



Chatbots oder Kundendienstassistenten sind KI-Tools, die durch die Übermittlung an Benutzer per Text oder Sprache über das Internet einen geschäftlichen Mehrwert erzielen möchten. Die Entwicklung von Chatbots hat in den letzten Jahren rasante Fortschritte gemacht, von den ersten Robotern, die auf einfacher Logik basieren, bis hin zur aktuellen künstlichen Intelligenz, die auf natürlichem Sprachverständnis (Natural Language Understanding, NLU) basiert. Für letztere gehören zu den am häufigsten verwendeten Frameworks oder Bibliotheken beim Aufbau solcher Chatbots ausländische RASA, Dialogflow, Amazon Lex usw. sowie inländische Großunternehmen Baidu, iFlytek usw. Diese Frameworks können Natural Language Processing (NLP) und NLU integrieren, um Eingabetext zu verarbeiten, Absichten zu klassifizieren und die richtigen Aktionen auszulösen, um Antworten zu generieren.
Mit dem Aufkommen großer Sprachmodelle (LLM) können wir diese Modelle direkt verwenden, um voll funktionsfähige Chatbots zu erstellen. Eines der bekanntesten LLM-Beispiele ist der Generative Pre-Trained Transformer 3 von OpenAI (GPT-3: chatgpt basiert auf der Feinabstimmung von GPT und dem Hinzufügen eines menschlichen Feedback-Modells), das mithilfe von Dialog- oder Sitzungsdaten eine Feinabstimmung des Modells generieren kann Text, der einer natürlichen Konversation ähnelt. Diese Fähigkeit macht es zur besten Wahl für die Erstellung benutzerdefinierter Chatbots.
Heute werden wir darüber sprechen, wie wir durch die Feinabstimmung des GPT-3-Modells unseren eigenen einfachen Konversations-Chatbot erstellen können.
Oft möchten wir das Modell anhand eines Datensatzes unserer eigenen Geschäftsgesprächsbeispiele verfeinern, z. B. Gesprächsaufzeichnungen im Kundendienst, Chatprotokolle oder Untertitel in einem Film. Durch den Feinabstimmungsprozess werden die Parameter des Modells so angepasst, dass sie besser zu diesen Gesprächsdaten passen, sodass der Chatbot Benutzereingaben besser verstehen und darauf reagieren kann.
Zur Feinabstimmung von GPT-3 können wir die Transformers-Bibliothek von Hugging Face verwenden, die vorab trainierte Modelle und Feinabstimmungstools bereitstellt. Die Bibliothek bietet mehrere GPT-3-Modelle unterschiedlicher Größe und Leistungsfähigkeit. Je größer das Modell, desto mehr Daten kann es verarbeiten und desto höher dürfte seine Genauigkeit sein. Der Einfachheit halber verwenden wir dieses Mal jedoch die OpenAI-Schnittstelle, die durch das Schreiben einer kleinen Menge Code eine Feinabstimmung implementieren kann.
Der nächste Schritt besteht darin, dass wir OpenAI GPT-3 verwenden, um die Feinabstimmung vorzunehmen. Der Datensatz kann hier abgerufen werden. Leider habe ich wieder einen ausländischen Datensatz verwendet.
Das Erstellen eines Kontos ist sehr einfach, Sie können einfach diesen Link öffnen. Wir können über den openai-Schlüssel auf das Modell auf OpenAI zugreifen. Die Schritte zum Erstellen eines API-Schlüssels sind wie folgt:
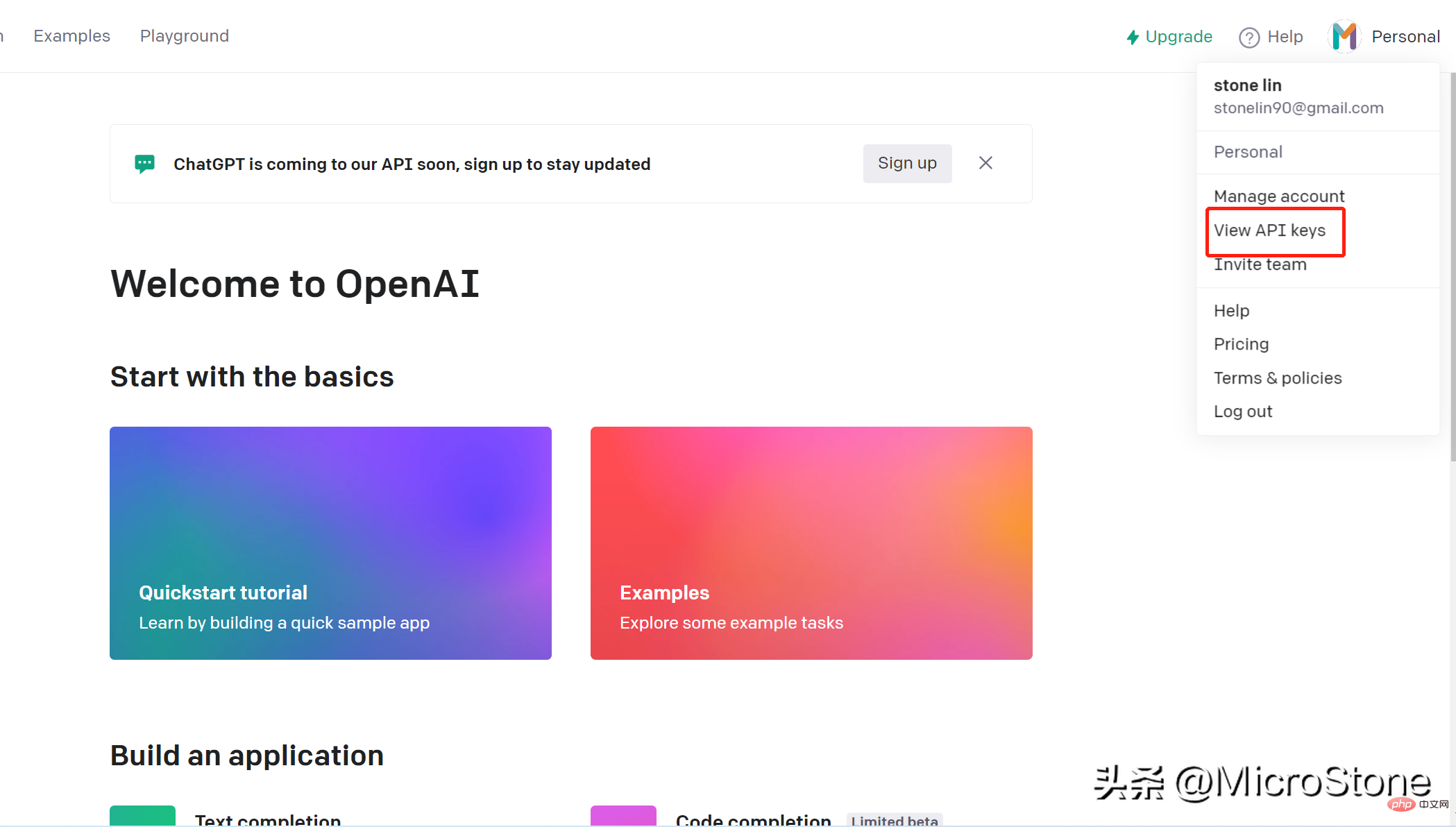
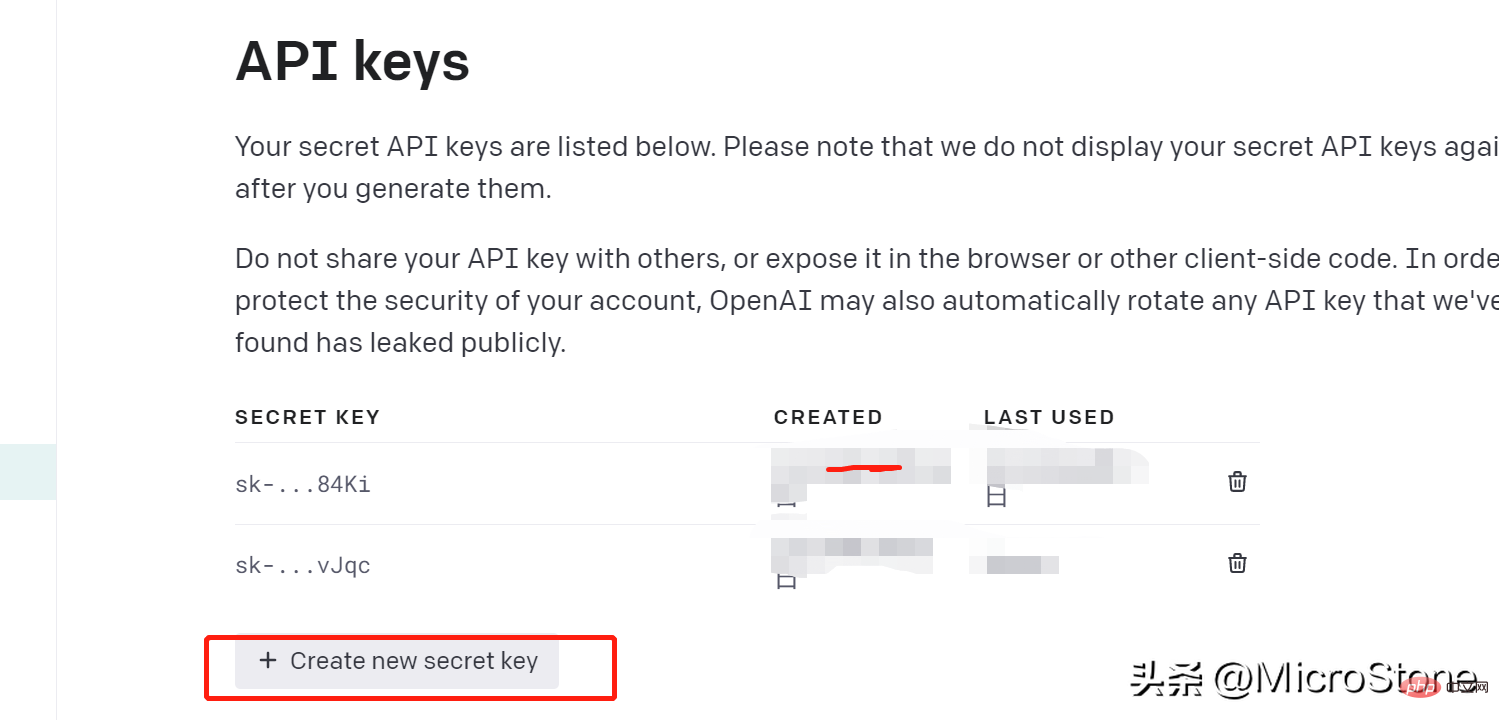
Wir haben den API-Schlüssel erstellt, dann können wir mit der Vorbereitung der Daten für das Feinabstimmungsmodell beginnen, und Sie können den Datensatz hier ansehen.

Installieren Sie die OpenAI-Bibliothek pip install openai
Nach der Installation können wir die Daten laden:
import os
import json
import openai
import pandas as pd
from dotenv import load_dotenv
load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_KEY')
openai.api_key = os.getenv('OPENAI_KEY')
data = pd.read_csv('data/data.csv')
new_df = pd.DataFrame({'Interview AI': data['Text'].iloc[::2].values, 'Human': data['Text'].iloc[1::2].values})
print(new_df.head(5))Wir laden die Fragen in die Spalte „Interview AI“ und die entsprechenden Antworten in die Spalte „Mensch“. Wir müssen außerdem eine .env-Datei mit Umgebungsvariablen erstellen, um OPENAI_API_KEY
zu speichern. Als nächstes konvertieren wir die Daten in den GPT-3-Standard. Stellen Sie laut Dokumentation sicher, dass die Daten im JSONL-Format mit zwei Schlüsseln vorliegen. Dies ist wichtig: Eingabeaufforderung, z. Weisen Sie den AI-Text des Interviews der Option „Abgeschlossen“ zu.
{ "prompt" :"<prompt text>" ,"completion" :"<ideal generated text>" }
{ "prompt" :"<prompt text>" ,"completion" :"<ideal generated text>" }Verwenden Sie den Befehl „prepare_data“, dann werden bei Aufforderung einige Fragen gestellt und wir können Y- oder N-Antworten geben.
output = []
for index, row in new_df.iterrows():
print(row)
completion = ''
line = {'prompt': row['Human'], 'completion': row['Interview AI']}
output.append(line)
print(output)
with open('data/data.jsonl', 'w') as outfile:
for i in output:
json.dump(i, outfile)
outfile.write('n')Schließlich wird eine Datei mit dem Namen data_prepared.jsonl im Verzeichnis abgelegt.
3. Fun-Tuning-Modell
os .system( "openai api fine_tunes.create -t 'data/data_prepared.jsonl' -m davinci " )
这基本上使用准备好的数据从 OpenAI 训练davinci模型,fine-tuning后的模型将存储在用户配置文件下,可以在模型下的右侧面板中找到。
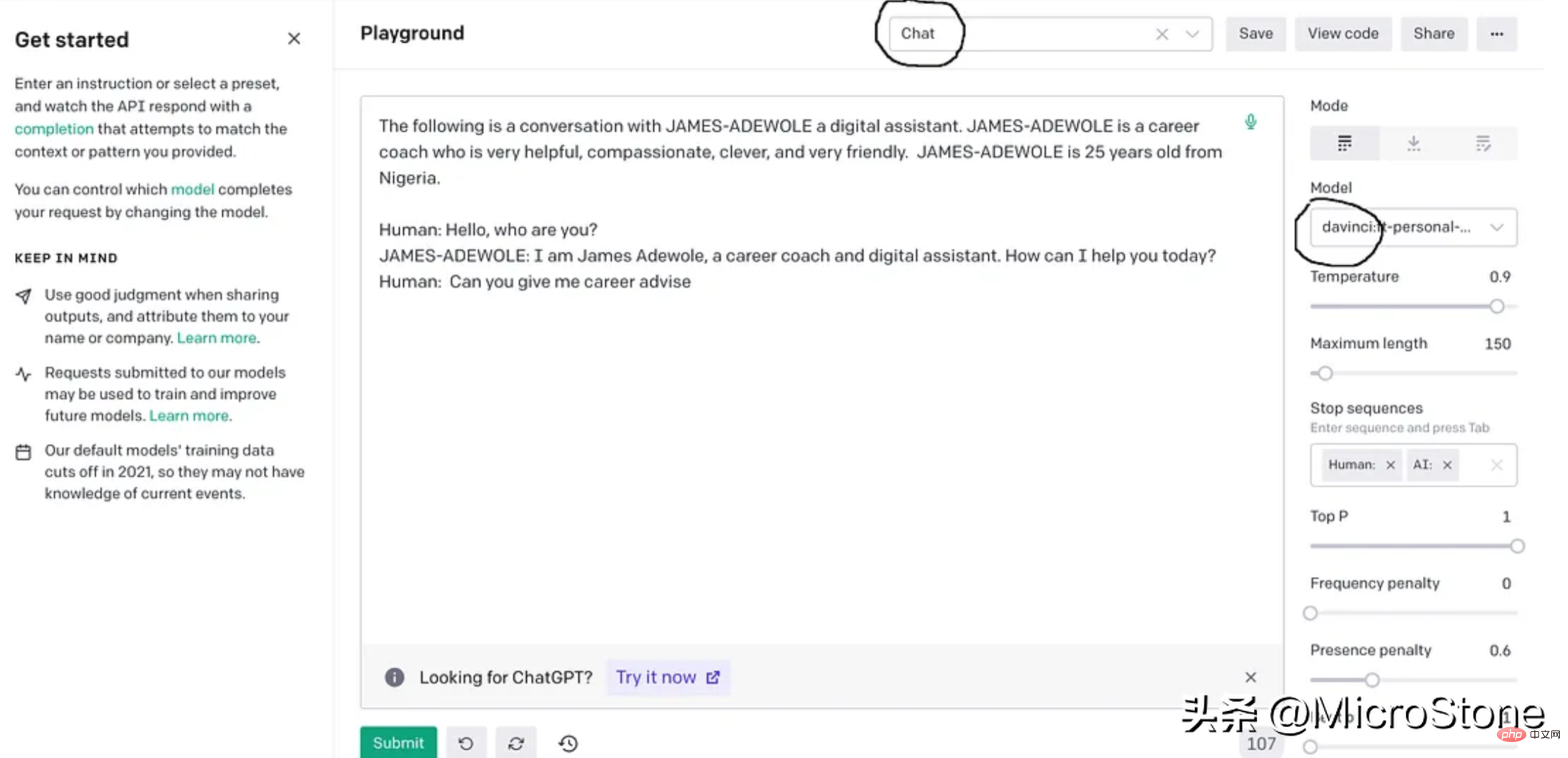
我们可以使用多种方法来验证我们的模型。可以直接从 Python 脚本、OpenAI Playground 来测试,或者使用 Flask 或 FastAPI 等框构建 Web 服务来测试。
我们先构建一个简单的函数来与此实验的模型进行交互。
def generate_response(input_text):
response = openai.Completion.create(
engine="davinci:ft-personal-2023-01-25-19-20-17",
prompt="The following is a conversation with DSA an AI assistant. "
"DSA is an interview bot who is very helpful and knowledgeable in data structure and algorithms.nn"
"Human: Hello, who are you?n"
"DSA: I am DSA, an interview digital assistant. How can I help you today?n"
"Human: {}nDSA:".format(input_text),
temperature=0.9,
max_tokens=150,
top_p=1,
frequency_penalty=0.0,
presence_penalty=0.6,
stop=["n", " Human:", " DSA:"]
)
return response.choices[0].text.strip()
output = generate_response(input_text)
print(output)把它们放在一起。
import os
import json
import openai
import pandas as pd
from dotenv import load_dotenv
load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_KEY')
openai.api_key = os.getenv('OPENAI_KEY')
data = pd.read_csv('data/data.csv')
new_df = pd.DataFrame({'Interview AI': data['Text'].iloc[::2].values, 'Human': data['Text'].iloc[1::2].values})
print(new_df.head(5))
output = []
for index, row in new_df.iterrows():
print(row)
completion = ''
line = {'prompt': row['Human'], 'completion': row['Interview AI']}
output.append(line)
print(output)
with open('data/data.jsonl', 'w') as outfile:
for i in output:
json.dump(i, outfile)
outfile.write('n')
os.system("openai tools fine_tunes.prepare_data -f 'data/data.jsonl' ")
os.system("openai api fine_tunes.create -t 'data/data_prepared.jsonl' -m davinci ")
def generate_response(input_text):
response = openai.Completion.create(
engine="davinci:ft-personal-2023-01-25-19-20-17",
prompt="The following is a conversation with DSA an AI assistant. "
"DSA is an interview bot who is very helpful and knowledgeable in data structure and algorithms.nn"
"Human: Hello, who are you?n"
"DSA: I am DSA, an interview digital assistant. How can I help you today?n"
"Human: {}nDSA:".format(input_text),
temperature=0.9,
max_tokens=150,
top_p=1,
frequency_penalty=0.0,
presence_penalty=0.6,
stop=["n", " Human:", " DSA:"]
)
return response.choices[0].text.strip()示例响应:
input_text = "what is breadth first search algorithm" output = generate_response(input_text)
The breadth-first search (BFS) is an algorithm for discovering all the reachable nodes from a starting point in a computer network graph or tree data structure
GPT-3 是一种强大的大型语言生成模型,最近火到无边无际的chatgpt就是基于GPT-3上fine-tuning的,我们也可以对GPT-3进行fine-tuning,以构建适合我们自己业务的聊天机器人。fun-tuning过程调整模型的参数可以更好地适应业务对话数据,让机器人更善于理解和响应业务的需求。经过fine-tuning的模型可以集成到聊天机器人平台中以处理用户交互,还可以为聊天机器人生成客服回复习惯与用户交互。整个实现可以在这里找到,数据集可以从这里下载。
Das obige ist der detaillierte Inhalt vonVerwenden Sie GPT-3, um einen Unternehmens-Chatbot zu erstellen, der Ihren Geschäftsanforderungen entspricht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



