Sie das Modell die richtige Lösung für jedes Problem generieren, indem Sie das Training auf die wahrscheinlichste Lösung für jedes Problem konzentrieren.
Nun, das Ergebnis kennt jeder.
Mit einem Elo-Score von 1238 landete AlphaCode in diesen 10 Spielen unter den besten 54,3 %. Betrachtet man die letzten 6 Monate, so erreichte dieses Ergebnis die besten 28 %.
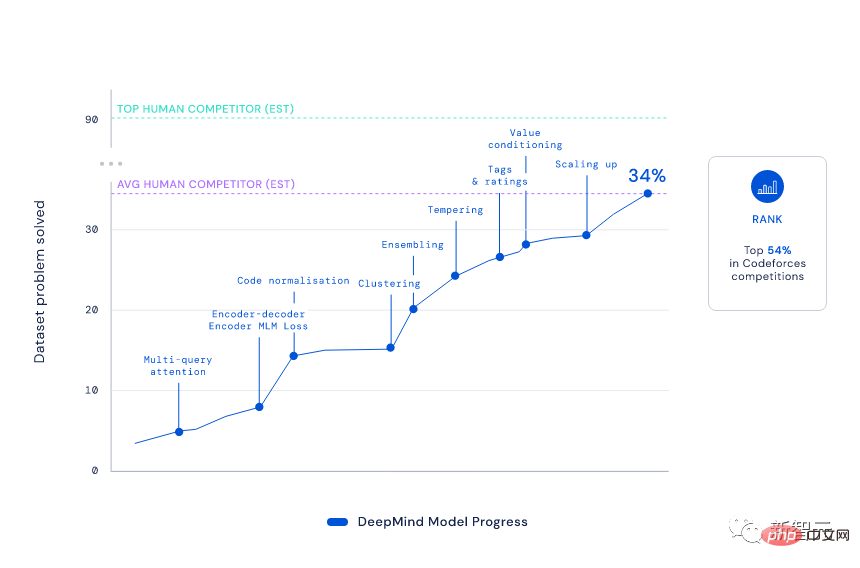
Sie müssen wissen, dass AlphaCode, um dieses Ranking zu erreichen, „fünf Level bestehen und sechs Generäle besiegen“ und verschiedene neue Probleme lösen muss, die kritisches Denken, Logik, Algorithmen, Codierung und Verständnis natürlicher Sprache kombinieren.
Den Ergebnissen nach zu urteilen, hat AlphaCode nicht nur 29,6 % der Programmierprobleme im CodeContests-Datensatz gelöst, sondern 66 % davon wurden bereits bei der ersten Einreichung gelöst. (Die Gesamtzahl der Einreichungen ist auf 10 Mal begrenzt)
Im Vergleich dazu ist die Lösungsrate des traditionellen Transformer-Modells relativ niedrig und liegt nur im einstelligen Bereich.
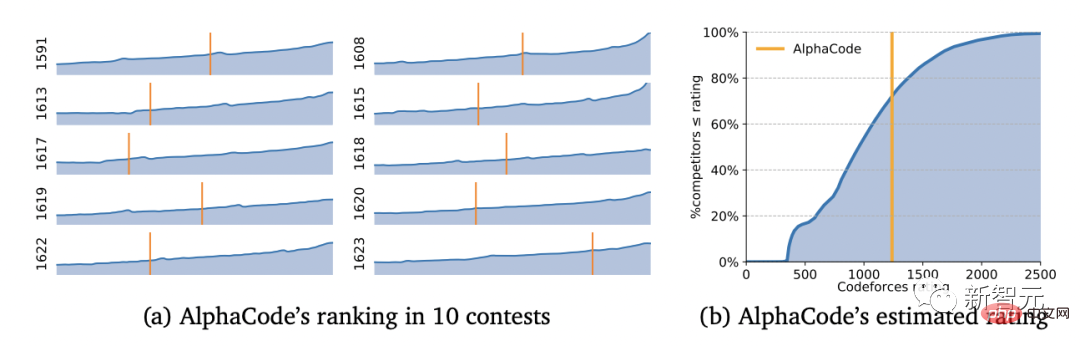
Sogar Codeforces-Gründer Mirzayanov war von diesem Ergebnis sehr überrascht.
Schließlich testen Programmierwettbewerbe die Fähigkeit, Algorithmen zu erfinden, was schon immer die Schwäche der KI und die Stärke des Menschen war.
Ich kann definitiv sagen, dass die Ergebnisse von AlphaCode meine Erwartungen übertroffen haben. Anfangs war ich skeptisch, denn selbst bei einfachen Wettbewerbsproblemen muss man den Algorithmus nicht nur implementieren, sondern auch erfinden (was der schwierigste Teil ist). AlphaCode hat sich für viele Menschen zu einem gewaltigen Gegner gemacht. Ich kann es kaum erwarten zu sehen, was die Zukunft bringt!
——Mike Mirzayanov, Gründer von Codeforces
Kann AlphaCode also die Jobs von Programmierern stehlen?
Natürlich noch nicht.
AlphaCode kann nur einfache Programmieraufgaben erledigen. Werden die Aufgaben komplexer und die Probleme „unvorhersehbarer“, ist AlphaCode, das nur Anweisungen in Codes übersetzt, hilflos.
Schließlich entspricht eine Punktzahl von 1238 aus einer bestimmten Perspektive dem Niveau eines Mittelschülers, der gerade das Programmieren lernt. Auf dieser Ebene stellt es für echte Programmierexperten keine Bedrohung dar.
Aber es besteht kein Zweifel daran, dass die Entwicklung dieser Art von Codierungsplattform einen enormen Einfluss auf die Produktivität der Programmierer haben wird.
Sogar die gesamte Programmierkultur kann sich ändern: Vielleicht ist der Mensch in Zukunft nur noch für die Formulierung von Problemen verantwortlich und die Aufgaben der Codegenerierung und -ausführung können dem maschinellen Lernen übergeben werden.
Wir wissen, dass maschinelles Lernen zwar große Fortschritte beim Generieren und Verstehen von Texten gemacht hat, der Großteil der KI jedoch immer noch auf einfache Mathematik- und Programmierprobleme beschränkt ist.
Was sie tun werden, ist, vorhandene Lösungen abzurufen und zu kopieren (ich glaube, jeder, der kürzlich ChatGPT gespielt hat, wird das gut verstehen).
Warum ist es für die KI so schwierig zu lernen, korrekte Programme zu generieren?
1. Um Code zu generieren, der eine bestimmte Aufgabe löst, müssen Sie in allen möglichen Zeichenfolgen suchen, und nur ein kleiner Teil davon entspricht einem effektiven korrekten Programm.
2. Die Bearbeitung eines einzelnen Zeichens kann das Verhalten des Programms völlig verändern oder sogar zum Absturz führen, und für jede Aufgabe gibt es viele verschiedene und gültige Lösungen.
Für extrem schwierige Programmierwettbewerbe muss die KI komplexe Beschreibungen in natürlicher Sprache verstehen; sie muss über Probleme nachdenken, die sie noch nie zuvor gesehen hat, und muss sich nicht nur Codeausschnitte merken, und zwar genau; vollständiger Code, der Hunderte von Zeilen lang sein kann.
Darüber hinaus muss die KI zur Bewertung des von ihr generierten Codes auch Aufgaben in einem umfassenden Satz versteckter Tests ausführen und die Ausführungsgeschwindigkeit sowie die Korrektheit von Randfällen überprüfen. ?? eine zufällig wiederholte Folge von s- und t-Buchstaben in eine andere Folge derselben Buchstaben unter Verwendung einer begrenzten Anzahl von Eingaben.
 Teilnehmer können nicht einfach neue Buchstaben eingeben, sondern müssen mit dem „Backspace“-Befehl mehrere Buchstaben aus der Originalzeichenfolge löschen. Die spezifischen Fragen lauten wie folgt:
Teilnehmer können nicht einfach neue Buchstaben eingeben, sondern müssen mit dem „Backspace“-Befehl mehrere Buchstaben aus der Originalzeichenfolge löschen. Die spezifischen Fragen lauten wie folgt:
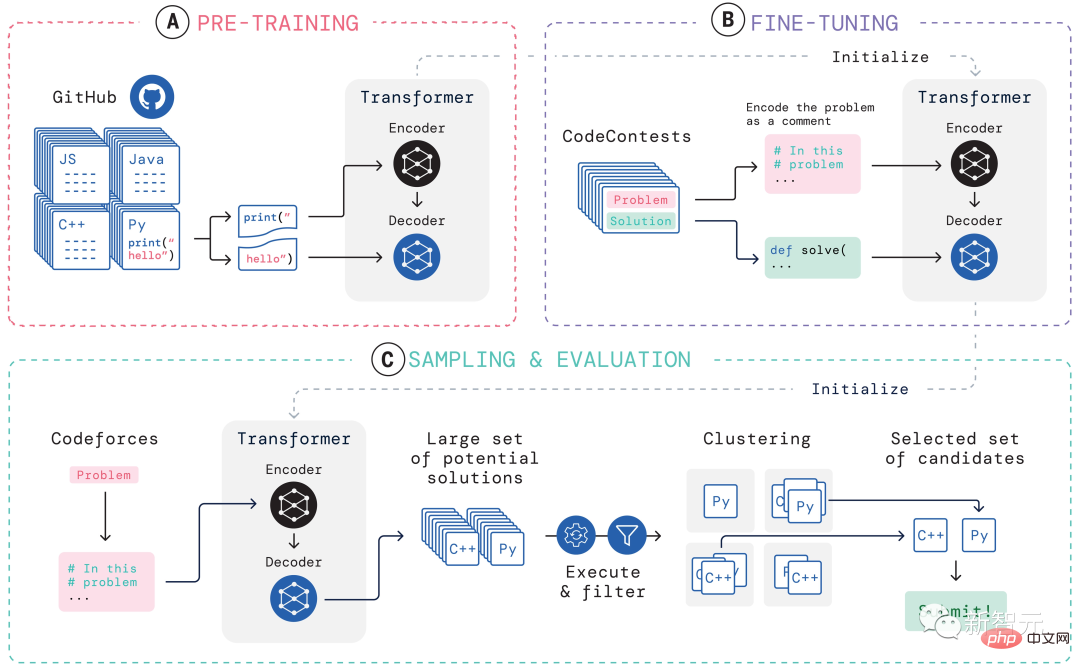
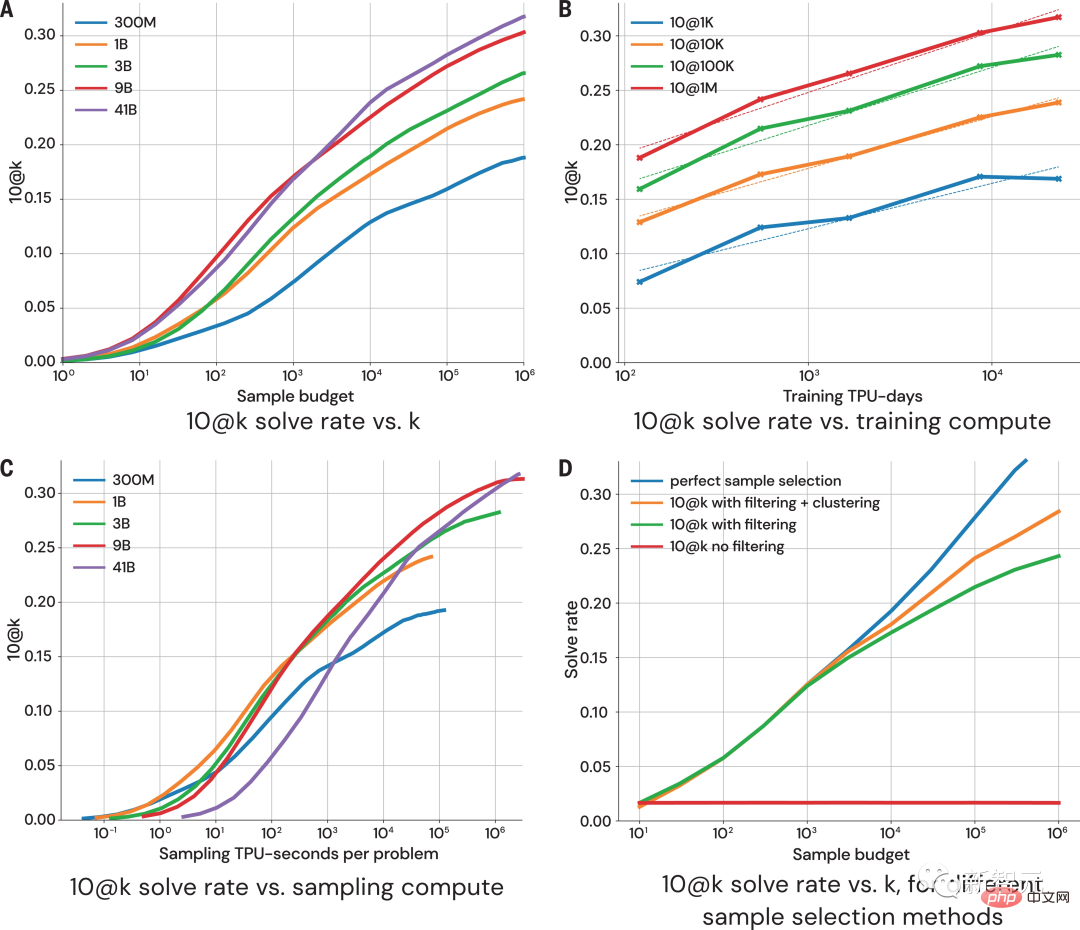
In dieser Hinsicht lautet die Lösung von AlphaCode wie folgt: Darüber hinaus sind die „Problemlösungsideen“ von AlphaCode keine Blackbox mehr, sondern können auch den Code und den Ort der Aufmerksamkeitshervorhebung anzeigen. Die größten Herausforderungen für AlphaCode bei der Teilnahme an Programmierwettbewerben sind: (i) muss in einem riesigen Programmraum gesucht werden, (ii) nur etwa 13.000 Beispielaufgaben erhalten für Schulungen und (iii) eine begrenzte Anzahl von Einsendungen pro Frage. Um diese Probleme zu lösen, ist der Aufbau des gesamten Lernsystems von AlphaCode in drei Glieder unterteilt: Vortraining, Feinabstimmung, Stichprobenziehung und Bewertung, wie in der obigen Abbildung dargestellt. Vortraining In der Vortrainingsphase wird das Modell mithilfe von 715 GB Code-Snapshots menschlicher Programmierer, die auf GitHub gesammelt wurden, vorab trainiert, und das entropieübergreifende nächste Token wird zur Vorhersage verwendet der Verlust. Während des Vortrainingsprozesses wird die Codedatei zufällig in zwei Teile geteilt, der erste Teil wird als Eingabe des Encoders verwendet und das Modell wird trainiert, um den zweiten Teil ohne den Encoder zu generieren. Dieses Vortraining erlernt einen starken Prior für die Kodierung, sodass eine anschließende aufgabenspezifische Feinabstimmung an einem kleineren Datensatz durchgeführt werden kann. Feinabstimmung In der Feinabstimmungsphase wurde das Modell anhand eines 2,6 GB großen, von DeepMind erstellten und als CodeContests öffentlich veröffentlichten Datensatzes zu wettbewerbsorientierten Programmierproblemen verfeinert und ausgewertet. Der CodeContests-Datensatz enthält Fragen und Testfälle. Das Trainingsset enthält 13.328 Fragen mit durchschnittlich 922,4 eingereichten Antworten pro Frage. Das Validierungsset und das Testset enthalten 117 bzw. 165 Fragen. Während der Feinabstimmung kodieren Sie die Problemstellung in natürlicher Sprache in Programmanmerkungen, sodass sie den während des Vortrainings angezeigten Dateien ähnlicher wird (die erweiterte Anmerkungen in natürlicher Sprache enthalten können) und verwenden Sie dieselbe Vorhersage für das nächste Token Verlust. Stichprobe Um die 10 besten Proben für die Einreichung auszuwählen, werden Filter- und Clustering-Methoden verwendet, um die Proben mithilfe der in der Problemstellung enthaltenen Beispieltests auszuführen und diejenigen zu entfernen, die diese Tests nicht bestehen. Filtern Sie fast 99 % der Modellproben heraus, gruppieren Sie die verbleibenden Kandidatenproben, führen Sie diese Proben auf der von einem separaten Transformatormodell generierten Eingabe aus und erzeugen Sie dieselbe Ausgabe auf den generierten Eingabeprogrammen, die in einer Kategorie gruppiert sind. Wählen Sie dann aus jedem der 10 größten Cluster eine Probe zur Einreichung aus. Intuitiv verhalten sich korrekte Programme identisch und bilden große Cluster, während falsche Programme auf unterschiedliche Weise versagen. Bewertung Die obige Abbildung zeigt, wie sich die Modellleistung mit größerer Stichprobengröße und Berechnungsmenge bei 10@k-Indikatoren ändert. Aus der Leistungsbewertung der Stichprobenergebnisse kamen die Forscher zu den folgenden vier Schlussfolgerungen: 1 Die Lösungsrate wächst logarithmisch linear mit größerer Stichprobengröße; 2 Besser Das Modell weist eine höhere Steigung auf Skalierungskurve; 3. Die Lösungsrate ist logarithmisch proportional zu mehr Berechnungen; 4. Rein „datengesteuert“ Es besteht kein Zweifel daran, dass die Einführung von AlphaCode einen Fortschritt in der Entwicklung von Modellen für maschinelles Lernen darstellt Ein wesentlicher Schritt. Interessanterweise enthält AlphaCode kein explizites integriertes Wissen über die Struktur von Computercode. Stattdessen basiert es auf einem rein „datengesteuerten“ Ansatz zum Schreiben von Code, bei dem die Struktur von Computerprogrammen einfach durch Beobachtung großer Mengen vorhandener Codes erlernt wird . Artikeladresse: https://www.science.org/doi/10.1126/science .add8258 Was AlphaCode bei konkurrierenden Programmieraufgaben besser macht als andere Systeme, hängt im Wesentlichen von zwei Hauptattributen ab: #🎜 🎜# 1. Trainingsdaten #🎜 🎜#Aber Computercode ist ein stark strukturiertes Medium, und Programme müssen einer definierten Syntax folgen und in verschiedenen Teilen der Lösung klare Vor- und Nachbedingungen schaffen. Die von AlphaCode beim Generieren von Code verwendete Methode ist genau die gleiche wie beim Generieren anderer Textinhalte – jeweils ein Token, und es wird erst nach dem gesamten Programm überprüft ist geschrieben. Bei entsprechender Daten- und Modellkomplexität kann AlphaCode kohärente Strukturen generieren. Das endgültige Rezept für dieses sequentielle Generierungsverfahren liegt jedoch tief in den Parametern von LLM vergraben und ist schwer zu fassen. Aber unabhängig davon, ob AlphaCode Programmierprobleme wirklich „verstehen“ kann, erreicht es bei Codierungswettbewerben das durchschnittliche menschliche Niveau. „Die Lösung von Programmierwettbewerbsproblemen ist eine sehr schwierige Sache und erfordert vom Menschen gute Programmierfähigkeiten und Kreativität bei der Problemlösung. Ich bin beeindruckt von AlphaCode.“ Ich bin begeistert von den Fortschritten, die in diesem Bereich gemacht werden, und ich bin gespannt, wie das Modell sein Anweisungsverständnis nutzt, um Code zu generieren und seine zufällige Erkundung zu steuern, um Lösungen zu schaffen 🎜# - Petr Mitrichev, Google-Softwareentwickler und erstklassiger Wettbewerbsprogrammierer AlphaCode wird im Programmierwettbewerb unter den besten 54 % genannt, was beweist das Potenzial von Deep-Learning-Modellen bei Aufgaben, die kritisches Denken erfordern. Diese Modelle nutzen auf elegante Weise modernes maschinelles Lernen, um Lösungen für Probleme als Code auszudrücken, und gehen dabei auf die Wurzeln der symbolischen Argumentation der KI vor Jahrzehnten zurück. Und das ist erst der Anfang. In Zukunft wird eine leistungsfähigere KI geboren, um Probleme zu lösen. Vielleicht ist dieser Tag nicht mehr weit. 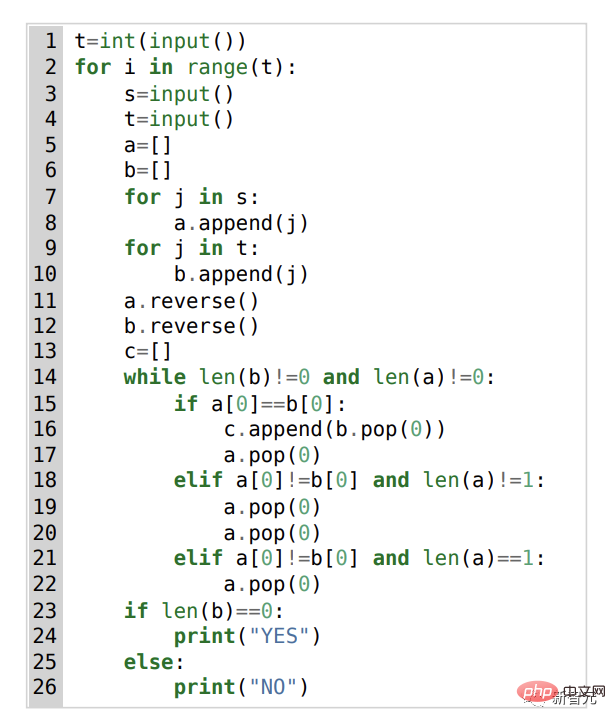
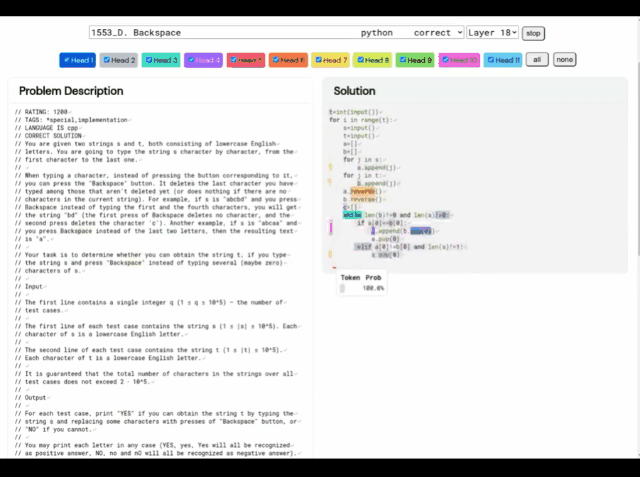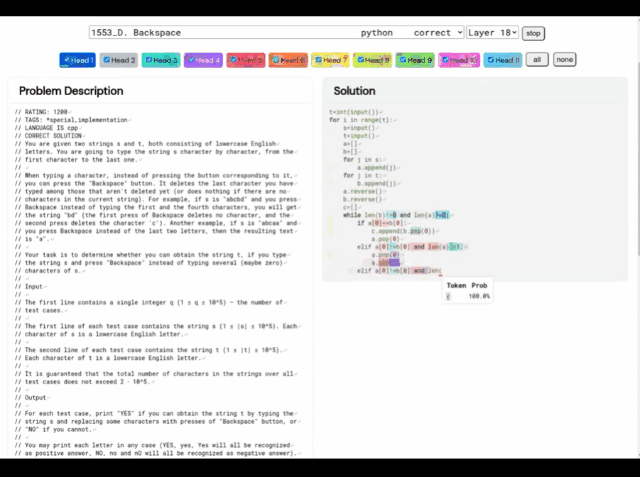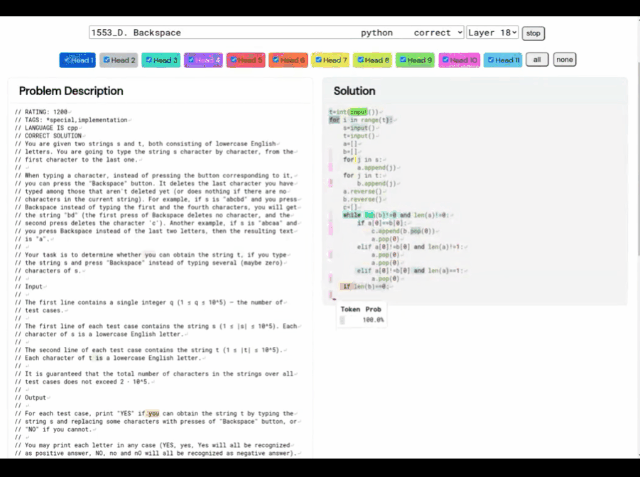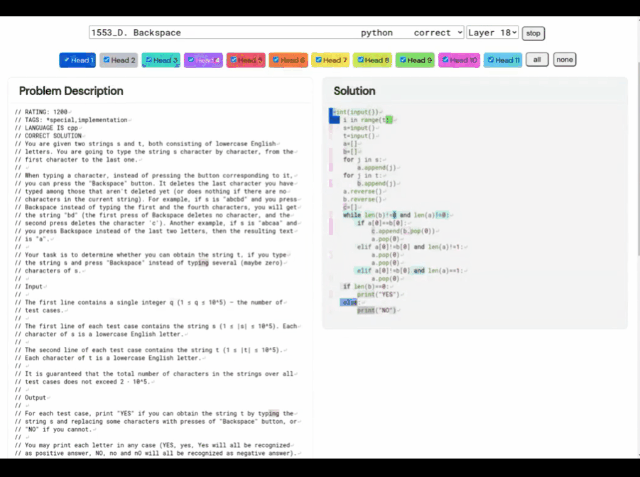
Das Lernsystem von AlphaCode

Das obige ist der detaillierte Inhalt vonSuperprogrammierte KI erscheint auf dem Cover von Science! AlphaCode-Programmierwettbewerb: Die Hälfte der Programmierer nimmt teil. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So beheben Sie den Fehler aufgrund einer ungültigen MySQL-ID
So beheben Sie den Fehler aufgrund einer ungültigen MySQL-ID
 So löschen Sie leere Seiten in Word, ohne dass sich dies auf andere Formate auswirkt
So löschen Sie leere Seiten in Word, ohne dass sich dies auf andere Formate auswirkt
 js-Split-Nutzung
js-Split-Nutzung
 Verwendung der Stripslashes-Funktion
Verwendung der Stripslashes-Funktion
 So kopieren Sie eine Excel-Tabelle, um sie auf die gleiche Größe wie das Original zu bringen
So kopieren Sie eine Excel-Tabelle, um sie auf die gleiche Größe wie das Original zu bringen
 Einführung in die Verwendung von vscode
Einführung in die Verwendung von vscode
 Linux fügt die Update-Quellenmethode hinzu
Linux fügt die Update-Quellenmethode hinzu
 Grundlegende Verwendung der Insert-Anweisung
Grundlegende Verwendung der Insert-Anweisung








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



