

 Technologie-Peripheriegeräte
KI
Sanfte Diffusion: Das neue Framework von Google plant, lernt und probiert einen universellen Diffusionsprozess korrekt aus
Technologie-Peripheriegeräte
KI
Sanfte Diffusion: Das neue Framework von Google plant, lernt und probiert einen universellen Diffusionsprozess korrekt aus
Sanfte Diffusion: Das neue Framework von Google plant, lernt und probiert einen universellen Diffusionsprozess korrekt aus

Wir wissen, dass punktebasierte Modelle und entrauschende Diffusions-Wahrscheinlichkeitsmodelle (DDPM) zwei leistungsstarke Arten generativer Modelle sind, die Stichproben durch Umkehrung des Diffusionsprozesses generieren. Diese beiden Arten von Modellen wurden in der Arbeit „Score-based generative modeling through stochastic Differential Equations“ von Yang Song und anderen Forschern in einem einzigen Rahmenwerk zusammengefasst und sind weithin als Diffusionsmodelle bekannt.
Gegenwärtig hat das Diffusionsmodell große Erfolge in einer Reihe von Anwendungen erzielt, darunter Bild-, Audio- und Videoerzeugung und die Lösung inverser Probleme. In der Arbeit „Elucidating the design space of diffusionbased generative models“ analysierten Forscher wie Tero Karras den Designraum des Diffusionsmodells und identifizierten drei Phasen, nämlich i) Auswahl der Planung des Rauschpegels, ii) Auswahl der Netzwerkparameter. isierung (jede Parametrisierung erzeugt eine andere Verlustfunktion), iii) Entwurf des Abtastalgorithmus.
In einem kürzlich von Google Research und UT-Austin gemeinsam durchgeführten arXiv-Artikel „Soft Diffusion: Score Matching for General Corruptions“ glauben mehrere Forscher, dass das Diffusionsmodell noch einen wichtigen Schritt hat: Korruption. Im Allgemeinen handelt es sich bei Korruption um einen Prozess, bei dem Rauschen unterschiedlicher Amplitude hinzugefügt wird, und bei DDMP ist auch eine Neuskalierung erforderlich. Obwohl Versuche unternommen wurden, unterschiedliche Distributionen für die Verbreitung zu nutzen, fehlt noch immer ein allgemeiner Rahmen. Daher schlugen die Forscher einen Entwurfsrahmen für ein Diffusionsmodell für einen allgemeineren Schadensprozess vor.
Konkret schlugen sie ein neues Trainingsziel namens Soft Score Matching und eine neuartige Stichprobenmethode Momentum Sampler vor. Theoretische Ergebnisse zeigen, dass Soft Score MatchIng für Schadensprozesse, die Regelmäßigkeitsbedingungen erfüllen, in der Lage ist, deren Scores (d. h. Wahrscheinlichkeitsgradienten) zu lernen, die durch Diffusion jedes Bild in jedes Bild mit einer Wahrscheinlichkeit ungleich Null umwandeln müssen.
Im experimentellen Teil trainierten die Forscher das Modell auf CelebA und CIFAR-10. Das auf CelebA trainierte Modell erreichte den SOTA-FID-Score des linearen Diffusionsmodells – 1,85. Gleichzeitig ist das von den Forschern trainierte Modell deutlich schneller als das Modell, das mit der ursprünglichen Gaußschen Entrauschungsdiffusion trainiert wurde.

Papieradresse: https://arxiv.org/pdf/2209.05442.pdf
Übersicht über die Methode
Im Allgemeinen werden Diffusionsmodelle durch Umkehrung des Schadensprozesses mit allmählich zunehmendem Schaden erzeugt Rauschbild. Die Forscher zeigen, wie man lernen kann, die Diffusion durch lineare deterministische Degradation und stochastisches additives Rauschen umzukehren.

Konkret demonstrierten die Forscher ein Framework zum Training eines Diffusionsmodells mithilfe eines allgemeineren Schadensmodells, das aus drei Teilen besteht, nämlich dem neuen Trainingsziel Soft Score Matching, der neuartigen Stichprobenmethode Momentum Sampler und der Planung des Schadensmechanismus.
Schauen wir uns zunächst das Trainingsziel Soft Score Matching an. Der Name ist von Soft Filtering inspiriert, einem Begriff aus der Fotografie, der sich auf einen Filter bezieht, der feine Details entfernt. Es lernt den Anteil eines herkömmlichen linearen Schadensprozesses auf nachweisbare Weise, integriert außerdem einen Filterprozess in das Netzwerk und trainiert das Modell, um Bilder nach dem Schaden vorherzusagen, die mit Diffusionsbeobachtungen übereinstimmen.
Solange die Diffusion jedem sauberen, beschädigten Bildpaar eine Wahrscheinlichkeit ungleich Null zuweist, kann dieses Trainingsziel beweisen, dass die Punktzahl gelernt ist. Darüber hinaus ist diese Bedingung immer dann erfüllt, wenn im Schaden zusätzliches Rauschen vorhanden ist.
Konkret untersuchten die Forscher den Schadensprozess in den folgenden Formen.

Dabei entdeckten die Forscher, dass Rauschen sowohl empirisch (also für bessere Ergebnisse) als auch theoretisch (also für das Lernen von Brüchen) wichtig ist. Dies ist auch ein wesentlicher Unterschied zu Cold Diffusion, einer parallelen Arbeit, die deterministische Korruption umkehrt.
Die zweite ist die Sampling-Methode Momentum Sampling. Die Forscher zeigten, dass die Wahl des Probenehmers einen erheblichen Einfluss auf die Qualität der erzeugten Proben hat. Sie schlugen den Momentum Sampler vor, um einen universellen linearen Schadensprozess umzukehren. Der Sampler nutzt konvexe Schadenskombinationen mit unterschiedlichen Diffusionsniveaus und ist von Impulsmethoden in der Optimierung inspiriert.
Diese Stichprobenmethode ist von der kontinuierlichen Formulierung des Diffusionsmodells inspiriert, das in der oben genannten Arbeit von Yang Song et al. vorgeschlagen wurde. Der Algorithmus für Momentum Sampler ist unten dargestellt.

Die folgende Abbildung zeigt visuell den Einfluss verschiedener Probenahmemethoden auf die Qualität der generierten Proben. Das mit Naive Sampler aufgenommene Bild auf der linken Seite scheint sich zu wiederholen und es mangelt an Details, während der Momentum Sampler auf der rechten Seite die Sampling-Qualität und den FID-Score deutlich verbessert.

Zum Schluss noch die Terminplanung. Selbst wenn die Art der Verschlechterung vordefiniert ist (z. B. Unschärfe), ist die Entscheidung, wie viel Schaden bei jedem Diffusionsschritt verursacht werden soll, nicht trivial. Die Forscher schlagen ein prinzipielles Werkzeug zur Steuerung der Gestaltung von Schadensprozessen vor. Um den Zeitplan zu ermitteln, minimieren sie den Wasserstein-Abstand zwischen Verteilungen entlang des Pfads. Intuitiv wünschen sich Forscher einen reibungslosen Übergang von einer vollständig beschädigten Verteilung zu einer sauberen Verteilung.
Experimentelle Ergebnisse
Die Forscher bewerteten die vorgeschlagene Methode anhand von CelebA-64 und CIFAR-10, die beide Standardbasislinien für die Bilderzeugung sind. Der Hauptzweck des Experiments besteht darin, die Rolle der Schadensart zu verstehen.
Die Forscher versuchten zunächst, Unschärfe und Rauschen mit niedriger Amplitude zur Schädigung zu nutzen. Die Ergebnisse zeigen, dass ihr vorgeschlagenes Modell SOTA-Ergebnisse auf CelebA erreicht, d. h. einen FID-Score von 1,85, und damit alle anderen Methoden übertrifft, die nur Rauschen hinzufügen und das Bild möglicherweise neu skalieren. Darüber hinaus beträgt der auf CIFAR-10 erzielte FID-Score 4,64, was konkurrenzfähig ist, obwohl er SOTA nicht erreicht.

Darüber hinaus schnitt die Methode des Forschers bei den CIFAR-10- und CelebA-Datensätzen auch bei einer anderen Metrik, der Stichprobenzeit, besser ab. Ein weiterer zusätzlicher Vorteil sind erhebliche Rechenvorteile. Das Entschärfen (fast kein Rauschen) scheint eine effizientere Manipulation im Vergleich zu Methoden zur Rauschunterdrückung bei der Bilderzeugung zu sein.
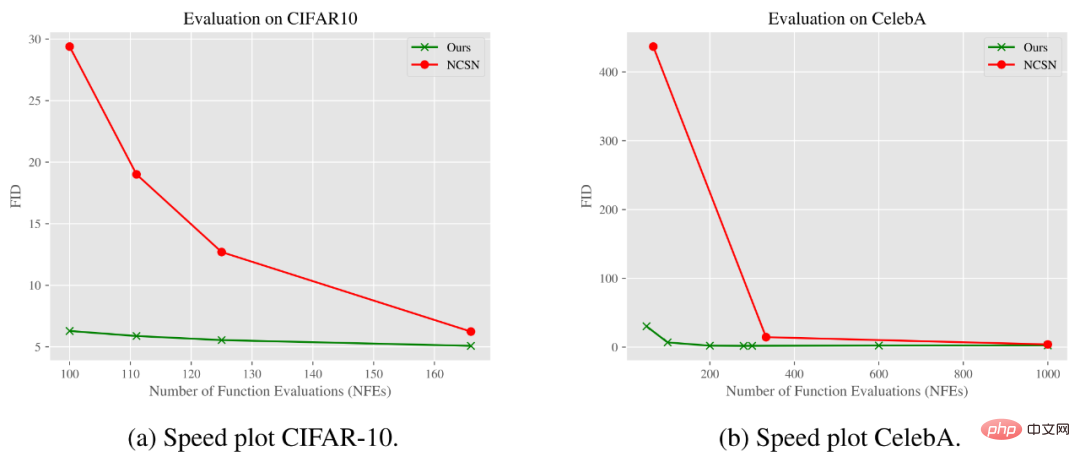
Das Diagramm unten zeigt, wie sich der FID-Score mit der Anzahl der Funktionsbewertungen (NFE) ändert. Wie aus den Ergebnissen hervorgeht, kann unser Modell mit deutlich weniger Schritten für die CIFAR-10- und CelebA-Datensätze die gleiche oder eine bessere Qualität als das Standard-Gaußsche Rauschunterdrückungs-Diffusionsmodell erreichen.
Das obige ist der detaillierte Inhalt vonSanfte Diffusion: Das neue Framework von Google plant, lernt und probiert einen universellen Diffusionsprozess korrekt aus. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Wie man Zookeeper Performance -Tuning auf Debian betreibt
Apr 02, 2025 am 07:42 AM
Wie man Zookeeper Performance -Tuning auf Debian betreibt
Apr 02, 2025 am 07:42 AM
In diesem Artikel wird beschrieben, wie die Zookeeper -Leistung auf Debian -Systemen optimiert werden kann. Wir beraten Hardware, Betriebssystem, Zookeeper -Konfiguration und Überwachung. 1. Optimieren Sie die Speichermedien-Upgrade auf Systemebene: Das Ersetzen herkömmlicher mechanischer Festplatten durch SSD-Solid-State-Laufwerke verbessert die E/A-Leistung erheblich und verringert die Zugriffslatenz. Deaktivieren Sie die Swap -Partitionierung: Durch Anpassung der Kernelparameter reduzieren Sie die Abhängigkeit von Swap -Partitionen und vermeiden Sie Leistungsverluste, die durch häufige Speicher- und Festplatten -Swaps verursacht werden. Obergrenze für den Dateideskriptor: Erhöhen Sie die Anzahl der Dateideskriptoren, die gleichzeitig vom System geöffnet werden dürfen, um zu vermeiden, dass Ressourcenbeschränkungen die Verarbeitungseffizienz von Zookeeper beeinflussen. 2. Zookeeper -Konfigurationsoptimierungszoo.CFG -Dateikonfiguration
 So führen Sie Oracle -Sicherheitseinstellungen auf Debian durch
Apr 02, 2025 am 07:48 AM
So führen Sie Oracle -Sicherheitseinstellungen auf Debian durch
Apr 02, 2025 am 07:48 AM
Um die Sicherheit der Oracle -Datenbank für das Debian -System zu stärken, müssen viele Aspekte beginnen. Die folgenden Schritte bieten ein Framework für die sichere Konfiguration: 1. Oracle Database Installation und Erstkonfigurationssystemvorbereitung: Stellen Sie sicher, dass das Debian -System auf die neueste Version aktualisiert wurde, die Netzwerkkonfiguration korrekt ist und alle erforderlichen Softwarepakete installiert sind. Es wird empfohlen, auf offizielle Dokumente oder zuverlässige Ressourcen von Drittanbietern für die Installation zu verweisen. Benutzer und Gruppen: Erstellen Sie eine dedizierte Oracle -Benutzergruppe (z. B. Oinstall, DBA, Backupdba) und setzen Sie geeignete Berechtigungen dafür. 2. Sicherheitsbeschränkungen setzen
 So stellen Sie den Debian Mail Server wieder her
Apr 02, 2025 am 07:33 AM
So stellen Sie den Debian Mail Server wieder her
Apr 02, 2025 am 07:33 AM
Detaillierte Schritte zum Wiederherstellen von Debian Mail Server In diesem Artikel können Sie den Debian -Mailserver wiederherstellen. Bevor Sie beginnen, ist es wichtig, sich an die Bedeutung der Datensicherung zu erinnern. Wiederherstellungsschritte: Sicherungsdaten: Stellen Sie sicher, dass Sie alle wichtigen E -Mail -Daten und Konfigurationsdateien sichern, bevor Sie Wiederherstellungsvorgänge ausführen. Dadurch wird sichergestellt, dass Sie eine Fallback -Version haben, wenn während des Wiederherstellungsprozesses Probleme auftreten. Protokolldateien überprüfen: Überprüfen Sie die E -Mail -Server -Protokolldateien (z. B. /var/log/mail.log) auf Fehler oder Ausnahmen. Protokolldateien bieten häufig wertvolle Hinweise zur Ursache des Problems. STOP -Service: Stoppen Sie den Mail -Dienst, um weitere Datenversorgung zu verhindern. Verwenden Sie den folgenden Befehl: SU
 So überwachen Sie die Systemleistung durch Debian -Protokolle
Apr 02, 2025 am 08:00 AM
So überwachen Sie die Systemleistung durch Debian -Protokolle
Apr 02, 2025 am 08:00 AM
Das Mastering Debian -Systemprotokollüberwachung ist der Schlüssel für den effizienten Betrieb und die Wartung. Es kann Ihnen helfen, die Betriebsbedingungen des Systems rechtzeitig zu verstehen, Fehler schnell zu lokalisieren und die Systemleistung zu optimieren. In diesem Artikel werden mehrere häufig verwendete Überwachungsmethoden und -werkzeuge eingeführt. Überwachung von Systemressourcen mit dem SysStat -Toolkit Das SysStat Toolkit bietet eine Reihe leistungsstarker Befehlszeilen -Tools zum Sammeln, Analysieren und Berichten verschiedener Systemressourcenmetriken, einschließlich CPU -Last, Speicherverbrauch, Festplatten -E/O, Netzwerkdurchsatz usw.. MPStat: Statistik von Multi-Core-CPUs. Pidsta
 Wie man Debian Syslog behebt
Apr 02, 2025 am 09:00 AM
Wie man Debian Syslog behebt
Apr 02, 2025 am 09:00 AM
Syslog für Debian Systems ist ein wichtiges Tool für Systemadministratoren zur Diagnose von Problemen. Dieser Artikel enthält einige Schritte und Befehle, um gemeinsame Syslog-Probleme zu beheben: 1. Log-Anzeigen von Echtzeit-Anzeigen des neuesten Protokolls: Tail-f/var/log/syslog-Kernelprotokolle (Startfehler und Treiberprobleme): DMESG verwendet JournalCTL (Debian8 und höher, Systemd-System): Journalctl-B (Anzeigen von Afterup-Logs), JournalCtl), JournalCtl (Debian8), Systemd-System): Journalctl-B (Anzeigen von Afterup-Logs). 2. Überwachungs- und Betrachtungsverfahren und Ressourcennutzung: PSAUX (Finden Sie hochressourcen
 Was ist die Rotationsstrategie für Golang -Protokolle auf Debian
Apr 02, 2025 am 08:39 AM
Was ist die Rotationsstrategie für Golang -Protokolle auf Debian
Apr 02, 2025 am 08:39 AM
In Debian Systems stützt sich die Protokollrotation von GO normalerweise auf Bibliotheken von Drittanbietern und nicht auf die Funktionen, die mit Go-Standardbibliotheken ausgestattet sind. Lumberjack ist eine häufig verwendete Option. Es kann mit verschiedenen Protokoll -Frameworks (z. B. ZAP und LOGRUS) verwendet werden, um die automatische Rotation und Komprimierung von Protokolldateien zu realisieren. Hier ist eine Beispielkonfiguration mit den Lumberjack- und Zap -Bibliotheken: PackageMainimport ("gopkg.in/natefinch/lumberjack.v2" "go.uber.org/zap"
 Warum ist es notwendig, Zeiger zu verabschieden, wenn sie GO- und Viper -Bibliotheken verwenden?
Apr 02, 2025 pm 04:00 PM
Warum ist es notwendig, Zeiger zu verabschieden, wenn sie GO- und Viper -Bibliotheken verwenden?
Apr 02, 2025 pm 04:00 PM
Go Zeigersyntax und Probleme bei der Verwendung der Viper -Bibliothek bei der Programmierung in Go -Sprache. Es ist entscheidend, die Syntax und Verwendung von Zeigern zu verstehen, insbesondere in ...
 Wie kann ich öffentliche Daten für alle Controller im Go Gin Framework zur Verfügung stellen?
Apr 02, 2025 am 10:21 AM
Wie kann ich öffentliche Daten für alle Controller im Go Gin Framework zur Verfügung stellen?
Apr 02, 2025 am 10:21 AM
Wie können alle Controller öffentliche Daten im Sogin -Framework erhalten? Verwenden Sie GO ...
