


Die tägliche Arbeit von Datenanalysten umfasst verschiedene Aufgaben, wie z. B. Datenvorverarbeitung, Datenanalyse, Modellerstellung für maschinelles Lernen und Modellbereitstellung.
In diesem Artikel werde ich 10 Python-Operationen vorstellen, die 90 % der Datenanalyseprobleme abdecken können. Gewinnen Sie Likes, Favoriten und Aufmerksamkeit.
Das Lesen von Daten ist ein wesentlicher Bestandteil der Datenanalyse. Der erste Schritt für einen Datenanalysten ist. Hier ist ein Beispiel dafür, wie man mit Pandas eine CSV-Datei mit Covid-19-Daten liest.
import pandas as pd
# reading the countries_data file along with the location within read_csv function.
countries_df = pd.read_csv('C:/Users/anmol/Desktop/Courses/Python for Data Science/Code/countries_data.csv')
# showing the first 5 rows of the dataframe
countries_df.head()
Das Folgende ist die Ausgabe von states_df.head(), wir können damit die ersten 5 Zeilen des Datenrahmens anzeigen:
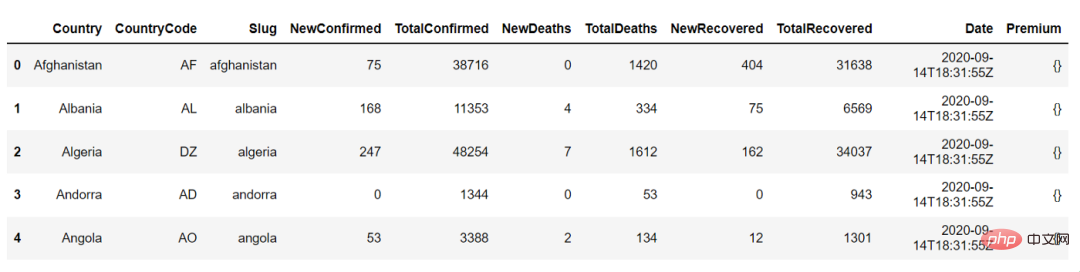
Der nächste Schritt besteht darin, die Daten zu verstehen Anzeigen der Datenzusammenfassung, z. B. NewConfirmed, der Anzahl, des Mittelwerts, der Standardabweichung, des Quantils numerischer Spalten wie TotalConfirmed sowie der Häufigkeit und des höchsten Vorkommenswerts kategorialer Spalten wie Ländercode
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">countries_df</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">describe</span>()
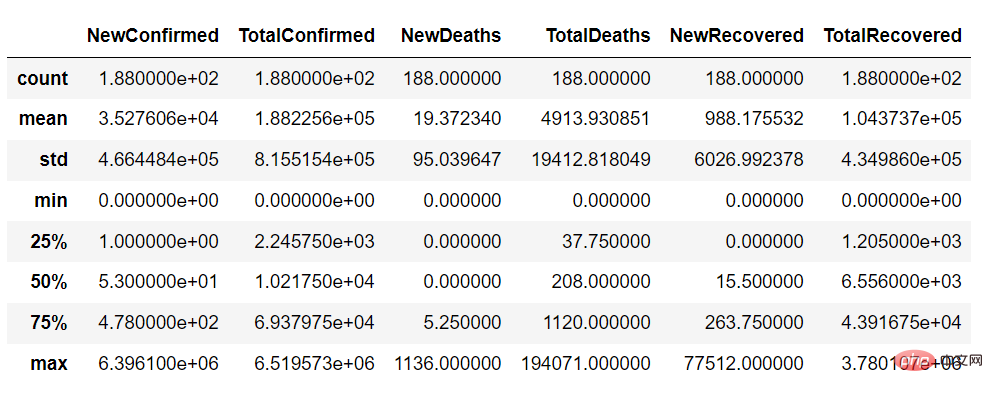
Mit der Beschreibungsfunktion können wir Folgendes erhalten eine Zusammenfassung der kontinuierlichen Variablen des Datensatzes wie folgt:
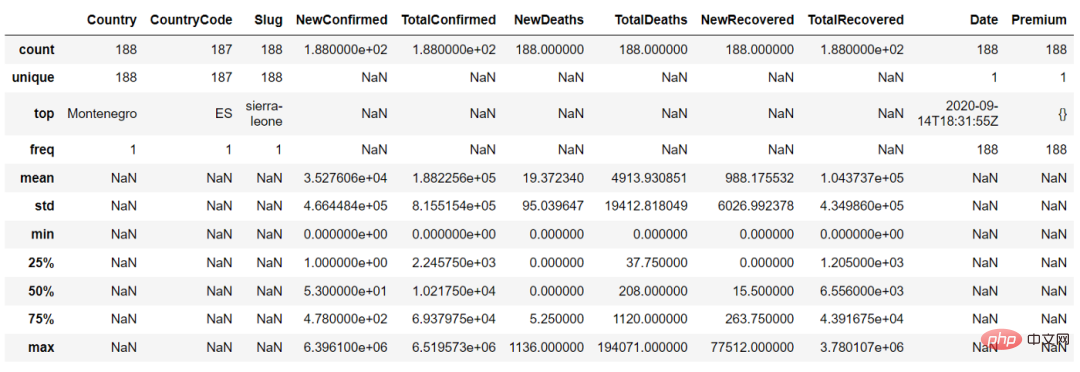
In der Funktion discover() können wir den Parameter „include = 'all'“ setzen, um die Zusammenfassung der kontinuierlichen Variablen und kategorialen Variablen zu erhalten
countries_df.describe(include = 'all')
Für die Analyse ist eigentlich kein Datensatz aller Zeilen und Spalten erforderlich. Wählen Sie einfach die gewünschten Spalten aus und filtern Sie einige Zeilen basierend auf der Frage.
Zum Beispiel können wir den folgenden Code verwenden, um die Spalten „Land“ und „Neu bestätigt“ auszuwählen:
countries_df[['Country','NewConfirmed']]
Mit loc können wir die Spalten auch anhand einiger Werte wie folgt filtern:
countries_df.loc[countries_df['Country'] == 'United States of America']

Datenaggregation wie Zählungen, Summen und Durchschnittswerte sind eine der am häufigsten durchgeführten Aufgaben in der Datenanalyse.
Mit Hilfe der Aggregation können wir die Gesamtzahl der NewConfimed-Fälle nach Ländern ermitteln. Verwenden Sie die Funktionen „groupby“ und „agg“, um eine Aggregation durchzuführen.
countries_df.groupby(['Country']).agg({'NewConfirmed':'sum'})Verwenden Sie die Join-Operation, um zwei Datensätze zu einem Datensatz zu kombinieren.
Zum Beispiel: Ein Datensatz kann die Anzahl der Covid-19-Fälle in verschiedenen Ländern enthalten, ein anderer Datensatz kann Informationen zu Breiten- und Längengraden für verschiedene Länder enthalten.
Jetzt müssen wir diese beiden Informationen kombinieren, dann können wir den Verbindungsvorgang wie unten gezeigt ausführen
countries_lat_lon = pd.read_excel('C:/Users/anmol/Desktop/Courses/Python for Data Science/Code/countries_lat_lon.xlsx')
# joining the 2 dataframe : countries_df and countries_lat_lon
# syntax : pd.merge(left_df, right_df, on = 'on_column', how = 'type_of_join')
joined_df = pd.merge(countries_df, countries_lat_lon, on = 'CountryCode', how = 'inner')
joined_dfVerstehen Sie die mathematischen integrierten Funktionen wie min(), max(), mean(), sum() usw. sind sehr hilfreich für die Durchführung verschiedener Analysen.
Wir können diese Funktionen direkt auf den Datenrahmen anwenden, indem wir sie aufrufen. Diese Funktionen können unabhängig auf Spalten oder in Aggregatfunktionen verwendet werden, wie unten gezeigt:
# finding sum of NewConfirmed cases of all the countries
countries_df['NewConfirmed'].sum()
# Output : 6,631,899
# finding the sum of NewConfirmed cases across different countries
countries_df.groupby(['Country']).agg({'NewConfirmed':'sum'})
# Output
#NewConfirmed
#Country
#Afghanistan75
#Albania 168
#Algeria 247
#Andorra0
#Angola53Funktion, die wir selbst geschrieben haben. Es ist eine Benutzerdefinierte Funktion. Wir können den Code in diesen Funktionen bei Bedarf ausführen, indem wir die Funktion aufrufen. Wir können zum Beispiel eine Funktion erstellen, die zwei Zahlen wie folgt addiert:
# User defined function is created using 'def' keyword, followed by function definition - 'addition()' # and 2 arguments num1 and num2 def addition(num1, num2): return num1+num2 # calling the function using function name and providing the arguments print(addition(1,2)) #output : 3
Pivot ist eine großartige Datenverarbeitungstechnik, die eindeutige Werte innerhalb einer Spaltenzeile in mehrere neue Spalten umwandelt.
Mit der Funktion „pivot_table()“ für den Covid-19-Datensatz können wir die Ländernamen in separate neue Spalten umwandeln:
# using pivot_table to convert values within the Country column into individual columns and # filling the values corresponding to these columns with numeric variable - NewConfimed pivot_df = pd.pivot_table(countries_df,columns = 'Country', values = 'NewConfirmed') pivot_df
Oft müssen wir die Indizes und Zeilen der Daten durchqueren Rahmen können wir die Funktion iterrows verwenden, um den Datenrahmen zu durchlaufen:
# iterating over the index and row of a dataframe using iterrows() function
for index, row in countries_df.iterrows():
print('Index is ' + str(index))
print('Country is '+ str(row['Country']))
# Output :
# Index is 0
# Country is Afghanistan
# Index is 1
# Country is Albania
# .......Oft beschäftigen wir uns mit String-Spalten im Datensatz. In diesem Fall ist es wichtig, einige grundlegende String-Operationen zu verstehen.
Zum Beispiel, wie man eine Zeichenfolge in Groß- und Kleinbuchstaben umwandelt und wie man die Länge einer Zeichenfolge ermittelt.
# country column to upper case countries_df['Country_upper'] = countries_df['Country'].str.upper() # country column to lower case countries_df['CountryCode_lower']=countries_df['CountryCode'].str.lower() # finding length of characters in the country column countries_df['len'] = countries_df['Country'].str.len() countries_df.head()
Das obige ist der detaillierte Inhalt vonZehn Python-Tipps decken 90 % des Datenanalysebedarfs ab!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



