


Apache Kafka ist ein verteiltes Publish-Subscribe-Messaging-System. Die Definition von Kafka auf der offiziellen Kafka-Website lautet: ein verteiltes Publish-Subscribe-Messaging-System. Es wurde ursprünglich von LinkedIn entwickelt, das 2010 der Apache Foundation zur Verfügung gestellt wurde und zu einem Top-Open-Source-Projekt wurde. Kafka ist ein schneller, skalierbarer und inhärent verteilter, partitionierter und replizierbarer Commit-Log-Dienst.
Hinweis: Kafka folgt nicht der JMS-Spezifikation (), sondern bietet nur Veröffentlichungs- und Abonnement-Kommunikationsmethoden.
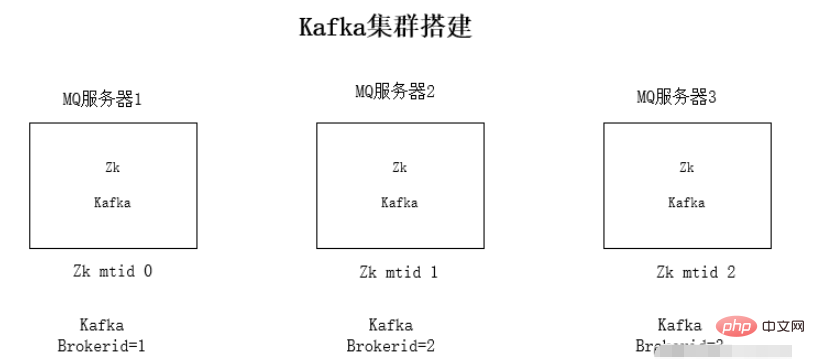
Broker: Kafka-Knoten, ein Kafka-Knoten ist ein Broker, mehrere Broker können einen Kafka-Cluster bilden
Topic: Ein Nachrichtentyp, das Verzeichnis, in dem die Nachricht gespeichert ist, ist das Thema B. Seitenaufrufprotokolle, Klickprotokolle usw., können in Form von Themen vorhanden sein. Der Kafka-Cluster kann für die gleichzeitige Verteilung mehrerer Themen verantwortlich sein. Massage: das grundlegendste Bereitstellungsobjekt in Kafka.
Partition: Die physische Gruppierung von Themen. Ein Thema kann in mehrere Partitionen unterteilt werden, und jede Partition ist eine geordnete Warteschlange. Die Partitionierung ist in Kafka implementiert und ein Broker repräsentiert eine Region.
Segment: Die Partition besteht physisch aus mehreren Segmenten. Jedes Segment speichert Nachrichteninformationen Verbraucht als Thread
Verbrauchergruppe: Verbrauchergruppe. Eine Verbrauchergruppe enthält mehrere Verbraucher :
tar -zxvf kafka_2.11-1.0.0.tgz
3. Ändern Sie die Konfigurationsdatei von kafka .propertieszookeeper.connect=192.168.1.19:2181
listeners geändert =PLAINTEXT://192.168.1.19:9092
broker.id=0
./kafka-server-start.sh -daemon config/server.properties
kafka verwendet
kafka-Dateispeicher
Thema ist ein logisches Konzept und die Partition ist physisch. Basierend auf dem Konzept Oben entspricht jede Partition einer Protokolldatei, und die Protokolldatei speichert die vom Produzenten generierten Daten. Die vom Produzenten generierten Daten werden kontinuierlich an das Ende der Protokolldatei angehängt. Um zu verhindern, dass die Protokolldatei zu groß wird und die Datenpositionierung ineffizient wird, verwendet Kafka einen Sharding- und Indizierungsmechanismus, um jede Partition in mehrere Segmente zu unterteilen . Jedes Segment enthält: „.index“-Dateien, „.log“-Dateien und .timeindex-Dateien. Diese Dateien befinden sich in einem Ordner und die Benennungsregel für den Ordner lautet: Themenname + Partitionsnummer.
Zum Beispiel: Führen Sie den Befehl aus, um ein neues Thema zu erstellen, das in drei Bereiche unterteilt und in drei Brokern gespeichert ist:
./kafka-topics.sh --create --zookeeper localhost:2181 --replication -faktor 1 - -partitions 3 --topic kaico
zookeeper.connect=192.168.1.19:2181
监听的ip,修改为本机的iplisteners=PLAINTEXT://192.168.1.19:9092
kafka的brokerid,每台broker的id都不一样broker.id=0
4、依次启动kafka
./kafka-server-start.sh -daemon config/server.properties
topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的就是Producer生成的数据。Producer生成的数据会被不断追加到该log文件末端,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个partition分为多个segment,每个segment包括:“.index”文件、“.log”文件和.timeindex等文件。这些文件位于一个文件夹下,该文件夹的命名规则为:topic名称+分区序号。
例如:执行命令新建一个主题,分三个区存放放在三个broker中:
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic kaico
.index-Offset-Indexdatei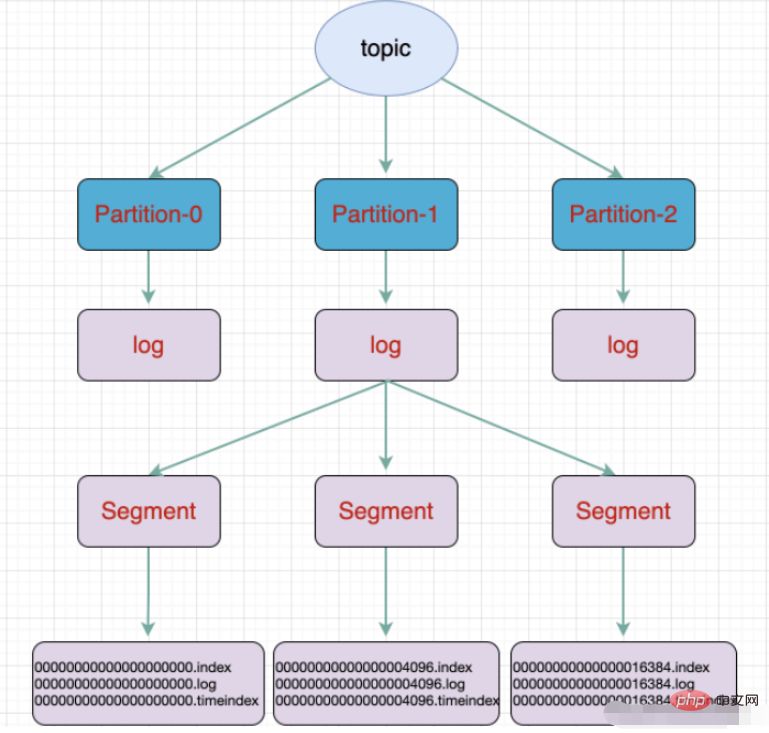
<dependencies>
<!-- springBoot集成kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!-- SpringBoot整合Web组件 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies># kafka
spring:
kafka:
# kafka服务器地址(可以多个)
# bootstrap-servers: 192.168.212.164:9092,192.168.212.167:9092,192.168.212.168:9092
bootstrap-servers: www.kaicostudy.com:9092,www.kaicostudy.com:9093,www.kaicostudy.com:9094
consumer:
# 指定一个默认的组名
group-id: kafkaGroup1
# earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
# latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
# none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
auto-offset-reset: earliest
# key/value的反序列化
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
# key/value的序列化
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# 批量抓取
batch-size: 65536
# 缓存容量
buffer-memory: 524288
# 服务器地址
bootstrap-servers: www.kaicostudy.com:9092,www.kaicostudy.com:9093,www.kaicostudy.com:9094@RestController
public class KafkaController {
/**
* 注入kafkaTemplate
*/
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
/**
* 发送消息的方法
*
* @param key
* 推送数据的key
* @param data
* 推送数据的data
*/
private void send(String key, String data) {
// topic 名称 key data 消息数据
kafkaTemplate.send("kaico", key, data);
}
// test 主题 1 my_test 3
@RequestMapping("/kafka")
public String testKafka() {
int iMax = 6;
for (int i = 1; i < iMax; i++) {
send("key" + i, "data" + i);
}
return "success";
}
}
@Component
public class TopicKaicoConsumer {
/**
* 消费者使用日志打印消息
*/
@KafkaListener(topics = "kaico") //监听的主题
public void receive(ConsumerRecord<?, ?> consumer) {
System.out.println("topic名称:" + consumer.topic() + ",key:" +
consumer.key() + "," +
"分区位置:" + consumer.partition()
+ ", 下标" + consumer.offset());
//输出key对应的value的值
System.out.println(consumer.value());
}
}Das obige ist der detaillierte Inhalt vonJava-verteilte Kafka-Nachrichtenwarteschlangeninstanzanalyse. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



