


Spark ist ein Open-Source-Framework, das für interaktive Abfragen, maschinelles Lernen und Echtzeit-Workloads entwickelt wurde, und PySpark ist eine Bibliothek für Python, die Spark verwendet.
PySpark ist eine hervorragende Sprache für die Durchführung explorativer Datenanalysen im großen Maßstab, den Aufbau von Pipelines für maschinelles Lernen und die Erstellung von ETL für Datenplattformen. Wenn Sie bereits mit Bibliotheken wie Python und Pandas vertraut sind, ist PySpark eine großartige Sprache zum Erlernen und Erstellen skalierbarerer Analysen und Pipelines.
Der Zweck dieses Artikels besteht darin, zu zeigen, wie man mit PySpark ein Modell für maschinelles Lernen erstellt.
Conda verwaltet fast alle Tools und Pakete von Drittanbietern als Pakete, sogar Python und Conda selbst. Anaconda ist eine gepackte Sammlung, die mit Conda, einer bestimmten Python-Version, verschiedenen Paketen usw. vorinstalliert ist.
Öffnen Sie die Befehlszeile und geben Sie conda -V ein, um zu überprüfen, ob es installiert ist und die aktuelle Conda-Version hat.
Installieren Sie die Standardversion von Python über Anaconda 3.6, die Anaconda3-5.2 entspricht, und Python 3.7 nach 5.3.
(https://repo.anaconda.com/archive/)
1) Überprüfen Sie, welche Pakete installiert sind
conda list
2) Überprüfen Sie, welche virtuellen Umgebungen derzeit vorhanden sind
conda env list <br>conda info -e
3) Aktivieren Sie „Aktualisieren Sie die aktuelle Conda
conda update conda
4. Aktivieren oder wechseln Sie die virtuelle Umgebung.
conda create -n your_env_name python=x.x
5. Installieren Sie zusätzliche Pakete in der virtuellen Umgebung
Linux:source activate your_env_nam<br>Windows: activate your_env_name
conda install -n your_env_name [package]
deactivate env_name<br># 或者`activate root`切回root环境<br>Linux下:source deactivate
9. Richten Sie einen inländischen Spiegel ein
conda remove -n your_env_name --all
conda remove --name $your_env_name$package_name
Der Installationsprozess von PySpark ist so einfach wie bei anderen Python-Paketen ( wie Pandas, Numpy, scikit-learn).
# 添加Anaconda的TUNA镜像<br>conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/<br><br># 设置搜索时显示通道地址<br>conda config --set show_channel_urls yes
 Der Datensatz besteht aus mehreren medizinischen Prädiktorvariablen und einer Zielvariablen Ergebnis. Zu den Prädiktorvariablen gehören die Anzahl der Schwangerschaften der Patientin, der BMI, der Insulinspiegel, das Alter usw. Schwangerschaften: Anzahl der Schwangerschaften Glukose: Blutzuckerkonzentration des oralen Glukosetoleranztests innerhalb von 2 Stunden Blutdruck: diastolischer Blutdruck (mm Hg)
Der Datensatz besteht aus mehreren medizinischen Prädiktorvariablen und einer Zielvariablen Ergebnis. Zu den Prädiktorvariablen gehören die Anzahl der Schwangerschaften der Patientin, der BMI, der Insulinspiegel, das Alter usw. Schwangerschaften: Anzahl der Schwangerschaften Glukose: Blutzuckerkonzentration des oralen Glukosetoleranztests innerhalb von 2 Stunden Blutdruck: diastolischer Blutdruck (mm Hg) conda config --remove-key channels
from pyspark.sql import SparkSession<br>spark = SparkSession.builder.appName('ml-diabetes').getOrCreate()<br>df = spark.read.csv('diabetes.csv', header = True, inferSchema = True)<br>df.printSchema()import pandas as pd<br>pd.DataFrame(df.take(5), <br> columns=df.columns).transpose()

df.toPandas()
df.groupby('Outcome').count().toPandas() Datenvorbereitung und Feature-EngineeringIn diesem Teil werden wir unnötige Spalten entfernen und fehlende Werte füllen. Abschließend werden Funktionen für das Machine-Learning-Modell ausgewählt. Diese Funktionen werden in zwei Teile unterteilt: Training und Testen.
Datenvorbereitung und Feature-EngineeringIn diesem Teil werden wir unnötige Spalten entfernen und fehlende Werte füllen. Abschließend werden Funktionen für das Machine-Learning-Modell ausgewählt. Diese Funktionen werden in zwei Teile unterteilt: Training und Testen.  Behandlung fehlender Daten
Behandlung fehlender Daten
numeric_features = [t[0] for t in df.dtypes if t[1] == 'int']<br>df.select(numeric_features)<br>.describe()<br>.toPandas()<br>.transpose()
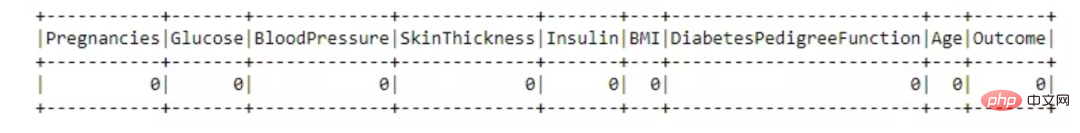
dataset = dataset.drop('SkinThickness')<br>dataset = dataset.drop('Insulin')<br>dataset = dataset.drop('DiabetesPedigreeFunction')<br>dataset = dataset.drop('Pregnancies')<br><br>dataset.show()
VectorAssembler —— 将多列合并为向量列的特征转换器。
# 用VectorAssembler合并所有特性<br>required_features = ['Glucose',<br>'BloodPressure',<br>'BMI',<br>'Age']<br><br>from pyspark.ml.feature import VectorAssembler<br><br>assembler = VectorAssembler(<br>inputCols=required_features, <br>outputCol='features')<br><br>transformed_data = assembler.transform(dataset)<br>transformed_data.show()
现在特征转换为向量已完成。
将数据随机分成训练集和测试集,并设置可重复性的种子。
(training_data, test_data) = transformed_data.randomSplit([0.8,0.2], seed =2020)<br>print("训练数据集总数: " + str(training_data.count()))<br>print("测试数据集总数: " + str(test_data.count()))训练数据集总数:620<br>测试数据集数量:148
随机森林是一种监督学习算法,用于分类和回归。但是,它主要用于分类问题。众所周知,森林是由树木组成的,树木越多,森林越茂盛。类似地,随机森林算法在数据样本上创建决策树,然后从每个样本中获取预测,最后通过投票选择最佳解决方案。这是一种比单个决策树更好的集成方法,因为它通过对结果进行平均来减少过拟合。
from pyspark.ml.classification import RandomForestClassifier<br><br>rf = RandomForestClassifier(labelCol='Outcome', <br>featuresCol='features',<br>maxDepth=5)<br>model = rf.fit(training_data)<br>rf_predictions = model.transform(test_data)
from pyspark.ml.evaluation import MulticlassClassificationEvaluator<br><br>multi_evaluator = MulticlassClassificationEvaluator(<br>labelCol = 'Outcome', metricName = 'accuracy')<br>print('Random Forest classifier Accuracy:', multi_evaluator.evaluate(rf_predictions))Random Forest classifier Accuracy:0.79452
决策树被广泛使用,因为它们易于解释、处理分类特征、扩展到多类分类设置、不需要特征缩放,并且能够捕获非线性和特征交互。
from pyspark.ml.classification import DecisionTreeClassifier<br><br>dt = DecisionTreeClassifier(featuresCol = 'features',<br>labelCol = 'Outcome',<br>maxDepth = 3)<br>dtModel = dt.fit(training_data)<br>dt_predictions = dtModel.transform(test_data)<br>dt_predictions.select('Glucose', 'BloodPressure', <br>'BMI', 'Age', 'Outcome').show(10)from pyspark.ml.evaluation import MulticlassClassificationEvaluator<br><br>multi_evaluator = MulticlassClassificationEvaluator(<br>labelCol = 'Outcome', <br>metricName = 'accuracy')<br>print('Decision Tree Accuracy:', <br>multi_evaluator.evaluate(dt_predictions))Decision Tree Accuracy: 0.78767
逻辑回归是在因变量是二分(二元)时进行的适当回归分析。与所有回归分析一样,逻辑回归是一种预测分析。逻辑回归用于描述数据并解释一个因二元变量与一个或多个名义、序数、区间或比率水平自变量之间的关系。当因变量(目标)是分类时,使用逻辑回归。
from pyspark.ml.classification import LogisticRegression<br><br>lr = LogisticRegression(featuresCol = 'features', <br>labelCol = 'Outcome', <br>maxIter=10)<br>lrModel = lr.fit(training_data)<br>lr_predictions = lrModel.transform(test_data)
评估我们的逻辑回归模型。
from pyspark.ml.evaluation import MulticlassClassificationEvaluator<br><br>multi_evaluator = MulticlassClassificationEvaluator(<br>labelCol = 'Outcome',<br>metricName = 'accuracy')<br>print('Logistic Regression Accuracy:', <br>multi_evaluator.evaluate(lr_predictions))Logistic Regression Accuracy:0.78767
梯度提升是一种用于回归和分类问题的机器学习技术,它以弱预测模型(通常是决策树)的集合形式生成预测模型。
from pyspark.ml.classification import GBTClassifier<br>gb = GBTClassifier(<br>labelCol = 'Outcome', <br>featuresCol = 'features')<br>gbModel = gb.fit(training_data)<br>gb_predictions = gbModel.transform(test_data)
评估我们的梯度提升树分类器。
from pyspark.ml.evaluation import MulticlassClassificationEvaluator<br>multi_evaluator = MulticlassClassificationEvaluator(<br>labelCol = 'Outcome',<br>metricName = 'accuracy')<br>print('Gradient-boosted Trees Accuracy:',<br>multi_evaluator.evaluate(gb_predictions))Gradient-boosted Trees Accuracy:0.80137
PySpark 是一种非常适合数据科学家学习的语言,因为它支持可扩展的分析和 ML 管道。如果您已经熟悉 Python 和 Pandas,那么您的大部分知识都可以应用于 Spark。总而言之,我们已经学习了如何使用 PySpark 构建机器学习应用程序。我们尝试了三种算法,梯度提升在我们的数据集上表现最好。
Das obige ist der detaillierte Inhalt vonErstellen Sie Modelle für maschinelles Lernen mit PySpark ML. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



