


In diesem Artikel stellen wir ein beliebtes Projekt für maschinelles Lernen vor – den Textgenerator. Sie erfahren, wie Sie einen Textgenerator erstellen und wie Sie eine Markov-Kette implementieren, um ein schnelleres Vorhersagemodell zu erhalten.

Die Textgenerierung ist in verschiedenen Branchen beliebt, insbesondere in den Bereichen Mobilgeräte, Apps und Datenwissenschaft. Sogar die Presse nutzt die Textgenerierung, um den Schreibprozess zu unterstützen.
Im täglichen Leben sind wir mit einigen Textgenerierungstechnologien konfrontiert. Textvervollständigung, Suchvorschläge, Smart Compose und Chatbots sind alles Beispiele für Anwendungen.
In diesem Artikel wird die Markov-Kette zum Erstellen eines Textgenerators verwendet. Dies wäre ein zeichenbasiertes Modell, das das vorherige Zeichen der Kette übernimmt und den nächsten Buchstaben in der Sequenz generiert.
Durch das Trainieren unseres Programms anhand von Beispielwörtern lernt der Textgenerator gängige Zeichenreihenfolgemuster. Der Textgenerator wendet diese Muster dann auf die Eingabe an, bei der es sich um ein unvollständiges Wort handelt, und gibt das Zeichen aus, das mit der höchsten Wahrscheinlichkeit das Wort vervollständigt.
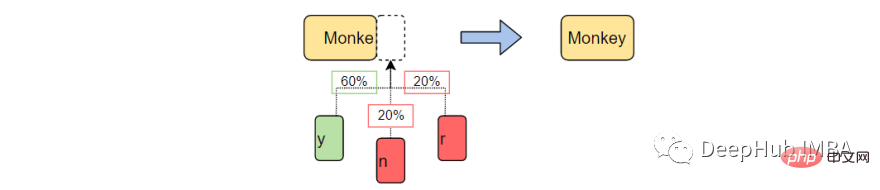
Die Textgenerierung ist ein Zweig der Verarbeitung natürlicher Sprache, der das nächste Zeichen basierend auf zuvor beobachteten Sprachmustern vorhersagt und generiert.
Vor dem maschinellen Lernen führte NLP die Textgenerierung durch, indem es eine Tabelle mit allen Wörtern in der englischen Sprache erstellte und die übergebene Zeichenfolge mit vorhandenen Wörtern abgleichte. Bei diesem Ansatz gibt es zwei Probleme.
Das Aufkommen von maschinellem Lernen und tiefem Lernen (NLP) ermöglicht es uns, die Laufzeit drastisch zu verkürzen und die Allgemeingültigkeit zu erhöhen, da der Generator Wörter vervollständigen kann, auf die er noch nie zuvor gestoßen ist. NLP kann auf Wunsch erweitert werden, um Wörter, Phrasen oder Sätze vorherzusagen.
Für dieses Projekt verwenden wir ausschließlich Markov-Ketten. Markov-Prozesse sind die Grundlage vieler Projekte zur Verarbeitung natürlicher Sprache, bei denen es um geschriebene Sprache und die Simulation von Beispielen aus komplexen Verteilungen geht.
Markov-Prozesse sind so leistungsstark, dass sie dazu verwendet werden können, mit nur einem Beispieldokument scheinbar real aussehenden Text zu generieren.
Eine Markov-Kette ist ein stochastischer Prozess, der eine Abfolge von Ereignissen modelliert, bei der die Wahrscheinlichkeit jedes Ereignisses vom Zustand des vorherigen Ereignisses abhängt. Das Modell verfügt über eine endliche Menge von Zuständen und die bedingte Wahrscheinlichkeit, von einem Zustand in einen anderen zu wechseln, ist fest.
Die Wahrscheinlichkeit jedes Übergangs hängt nur vom vorherigen Zustand des Modells ab, nicht vom gesamten Ereignisverlauf.
Angenommen, Sie möchten ein Markov-Kettenmodell erstellen, um das Wetter vorherzusagen.
In diesem Modell haben wir zwei Zustände, sonnig oder regnerisch. Wenn wir heute einen sonnigen Tag haben, ist die Wahrscheinlichkeit (70 %) höher, dass es morgen sonnig sein wird. Das Gleiche gilt für Regen; wenn es bereits geregnet hat, wird es wahrscheinlich weiter regnen.
Aber es ist möglich (30 %), dass sich das Wetter ändert, deshalb beziehen wir dies auch in unser Markov-Kettenmodell ein.
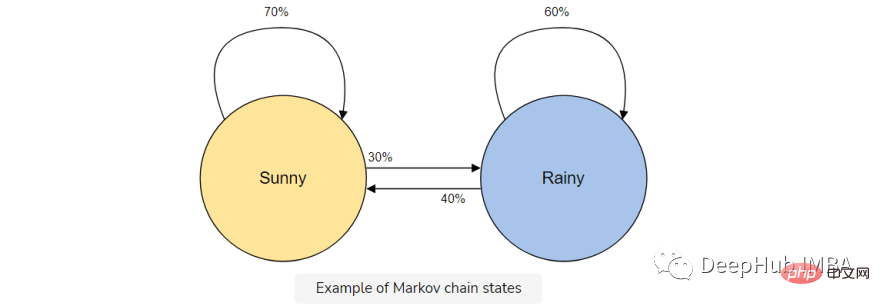
Die Markov-Kette ist das perfekte Modell für unseren Textgenerator, da unser Modell das nächste Zeichen nur anhand des vorherigen Zeichens vorhersagt. Die Vorteile der Verwendung einer Markov-Kette bestehen darin, dass sie genau ist, weniger Speicher benötigt (es wird nur ein vorheriger Zustand gespeichert) und schnell ausgeführt werden kann.
Hier vervollständigen wir den Textgenerator in 6 Schritten:

Zunächst erstellen wir eine Tabelle, um das Auftreten jedes Zeichenzustands im Trainingskorpus aufzuzeichnen. Speichern Sie die letzten „K“-Zeichen und „K+1“-Zeichen aus dem Trainingskorpus und speichern Sie sie in einer Nachschlagetabelle.
Stellen Sie sich zum Beispiel vor, dass unser Schulungskorpus Folgendes enthält: „Der Mann war, sie, dann, der, der“. Dann beträgt die Häufigkeit des Vorkommens des Wortes:
Das Folgende sind die Ergebnisse der Suche Tisch:

Im obigen Beispiel nehmen wir K = 3, was bedeutet, dass 3 Zeichen gleichzeitig berücksichtigt werden und das nächste Zeichen (K+1) als Ausgabezeichen verwendet wird. Behandeln Sie das Wort (X) als Zeichen in der obigen Nachschlagetabelle und das Ausgabezeichen (Y) als einzelnes Leerzeichen („“), da nach dem ersten kein Wort steht. Außerdem wird berechnet, wie oft diese Sequenz im Datensatz vorkommt, in diesem Fall dreimal.
Auf diese Weise werden Daten für jedes Wort im Korpus generiert, d. h. alle möglichen X- und Y-Paare werden generiert.
So generieren wir die Nachschlagetabelle im Code:
def generateTable(data,k=4):
T = {}
for i in range(len(data)-k):
X = data[i:i+k]
Y = data[i+k]
#print("X %s and Y %s "%(X,Y))
if T.get(X) is None:
T[X] = {}
T[X][Y] = 1
else:
if T[X].get(Y) is None:
T[X][Y] = 1
else:
T[X][Y] += 1
return T
T = generateTable("hello hello helli")
print(T)
#{'llo ': {'h': 2}, 'ello': {' ': 2}, 'o he': {'l': 2}, 'lo h': {'e': 2}, 'hell': {'i': 1, 'o': 2}, ' hel': {'l': 2}}Einfache Erklärung des Codes:
In Zeile 3 wird ein Wörterbuch erstellt, das X und die entsprechenden Y- und Häufigkeitswerte speichert. Die Zeilen 9 bis 17 prüfen, ob X und Y vorkommen. Wenn im Nachschlagewörterbuch bereits ein X- und Y-Paar vorhanden ist, erhöhen Sie es einfach um 1.
Sobald wir diese Tabelle und die Anzahl der Vorkommen haben, können wir die Wahrscheinlichkeit für das Auftreten von Y nach einem bestimmten Vorkommen von x ermitteln. Die Formel lautet:
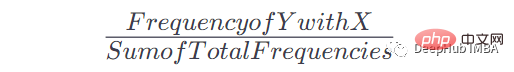
Wenn beispielsweise Wenden Sie diese Formel an, um die Nachschlagetabelle in eine nutzbare Wahrscheinlichkeit der Markov-Kette umzuwandeln:
def convertFreqIntoProb(T):
for kx in T.keys():
s = float(sum(T[kx].values()))
for k in T[kx].keys():
T[kx][k] = T[kx][k]/s
return T
T = convertFreqIntoProb(T)
print(T)
#{'llo ': {'h': 1.0}, 'ello': {' ': 1.0}, 'o he': {'l': 1.0}, 'lo h': {'e': 1.0}, 'hell': {'i': 0.3333333333333333, 'o': 0.6666666666666666}, ' hel': {'l': 1.0}}Einfache Erklärung:
Summieren Sie die Häufigkeitswerte eines bestimmten Schlüssels und dividieren Sie dann jeden Häufigkeitswert für diesen Schlüssel durch diesen Mehrwert, um die zu erhalten Wahrscheinlichkeit.
3. Laden Sie den Datensatz
Als nächstes wird der eigentliche Trainingskorpus geladen. Sie können jedes gewünschte Langtextdokument (.txt) verwenden.
text_path = "train_corpus.txt"
def load_text(filename):
with open(filename,encoding='utf8') as f:
return f.read().lower()
text = load_text(text_path)
print('Loaded the dataset.')Dieser Datensatz kann für unser Beispielprojekt genügend Ereignisse bereitstellen, um einigermaßen genaue Vorhersagen zu treffen. Wie bei jedem maschinellen Lernen führt ein größerer Trainingskorpus zu genaueren Vorhersagen.
4. Erstellen Sie eine Markov-Kette
Lassen Sie uns eine Markov-Kette erstellen und jedem Zeichen die Wahrscheinlichkeit zuordnen. Die in den Schritten 1 und 2 erstellten Funktionen „generateTable()“ und „convertFreqIntoProb()“ werden hier zum Erstellen des Markov-Modells verwendet.
def MarkovChain(text,k=4): T = generateTable(text,k) T = convertFreqIntoProb(T) return T model = MarkovChain(text)
5. Text-Sampling
Erstellen Sie eine Sampling-Funktion, die das unvollendete Wort (ctx), das Markov-Kettenmodell (Modell) aus Schritt 4 und die Anzahl der Zeichen verwendet, die zur Bildung der Wortbasis (k) verwendet werden.
import numpy as np
def sample_next(ctx,model,k):
ctx = ctx[-k:]
if model.get(ctx) is None:
return " "
possible_Chars = list(model[ctx].keys())
possible_values = list(model[ctx].values())
print(possible_Chars)
print(possible_values)
return np.random.choice(possible_Chars,p=possible_values)
sample_next("commo",model,4)
#['n']
#[1.0]Code-Erklärung:
Die Funktion sample_next akzeptiert drei Parameter: ctx, model und k-Wert.
ctx ist Text, der zum Generieren eines neuen Textes verwendet wird. Aber hier werden nur die letzten K Zeichen in ctx vom Modell verwendet, um das nächste Zeichen in der Sequenz vorherzusagen. Beispielsweise übergeben wir common, K = 4, und der Text, den das Modell zum Generieren des nächsten Zeichens verwendet, ist ommo, da das Markov-Modell nur den vorherigen Verlauf verwendet.
In den Zeilen 9 und 10 werden die möglichen Zeichen und ihre Wahrscheinlichkeitswerte abgedruckt, da diese Zeichen auch in unserem Modell vorhanden sind. Wir erhalten, dass das nächste vorhergesagte Zeichen n ist, mit einer Wahrscheinlichkeit von 1,0. Da es wahrscheinlicher ist, dass das Wort „commo“ häufiger vorkommt, nachdem das nächste Zeichen generiert wurde.
In Zeile 12 geben wir ein Zeichen zurück, das auf dem oben diskutierten Wahrscheinlichkeitswert basiert.
6. Text generieren
Kombinieren Sie abschließend alle oben genannten Funktionen, um Text zu generieren.
def generateText(starting_sent,k=4,maxLen=1000):
sentence = starting_sent
ctx = starting_sent[-k:]
for ix in range(maxLen):
next_prediction = sample_next(ctx,model,k)
sentence += next_prediction
ctx = sentence[-k:]
return sentence
print("Function Created Successfully!")
text = generateText("dear",k=4,maxLen=2000)
print(text)dear country brought new consciousness. i heartily great service of their lives, our country, many of tricoloring a color flag on their lives independence today.my devoted to be oppression of independence.these day the obc common many country, millions of oppression of massacrifice of indian whom everest. my dear country is not in the sevents went was demanding and nights by plowing in the message of the country is crossed, oppressed, women, to overcrowding for years of the south, it is like the ashok chakra of constitutional states crossed, deprived, oppressions of freedom, i bow my heart to proud of our country.my dear country, millions under to be a hundred years of the south, it is going their heroes.
Die obige Funktion akzeptiert drei Parameter: das Startwort des generierten Textes, den Wert von K und die maximale Zeichenlänge des erforderlichen Textes. Das Ausführen des Codes führt zu einem Text mit 2000 Zeichen, der mit „dear“ beginnt.
Obwohl diese Rede vielleicht nicht viel Sinn ergibt, sind die Wörter vollständig und ahmen oft bekannte Muster in Wörtern nach.
Was Sie als Nächstes lernen sollten
Dies ist ein einfaches Textgenerierungsprojekt. Nutzen Sie dieses Projekt, um zu erfahren, wie die Verarbeitung natürlicher Sprache und Markov-Ketten in Aktion funktionieren, was Sie auf Ihrer Deep-Learning-Reise nutzen können.
Das obige ist der detaillierte Inhalt vonErstellen von Textgeneratoren mithilfe von Markov-Ketten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



