


Überlegen Sie, ein Modell für einen Datensatz zu erstellen, aber es schlägt bei unsichtbaren Daten fehl.
Wir können nicht einfach ein Modell an unsere Trainingsdaten anpassen und darauf warten, dass es mit echten, unsichtbaren Daten perfekt funktioniert.
Dies ist ein Beispiel für Überanpassung. Unser Modell hat alle Muster und Störungen in den Trainingsdaten extrahiert. Um dies zu verhindern, müssen wir sicherstellen, dass unser Modell die meisten Muster erfasst hat und nicht jedes bisschen Rauschen in den Daten auffängt (geringe Verzerrung und geringe Varianz). Eine der vielen Techniken zur Lösung dieses Problems ist die Kreuzvalidierung.
Angenommen, wir haben in einem bestimmten Datensatz 1000 Datensätze und train_test_split() wird darauf ausgeführt. Unter der Annahme, dass wir 70 % der Trainingsdaten und 30 % der Testdaten mit random_state = 0 haben, führen diese Parameter zu einer Genauigkeit von 85 %. Wenn wir nun random_state = 50 setzen, nehmen wir an, dass sich die Genauigkeit auf 87 % verbessert.
Das bedeutet, dass es zu Schwankungen kommt, wenn wir weiterhin unterschiedliche Präzisionswerte für random_state wählen. Um dies zu verhindern, kommt eine Technik namens Kreuzvalidierung ins Spiel.
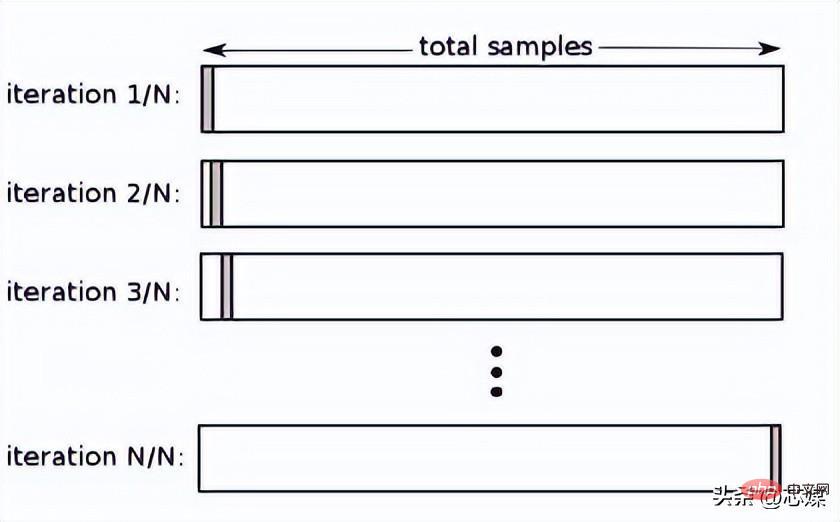
In LOOCV wählen wir 1 Datenpunkt als Test aus und alle verbleibenden Daten sind die Trainingsdaten in der ersten Iteration. In der nächsten Iteration werden wir den nächsten Datenpunkt als Testdaten und den Rest als Trainingsdaten auswählen. Wir werden dies für den gesamten Datensatz wiederholen, sodass der letzte Datenpunkt als Test in der letzten Iteration ausgewählt wird.
Um den Kreuzvalidierungs-R² für ein iteratives Kreuzvalidierungsverfahren zu berechnen, müssen Sie normalerweise den R²-Score für jede Iteration berechnen und deren Durchschnitt ermitteln.
Obwohl es zu zuverlässigen und unvoreingenommenen Schätzungen der Modellleistung führt, ist die Durchführung rechenintensiv.

Im K-fachen Lebenslauf teilen wir den Datensatz in k Teilmengen (Faltungen genannt) auf und machen uns dann für das Training bereit, lassen aber a (k-1) Teilmenge zur Bewertung des trainierten Modells.
Angenommen, wir haben 1000 Datensätze und unser K=5. Dieser K-Wert bedeutet, dass wir 5 Iterationen haben. Die Anzahl der Datenpunkte für die erste Iteration, die für die Testdaten berücksichtigt werden sollen, beträgt von Anfang an 1000/5=200. Bei der nächsten Iteration werden dann die nächsten 200 Datenpunkte als Tests betrachtet und so weiter.
Um die Gesamtgenauigkeit zu berechnen, berechnen wir die Genauigkeit für jede Iteration und bilden dann den Durchschnitt.
Die minimale Genauigkeit, die wir durch diesen Prozess erreichen können, ist die niedrigste Genauigkeit, die über alle Iterationen hinweg erzielt wird, und in ähnlicher Weise ist die maximale Genauigkeit die höchste Genauigkeit, die über alle Iterationen hinweg erzielt wird.
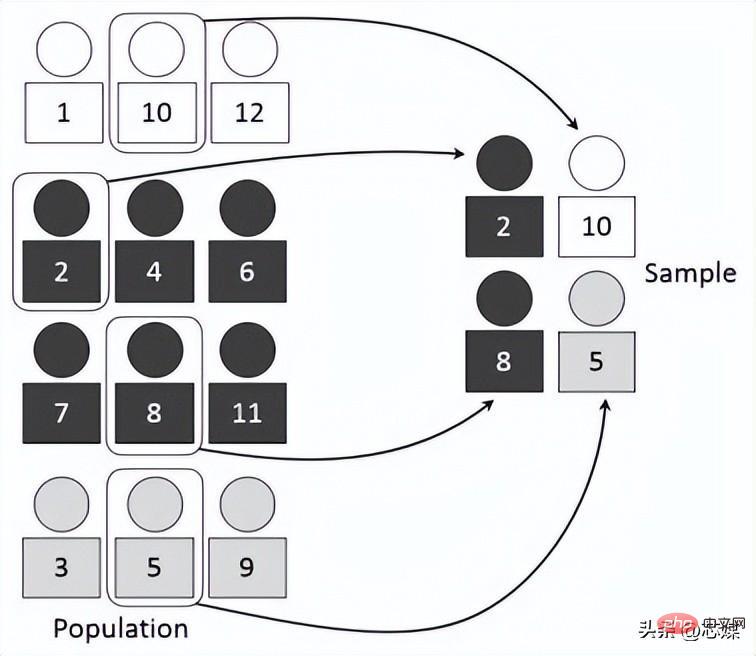
Strategischer Lebenslauf ist eine Erweiterung der regulären k-fachen Kreuzvalidierung, jedoch speziell für Klassifizierungsprobleme, bei denen die Aufteilungen nicht vollständig zufällig und das Ziel sind Klasse ist Das Verhältnis zwischen ist bei jeder Falte das gleiche wie im gesamten Datensatz.
Angenommen, wir haben 1000 Datensätze, die 600 Ja und 400 Nein enthalten. Daher wird in jedem Experiment sichergestellt, dass die Zufallsstichproben, die in Training und Tests einfließen, so bestückt werden, dass mindestens einige Instanzen jeder Klasse sowohl in der Trainings- als auch in der Testaufteilung vorhanden sind. 4. Zeitreihen-Kreuzvalidierung Der entsprechende Trainingssatz enthält nur Beobachtungen, die vor der Beobachtung erfolgten, die den Testsatz bildete.
Daher können zukünftige Beobachtungen nicht zur Erstellung von Vorhersagen verwendet werden.Beim maschinellen Lernen wollen wir normalerweise nicht den Algorithmus oder das Modell, das auf dem Trainingssatz die beste Leistung erbringt. Stattdessen möchten wir ein Modell, das im Testsatz eine gute Leistung erbringt, und ein Modell, das bei neuen Eingabedaten konstant eine gute Leistung erbringt. Die Kreuzvalidierung ist ein entscheidender Schritt, um sicherzustellen, dass wir solche Algorithmen oder Modelle identifizieren können.
Das obige ist der detaillierte Inhalt vonVier Kreuzvalidierungstechniken, die Sie beim maschinellen Lernen erlernen müssen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



