


目录
接着将时间维度引入潜在空间 DM 、并在编码图像序列(即视频)上仅训练这些时间层的同时固定预训练空间层,从而将 LDM 图像生成器转换为视频生成器(下图左).最后以类似方式微调 LDM 的解码器以实现像素空间中的时间一致性(下图右) Größe: 1280 x 2048, Größe: 4,7 Zoll -4: Verbesserung des visuellen Sprachverständnisses mit erweiterten großen Sprachmodellen文地址:https:// minigpt-4.github.io/
Beispiel zeigt: Erstellen einer Website aus einer Skizze.

Empfehlung: Fast 10.000 Sterne in 3 Tagen, erleben Sie die GPT-4-Bilderkennungsfunktion ohne Unterschied, MiniGPT-4-Bild-Chat und Skizzen zum Erstellen einer Website. ?? com/file/d/10iR5hKwFqAKhL3umx8muOWSRm7hs5FqX/view
Zusammenfassung:
Um groß angelegte Ausrichtungsforschung zu demokratisieren, haben Forscher von Institutionen wie LAION AI (das die von Stable Diffusion verwendeten Open-Source-Daten bereitstellt) gesammelt Durch eine große Menge an textbasiertem Input und Feedback entsteht OpenAssistant Conversations, ein vielfältiger und einzigartiger Datensatz, der speziell für das Training von Sprachmodellen oder anderen KI-Anwendungen entwickelt wurde.OpenAssistant Conversations-Daten werden über die Web-App-Schnittstelle erfasst und bestehen aus fünf Schritten: Eingabeaufforderung, Eingabeaufforderung markieren, Antwortnachricht als Eingabeaufforderung oder Assistent hinzufügen, Antwort markieren und Antwort des Assistenten bewerten.
Empfohlen: ChatGPT, die weltweit größte Open-Source-Alternative.
Papier 4: Inpaint Anything: Segment Anything Meets Image Inpainting
Autoren: Tao Yu, Runseng Feng usw.
Papieradresse: http://arxiv.org/ abs/ 2304.06790
Zusammenfassung:
Das Forschungsteam der University of Science and Technology of China und des Eastern Institute of Technology schlug das „Inpaint Anything“ (IA)-Modell vor, das auf SAM (Segment Anything Model) basiert. Im Gegensatz zu herkömmlichen Bildreparaturmodellen erfordert das IA-Modell keine detaillierten Vorgänge zum Generieren von Masken und unterstützt das Markieren ausgewählter Objekte mit einem Klick. IA kann alles entfernen (Alles entfernen), alles füllen (Alles füllen) und alles ersetzen (Szenario). Anything) deckt eine Vielzahl typischer Bildreparatur-Anwendungsszenarien ab, einschließlich Zielentfernung, Zielfüllung, Hintergrundersetzung usw.IA hat drei Hauptfunktionen: (i) Alles entfernen: Benutzer müssen nur auf das Objekt klicken, das sie entfernen möchten, und IA entfernt das Objekt, ohne eine Spur zu hinterlassen, wodurch eine effiziente „magische Beseitigung“ erreicht wird : Gleichzeitig kann der Benutzer IA über Texteingabeaufforderungen (Texteingabeaufforderung) weiter mitteilen, was er in das Objekt einfügen möchte, und IA steuert dann das eingebettete AIGC-Modell (AI-Generated Content) (z. B. Stable Diffusion [2 ]) generiert entsprechende inhaltsgefüllte Objekte, um nach Belieben eine „Inhaltserstellung“ zu erreichen; (iii) Alles ersetzen: Der Benutzer kann auch klicken, um die Objekte auszuwählen, die beibehalten werden müssen, und Textaufforderungen verwenden, um IA mitzuteilen, dass sie ersetzt werden möchten die Objekte Sie können den Hintergrund des Objekts durch den angegebenen Inhalt ersetzen, um eine lebendige „Umwelttransformation“ zu erreichen. Der Gesamtrahmen von IA ist in der folgenden Abbildung dargestellt:
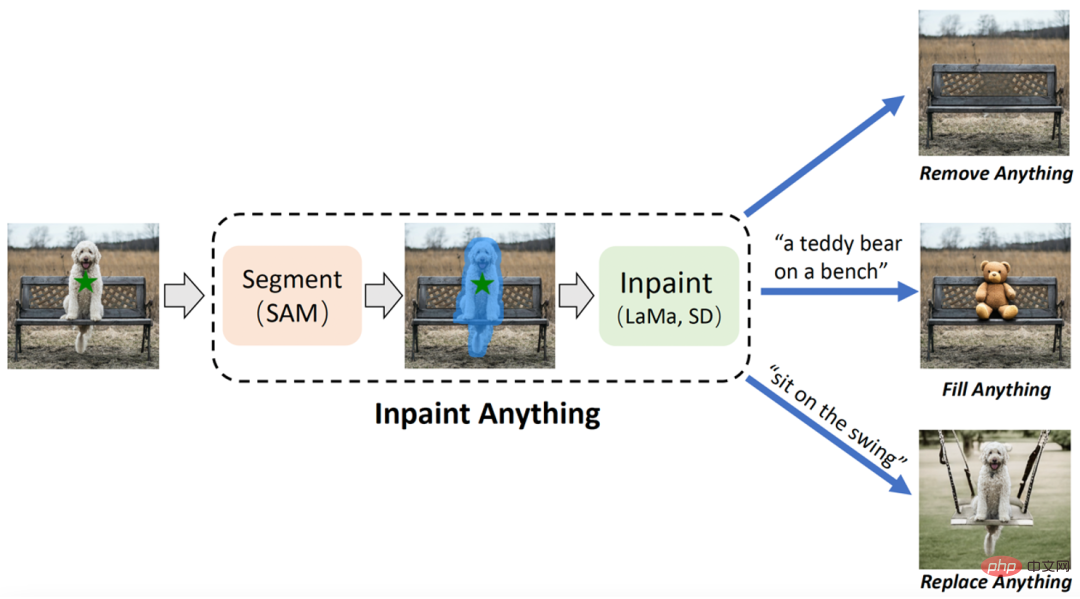
Empfehlung: Keine Feinmarkierung erforderlich. Klicken Sie auf das Objekt, um Objektentfernung, Inhaltsfüllung und Szenenersetzung zu erreichen.
Aufsatz 5: Semantische Segmentierung des offenen Wortschatzes mit maskenadaptiertem CLIP
Zusammenfassung: Meta und UTAustin haben gemeinsam ein neues offenes Sprachstilmodell (Open-Vocabulary Segmentation, OVSeg) vorgeschlagen, das es dem Segment Anything-Modell ermöglicht, die zu trennenden Kategorien zu kennen .
Aus Sicht der Wirkung kann OVSeg mit Segment Anything kombiniert werden, um eine feinkörnige Segmentierung offener Sprache abzuschließen. Identifizieren Sie beispielsweise in Abbildung 1 unten die Blumenarten: Sonnenblumen, weiße Rosen, Chrysanthemen, Nelken, grüne Dianthus.

Empfohlen: Meta/UTAustin schlägt ein neues Segmentierungsmodell für offene Klassen vor.
Papier 6: Plan4MC: Kompetenzverstärkungslernen und -planung für Open-World-Minecraft-Aufgaben
Zusammenfassung: Ein Team der Peking-Universität und des Beijing Zhiyuan Artificial Intelligence Research Institute schlug Plan4MC vor, eine Methode zur effizienten Lösung von Minecraft-Multitasking ohne Expertendaten. Der Autor kombiniert verstärkendes Lernen und Planungsmethoden, um die Lösung komplexer Aufgaben in zwei Teile zu zerlegen: das Erlernen grundlegender Fähigkeiten und die Fähigkeitsplanung. Die Autoren verwenden intrinsische Lernmethoden zur Belohnungsverstärkung, um drei Arten feinkörniger Grundkompetenzen zu trainieren. Der Agent verwendet ein umfangreiches Sprachmodell, um ein Fähigkeitsbeziehungsdiagramm zu erstellen, und erhält durch die Suche im Diagramm eine Aufgabenplanung. Im experimentellen Teil kann Plan4MC derzeit 24 komplexe und vielfältige Aufgaben erledigen, und die Erfolgsquote wurde im Vergleich zu allen Basismethoden erheblich verbessert.

Empfohlen: Verwenden Sie ChatGPT und Verstärkungslernen, um „Minecraft“ zu spielen. Plan4MC bewältigt 24 komplexe Aufgaben.
Aufsatz 7: T2Ranking: Ein groß angelegter chinesischer Benchmark für das Passage-Ranking
Zusammenfassung: Absatzsortierung ist ein sehr wichtiges Problem im Bereich Information Retrieval Es handelt sich um ein wichtiges und herausforderndes Thema, das in Wissenschaft und Industrie große Aufmerksamkeit erregt hat. Die Wirksamkeit des Absatz-Ranking-Modells kann die Zufriedenheit der Suchmaschinennutzer verbessern und beim Informationsabruf bezogene Anwendungen wie Frage- und Antwortsysteme, Leseverständnis usw. unterstützen. In diesem Zusammenhang wurden einige Benchmark-Datensätze wie MS-MARCO, DuReader_retrieval usw. erstellt, um entsprechende Forschungsarbeiten zur Absatzsortierung zu unterstützen. Die meisten häufig verwendeten Datensätze konzentrieren sich jedoch auf englische Szenen. Bei chinesischen Szenen weisen die vorhandenen Datensätze Einschränkungen hinsichtlich der Datenskala, der feinkörnigen Benutzeranmerkung und der Lösung des Problems falsch negativer Beispiele auf. Vor diesem Hintergrund wurde in dieser Studie ein neuer Benchmark-Datensatz für das Absatzranking in China erstellt, der auf echten Suchprotokollen basiert: T2Ranking.
T2Ranking besteht aus mehr als 300.000 echten Suchanfragen und 2 Millionen Internetabsätzen und enthält 4-stufige, feinkörnige Relevanzanmerkungen, die von professionellen Kommentatoren bereitgestellt werden. Die aktuellen Daten und einige Basismodelle wurden auf Github veröffentlicht und die relevanten Forschungsarbeiten wurden von SIGIR 2023 als Ressourcenpapier akzeptiert.
Empfohlen: 300.000 echte Abfragen, 2 Millionen Internetabsätze, Benchmark-Datensatz für das chinesische Absatzranking veröffentlicht.
Heart of Machine kooperiert mit der von Chu Hang, Luo Ruotian und Mei Hongyuan initiierten ArXiv Weekly Radiostation und wählt diese Woche weitere wichtige Papiere auf der Grundlage von 7 Papieren aus, darunter NLP, CV, ML 10 ausgewählte Papiere In jedem Bereich werden abstrakte Einführungen zu den Papieren in Audioform bereitgestellt. Die Details lauten wie folgt:
Die 10 ausgewählten NLP-Papiere dieser Woche sind:
1 von HLTPR@RWTH für DSTC9 und DSTC10. (von Hermann Ney) Shen)
3. Über die Robustheit der aspektbasierten Stimmungsanalyse: Modell, Daten und Training neu denken (von Tat-Seng Chua)
4. Stochastische Papageien sind einfach zu finden Fein abgestimmt und schwer zu erkennen mit anderen LLMs. (von Rachid Guerraoui) )
6. MER 2023: Multi-Label-Lernen, Modalitätsrobustheit und halbüberwachtes Lernen (von Meng Wang, Erik Cambria, Guoying Zhao)
7. GeneGPT: Lehren großer Sprachmodelle zur Verwendung von NCBI Web-APIs. (von Zhiyong Lu)
8. Eine Umfrage zur biomedizinischen Textzusammenfassung mit vorab trainiertem Sprachmodell Lakes (von Christopher Ré) Align-DETR: Verbesserung der DETR mit einfachem IoU-bewusstem BCE-Verlust (von Xiangyu Zhang)
3 4. Lernsituations-Hypergraphen für die Beantwortung von Videofragen. (von Mubarak Shah) 5. Videogenerierung über einen einzelnen Clip hinaus. (von Ming-Hsuan Yang) 6. Eine datenzentrierte Lösung zur inhomogenen Dunstentfernung mittels Vision Transformer. (von Huan Liu) 7. Neuromorpher optischer Fluss und Echtzeitimplementierung mit Ereigniskameras. (von Luca Benini, Davide Scaramuzza) 8. Sprachgesteuerte lokale Infiltration für den interaktiven Bildabruf. (von Lei Zhang) 9. LipsFormer: Einführung von Lipschitz Continuity in Vision Transformers. (von Lei Zhang) 10. UVA: Auf dem Weg zu einem einheitlichen volumetrischen Avatar für Ansichtssynthese, Posenrendering, Geometrie und Texturbearbeitung. (von Dacheng Tao) 本周 10 篇 ML 精选论文是: 1. Verbindung von RL-Theorie und -Praxis mit dem effektiven Horizont. (von Stuart Russell) 2. Auf dem Weg zu transparenten und robusten datengesteuerten Leistungskurvenmodellen für Windkraftanlagen. (von Klaus-Robert Müller) 3. Kontinuierliches Lernen in der offenen Welt: Neuheitserkennung und kontinuierliches Lernen vereinen. (von Bing Liu) 4. Das Lernen in latenten Räumen verbessert die Vorhersagegenauigkeit tiefer neuronaler Operatoren. (von George Em Karniadakis) 5. Entkoppeln Sie graphische neuronale Netze: Trainieren Sie mehrere einfache GNNs gleichzeitig statt eines. (von Xuelong Li) 6. Generalisierungs- und Schätzfehlergrenzen für modellbasierte neuronale Netze. (von Yonina C. Eldar) 7. RAFT: Prämiertes FineTuning für die generative Foundation-Modellausrichtung. (von Tong Zhang) 8. Adaptive Konsensoptimierungsmethode für GANs. (von Pawan Kumar) 9. Winkelbasierte dynamische Lernrate für den Gradientenabstieg. (von Pawan Kumar) 10. AGNN: Alternierende graphregulierte neuronale Netze zur Linderung von Überglättung. (von Wenzhong Guo)
Das obige ist der detaillierte Inhalt vonMiniGPT-4 betrachtet Bilder, chattet und kann auch Websites skizzieren und erstellen. Die Videoversion von Stable Diffusion finden Sie hier. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Welche Plattform ist besser für den Handel mit virtuellen Währungen?
Welche Plattform ist besser für den Handel mit virtuellen Währungen?
 Eine vollständige Liste der Betriebs- und Wartungsbefehle für Linux-Server
Eine vollständige Liste der Betriebs- und Wartungsbefehle für Linux-Server
 So erstellen Sie virtuelles WLAN in Win7
So erstellen Sie virtuelles WLAN in Win7
 So verbinden Sie VB mit dem Zugriff auf die Datenbank
So verbinden Sie VB mit dem Zugriff auf die Datenbank
 Mit WLAN verbunden, aber kein Internetzugang möglich
Mit WLAN verbunden, aber kein Internetzugang möglich
 Einführung in die Überwachungsausrüstung von Wetterstationen
Einführung in die Überwachungsausrüstung von Wetterstationen
 Der heutige Preistrend des ETH-Preises
Der heutige Preistrend des ETH-Preises
 Einführung in den Javascript-Spezialeffektcode
Einführung in den Javascript-Spezialeffektcode

























