


Bei der täglichen Data-Mining-Arbeit sind neben der Verwendung von Python zur Bearbeitung von Klassifizierungs- oder Vorhersageaufgaben manchmal auch Aufgaben im Zusammenhang mit Empfehlungssystemen erforderlich.
Empfehlungssysteme werden in verschiedenen Bereichen eingesetzt, gängige Beispiele sind Playlist-Generatoren für Video- und Musikdienste, Produktempfehlungen für Online-Shops oder Inhaltsempfehlungen für Social-Media-Plattformen. In diesem Projekt erstellen wir einen Filmempfehlungsgeber.
Kollaborative Filterung prognostiziert (filtert) automatisch die Interessen der Benutzer, indem sie die Vorlieben oder Geschmacksinformationen vieler Benutzer sammelt. Empfehlungssysteme werden bereits seit langem entwickelt und ihre Modelle basieren auf verschiedenen Techniken wie gewichtetem Durchschnitt, Korrelation, maschinellem Lernen, tiefem Lernen usw.
Movielens 20M-Datensatz enthält über 20 Millionen Filmbewertungen und Tagging-Ereignisse seit 1995. In diesem Artikel rufen wir Informationen aus den Dateien „movie.csv“ und „rating.csv“ ab. Verwenden Sie die Python-Bibliotheken Pandas, Seaborn, Scikit-learn und SciPy, um das Modell mithilfe der Kosinusähnlichkeit im k-Nearest-Neighbor-Algorithmus zu trainieren. 🎜🎜 Daten analysieren
Verwenden Sie Seaborn, um Daten zu visualisieren und zu analysieren
# usecols 允许选择自己选择的特征,并通过dtype设定对应类型
movies_df=pd.read_csv('movies.csv',
usecols=['movieId','title'],
dtype={'movieId':'int32','title':'str'})
movies_df.head()ratings_df=pd.read_csv('ratings.csv',
usecols=['userId', 'movieId', 'rating','timestamp'],
dtype={'userId': 'int32', 'movieId': 'int32', 'rating': 'float32'})
ratings_df.head()Movieid 0 🎜🎜#0
🎜🎜#0
🎜🎜 ## 🎜🎜 ############# ########## 🎜🎜#userId 0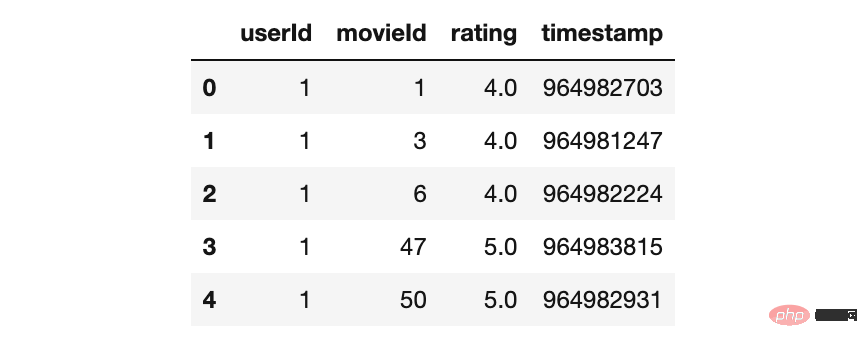
# 🎜🎜#dtype: int64#🎜 🎜#
# 检查缺失值 movies_df.isnull().sum()
Filme: (9742, 2)
Bewertungen: (100836, 4)
Mer ge Datenrahmen in der Spalte „movieId“#🎜 🎜#ratings_df.isnull().sum()
print("Movies:",movies_df.shape)
print("Ratings:",ratings_df.shape)# movies_df.info() # ratings_df.info() movies_merged_df=movies_df.merge(ratings_df, on='movieId') movies_merged_df.head()
Derzeit wurden 2 neue abgeleitete Features erstellt. 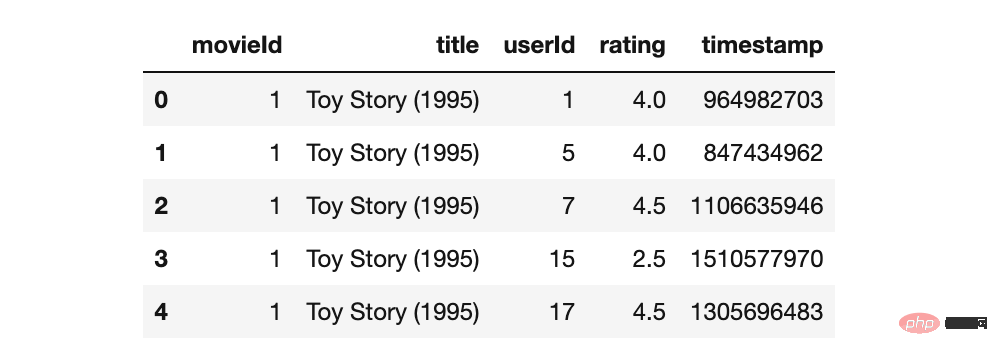
Nach der Analyse wurde festgestellt, dass viele Filme in einem bewertet wurden Datensatz von fast 100.000 Benutzern. Alle haben eine perfekte durchschnittliche 5-Sterne-Bewertung. Dies weist auf das Vorhandensein von Ausreißern hin, die wir durch Visualisierung weiter bestätigen müssen.
Viele Filme haben relativ einfache Bewertungen. Es wird empfohlen, einen Bewertungsschwellenwert festzulegen, um wertvolle Empfehlungen zu generieren.
 Verwenden Sie Seaborn und Matplotlib, um Daten für eine bessere Beobachtung und Analyse von Daten zu visualisieren.
Verwenden Sie Seaborn und Matplotlib, um Daten für eine bessere Beobachtung und Analyse von Daten zu visualisieren.
Zeichnen Sie ein Histogramm der neu erstellten Features und sehen Sie sich deren Verteilung an. Stellen Sie die Bin-Größe auf 80 ein. Die Einstellung dieses Werts erfordert eine detaillierte Analyse und eine angemessene Einstellung. 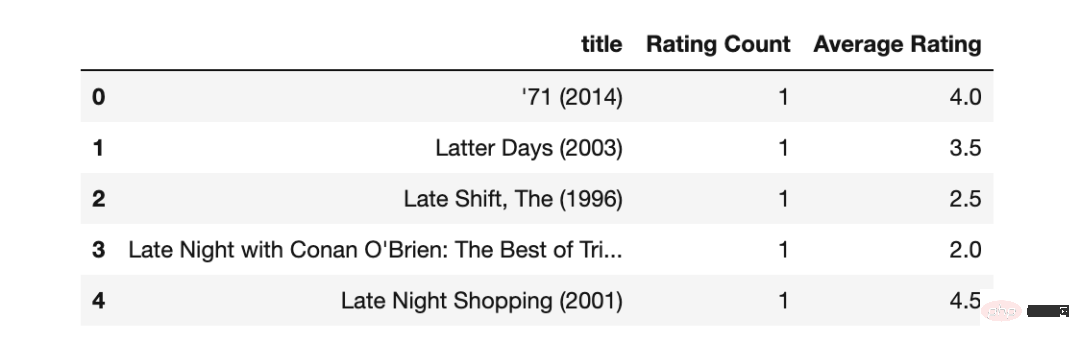
movies_average_rating=movies_merged_df.groupby('title')['rating']
.mean().sort_values(ascending=False)
.reset_index().rename(columns={'rating':'Average Rating'})
movies_average_rating.head()Erstellen Sie nun ein zweidimensionales Joinplot-Diagramm, um diese beiden Funktionen zusammen zu visualisieren.
movies_rating_count=movies_merged_df.groupby('title')['rating']
.count().sort_values(ascending=True)
.reset_index().rename(columns={'rating':'Rating Count'}) #ascending=False
movies_rating_count_avg=movies_rating_count.merge(movies_average_rating, on='title')
movies_rating_count_avg.head()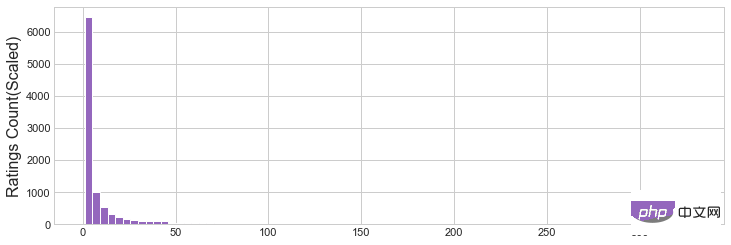
运用describe()函数得到数据集的描述统计值,如分位数和标准差等。 设置阈值并筛选出高于阈值的数据。 至此已经通过过滤掉了评论低于阈值的电影来清洗数据。 创建一个以用户为索引、以电影为列的数据透视表 为了稍后将数据加载到模型中,需要创建一个数据透视表。并设置'title'作为索引,'userId'为列,'rating'为值。 接下来将创建的数据透视表加载到模型。 建立 kNN 模型并输出与每部电影相似的 5 个推荐 使用scipy.sparse模块中的csr_matrix方法,将数据透视表转换为用于拟合模型的数组矩阵。 最后,使用之前生成的矩阵数据,来训练来自sklearn中的NearestNeighbors算法。并设置参数:metric = 'cosine', algorithm = 'brute'分析
数据清洗
pd.set_option('display.float_format', lambda x: '%.3f' % x)
print(rating_with_RatingCount['Rating Count'].describe())Nach dem Login kopierencount 100836.000
mean58.759
std 61.965
min1.000
25% 13.000
50% 39.000
75% 84.000
max329.000
Name: Rating Count, dtype: float64
Nach dem Login kopierenpopularity_threshold = 50
popular_movies= rating_with_RatingCount[
rating_with_RatingCount['Rating Count']>=popularity_threshold]
popular_movies.head()
# popular_movies.shape
Nach dem Login kopieren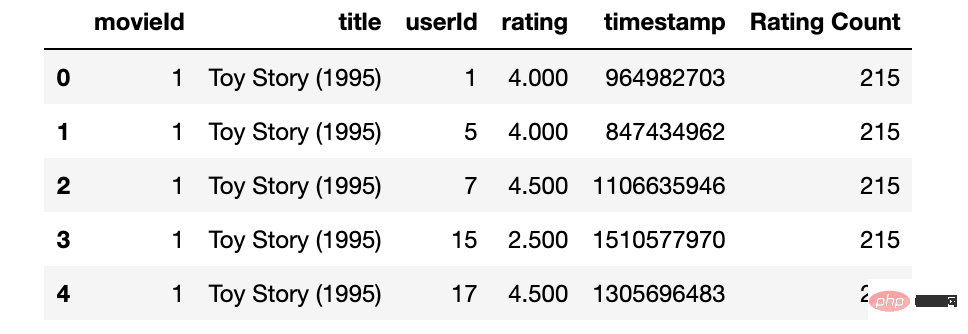
创建数据透视表
import os
movie_features_df=popular_movies.pivot_table(
index='title',columns='userId',values='rating').fillna(0)
movie_features_df.head()
movie_features_df.to_excel('output.xlsx')Nach dem Login kopieren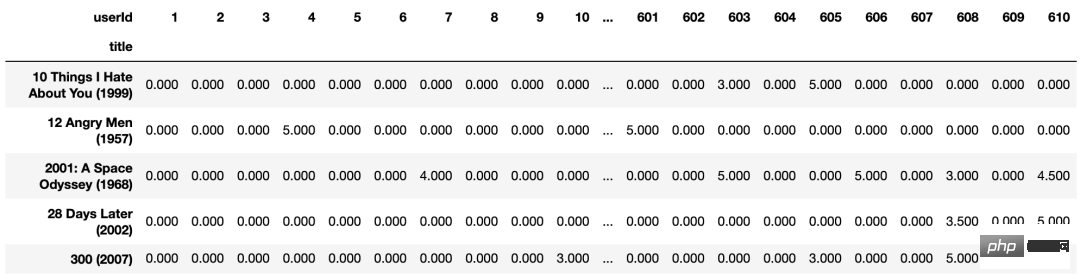
建立 kNN 模型
from scipy.sparse import csr_matrix
movie_features_df_matrix = csr_matrix(movie_features_df.values)
Nach dem Login kopieren
from sklearn.neighbors import NearestNeighbors model_knn = NearestNeighbors(metric = 'cosine', algorithm = 'brute') model_knn.fit(movie_features_df_matrix)
现在向模型传递一个索引,根据'kneighbors'算法要求,需要将数据转换为单行数组,并设置n_neighbors的值。
query_index = np.random.choice(movie_features_df.shape[0]) distances, indices = model_knn.kneighbors(movie_features_df.iloc[query_index,:].values.reshape(1, -1), n_neighbors = 6)
最后在 query_index 中输出出电影推荐。
for i in range(0, len(distances.flatten())):
if i == 0:
print('Recommendations for {0}:n'
.format(movie_features_df.index[query_index]))
else:
print('{0}: {1}, with distance of {2}:'
.format(i, movie_features_df.index[indices.flatten()[i]],
distances.flatten()[i]))Recommendations for Harry Potter and the Order of the Phoenix (2007): 1: Harry Potter and the Half-Blood Prince (2009), with distance of 0.2346513867378235: 2: Harry Potter and the Order of the Phoenix (2007), with distance of 0.3396233320236206: 3: Harry Potter and the Goblet of Fire (2005), with distance of 0.4170845150947571: 4: Harry Potter and the Prisoner of Azkaban (2004), with distance of 0.4499547481536865: 5: Harry Potter and the Chamber of Secrets (2002), with distance of 0.4506162405014038:
至此我们已经能够成功构建了一个仅基于用户评分的推荐引擎。
以下是我们构建电影推荐系统的步骤摘要:
以下是可以扩展项目的一些方法:
Das obige ist der detaillierte Inhalt vonErstellen Sie mit Python ein Filmempfehlungssystem. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



