


Unbewusst sind große Modelle + kleine Stichproben zum Mainstream-Ansatz im Bereich des Lernens kleiner Stichproben geworden. In vielen Aufgabenkontexten besteht eine gängige Idee darin, zunächst kleine Datenstichproben zu kennzeichnen und dann große Modelle basierend auf kleinen Daten vorab zu trainieren Proben für die Ausbildung. Obwohl, wie wir gesehen haben, große Modelle bei einer Vielzahl von Lernaufgaben mit kleinen Stichproben erstaunliche Ergebnisse erzielt haben, rückt dies natürlich auch einige der inhärenten Mängel großer Modelle in den Mittelpunkt des Lernens mit kleinen Stichproben.
Beim Lernen mit kleinen Stichproben wird erwartet, dass das Modell in der Lage ist, unabhängige Überlegungen auf der Grundlage einer kleinen Anzahl von Stichproben anzustellen. Das heißt, das ideale Modell sollte Problemlösungsideen beherrschen, indem es Probleme löst, damit es Schlussfolgerungen ziehen kann über andere Fälle, wenn neue Probleme auftreten. Die ideale und praktische Lernfähigkeit großer Modelle + kleiner Stichproben scheint jedoch auf der großen Menge an Informationen zu beruhen, die während des Trainings großer Modelle gespeichert werden, um sich den Prozess der Lösung eines Problems zu merken. Obwohl dies bei verschiedenen Datensätzen äußerst mutig ist, wird dies immer der Fall sein Scheitern bringt bei den Menschen Zweifel hervor. Ist ein Student, der auf diese Weise studiert, wirklich ein potenzieller Student?

Der heute von Meta AI vorgestellte Artikel wendet die Retrieval-Enhancement-Methode auf eine neue Art und Weise an. Er verwendet nicht nur 64 Beispiele, sondern auch 64 Beispiele im Natural Questions-Datensatz. und erreichte eine Genauigkeitsrate von 42 % im Vergleich zum großen Modell PaLM mit einer 50-fachen Reduzierung der Parameter (540 B -> 11 B) und weist eine hervorragende Interpretierbarkeit, Steuerbarkeit und Aktualisierbarkeit auf.
Papiertitel:Few-shot Learning with Retrieval Augmented Language ModelsPapier. Link:https://arxiv.org/pdf/2208.03299.pdf
Zu Beginn des Artikels wurde allen eine Frage gestellt: „Ist es im Bereich des Lernens kleiner Stichproben wirklich notwendig, eine große Anzahl von Parametern zum Speichern von Informationen zu verwenden?“ Ein großes Modell nach dem anderen. Einer der Gründe, warum das Modell SOTA endlos aktualisieren kann, ist, dass seine riesigen Parameter die für das Problem erforderlichen Informationen speichern. Seit der Geburt von Transformer sind große Modelle das Mainstream-Paradigma im Bereich NLP. Mit der allmählichen Entwicklung großer Modelle wird die Notwendigkeit von „großen“ Problemen immer wieder aufgedeckt Der Artikel beginnt mit: Ausgehend von dieser Frage wird diese Frage negativ beantwortet und die Methode besteht darin, das erweiterte Modell abzurufen.

Verbesserung der Rückverfolgbarkeit Obwohl seine Technologie hauptsächlich für Aufgaben wie die Beantwortung von Fragen im offenen Bereich, das maschinelle Lesen und die Textgenerierung verwendet wird, kann die Idee der Verbesserung der Rückverfolgbarkeit auf das RNN zurückgeführt werden Ära des NLP. Der Mangel des RNN-Modells, der die langfristige Abhängigkeit von Daten nicht lösen kann, hat Forscher dazu veranlasst, umfassend nach Lösungen zu suchen. Der Transformer, mit dem wir durchaus vertraut sind, nutzt den Aufmerksamkeitsmechanismus, um das Problem der Unfähigkeit des Modells, sich zu erinnern, effektiv zu lösen. Dies öffnet die Tür für die Ära der Vorschulung großer Modelle.
Damals gab es tatsächlich einen anderen Weg, nämlich Cached LM. Seine Kernidee war, dass wir RNN genauso gut die offene Prüfung überlassen könnten, da RNN sich möglicherweise nicht daran erinnern kann, sobald es die Prüfung ablegt Durch die Einführung des Cache-Mechanismus werden die während des Trainings vorhergesagten Wörter im Cache gespeichert und die Informationen aus der Abfrage und dem Cache-Index können kombiniert werden, um die Aufgabe während der Vorhersage abzuschließen, wodurch die Mängel des RNN-Modells behoben werden Zeit.
Infolgedessen hat die Retrieval-Enhancement-Technologie einen völlig anderen Weg eingeschlagen als große Modelle, die auf Parameterspeicherinformationen angewiesen sind. Das auf der Abrufverbesserung basierende Modell ermöglicht die Einführung von externem Wissen aus verschiedenen Quellen. Zu diesen Abrufquellen gehören Trainingskorpus, externe Daten, unbeaufsichtigte Daten und andere Optionen. Das Abrufverbesserungsmodell besteht im Allgemeinen aus einem Retriever und einem Generator. Der Retriever erhält entsprechend der Abfrage relevantes Wissen von externen Abrufquellen, und der Generator kombiniert die Abfrage mit dem abgerufenen relevanten Wissen, um Modellvorhersagen durchzuführen.
Letztendlich besteht das Ziel des Abruf-erweiterten Modells darin, zu erwarten, dass das Modell nicht nur lernt, sich die Daten zu merken, sondern auch, die Daten selbst zu finden. Diese Funktion hat in vielen Bereichen große Vorteile. Intensive Aufgaben, und das Retrieval-Enhanced-Modell hat auch in diesen Bereichen große Erfolge erzielt, es ist jedoch nicht bekannt, ob die Retrieval-Enhancement für das Small-Shot-Lernen geeignet ist. Zurück zu diesem Artikel in Meta AI: Wir haben die Anwendung der Abrufverbesserung beim Lernen kleiner Stichproben erfolgreich getestet und Atlas entstand.
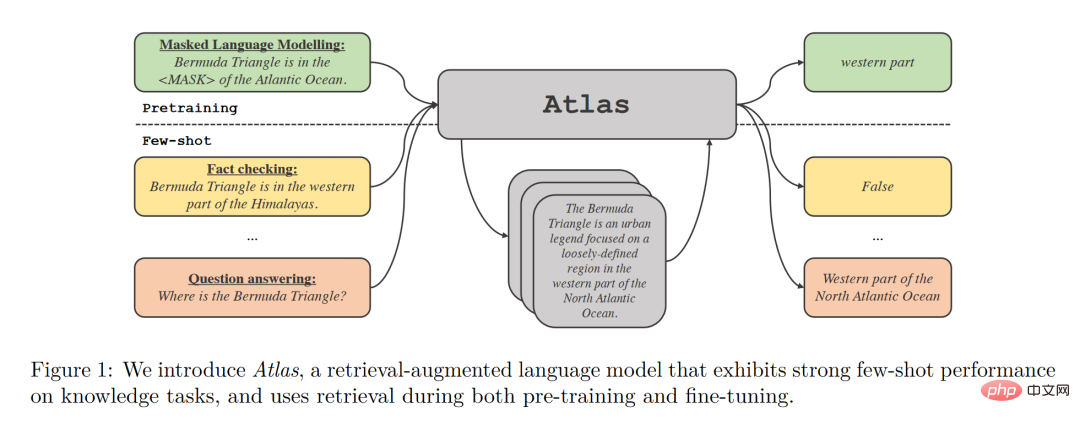
Atlas verfügt über zwei Untermodelle, ein Retriever- und ein Sprachmodell. Wenn Atlas vor einer Aufgabe steht, verwendet Atlas einen Sucher, um aus einer großen Menge an Korpus basierend auf der Eingabefrage die relevantesten Top-K-Dokumente zu generieren, und fügt diese Dokumente dann zusammen mit der Frageabfrage in das Sprachmodell ein, um die erforderliche Ausgabe zu generieren .

Die grundlegende Trainingsstrategie des Atlas-Modells besteht darin, den Retriever und das Sprachmodell gemeinsam mit derselben Verlustfunktion zu trainieren. Sowohl der Retriever als auch das Sprachmodell basieren auf dem vorab trainierten Transformer-Netzwerk.
Es ist erwähnenswert, dass der Autor vier Verlustfunktionen und die Situation ohne gemeinsames Training des Retrievers und des Sprachmodells verglichen und getestet hat. Die Ergebnisse sind wie folgt:
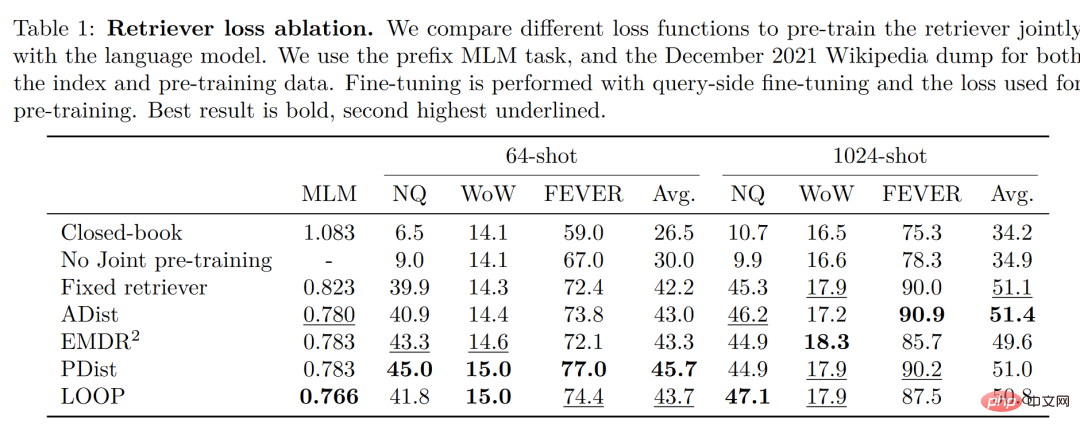
Das ist in zu sehen Eine kleine Stichprobenumgebung Unter dieser Bedingung ist die durch die Verwendung der gemeinsamen Trainingsmethode erzielte Genauigkeit deutlich höher als die ohne gemeinsames Training. Daher kommt der Autor zu dem Schluss, dass dieses gemeinsame Training des Retrievers und des Sprachmodells der Schlüssel zur Fähigkeit von Atlas ist kleines Beispiellernen.
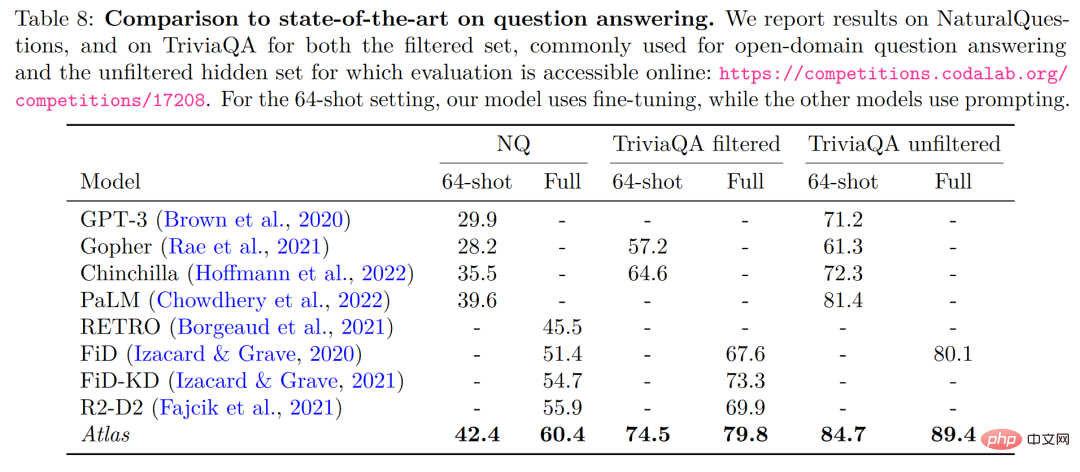
Bei der groß angelegten Multitask-Sprachverständnisaufgabe (MMLU) verfügt Atlas im Vergleich zu anderen Modellen über 15-mal mehr Parameter als GPT-3 mit nur 11B Parametern. Die Genauigkeitsrate ist sehr hoch Gut Nach der Einführung des Multitasking-Trainings liegt die Genauigkeitsrate im 5-Schuss-Test sogar nahe an der von Gopher, was 25 Mal so viele Parameter wie Atlas beträgt.
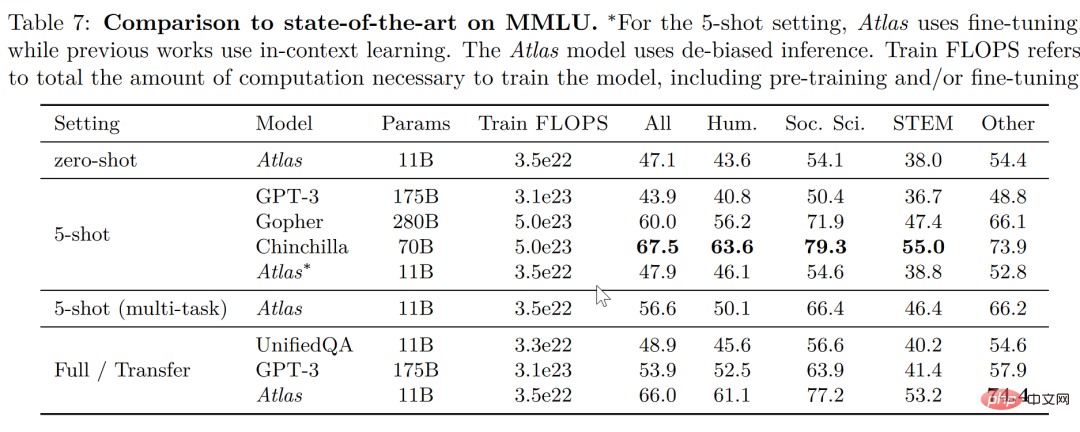
In den beiden Testdaten für die Beantwortung offener Domänen – NaturalQuestions und TriviaQA – wird die Leistung von Atlas und anderen Modellen an 64 Beispielen und die Leistung am gesamten Trainingssatz verglichen. Atlas ist ein neuer SOTA, der in 64 Schuss erreicht wurde und bei TrivuaQA mit nur 64 Daten eine Genauigkeit von 84,7 % erreichte.
Bei der Faktenprüfungsaufgabe (FEVER) schnitt Atlas auch bei kleinen Stichproben deutlich besser ab als Gopher und ProoFVer, die Dutzende Male so viele Parameter wie Atlas bei der 15-Schuss-Aufgabe haben überstieg Gopher 5,1 %.

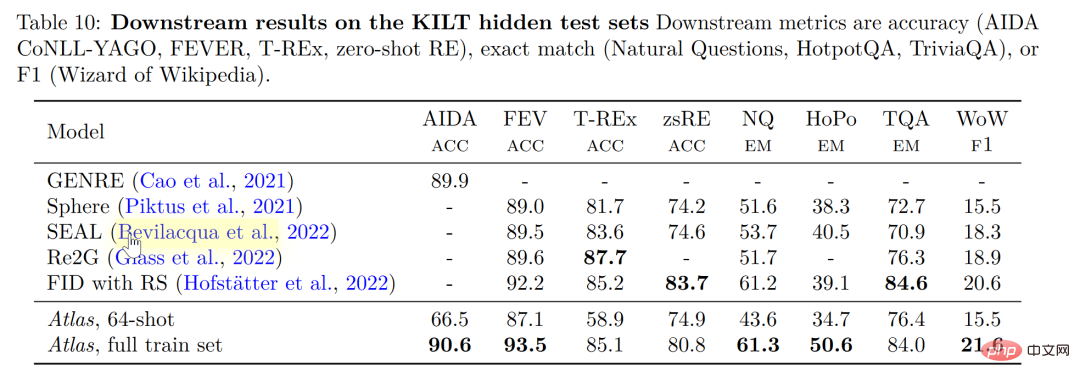
Bei KILT, dem selbstveröffentlichten Benchmark für wissensintensive Verarbeitungsaufgaben in natürlicher Sprache, liegt die Genauigkeit von Atlas, die mit 64 Beispielen trainiert wurde, bei einigen Aufgaben sogar nahe an der Genauigkeit, die andere Modelle mit vollständigen Beispielen danach erreichten Beim Training von Atlas mit allen Beispielen aktualisierte Atlas die SOTA anhand von fünf Datensätzen.
Den Untersuchungen in diesem Artikel zufolge gleicht das Retrieval-Enhancement-Modell nicht nur kleinere und bessere Modelle aus, sondern verfügt auch über Funktionen, die andere große Modelle in Bezug auf die Interpretierbarkeit nicht haben. Der Black-Box-Charakter großer Modelle macht es für Forscher schwierig, den Funktionsmechanismus des Modells mit großen Modellen zu analysieren. Das abrufbare Modell kann jedoch die abgerufenen Dokumente direkt extrahieren, sodass wir durch die Analyse der durch den Abruf abgerufenen Artikel Einblicke in die Atlas-Arbeit erhalten. In der Arbeit wurde beispielsweise festgestellt, dass im Bereich der abstrakten Algebra 73 % des Modellkorpus auf Wikipedia beruhten, während in ethikbezogenen Bereichen nur 3 % der vom Suchenden extrahierten Dokumente aus Wikipedia stammten, was mit dem Menschen übereinstimmt Intuition. Wie im statistischen Diagramm auf der linken Seite der Abbildung unten gezeigt, ist die Nutzungsrate von Wikipedia-Artikeln in MINT-Bereichen, die sich mehr auf Formeln und Argumentation konzentrieren, deutlich gestiegen, obwohl das Modell die Verwendung von CCNet-Daten bevorzugt.
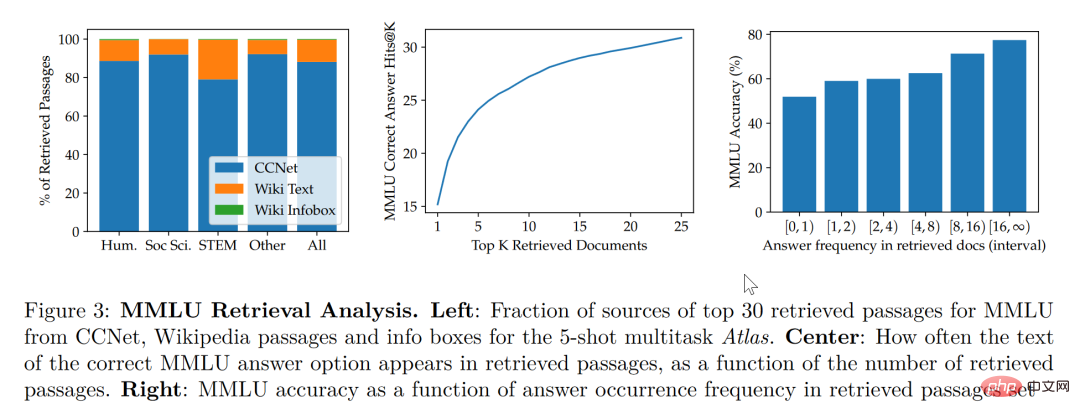
Laut dem statistischen Diagramm auf der rechten Seite der obigen Abbildung stellte der Autor fest, dass mit zunehmender Anzahl abgerufener Artikel mit korrekten Antworten auch die Genauigkeit des Modells weiter zunimmt Wenn die Antwort keine Antworten enthält, ist sie nur zu 55 % richtig, und wenn die Antwort mehr als 15 Mal genannt wurde, erreichte die Richtigkeitsquote 77 %. Darüber hinaus wurde bei der manuellen Durchsicht der von 50 Suchmaschinen abgerufenen Dokumente festgestellt, dass 44 % davon nützliche Hintergrundinformationen enthielten. Offensichtlich können diese Materialien mit Hintergrundinformationen zu Themen großartige Möglichkeiten bieten, ihre Lektüre zu erweitern.
Im Allgemeinen gehen wir davon aus, dass bei großen Modellen das Risiko eines „Lecks“ von Trainingsdaten besteht, das heißt, dass die Antworten großer Modelle auf Testfragen manchmal nicht auf der Lernfähigkeit des Modells, sondern auf dem Gedächtnis basieren Fähigkeit des großen Modells, das heißt, die Antworten auf die Testfragen wurden in einem großen Korpus durchgesickert, den das Modell in diesem Artikel gelernt hat, nachdem der Autor die möglicherweise durchgesickerten Korpusinformationen manuell entfernt hat Die Genauigkeit sank von 56,4 % auf 55,8 %, was einem Rückgang von nur 0,6 % entspricht. Es ist ersichtlich, dass die Abrufverbesserungsmethode das Risiko von Modellbetrug effektiv vermeiden kann.
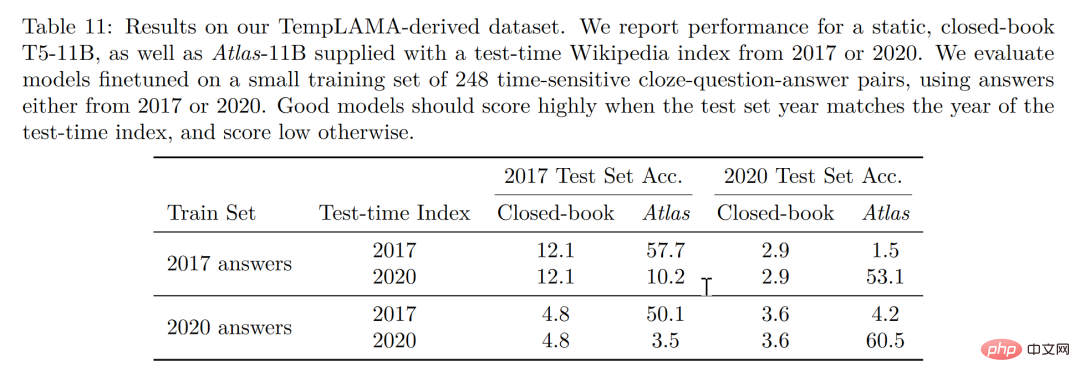
Schließlich ist die Aktualisierbarkeit auch ein einzigartiger Vorteil des Retrieval-Enhancement-Modells. Das Retrieval-Enhancement-Modell kann von Zeit zu Zeit ohne Umschulung aktualisiert werden, sondern nur durch Aktualisierung oder Austausch des Korpus, auf dem es basiert. Durch die Erstellung eines Zeitreihendatensatzes, wie in der Abbildung unten gezeigt, ohne die Atlas-Parameter zu aktualisieren, erreichte der Autor allein durch die Verwendung des 2020-Korpus-Atlas eine Genauigkeit von 53,1 %. Interessant ist, dass dies auch bei der Feinabstimmung der Daten für 2020 der Fall ist T5 und T5 schnitten ebenfalls nicht sehr gut ab. Der Autor ist der Ansicht, dass der Grund hauptsächlich darin liegt, dass es sich bei den im Vortraining von T5 verwendeten Daten um Daten vor 2020 handelt.
Natürlich besteht das Ideal des Lernens in kleinen Stichproben darin, der dritte Schüler zu werden, aber die Realität wird wahrscheinlich über dem ersten Schüler bleiben. Große Modelle sind einfach zu verwenden, aber „groß“ ist keineswegs das ultimative Ziel des Modells. Zurück zur ursprünglichen Absicht des Lernens mit kleinen Stichproben, von dem Modell ein logisches Urteilsvermögen und die Fähigkeit zu erwarten, ähnliche Schlussfolgerungen zu ziehen wie Menschen Wir können sehen, dass diese Arbeit aus einer anderen Perspektive ist. Es wäre gut, einen Schritt nach vorne zu machen, um es dem Studenten zumindest zu erleichtern, nicht so viel potenziell überflüssiges Wissen in seinen Kopf zu laden, sondern ein Lehrbuch in die Hand zu nehmen Reisen Sie mit leichtem Gepäck und erlauben Sie den Schülern möglicherweise sogar, offene Prüfungen mit dem Lehrbuch zur ständigen Wiederholung abzulegen, und es wird der Intelligenz näher kommen als den Schülern, die es auswendig lernen!
Das obige ist der detaillierte Inhalt vonGPT3 und Google PaLM sind der absolute Hammer! Der erweiterte Modellatlas zum Abrufen aktualisiert wissensbasierte kleine Beispielaufgaben SOTA. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



