


Übersetzer |. Li Rui
Rezensent |.Das BigScience-Forschungsprojekt hat kürzlich ein großes Sprachmodell BLOOM veröffentlicht. Auf den ersten Blick sieht es wie ein weiterer Versuch aus, OpenAIs GPT-3 zu kopieren.
Aber was BLOOM von anderen groß angelegten Modellen natürlicher Sprache (LLMs) unterscheidet, sind seine Bemühungen bei der Erforschung, Entwicklung, Schulung und Veröffentlichung von Modellen für maschinelles Lernen.
In den letzten Jahren haben große Technologieunternehmen groß angelegte Modelle natürlicher Sprache (LLM) wie streng gehütete Geschäftsgeheimnisse versteckt, und das BigScience-Team hat von Beginn des Projekts an Transparenz und Offenheit in den Mittelpunkt von BLOOM gestellt.
Das Ergebnis ist ein großes Sprachmodell, das zum Forschen und Lernen bereit ist und für jedermann verfügbar ist. Das von BLOOM etablierte Beispiel von Open Source und offener Zusammenarbeit wird für die zukünftige Forschung in groß angelegten Modellen natürlicher Sprache (LLM) und anderen Bereichen der künstlichen Intelligenz von großem Nutzen sein. Es gibt jedoch immer noch einige Herausforderungen, die großen Sprachmodellen innewohnen und angegangen werden müssen.
Was ist BLOOM?
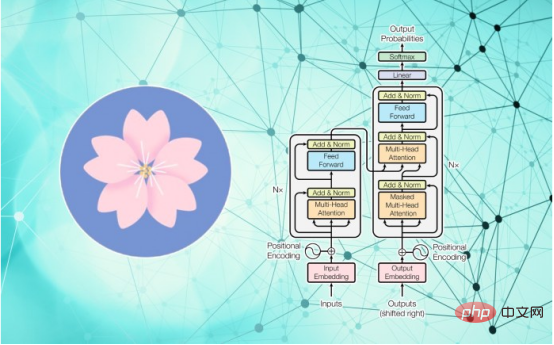 BLOOM ist die Abkürzung für „BigScience Large-Scale Open Science Open Access Multilingual Model“. Aus Datensicht unterscheidet es sich nicht wesentlich von GPT-3 und OPT-175B. Es handelt sich um ein sehr großes Transformer-Modell mit 176 Milliarden Parametern, das mit 1,6 TB Daten trainiert wurde, einschließlich natürlicher Sprache und Software-Quellcode.
BLOOM ist die Abkürzung für „BigScience Large-Scale Open Science Open Access Multilingual Model“. Aus Datensicht unterscheidet es sich nicht wesentlich von GPT-3 und OPT-175B. Es handelt sich um ein sehr großes Transformer-Modell mit 176 Milliarden Parametern, das mit 1,6 TB Daten trainiert wurde, einschließlich natürlicher Sprache und Software-Quellcode.
Wie GPT-3 kann es viele Aufgaben durch Null-Schuss- oder Wenig-Schuss-Lernen ausführen, einschließlich Textgenerierung, Zusammenfassung, Beantwortung von Fragen und Programmierung.
Aber die Bedeutung von BLOOM liegt in der Organisation und dem Bauprozess dahinter.
BigScience ist ein 2021 vom Machine Learning Model Center „Hugging Face“ ins Leben gerufenes Forschungsprojekt. Laut der Beschreibung auf seiner Website zielt das Projekt darauf ab, „eine alternative Möglichkeit aufzuzeigen, große Sprachmodelle und große Forschungsartefakte innerhalb der KI/NLP-Forschungsgemeinschaft zu erstellen, zu lernen und zu teilen.“ In dieser Hinsicht wird BigScience from Europe Inspiration herangezogen von wissenschaftlichen Initiativen wie dem Zentrum für Kernforschung (CERN) und dem Large Hadron Collider (LHC), wo eine offene wissenschaftliche Zusammenarbeit die Schaffung groß angelegter Artefakte fördert, die für die gesamte Forschungsgemeinschaft nützlich sind.
In einem Jahr seit Mai 2021 haben mehr als 1.000 Forscher aus 60 Ländern und mehr als 250 Institutionen BLOOM in BigScience mitgestaltet.
Transparenz, Offenheit und Inklusion
Während die meisten großen groß angelegten Modelle natürlicher Sprache (LLMs) nur auf englischem Text trainiert werden, umfasst das Trainingskorpus von BLOOM 46 natürliche Sprachen und 13 Programmiersprachen. Dies ist in vielen Regionen nützlich, in denen die Hauptsprache nicht Englisch ist.
Im Gegensatz dazu erhielt das BigScience-Forschungsteam vom französischen Nationalen Zentrum für wissenschaftliche Forschung einen Zuschuss in Höhe von 3 Millionen Euro, um BLOOM auf dem Supercomputer Jean Zay zu trainieren. Es gibt keine Vereinbarung, die einem kommerziellen Unternehmen eine exklusive Lizenz für die Technologie gewährt, noch gibt es eine Verpflichtung, das Modell zu kommerzialisieren und in ein profitables Produkt umzuwandeln.
Darüber hinaus ist das BigScience-Team hinsichtlich des gesamten Modellschulungsprozesses völlig transparent. Sie veröffentlichen Datensätze, Sitzungsprotokolle, Diskussionen und Code sowie Protokolle und technische Details von Trainingsmodellen.
Forscher untersuchen die Daten und Metadaten des Modells und veröffentlichen interessante Erkenntnisse.
Zum Beispiel twitterte der Forscher David McClure am 12. Juli 2022: „Ich habe mir den Trainingsdatensatz hinter dem wirklich coolen BLOOM-Modell von Bigscience und Hugging Face angesehen. Es gibt einige aus dem englischen Korpus 10 Millionen Proben, etwa 1,25.“ % der Gesamtmenge, codiert mit „all-distilroberta-v1“, dann UMAP auf 2d. „
Natürlich kann das trainierte Modell selbst auf der Plattform von Hugging Face heruntergeladen werden, was dieses Problem lindert. Forscher haben Millionen von Dollar für die Schulung ausgegeben.
Facebook hat letzten Monat unter einigen Einschränkungen eines seiner groß angelegten Modelle in natürlicher Sprache (LLM) als Open Source bereitgestellt. Die durch BLOOM geschaffene Transparenz ist jedoch beispiellos und verspricht, einen neuen Standard für die Branche zu setzen.
Teven LeScao, Co-Leiter der BLOOM-Schulung, sagte: „Im Gegensatz zur Geheimhaltung industrieller KI-Forschungslabore zeigt BLOOM, dass die leistungsstärksten KI-Modelle von der breiteren Forschungsgemeinschaft auf verantwortungsvolle und offene Weise trainiert und veröffentlicht werden können.“ .
Herausforderungen bleiben
Während die Bemühungen von BigScience, Offenheit und Transparenz in die KI-Forschung und groß angelegte Sprachmodelle zu bringen, lobenswert sind, bleiben die Herausforderungen, die diesem Bereich innewohnen, unverändert.
Die groß angelegte Forschung an natürlichen Sprachmodellen (LLM) geht in Richtung immer größerer Modelle, was die Schulungs- und Betriebskosten weiter erhöhen wird. BLOOM verwendet für das Training 384 Nvidia Tesla A100-GPUs (Preis pro Stück etwa 32.000 US-Dollar). Und größere Modelle erfordern größere Rechencluster. Das BigScience-Team hat angekündigt, weiterhin weitere Open-Source-LLMs (große natürliche Sprachmodelle) zu erstellen, es bleibt jedoch abzuwarten, wie das Team seine immer teurer werdende Forschung finanzieren wird. OpenAI begann beispielsweise als gemeinnützige Organisation und entwickelte sich später zu einer gewinnorientierten Organisation, die Produkte verkauft und auf die Finanzierung von Microsoft angewiesen ist.
Ein weiteres zu lösendes Problem sind die enormen Kosten für den Betrieb dieser Modelle. Das komprimierte BLOOM-Modell ist 227 GB groß und erfordert für seine Ausführung spezielle Hardware mit Hunderten von GB Speicher. Zum Vergleich: Für GPT-3 ist ein Rechencluster erforderlich, der einem Nvidia DGX 2 entspricht und etwa 400.000 US-Dollar kostet. Hugging Face plant die Einführung einer API-Plattform, die es Forschern ermöglichen wird, das Modell für etwa 40 US-Dollar pro Stunde zu nutzen, was erhebliche Kosten darstellt.
Die Kosten für den Betrieb von BLOOM wirken sich auch auf die Community für angewandtes maschinelles Lernen, Start-ups und Organisationen aus, die Produkte entwickeln möchten, die auf groß angelegten Modellen natürlicher Sprache (LLMs) basieren. Derzeit eignet sich die von OpenAI bereitgestellte GPT-3-API besser für die Produktentwicklung. Es wird interessant sein zu sehen, welche Richtung BigScience und Hugging Face einschlagen, um Entwicklern die Entwicklung von Produkten auf der Grundlage ihrer wertvollen Forschung zu ermöglichen.
In diesem Zusammenhang freut man sich darauf, dass in Zukunft kleinere Versionen der Modelle von BigScience erscheinen. Entgegen der häufigen Darstellung in den Medien gilt bei Large Natural Language Models (LLMs) immer noch das „No Free Lunch“-Prinzip. Dies bedeutet, dass bei der Anwendung von maschinellem Lernen ein kompakteres Modell, das auf eine bestimmte Aufgabe abgestimmt ist, effektiver ist als ein sehr großes Modell mit durchschnittlicher Leistung bei vielen Aufgaben. Codex ist beispielsweise eine modifizierte Version von GPT-3, die große Unterstützung bei der Programmierung zu einem Bruchteil der Größe und Kosten von GPT-3 bietet. GitHub bietet derzeit ein Codex-basiertes Produkt, Copilot, für 10 US-Dollar pro Monat an.
Es wird interessant sein zu untersuchen, wohin sich akademische und angewandte KI in Zukunft entwickeln wird, da BLOOM eine neue Kultur aufbauen möchte.
Originaltitel: BLOOM kann eine neue Kultur für die KI-Forschung schaffen – aber Herausforderungen bleiben bestehen, Autor: Ben Dickson
Das obige ist der detaillierte Inhalt vonBLOOM kann eine neue Kultur für die KI-Forschung schaffen, aber es bleiben Herausforderungen bestehen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Anwendung künstlicher Intelligenz im Leben
Anwendung künstlicher Intelligenz im Leben
 Was ist das Grundkonzept der künstlichen Intelligenz?
Was ist das Grundkonzept der künstlichen Intelligenz?
 Es ist nicht möglich, das Standard-Gateway des Computers zu reparieren
Es ist nicht möglich, das Standard-Gateway des Computers zu reparieren
 Die acht am häufigsten verwendeten Funktionen in Excel
Die acht am häufigsten verwendeten Funktionen in Excel
 Nutzung der Bodenfunktion
Nutzung der Bodenfunktion
 Windows kann keine Verbindung zur WLAN-Lösung herstellen
Windows kann keine Verbindung zur WLAN-Lösung herstellen
 So verwenden Sie die Shift-Hintertür
So verwenden Sie die Shift-Hintertür
 Methode zur Erstellung von Intouch-Berichten
Methode zur Erstellung von Intouch-Berichten








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



