


Du hättest „Mission: Impossible 4“ von Brad Bird mit Tom Cruise in der Hauptrolle sehen sollen? In einem überfüllten Bahnhof braucht es nur einen Wimpernschlag, um vom Computer erkannt und sofort von Agenten verfolgt zu werden. Die schöne Frau, die ihn trifft, ist eine tödliche Mörderin, und das Mobiltelefon piept mit einem Alarmton, und die Schönheit Name und Informationen werden bereits darauf angezeigt. Dies ist der Gesichtserkennungsalgorithmus, den dieser Artikel vorstellen möchte, und wie die öffentliche Cloud-KI-Plattform zum Trainieren des Modells verwendet werden kann.
Als eine der früher ausgereiften und weit verbreiteten Technologien im Bereich der künstlichen Intelligenz besteht der Zweck der Gesichtserkennung darin, die Identität von Gesichtern in Bildern und Videos zu bestimmen. . Von der Gesichtserkennung zum Entsperren und Bezahlen von Mobiltelefonen bis hin zur Gesichtserkennungskontrolle im Sicherheitsbereich usw. bietet die Gesichtserkennungstechnologie ein breites Anwendungsspektrum. Das Gesicht ist ein angeborenes Merkmal jedes Menschen. Dieses Merkmal ist einzigartig und kann nicht einfach kopiert werden und stellt somit eine notwendige Voraussetzung für die Identitätsidentifizierung dar.
Die Forschung zur Gesichtserkennung begann in den 1960er Jahren mit der kontinuierlichen Verbesserung der Computertechnologie und der optischen Bildgebungstechnologie sowie dem Wiederaufkommen der neuronalen Netzwerktechnologie Der Aufstieg der Gesichtserkennungstechnologie, insbesondere der große Erfolg von Faltungs-Neuronalen Netzen bei der Bilderkennung und -erkennung, hat die Leistung von Gesichtserkennungssystemen erheblich verbessert. In diesem Artikel beginnen wir mit den technischen Details der Gesichtserkennungstechnologie und geben Ihnen einen ersten Einblick in den Entwicklungsprozess der Gesichtserkennungstechnologie. In der zweiten Hälfte des Artikels werden wir Ihnen das benutzerdefinierte Bild der ModelArts-Plattform zeigen Wie man öffentliche Cloud-Computing-Ressourcen nutzt, kann schnell ein brauchbares Gesichtserkennungsmodell trainieren.
Ob es auf traditioneller Bildverarbeitung und maschineller Lerntechnologie basiert oder Deep-Learning-Technologie verwendet, der Prozess ist derselbe. Wie in Abbildung 1 dargestellt, umfassen Gesichtserkennungssysteme vier grundlegende Verbindungen: Gesichtserkennung, Ausrichtung, Kodierung und Abgleich. Daher bietet dieser Teil zunächst einen Überblick über das Gesichtserkennungssystem, das auf herkömmlichen Bildverarbeitungs- und maschinellen Lernalgorithmen basiert, damit wir den Entwicklungskontext des gesamten Deep-Learning-Algorithmus im Bereich der Gesichtserkennung sehen können.

Gesichtserkennungsprozess
#🎜 🎜 #Wie bereits erwähnt, besteht der Zweck der Gesichtserkennung darin, die Identität des Gesichts im Bild zu bestimmen. Daher müssen wir zunächst das Gesicht im Bild erkennen. Tatsächlich ist dieser Schritt letztendlich ein Problem der Zielerkennung. Der herkömmliche Bildzielerkennungsalgorithmus besteht hauptsächlich aus drei Teilen: Vorschlagsrahmengenerierung, Feature-Engineering und Klassifizierung. Die Optimierungsideen, einschließlich der berühmten RCNN-Algorithmenreihe, basieren ebenfalls auf diesen drei Teilen.
Der erste Schritt besteht darin, das Vorschlagsfeld zu generieren. Die einfachste Idee für diesen Schritt besteht darin, eine Reihe von Feldern zuzuschneiden, die im Bild erkannt werden sollen, und dann zu erkennen, ob Wenn sich ein Ziel im Feld befindet, ist die Position des Rahmens im Originalbild die Position, an der das Ziel erkannt wird. Je größer die Abdeckung des Ziels in diesem Schritt ist, desto besser ist die vorgeschlagene Rahmengenerierungsstrategie . Zu den gängigen Strategien zur Generierung von Vorschlagsboxen gehören Schiebefenster, selektive Suche, randomisierte Prim usw., die eine große Anzahl von Kandidatenboxen generieren, wie in der folgenden Abbildung dargestellt.

Nachdem eine große Anzahl von Kandidatenrahmen erhalten wurde, ist der nächstwichtigste Teil des herkömmlichen Gesichtserkennungsalgorithmus die Funktion Maschinenbau . Feature Engineering nutzt tatsächlich die Expertenerfahrung von Algorithmusingenieuren, um verschiedene Features aus Gesichtern in verschiedenen Szenen zu extrahieren, wie z. B. Kantenmerkmale, Formmorphologiemerkmale, Texturmerkmale usw. Zu den spezifischen Algorithmustechnologien gehören LBP, Gabor, Haar, SIFT usw. Merkmalsextraktion Der Algorithmus wandelt ein durch eine zweidimensionale Matrix dargestelltes Gesichtsbild in die Darstellung verschiedener Merkmalsvektoren um.
Nachdem Sie den Merkmalsvektor erhalten haben, können Sie das Merkmal mithilfe herkömmlicher Klassifikatoren für maschinelles Lernen klassifizieren, um festzustellen, ob es sich um ein Gesicht handelt, z. B. durch Adaboost, Cascade, SVM, Random Wald usw. Nach der Klassifizierung durch einen herkömmlichen Klassifikator können Gesichtsfläche, Merkmalsvektor, Klassifizierungssicherheit usw. ermittelt werden. Mit diesen Informationen können wir die Gesichtsausrichtung, die Merkmalsdarstellung und die Erkennung von Gesichtsübereinstimmungen abschließen.
Nehmen Sie als Beispiel die traditionelle Methode, die klassische HAAR+AdaBoost-Methode. In der Phase der Merkmalsextraktion werden zunächst Haarmerkmale verwendet, um viele einfache Merkmale aus dem zu extrahieren Bild. . Haar-Merkmale sind in der folgenden Abbildung dargestellt. Um die Erkennung von Gesichtern unterschiedlicher Größe zu ermöglichen, werden normalerweise Gaußsche Pyramiden verwendet, um Haar-Merkmale aus Bildern unterschiedlicher Auflösung zu extrahieren.
Die Berechnungsmethode der Haar-Funktion besteht darin, den schwarzen Bereich von der Summe der Pixel im weißen Bereich zu subtrahieren, sodass die erhaltenen Werte im Gesichts- und Nichtgesichtsbereich unterschiedlich sind. Im Allgemeinen kann der spezifische Implementierungsprozess mithilfe der Integraldiagrammmethode schnell implementiert werden. Im Allgemeinen beträgt die Anzahl der verfügbaren Haar-Merkmale in den auf 20*20 normalisierten Trainingsbildern etwa 10.000. Daher können bei dieser Merkmalsskala maschinelle Lernalgorithmen zur Klassifizierung und Identifizierung verwendet werden.
Nachdem Sie die Haar-Funktionen erhalten haben, können Sie Adaboost zur Klassifizierung verwenden. Der Adaboost-Algorithmus ist eine Methode, die mehrere schwache Klassifizierungsmethoden kombiniert, um eine neue starke Klassifizierungsmethode zu bilden. Basierend auf dem Kaskadenklassifikator und den trainierten Merkmalsauswahlschwellenwerten kann die Gesichtserkennung abgeschlossen werden.
Aus der obigen Methode ist ersichtlich, dass der herkömmliche Algorithmus für maschinelles Lernen ein merkmalsbasierter Algorithmus ist. Daher ist für die Durchführung von Feature-Engineering und Parameteranpassung eine große Expertenerfahrung des Algorithmusingenieurs erforderlich, und der Algorithmuseffekt ist vorhanden nicht sehr gut. Darüber hinaus ist es für künstliches Design schwierig, in einer uneingeschränkten Umgebung robust gegenüber sich ändernden Bedingungen zu sein. In der Vergangenheit verwendeten Bildalgorithmen traditionellere Bildverarbeitungsmethoden von Ingenieuren, um eine große Anzahl von Merkmalen basierend auf realen Szenen und Expertenerfahrungen zu extrahieren, und führten dann statistisches Lernen an den extrahierten Merkmalen durch. Auf diese Weise wurde die Leistung des Gesamtalgorithmus ermittelt hängt stark von realistischen Szenen ab und Expertenerfahrungen zeigen, dass der Effekt für uneingeschränkte Szenen mit großen Kategorien wie Gesichtern und einem gravierenden Ungleichgewicht der Samples in jeder Kategorie nicht sehr gut ist. Aufgrund des großen Erfolgs von Deep Learning in der Bildverarbeitung in den letzten Jahren basiert daher auch die Gesichtserkennungstechnologie auf Deep Learning und hat sehr gute Ergebnisse erzielt.
Im Gesichtserkennungssystem des Deep Learning wird das Problem in ein Zielerkennungsproblem und ein Klassifizierungsproblem unterteilt. Das Wesentliche des Zielerkennungsproblems beim Deep Learning ist immer noch ein Klassifizierungsproblem und ein Regressionsproblem. Daher wurde die Wirkung von Gesichtserkennungssystemen mit der erfolgreichen Anwendung von Faltungs-Neuronalen Netzen schnell und erheblich verbessert geboren und menschlich Gesichtserkennung wird in allen Aspekten des sozialen Lebens eingesetzt.
Tatsächlich ist die Verwendung neuronaler Netze zur Gesichtserkennung keine neue Idee. 1997 schlugen Forscher eine Methode namens neuronales Netz vor, die auf probabilistischer Entscheidungsfindung zur Gesichtserkennung, Augenpositionierung und Gesichtserkennung basiert. Dieses Gesichtserkennungs-PDBNN ist für jedes Trainingsfach in ein vollständig verbundenes Teilnetzwerk unterteilt, um die Anzahl versteckter Einheiten zu reduzieren und eine Überanpassung zu vermeiden. Die Forscher trainierten zwei PBDNNs separat mithilfe von Dichte- und Kantenmerkmalen und kombinierten dann ihre Ergebnisse, um die endgültige Klassifizierungsentscheidung zu treffen. Aufgrund des damaligen gravierenden Mangels an Rechenleistung und Daten war der Algorithmus jedoch relativ einfach, sodass der Algorithmus keine sehr guten Ergebnisse erzielte. Da die Backpropagation-Theorie und die Rechenleistungs-Frameworks erst in diesem Jahr ausgereift sind, hat sich die Wirksamkeit von Gesichtserkennungsalgorithmen erheblich verbessert.
Beim Deep Learning umfasst ein vollständiges Gesichtserkennungssystem auch die in Abbildung 1 gezeigten vier Schritte. Der erste Schritt wird als Gesichtserkennungsalgorithmus bezeichnet, bei dem es sich im Wesentlichen um einen Zielerkennungsalgorithmus handelt. Der zweite Schritt heißt Gesichtsausrichtung und basiert derzeit auf der geometrischen Ausrichtung von Schlüsselpunkten und der Gesichtsausrichtung auf Basis von Deep Learning. Der dritte Schritt ist die Merkmalsdarstellung. Durch die Idee des Klassifizierungsnetzwerks werden einige Merkmalsschichten im Klassifizierungsnetzwerk als Merkmalsdarstellung des Gesichts extrahiert und dann das Standard-Gesichtsbild auf die gleiche Weise verarbeitet. und schließlich durch Vergleich Die Abfragemethode vervollständigt das gesamte Gesichtserkennungssystem. Im Folgenden finden Sie einen kurzen Überblick über die Entwicklung von Gesichtserkennungs- und Gesichtserkennungsalgorithmen.
Deep Learning wurde nach seinem großen Erfolg bei der Bildklassifizierung schnell für das Problem der Gesichtserkennung eingesetzt. Zunächst basierten die Ideen zur Lösung dieses Problems hauptsächlich auf der Skaleninvarianz des CNN-Netzwerks Die Bilder wurden unterschiedlich skaliert und führen dann eine Inferenz durch, um die Kategorie- und Standortinformationen direkt vorherzusagen. Darüber hinaus ist die Genauigkeit des erhaltenen Gesichtsrahmens aufgrund der direkten Positionsregression jedes Punkts in der Merkmalskarte relativ gering. Daher haben einige Leute eine Grob-zu-Fein-Erkennungsstrategie vorgeschlagen, die auf einem mehrstufigen Klassifikator basiert Die Hauptmethoden zur Gesichtserkennung sind beispielsweise CNN, DenseBox und MTCNN.
MTCNN ist eine Multitasking-Methode. Zum ersten Mal werden Gesichtsbereichserkennung und Gesichtsschlüsselpunkterkennung kombiniert, aber die Gesamtidee ist cleverer sinnvoll. Im Allgemeinen ist es in drei Teile unterteilt: PNet, RNet und ONet. Die Netzwerkstruktur ist in der folgenden Abbildung dargestellt.
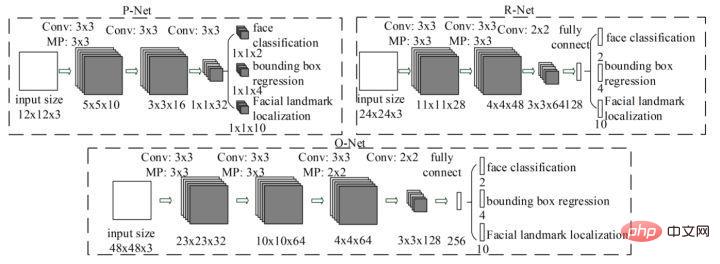
Zuerst passt das PNet-Netzwerk die Größe des Eingabebilds an. Als Eingabe durchläuft es direkt zwei Faltungsschichten und gibt den Gesichtsklassifizierungs- und Gesichtserkennungsrahmen zurück. Nachdem Sie das grob erkannte Gesicht aus dem Originalbild zugeschnitten haben, führen Sie die Gesichtserkennung erneut im Eingabe-R-Net durch. Schließlich wird das erhaltene Gesicht schließlich in O-Net eingegeben, und das erhaltene O-Net-Ausgabeergebnis ist das endgültige Ergebnis der Gesichtserkennung. Der Gesamtprozess von MTCNN ist relativ einfach und kann schnell bereitgestellt und implementiert werden. MTCNN weist jedoch auch viele Mängel auf. Das Einbeziehen eines mehrstufigen Aufgabentrainings ist zeitaufwändig und das Speichern einer großen Anzahl von Zwischenergebnissen erfordert viel Speicherplatz. Da das modifizierte Netzwerk außerdem direkt eine Bounding-Box-Regression an Merkmalspunkten durchführt, ist der Effekt auf die Erkennung kleiner Zielgesichter nicht sehr gut. Darüber hinaus muss das Netzwerk während des Inferenzprozesses die Gesichtsbilder auf unterschiedliche Größen anpassen, um den Anforderungen der Gesichtserkennung unterschiedlicher Größe gerecht zu werden, was die Geschwindigkeit der Inferenz erheblich beeinträchtigt.
Mit der Entwicklung des Bereichs der Zielerkennung beweisen immer mehr experimentelle Beweise, dass immer mehr Engpässe bei der Zielerkennung im Widerspruch zwischen Netzwerksemantik auf niedriger Ebene, aber relativ hoher Positionierungsgenauigkeit und Netzwerksemantik auf hoher Ebene, aber geringer Positionierung liegen Zielerkennungsnetzwerke sind auch bei ankerbasierten Strategien und schichtübergreifenden Fusionsstrategien beliebt geworden, wie beispielsweise den berühmten Serien Faster-rcnn, SSD und yolo. Daher verwenden Gesichtserkennungsalgorithmen zunehmend Anker und Mehrkanalausgabe, um den Erkennungseffekten von Gesichtern unterschiedlicher Größe gerecht zu werden. Der bekannteste Algorithmus ist die SSH-Netzwerkstruktur.
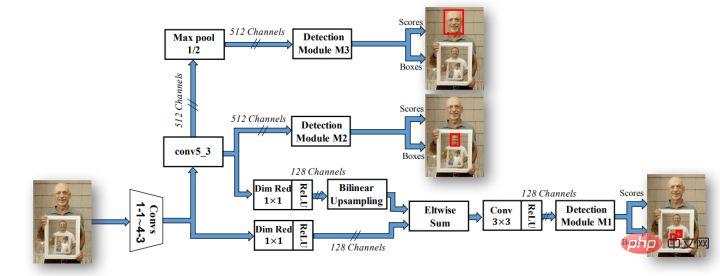
Wie Sie der obigen Abbildung entnehmen können, verfügt das SSH-Netzwerk bereits über Methoden zur Verarbeitung der Ausgabe verschiedener Netzwerkschichten. Es ist also nur eine Schlussfolgerung erforderlich, um den Erkennungsprozess von Gesichtern unterschiedlicher Größe abzuschließen genannt Single Stage. Das SSH-Netzwerk ist auch relativ einfach, es führt lediglich Verzweigungsberechnungen und Ausgaben auf verschiedenen Faltungsschichten von VGG durch. Darüber hinaus werden die High-Level-Features hochgetastet und Eltwise Sum mit den Low-Level-Features durchgeführt, um die Feature-Fusion der Low-Level- und High-Level-Features abzuschließen. Darüber hinaus hat das SSH-Netzwerk auch ein Erkennungsmodul und ein Kontextmodul entwickelt. Das Kontextmodul übernimmt als Teil des Erkennungsmoduls die Anfangsstruktur, um mehr Kontextinformationen und ein größeres Empfangsfeld zu erhalten.
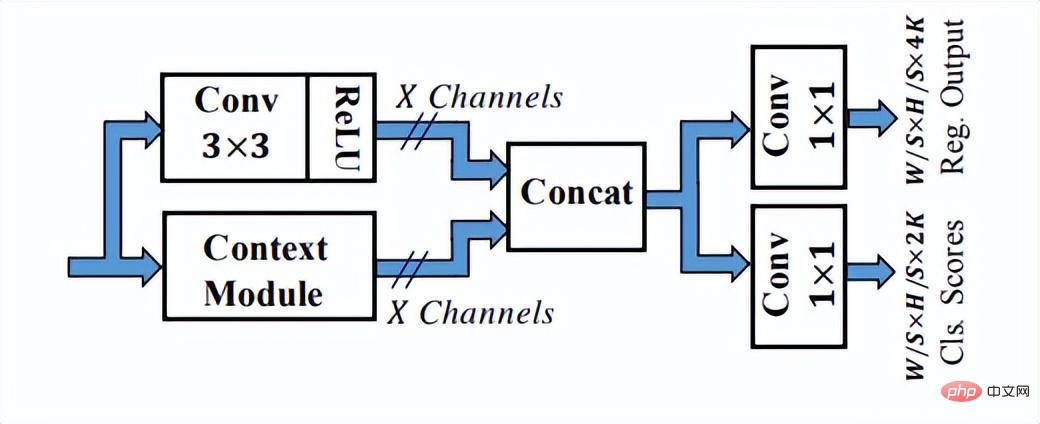
Das Erkennungsmodul in SSH
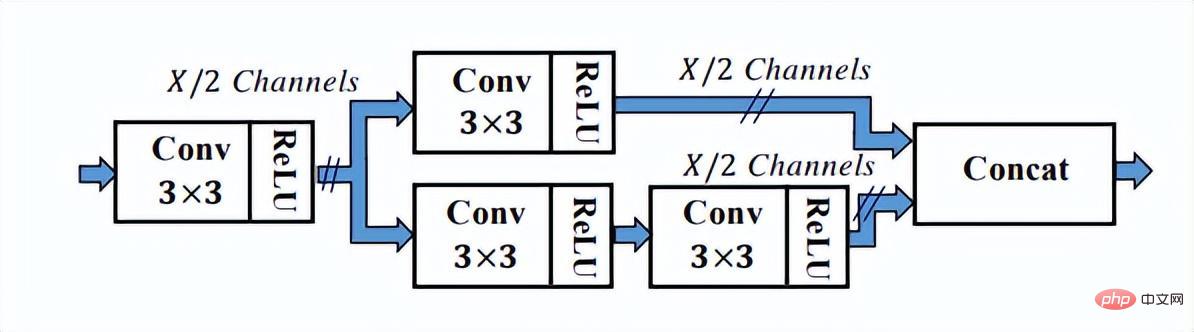
Das Kontextmodul im Erkennungsmodul in SSH
SSH verwendet 1 × 1-Faltung, um die endgültigen Regressions- und Klassifizierungszweigergebnisse auszugeben, und verwendet es nicht vollständig Die verbundene Schicht kann sicherstellen, dass durch die Eingabe von Bildern unterschiedlicher Größe ein Ausgabeergebnis erzielt werden kann, was auch dem damaligen Trend zu vollständig faltenden Entwurfsmethoden entspricht. Leider gibt das Netzwerk keine Orientierungspunkte aus. Tatsächlich verwendet die Kontextstruktur nicht die beliebtere Feature-Pyramidenstruktur. Mit der kontinuierlichen Weiterentwicklung der Gesichtsoptimierungstechnologie werden auch verschiedene Tricks verwendet reifer. Deshalb möchte ich Ihnen abschließend das Retinaface-Netzwerk vorstellen, das in aktuellen Gesichtserkennungsalgorithmen weit verbreitet ist.
Retinaface wurde von Google vorgeschlagen und basiert im Wesentlichen auf der Netzwerkstruktur von RetinaNet. Es nutzt die Feature-Pyramiden-Technologie, um die Fusion von Multiskaleninformationen zu erreichen, und spielt eine wichtige Rolle bei der Erkennung kleiner Objekte. Die Netzwerkstruktur ist unten dargestellt.
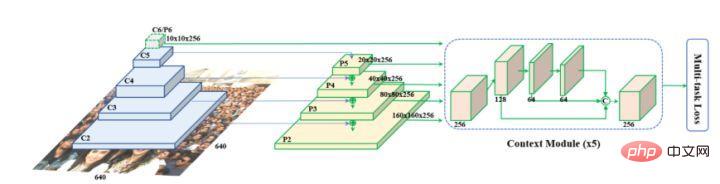
Wie Sie auf dem Bild oben sehen können, ist das Backbone-Netzwerk von Retinaface ein allgemeines Faltungs-Neuronales Netzwerk und fügt dann die Funktionspyramidenstruktur und das Kontextmodulmodul hinzu, um Kontextinformationen weiter zu integrieren und Klassifizierung, Erkennung und verschiedene Aufgaben abzuschließen wie z. B. Landmark-Point-Regression und Bildselbstverbesserung.
Da die Gesichtserkennung im Wesentlichen eine Zielerkennungsaufgabe ist, gilt die zukünftige Richtung der Zielerkennung auch für die Optimierungsrichtung von Gesichtern. Derzeit ist es immer noch schwierig, kleine Ziele und verdeckte Ziele bei der Zielerkennung zu erkennen. Darüber hinaus werden die meisten Erkennungsnetzwerke zunehmend auf der Endseite eingesetzt. Daher stellen die Komprimierung des Netzwerkmodells und die Rekonstruktionsbeschleunigung auf der Endseite eine größere Herausforderung dar Ingenieure. Verständnis und Anwendung von Deep-Learning-Erkennungsalgorithmen.
Der Kern des Gesichtserkennungsproblems ist ein Klassifizierungsproblem, das heißt, jede Person wird als Kategorie klassifiziert und erkannt, aber während der tatsächlichen Erkennung treten viele Probleme auf Anwendung. Erstens gibt es viele Gesichtskategorien, wenn Sie alle Personen in einer Stadt identifizieren möchten. Darüber hinaus sind für jede Person nur sehr wenige beschriftete Stichproben verfügbar, und es sind viele Long-Tail-Daten vorhanden . Aufgrund der oben genannten Probleme muss das traditionelle CNN-Klassifizierungsnetzwerk geändert werden.
Wir wissen, dass das tiefe Faltungsnetzwerk zwar ein Black-Box-Modell ist, aber die Eigenschaften von Bildern oder Objekten durch Datentraining charakterisieren kann. Daher kann der Gesichtserkennungsalgorithmus eine große Anzahl von Gesichtsmerkmalsvektoren über das Faltungsnetzwerk extrahieren und dann den Gesichtserkennungsprozess basierend auf der Ähnlichkeitsbeurteilung und dem Vergleich mit der Basisbibliothek abschließen. Daher kann das Algorithmusnetzwerk unterschiedliche Merkmale für verschiedene Gesichter generieren Der Schwerpunkt dieser Einbettungsaufgabe liegt auf der Generierung ähnlicher Merkmale für dasselbe Gesicht, d. h. auf der Frage, wie der Abstand zwischen den Klassen maximiert und der Abstand zwischen den Klassen minimiert werden kann.
Bei der Gesichtserkennung kann das Backbone-Netzwerk verschiedene Faltungs-Neuronale Netze verwenden, um die Merkmalsextraktion abzuschließen, z. B. Resnet, Inception und andere klassische Faltungs-Neuronale Netze. Als Rückgrat der Schlüssel liegt im Entwurf und der Implementierung der letzten Schicht der Verlustfunktion. Lassen Sie uns nun verschiedene Verlustfunktionen in Gesichtserkennungsalgorithmen analysieren, die auf Deep Learning aus zwei Ideen basieren.
Idee 1: metrisches Lernen, einschließlich Kontrastverlust, Triplettverlust und Stichprobenmethode
Idee 2: Margenbasierte Klassifizierung, einschließlich Softmax mit Zentrumsverlust, Sphereface, Normface, AM-Sofrmax(Cosface) und Arcface. Metric Larning) Kontrastverlust
Eine der ersten Anwendungen metrischer Lernideen im Deep Learning ist DeepID2. Die wichtigste Verbesserung von DeepID2 besteht darin, dass dasselbe Netzwerk gleichzeitig die Verifizierung und Klassifizierung trainiert (mit zwei Überwachungssignalen). Darunter wird der Kontrastverlust in der Merkmalsschicht des Verifizierungsverlusts eingeführt.
Kontrastverlust berücksichtigt nicht nur die Abstandsminimierung derselben Kategorie, sondern auch die Abstandsmaximierung verschiedener Kategorien und verbessert das Gesicht durch vollständige Nutzung des Etiketts Informationen zur Erkennungsgenauigkeit der Trainingsbeispiele. Daher sorgt die Verlustfunktion im Wesentlichen dafür, dass Fotos derselben Person im Feature-Raum nah genug beieinander liegen und verschiedene Personen im Feature-Raum weit genug voneinander entfernt sind, bis sie einen bestimmten Schwellenwert überschreiten. (Es klingt ein bisschen nach Triplett-Verlust).
Kontrastiver Verlust führt zwei Signale ein und trainiert das Netzwerk durch die beiden Signale. Der Ausdruck zur Identifizierung des Signals lautet wie folgt:
Basierend auf diesem Signal wird DeepID2 nicht in einem Bild trainiert, sondern in zwei Bildern gleichzeitig . Wenn sie von derselben Person sind, ist es 1. Wenn sie nicht von derselben Person sind, ist es -1. Das einjährige FaceNet von Google ist auch ein Wendepunkt im Bereich der Gesichtserkennung. Es wird ein einheitlicher Lösungsrahmen für die meisten Gesichtsprobleme vorgeschlagen, d. h. Probleme wie Erkennung, Überprüfung und Suche können alle im Merkmalsraum durchgeführt werden. Der Schwerpunkt muss darauf liegen, wie das Gesicht besser dem Merkmalsraum zugeordnet werden kann. .
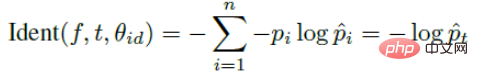 Basierend auf DeepID2 hat Google die Klassifizierungsebene, also den Klassifizierungsverlust, aufgegeben und den Kontrastverlust zum Triplettverlust verbessert, und zwar nur zu einem Zweck: um bessere Funktionen zu lernen.
Basierend auf DeepID2 hat Google die Klassifizierungsebene, also den Klassifizierungsverlust, aufgegeben und den Kontrastverlust zum Triplettverlust verbessert, und zwar nur zu einem Zweck: um bessere Funktionen zu lernen.
Posten Sie direkt die Verlustfunktion des Triplettverlusts. Die Eingabe erfolgt nicht mehr über ein Bildpaar, sondern über drei Bilder (Triplett), nämlich Ankergesicht und Negativgesicht Gesicht. Anker und positives Gesicht sind dieselbe Person und negatives Gesicht sind verschiedene Personen. Dann kann die Verlustfunktion des Triplettverlusts ausgedrückt werden als:
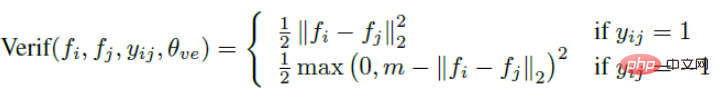
Die intuitive Erklärung dieser Formel lautet: Im Merkmalsraum ist der Abstand zwischen Anker und Positiv kleiner als der Abstand zwischen Anker und Negativ und überschreitet ein Margin Alpha. Der intuitive Unterschied zwischen ihm und dem Kontrastverlust ist in der folgenden Abbildung dargestellt. (3) Probleme beim metrischen Lernen weist noch einige Mängel auf.
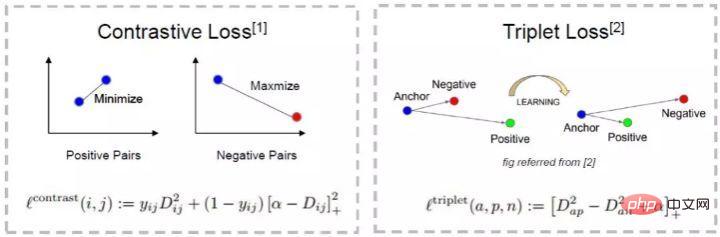
Der Beispielmodus wirkt sich auf das Modelltraining aus. Beispielsweise müssen für den Triplettverlust die Ankerfläche, die negative Fläche und die positive Fläche während des Trainingsprozesses zufällig abgetastet werden. Eine gute Stichprobenentnahme kann die Trainingsgeschwindigkeit und die Modellkonvergenz beschleunigen, es ist jedoch schwierig, während der Zufallsstichprobe sehr gute Ergebnisse zu erzielen Verfahren.
Mangel an Mining-Hard-Triplets, was auch bei den meisten Modelltrainings ein Problem darstellt. Im Bereich der Gesichtserkennung stellen beispielsweise harte Negative ähnliche, aber unterschiedliche Personen dar, während harte Positive dieselbe Person, aber völlig unterschiedliche Haltungen, Ausdrücke usw. darstellen. Lernen und spezielle Verarbeitung harter Beispiele sind entscheidend für die Verbesserung der Genauigkeit des Erkennungsmodells. 2. Verschiedene Tricks, um die Mängel des metrischen Lernens zu beheben. (1) Feinabstimmung in der Zeitung „Deep Face „Erkennung“, um das Training des Triplet-Verlusts zu beschleunigen, habe ich zuerst Softmax zum Trainieren des Gesichtserkennungsmodells verwendet, dann die Klassifizierungsebene der obersten Ebene entfernt und dann den Triplet-Verlust verwendet, um eine Feinabstimmung der Feature-Ebene am Modell durchzuführen Durch das Beschleunigungstraining habe ich auch viel erreicht. Diese Methode ist auch die am häufigsten verwendete Methode beim Training des Triplettverlusts.
Während des von Google bereitgestellten Facenet-Triplett-Verlusttrainings werden die Daten nach Auswahl des B-Triplett-Sets in 3er-Gruppen der Reihe nach angeordnet, sodass insgesamt 3B-Kombinationen vorhanden sind, diese 3B-Bilder jedoch tatsächlich vorhanden sind Es gibt so viele effektive Kombinationen von Drillingen, dass die Verwendung von nur 3B verschwenderisch wäre.
In diesem Artikel schlug der Autor einen TriHard-Verlust vor. Die Kernidee besteht darin, eine harte Beispielverarbeitung auf der Grundlage des Triplettverlusts hinzuzufügen: Für jeden Trainingsstapel werden P-Fußgänger mit IDs zufällig ausgewählt, und jeder A-Fußgänger wählt zufällig aus K verschiedene Bilder, das heißt, ein Stapel enthält P×K Bilder. Dann können wir für jedes Bild a im Stapel die schwierigste positive Probe und die schwierigste negative Probe auswählen, um ein Triplett mit a zu bilden. Zuerst definieren wir den Bildsatz mit derselben ID wie a als A und den verbleibenden Bildsatz mit unterschiedlichen IDs als B. Dann wird der TriHard-Verlust ausgedrückt als:
, wobei der künstlich festgelegte Schwellenwertparameter ist . Der TriHard-Verlust berechnet den euklidischen Abstand zwischen a und jedem Bild im Stapel im Merkmalsraum und wählt dann die positive Stichprobe p aus, die am weitesten (am wenigsten unähnlich) von a ist, und die negative Stichprobe n, die a am nächsten (am ähnlichsten) ist . Berechnen Sie den Triplettverlust. wobei d den euklidischen Abstand darstellt. Eine andere Möglichkeit, die Verlustfunktion zu schreiben, ist wie folgt:
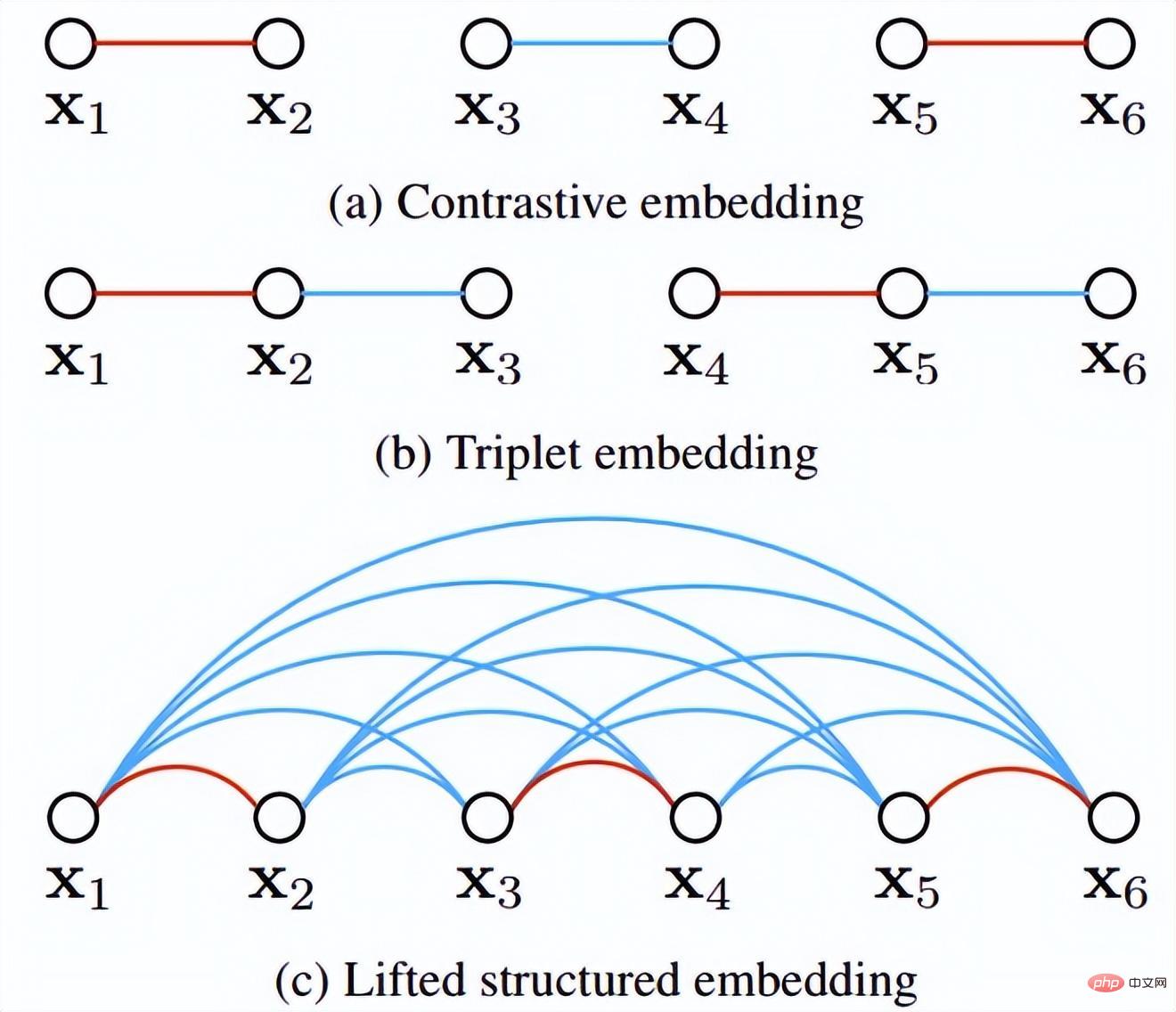
Darüber hinaus hat der Autor während der Runde auch mehrere experimentelle Punkte vorgebracht: Diese Methode berücksichtigt das Effektverhältnis nach traditionellem harten Beispiel Der Triplettverlust ist gut. (3) Änderungen an Verlust- und Probenmethoden 🎜🎜#Referenzpapier: Deep Metric Learning via Lifted Structured Feature Embedding In diesem Papier wurde zunächst vorgeschlagen, dass die vorhandene Triplet-Methode nicht vollständig ausgenutzt werden kann In den Trainingsstapeln des Minibatch-SGD-Trainings haben wir den Vektor der paarweisen Distanz kreativ in die Matrix der paarweisen Distanz umgewandelt und dann eine neue strukturierte Verlustfunktion entworfen, die sehr gute Ergebnisse erzielte. Wie in der folgenden Abbildung dargestellt, handelt es sich um ein Stichprobendiagramm der drei Methoden der Kontrasteinbettung, der Triplett-Einbettung und der angehobenen strukturierten Einbettung. Intuitiv umfasst die aufgehobene strukturierte Einbettung mehr Klassifizierungsmodi, um Training zu vermeiden, das durch eine große Datenmenge verursacht wird , der Autor Schwierigkeit, der Autor gibt eine darauf basierende strukturierte Verlustfunktion an. Wie unten gezeigt. wobei P der positive Probensatz und N der negative Probensatz ist. Es ist ersichtlich, dass diese Verlustfunktion im Vergleich zur obigen Verlustfunktion beginnt, das Problem eines Stichprobensatzes zu berücksichtigen. Allerdings enthalten nicht alle negativen Kanten zwischen Stichprobenpaaren nützliche Informationen. Daher müssen wir eine nicht zufällige Stichprobenmethode entwerfen. Durch die obige strukturierte Verlustfunktion können wir sehen, dass in der endgültigen Berechnung der Verlustfunktion die ähnlichsten und am wenigsten ähnlichen harten Paare (d. h. der Verlust) ermittelt werden Funktion), was dem Hinzufügen schwieriger Nachbarninformationen zum Trainings-Minibatch während des Trainingsprozesses entspricht. Auf diese Weise können die Trainingsdaten mit hoher Wahrscheinlichkeit nach Proben von harten Negativen und harten Positiven suchen Im weiteren Verlauf des Trainings wird durch das Training harter Proben auch der Zweck erreicht, den Abstand zwischen den Klassen zu maximieren und den Abstand innerhalb der Klassen zu minimieren. Wie in der Abbildung oben gezeigt, wählt dieser Artikel beim Durchführen von metrischem Lernen nicht zufällig Stichprobenpaare aus, sondern wird trainiert, indem die schwer zu unterscheidenden Probentypen kombiniert werden. Darüber hinaus wurde in dem Artikel auch erwähnt, dass der Prozess der Suche nach Max oder nach dem härtesten Negativ dazu führt, dass das Netzwerk zu einem schlechten lokalen Optimum konvergiert. Ich vermute, dass dies am Kürzungseffekt von Max liegt, der den Gradienten steiler macht weist zu viele Gradientendiskontinuitäten auf. Der Autor hat die Verlustfunktion weiter verbessert und die glatte Obergrenze übernommen, die in der folgenden Formel dargestellt ist. (4) Weitere Modifikationen der Stichprobenmethode und Triplettverlust Referenzpapier: Sampling Matters in Deep Embedding Learning Der Artikel weist darauf hin, dass die harte negative Probe einen kleinen Ankerabstand aufweist und diese Abtastmethode leicht durch das Rauschen beeinträchtigt wird führt zum Zusammenbruch des Modells während des Trainings. FaceNet schlug einmal eine halbharte negative Mining-Methode vor. Die vorgeschlagene Methode bestand darin, die abgetasteten Proben nicht zu hart zu machen. Der Analyse des Autors zufolge sollte die Probe jedoch gleichmäßig in der Probe entnommen werden, sodass der beste Probenahmezustand in gleichmäßig verteilten negativen Proben liegen sollte, einschließlich harter, halbharter und einfacher Proben. Daher schlägt der Autor eine neue Probenahmemethode vor Distanzgewichtete Probenahme. In Wirklichkeit tastet unser Team alle Proben paarweise ab und berechnet deren Abstände. Schließlich hat die Verteilung der Punkt-zu-Punkt-Abstände die folgende Beziehung: Anschließend kann die Abtastwahrscheinlichkeit entsprechend der gegebenen Entfernung durch die Umkehrfunktion der obigen Funktion ermittelt und der für jede Entfernung erforderliche Anteil der Abtastung bestimmt werden basierend auf dieser Wahrscheinlichkeit. Bei einem gegebenen Anker lautet die Wahrscheinlichkeit, ein negatives Beispiel abzutasten, wie folgt: Da die Trainingsstichprobe stark ist bezogen auf den Trainingsgradienten, daher hat der Autor auch die Beziehung zwischen Stichprobenentfernung, Stichprobenmethode und Datengradientenvarianz aufgezeichnet, wie in der folgenden Abbildung dargestellt. Wie aus der Abbildung ersichtlich ist, befinden sich die mit der Hard-Negative-Mining-Methode erfassten Stichproben alle in Bereichen mit hoher Varianz. Wenn der Datensatz Rauschen enthält, wird die Stichprobe leicht durch das Rauschen beeinflusst, was zum Zusammenbruch des Modells führt. Zufällig ausgewählte Stichproben konzentrieren sich tendenziell auf Bereiche mit geringer Varianz, wodurch der Verlust sehr gering ist. Zu diesem Zeitpunkt ist das Modell jedoch nicht wirklich gut trainiert. Der Stichprobenbereich des halbharten negativen Minings ist sehr klein, was wahrscheinlich dazu führt, dass das Modell sehr früh konvergiert und der Verlust sehr langsam abnimmt. Tatsächlich wurde das Modell jedoch zu diesem Zeitpunkt noch nicht gut trainiert und die vorgeschlagene Methode verwendet in diesem Artikel kann in Sample gleichmäßig über den gesamten Datensatz erreicht werden.
3. Margenbasierte Klassifizierung -Formel wird die Gesichtserkennung indirekt realisiert Durch die Einschränkung wird das vom Netzwerk erhaltene endgültige Merkmal diskriminierender. (1) Zentrumsverlust Referenz Papier: Ein Ansatz zum Lernen diskriminierender Merkmale für die tiefe Gesichtserkennung Dieser Artikel von ECCV 2016 schlägt hauptsächlich einen neuen Verlust vor: Center Loss, um Softmax Loss beim Gesichtstraining zu unterstützen, um dieselbe Kategorie zusammenzufassen und letztendlich diskriminierendere Merkmale zu erhalten. Zentrumsverlust bedeutet: Bereitstellung eines Kategoriezentrums für jede Kategorie und Minimierung des Abstands zwischen jeder Stichprobe im Min-Batch und dem entsprechenden Kategoriezentrum, um den Zweck der Verringerung des Abstands innerhalb der Klasse zu erreichen. Die folgende Abbildung zeigt die Verlustfunktion, die den Abstand zwischen der Stichprobe und dem Klassenzentrum minimiert. ist das Kategoriezentrum, das jeder Probe in jeder Charge entspricht, und wird wie die Dimension des Merkmals durch den euklidischen Abstand als hochdimensionalen Mannigfaltigkeitsabstand ausgedrückt. Basierend auf Softmax lautet die Verlustfunktion des Zentrumsverlusts daher wie folgt: Die Clustering-Funktion wird der Verlustfunktion hinzugefügt. Mit fortschreitendem Training werden die Stichproben bewusst in der Mitte jedes Stapels geclustert, wodurch die Unterschiede zwischen den Klassen weiter maximiert werden. Ich denke jedoch, dass bei hochdimensionalen Merkmalen der euklidische Abstand nicht den Abstand der Clusterbildung widerspiegelt, sodass eine solche einfache Clusterbildung in hohen Dimensionen keine besseren Ergebnisse erzielen kann.
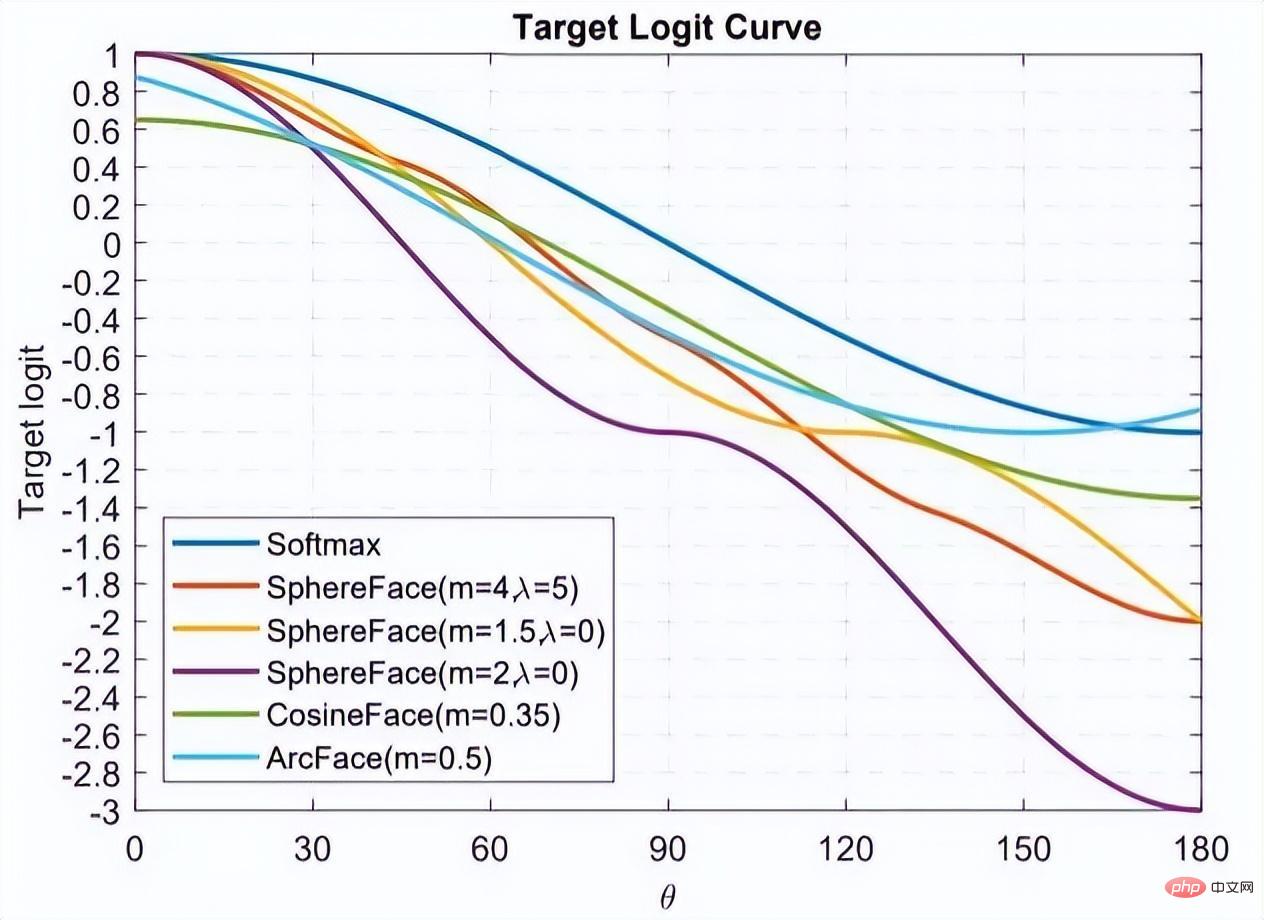
Original Softmax Der Zweck besteht darin, die Methode der Vektormultiplikation in die Beziehung zwischen dem Modul und dem Winkel des Vektors umzuwandeln. Das heißt, L-Softmax hofft, eine positive ganzzahlige Variable m hinzuzufügen, die wie folgt aussieht: #🎜 🎜# ermöglicht es der generierten Entscheidungsgrenze, die oben genannten Ungleichungen strenger einzuschränken, wodurch der Abstand innerhalb der Klasse kompakter und der Abstand zwischen Klassen enger wird. Basierend auf der obigen Formel und der Formel von Softmax kann die Formel von L-Softmax daher wie folgt erhalten werden: Da cos eine abnehmende Funktion ist, wird das innere Produkt durch Multiplikation mit m kleiner. Mit zunehmendem Training wird sich schließlich der Abstand zwischen den Klassen selbst vergrößern. Durch Steuern der Größe von m können Sie die Änderungen in den Abständen zwischen Klassen und Klassen sehen. Das zweidimensionale Diagramm wird wie folgt angezeigt: 🎜#Um sicherzustellen, dass die Winkel zwischen Kategorievektoren den Randprozess erfüllen können Während des Backpropagation- und Inferenzprozesses und um eine monoton abnehmende Funktion sicherzustellen, hat der Autor eine neue Funktionsform erstellt: Es wurde berichtet, dass es schwierig ist, die Parameter von L-Softmax anzupassen, und dass die Parameter von m wiederholt angepasst werden müssen, um bessere Ergebnisse zu erzielen. Nomface:NormFace: L2 Hypersphere Embedding for Face Verification Dieser Artikel ist ein sehr interessanter Artikel, in dem es um die Normalisierung von Gewichten und Merkmalen geht. Viele interessante Diskussionen. Der Artikel weist darauf hin, dass die Kugeloberfläche zwar gut, aber nicht schön ist. In der Testphase misst Sphereface die Ähnlichkeit anhand des Kosinuswerts zwischen Merkmalen, d. h. der Winkel wird als Ähnlichkeitsmaß verwendet. Es gibt jedoch auch ein Problem während des Trainingsprozesses. Wenn die Verlustfunktion während des Trainingsprozesses abnimmt, wird das Gewicht immer größer, sodass die Optimierung erfolgt Die Richtung der Kugelflächenverlustfunktion ist nicht sehr streng. Tatsächlich besteht ein Teil der Optimierungsrichtung darin, die Länge des Merkmals zu erhöhen. Einige Blogger führten Experimente durch und stellten fest, dass mit zunehmendem m auch der Maßstab der Koordinaten weiter zunimmt, wie in der folgenden Abbildung dargestellt.
Daher hat der Autor die Funktionen während des Optimierungsprozesses normalisiert. Die entsprechende Verlustfunktion lautet auch wie folgt:
W und f sind beide normalisierte Merkmale und die beiden Skalarprodukte sind die Winkelkosinuswerte. Der Parameter s wird aufgrund seiner mathematischen Eigenschaften eingeführt, die die Rationalität der Gradientengröße gewährleisten. Es gibt eine relativ intuitive Erklärung im Originalpapier, das nicht im Mittelpunkt steht. s können in einen lernbaren Parameter oder einen Superparameter umgewandelt werden. Der Autor des Artikels hat viele empfohlene Werte angegeben, die im Artikel zu finden sind. Tatsächlich sind der normalisierte euklidische Abstand und der Kosinusabstand in FaceNet vereinheitlicht. 4. AM-Softmax/CosFace Referenzpapier: Additive Margin Softmax zur Gesichtsverifizierung Schau oben In der Arbeit werden Sie feststellen, dass etwas fehlt, nämlich die Marge, oder dass die Bedeutung von Marge geringer ist. Daher führt AM-Softmax die Marge auf der Grundlage der Normalisierung ein. Die Verlustfunktion lautet wie folgt: Intuitiv ist das -m-Verhältnis kleiner, sodass der Verlustfunktionswert größer als der in Normface ist, sodass ein Gefühl der Marge entsteht. m ist ein Hyperparameter, der die Strafe steuert. Je größer m ist, desto stärker ist die Strafe. Das Gute an dieser Methode ist, dass sie einfach zu reproduzieren ist, es nicht viele Tricks zur Parameteranpassung gibt und der Effekt sehr gut ist. (1) ArcFace Im Vergleich zu AM-Softmax liegt der Unterschied in der Art und Weise, wie Arcface die Marge einführt. Auf den ersten Blick ist es so nicht dasselbe wie AM. -Gleich wie Softmax? Beachten Sie, dass m innerhalb des Kosinus liegt. Der Artikel weist darauf hin, dass die Grenze zwischen den Merkmalen, die auf der Grundlage der Optimierung der obigen Formel erhalten wurden, besser ist und eine stärkere geometrische Interpretation aufweist. Gibt es jedoch Probleme bei der Einführung einer solchen Marge? Überlegen Sie genau, ob cos(θ+m) kleiner als cos(θ) sein muss? Dieses Bild stammt von Arcface. Die Abszisse ist der Winkel zwischen dem Merkmal und dem Klassenzentrum. Die Ordinate ist der Wert des exponentiellen Teils des Moleküls der Verlustfunktion (unabhängig von s ). Je kleiner der Wert, desto größer die Verlustfunktion. Nachdem ich so viele klassifizierungsbasierte Gesichtserkennungspapiere gelesen habe, glaube ich, dass Sie auch das Gefühl haben, dass sich offenbar alle um die Verlustfunktion kümmern, oder genauer gesagt, alle darüber diskutieren, wie das Target-Logit gestaltet werden soll im Bild oben: θ-Kurve. Diese Kurve gibt an, wie Sie Proben optimieren möchten, die vom Ziel abweichen, oder mit anderen Worten, wie viel Strafe Sie basierend auf dem Grad der Abweichung vom Ziel verhängen sollten. Zwei Punkte zur Zusammenfassung: 1. Zu starke Einschränkungen lassen sich nicht einfach verallgemeinern. Beispielsweise kann die Verlustfunktion von Sphereface die Anforderung erfüllen, dass der maximale Abstand innerhalb einer Klasse kleiner ist als der minimale Abstand zwischen Klassen, wenn m = 3 oder 4. Zu diesem Zeitpunkt ist der Verlustfunktionswert sehr groß, dh die Ziellogits sind sehr klein. Dies bedeutet jedoch nicht, dass es auf Proben außerhalb des Trainingssatzes verallgemeinert werden kann. Das Auferlegen zu starker Einschränkungen verringert die Modellleistung und erschwert die Konvergenz des Trainings. 2. Es ist wichtig auszuwählen, welche Art von Probe optimiert werden soll. Der Arcface-Artikel weist darauf hin, dass eine zu starke Bestrafung von Stichproben von θ∈[60°, 90°] dazu führen kann, dass das Training nicht konvergiert. Die Optimierung von Proben für θ ∈ [30°, 60°] kann die Modellgenauigkeit verbessern, während eine übermäßige Optimierung von Proben für θ∈[0°, 30°] keine wesentlichen Verbesserungen bringt. Proben mit größeren Winkeln weichen zu weit vom Ziel ab, und eine erzwungene Optimierung verringert wahrscheinlich die Modellleistung. Damit werden auch die im vorherigen Abschnitt verbleibenden Fragen beantwortet. Die Kurve Arcface im obigen Bild erhebt sich dahinter, was irrelevant und sogar vorteilhaft ist. Weil die Optimierung harter Proben mit großen Winkeln möglicherweise keinen Nutzen bringt. Dies ist dasselbe wie die halbharte Strategie für die Beispielauswahl in FaceNet. Margenbasierte Klassifizierung Erweitertes Lesen vorgeschlagener Zentrumsverlust, der gewichtet und in den ursprünglichen Softmax-Verlust integriert wird. Durch die Aufrechterhaltung eines euklidischen Raumklassenzentrums wird der Abstand innerhalb der Klasse verringert und die Unterscheidungskraft von Merkmalen erhöht. 2. Softmax-Verlust mit großer Marge für Faltungs-Neuronale Netze [10] Der vorherige Artikel des Sphereface-Autors, nicht normalisierte Gewichte, führte die Marge beim Softmax-Verlust ein. Dazu gehören auch die Trainingsdetails von Sphereface. Erklärung der Implementierung des Gesichtserkennungsalgorithmus Das in diesem Artikel verwendete Modell des Gesichtserkennungsalgorithmus besteht hauptsächlich aus zwei Teilen: Wie in der folgenden Abbildung dargestellt, ist der gesamte Algorithmusimplementierungsprozess in zwei Teile unterteilt: Offline und Online. Vor jeder Identifizierung verschiedener Personen wird zunächst der trainierte Algorithmus verwendet, um eine Standard-Basisbibliothek von Gesichtern zu generieren Basisdatenbankdaten werden auf modelarts gespeichert. Während jedes Inferenzprozesses durchläuft die Bildeingabe dann das Gesichtserkennungsmodell und das Gesichtserkennungsmodell, um die Gesichtsmerkmale zu erhalten. Anschließend wird basierend auf diesen Merkmalen das Merkmalspaar mit der höchsten Ähnlichkeit in der Basisbibliothek durchsucht, um es zu vervollständigen Der Gesichtserkennungsprozess. Im Implementierungsprozess haben wir einen auf Retinaface+resnet50+arcface basierenden Algorithmus verwendet, um die Merkmalsextraktion von Gesichtsbildern abzuschließen, wobei Retinaface als Erkennungsmodell und resnet50+arcface als Merkmal verwendet wird Extraktionsmodell. Im Bild gibt es zwei Skripte für das Lauftraining, die dem Gesichtserkennungstraining bzw. dem Gesichtserkennungstraining entsprechen. Der Startbefehl dieses Skripts lautet wobei model_output_path der Pfad der Modellausgabe und data_path der Eingabepfad der Gesichtserkennung ist Trainingssatz und die Eingabe. Die Bildpfadstruktur ist wie folgt: Der Startbefehl dieses Skripts lautet wobei model_output_path der ist Pfad der Modellausgabe, und data_path ist der Gesichtserkennungs-Trainingssatz. Der Eingabepfad und die Struktur des Eingabebildpfads sind wie folgt: Der Startbefehl des Skripts ist: wobei data_path der Eingabepfad der unteren Bibliothek ist, discover_model_path Es ist der Eingabepfad des Erkennungsmodells,cognize_model_path ist der Eingabepfad des Erkennungsmodells und db_output_path ist der Ausgabepfad der Basisbibliothek . Der Startbefehl dieses Skripts lautet: wobei data_path der Eingabepfad für das Testbild ist, db_path der untere Bibliothekspfad und discover_model_path der Eingabepfad des Erkennungsmodells, „recognize_model_path“ ist der Eingabepfad des Erkennungsmodells . Diese Funktion ist für Entwickler, die sich mit der iterativen Entwicklung mehrerer Versionen befassen, von großer Hilfe. Es gibt einige voreingestellte Bilder und Algorithmen im Trainingsjob. Derzeit gibt es voreingestellte Bilder für häufig verwendete Frameworks (einschließlich Caffe, MXNet, Pytorch, TensorFlow) und das Engine-Image von Huaweis eigenem Ascend-Chip (Ascend-Powered-Engine). Wir möchten ModelArts in der Huawei Cloud nutzen, um ein Gesichtserkennungsmodell zu erstellen, das auf den Daten gängiger Prominenter auf der Website basiert. Da es sich bei dem Gesichtserkennungsnetzwerk um eine von Ingenieuren selbst entworfene Netzwerkstruktur handelt, muss es in diesem Prozess über ein benutzerdefiniertes Bild hochgeladen werden. Daher ist der gesamte Gesichtstrainingsprozess in die folgenden neun Schritte unterteilt: https://docs.docker.com/engine/install/binaries/#install-static-binaries Laden Sie das Basis-Image von Huawei Cloud herunter Offizielle Website-Anleitungs-URL: https://support.huaweicloud.com/engineers-modelarts/modelarts_23_0085.html#modelarts_23_0085__section19397101102 Wir müssen die MXNet-Umgebung für das Training verwenden die entsprechende Umgebung aus der Huawei Cloud. Das Basis-Image des benutzerdefinierten Images. Der auf der offiziellen Website angegebene Download-Befehl lautet wie folgt:
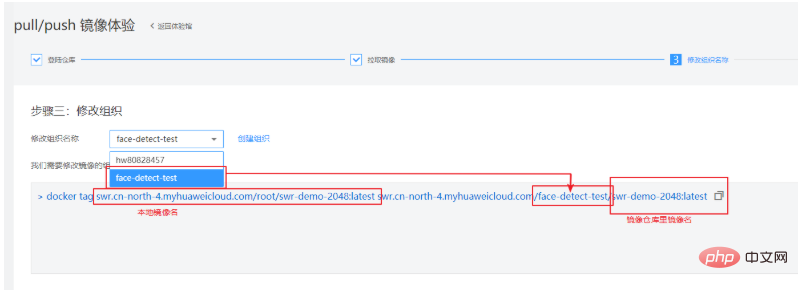
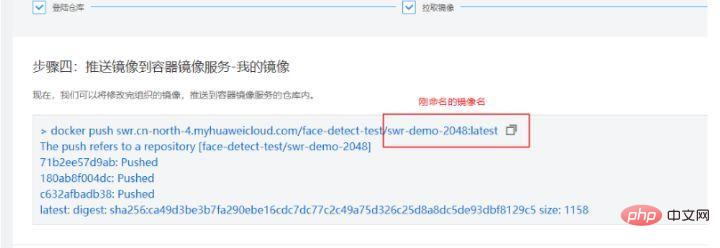
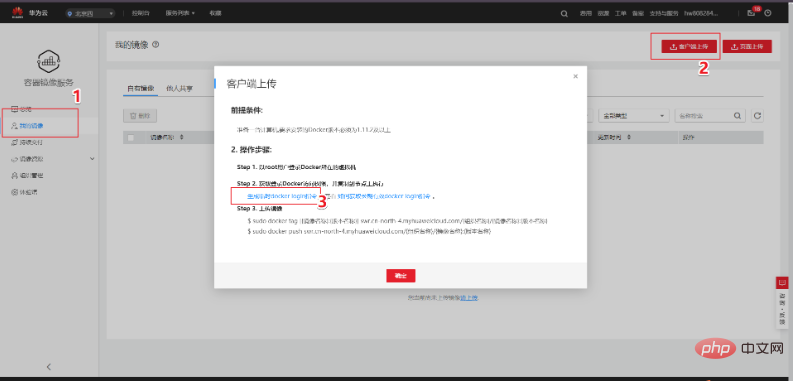
Die Erläuterung dieses Befehls finden Sie in den Spezifikationen des Grundbilds des Trainingsjobs. https://support.huaweicloud.com/engineers-modelarts/modelarts_23_0217.html Gemäß unseren Skriptanforderungen verwende ich das cuda9-Bild:
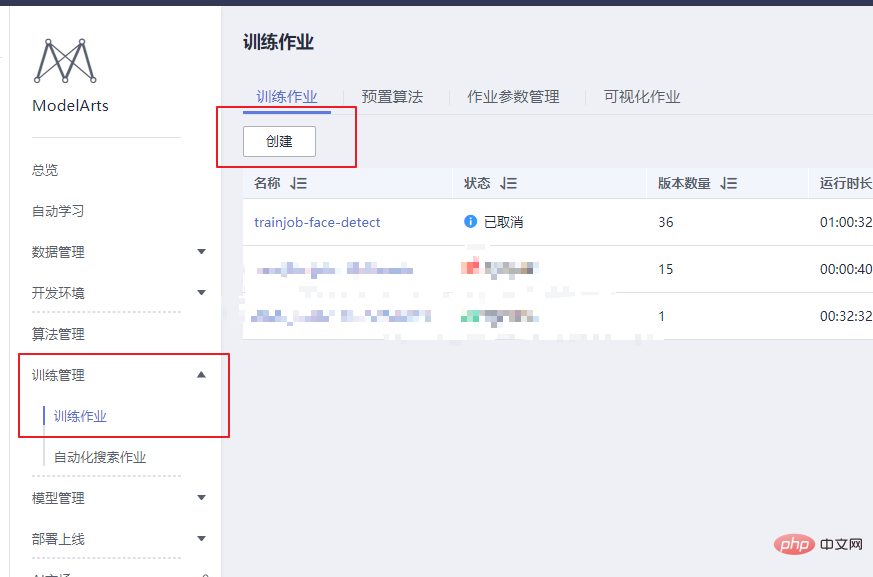
Der Beamte gibt auch ein anderes Die Methode besteht darin, eine Docker-Datei zu verwenden. Die Docker-Datei des Basis-Images finden Sie auch in der Spezifikation des Trainingsjob-Basis-Images. Sie können sich auf die Docker-Datei beziehen: https://github.com/huaweicloud/ModelArts-Lab/tree/master/docs/custom_image/custom_base Erstellen Sie eine benutzerdefinierte Spiegelumgebung entsprechend Ihren eigenen Anforderungen Da ich relativ faul bin, verwende ich Dockerfile immer noch nicht, um das Image selbst zu erstellen. Ich gehe einen anderen Weg! Da wir Cuda 9 und einige verwandte Python-Abhängigkeitspakete benötigen, können wir diesem Tutorial folgen und eine Anforderung.txt in das Trainingsskript einfügen. Einfache, effiziente und schnelle Lösung für Ihre Bedürfnisse! ! ! Hier ist das Tutorial~~~ https://support.huaweicloud.com/modelarts_faq/modelarts_05_0063.html Benutzerdefiniertes Bild auf SWR hochladen Offizielles Website-Tutorial: https: / /support.huaweicloud.com/engineers-modelarts/modelarts_23_0085.html#modelarts_23_0085__section19397101102 https://support.huaweicloud.com/usermanual-swr/swr_01_0011.html Wenn Sie Schwierigkeiten haben, die Produktdokumentation zu verstehen, können Sie das Pull/Push-Bilderlebnis auf der SWR-Seite ausprobieren: Hier zeigen wir Kunden, wie sie lokal hinzufügen können. Der erste Schritt, um das Bild in die Cloud zu übertragen, besteht darin, sich beim Lager anzumelden: Der zweite Schritt besteht darin, das Bild abzurufen. Wir werden es durch das von uns erstellte benutzerdefinierte Bild ersetzen. Der dritte Schritt besteht darin, die Organisation zu ändern und den auf der Grundlage der Produktdokumentation erstellten Organisationsnamen zu verwenden. In diesem Schritt müssen Sie ein lokales Bild in den in der Cloud erkannten Bildnamen umbenennen. Einzelheiten finden Sie in der Erklärung unten: Der vierte Schritt besteht darin, das Bild zu übertragen. Wenn Sie diese vier Schritte beherrschen, können Sie dieses Tutorial verlassen und den Client zum Hochladen verwenden . Melden Sie sich mit dem Client an und laden Sie hoch. Die Client-Anmeldung kann zum Generieren den temporären Docker-Anmeldebefehl verwenden. Diese Seite befindet sich unter „Mein Bild“ -> „Client-Upload“ -> „Temporären Docker-Anmeldebefehl generieren“: Verwenden Sie in der lokalen Docker-Umgebung diesen generierten temporären Docker-Anmeldebefehl, um sich anzumelden. Verwenden Sie den Befolgen Sie den folgenden Befehl, um das Bild hochzuladen: Huawei Cloud ModelArts bietet Trainingsjobs für Benutzer zum Trainieren von Modellen. Es gibt voreingestellte Bilder und benutzerdefinierte Bilder, die im Trainingsjob ausgewählt werden können. Die voreingestellten Bilder umfassen die meisten auf dem Markt erhältlichen Frameworks. Wenn keine besonderen Anforderungen bestehen, ist es auch sehr praktisch, die Bilder dieser Frameworks für das Training zu verwenden. Dieser Test verwendet immer noch ein benutzerdefiniertes Bild. In einem benutzerdefinierten Image müssen Sie nicht nur Ihre eigene Umgebung im Image konfigurieren, sondern wenn Sie die Art und Weise ändern, wie der Trainingsjob gestartet wird, müssen Sie auch das Trainingsstartskript ändern. Es gibt ein Startskript „run_train.sh“ im Pfad /home/work/ des offiziellen Bildes, das von der offiziellen Website von Huawei Cloud ModelArts abgerufen wurde. Das angepasste Startskript muss auf der Grundlage dieses Skripts geändert werden. Das Wichtigste, worauf Sie achten sollten, ist Wenn Sie Trainingsergebnisse oder Modelle auf OBS hochladen müssen, müssen Sie auf die Befehle „dls_get_app“ und „dls_upload_model“ zurückgreifen. In unserem Training lautet das hochgeladene Skript wie folgt: Beim Debuggen des Trainingsjobs können Sie derzeit das kostenlose einstündige V100 verwenden. Eines der besseren Dinge am ModelArts-Trainingsjob ist, dass er unsere Versionsverwaltung erleichtert. Die Version zeichnet alle Parameter auf, die durch die Ausführung von Parametern an das Trainingsskript übergeben werden. Sie können auch den Versionsvergleich verwenden, um Parameter zu vergleichen. Ein weiterer praktischer Vorteil besteht darin, dass es basierend auf einer bestimmten Version geändert werden kann, was den Schritt der erneuten Eingabe aller Parameter reduziert und das Debuggen komfortabler macht. Nachdem die Ausbildung im Ausbildungsjob abgeschlossen ist, kann das Model auch in ModelArts eingesetzt und online gestellt werden. Derzeit hat die Optimierung von Gesichtserkennungsalgorithmen einen Engpass erreicht, aber auf technischer Ebene zielt sie auf die Ähnlichkeit von Gesichtsstruktur, Gesichtshaltung, Altersänderungen, Lichtänderungen in komplexen Umgebungen ab. und menschliche Gesichter gibt es immer noch viele Probleme wie die Verdeckung verschiedener Gesichtserkennungstechnologien, die auf der Integration mehrerer Algorithmustechnologien basieren. Darüber hinaus werden Gesichtserkennungssysteme mit der schrittweisen Verbesserung der Gesichtszahlung auch in Banken, Einkaufszentren usw. eingesetzt. Daher sind auch die Sicherheitsprobleme und Angriffsschutzprobleme der Gesichtserkennung dringend zu lösen, beispielsweise die Lebenderkennung , 3D-Gesichtserkennung usw. warten. Schließlich ist die Gesichtserkennung ein relativ ausgereiftes Projekt im Deep Learning, und ihre Entwicklung hängt auch eng mit der technischen Entwicklung des Deep Learning selbst zusammen. Derzeit besteht bei vielen Optimierungen der größte Nachteil des Deep Learning darin, dass es keine entsprechende Mathematik gibt Die theoretische Unterstützung ist ebenfalls sehr begrenzt, daher liegt in Zukunft auch die Forschung am Deep-Learning-Algorithmus selbst im Fokus.
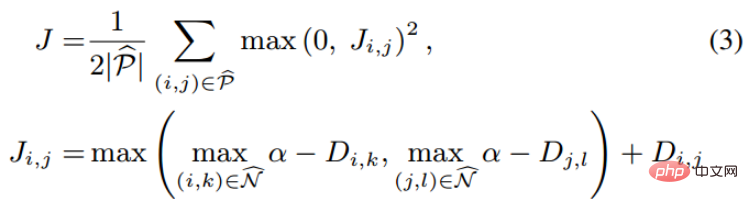
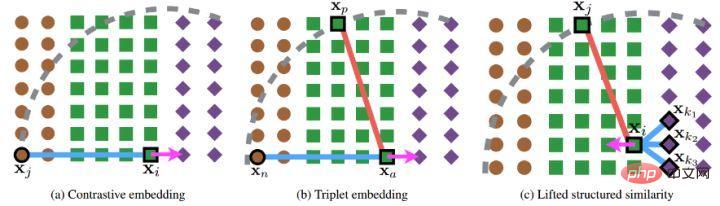
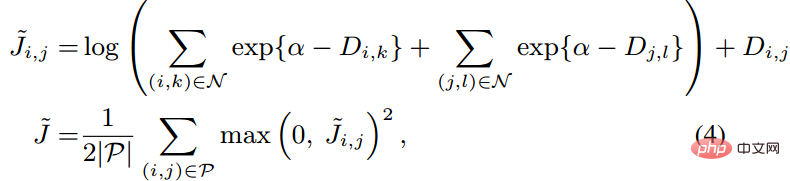
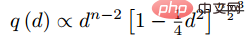
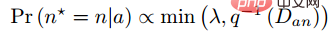
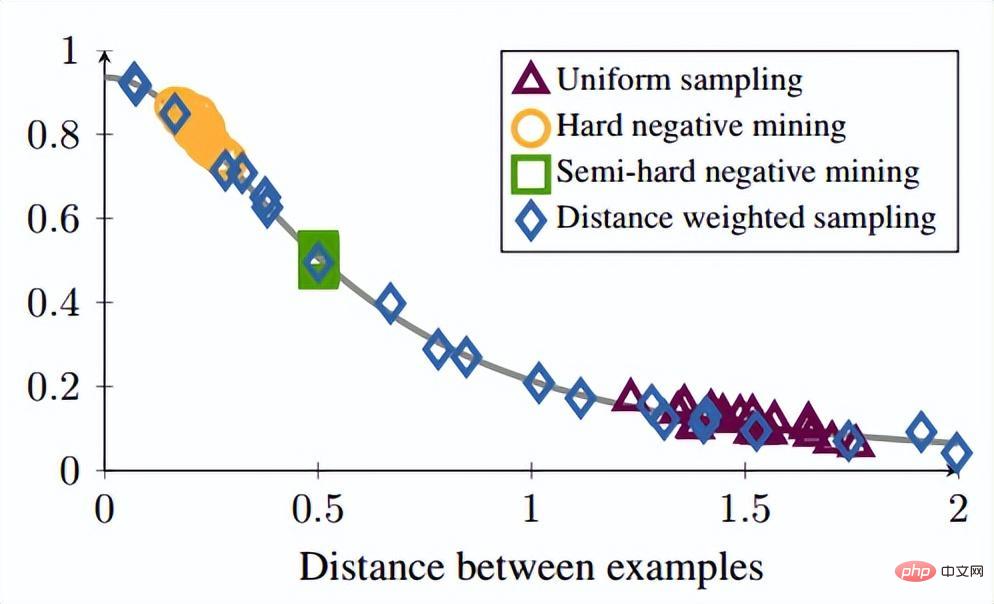
Der Autor entdeckte ein Problem bei der Beobachtung des konservativen Verlusts und des Triplettverlusts. Das heißt, wenn die negative Probe sehr hart ist, ist die Verlustfunktion sehr glatt, was bedeutet, dass der Gradient sehr klein ist Kleine Gradienten sind nicht für das Training geeignet. Dies bedeutet, dass sehr harte Proben nicht vollständig trainiert werden können und das Netzwerk keine effektiven Informationen aus harten Proben erhalten kann, sodass die Wirkung harter Proben schlechter wird. Wenn also der Verlust um die harte Probe nicht so glatt ist, das heißt, die beim Deep Learning häufig verwendete Ableitung ist 1 (wie Relu), dann löst der harte Modus das Problem des Verschwindens des Gradienten. Darüber hinaus muss die Verlustfunktion auch einen Triplettverlust implementieren, um sowohl positive als auch negative Stichproben zu berücksichtigen, und über die Funktion des Margin-Designs verfügen, das darin besteht, sich an unterschiedliche Datenverteilungen anzupassen. Die Verlustfunktion lautet wie folgt: 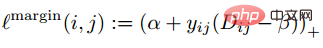
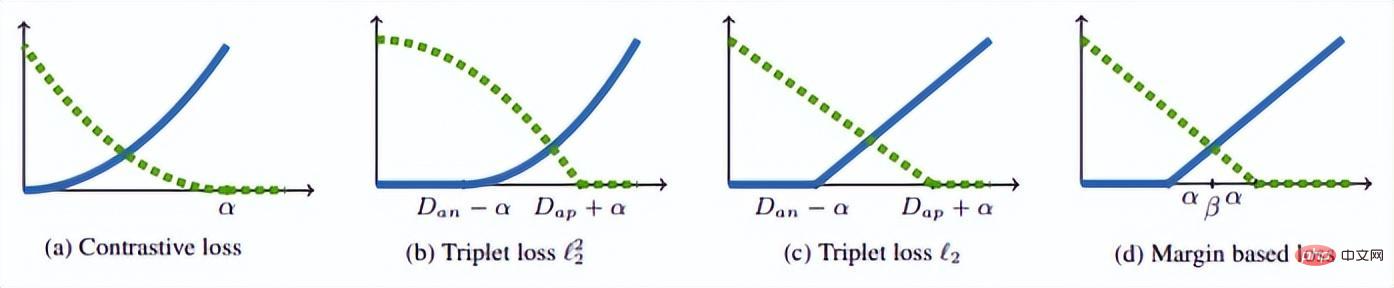
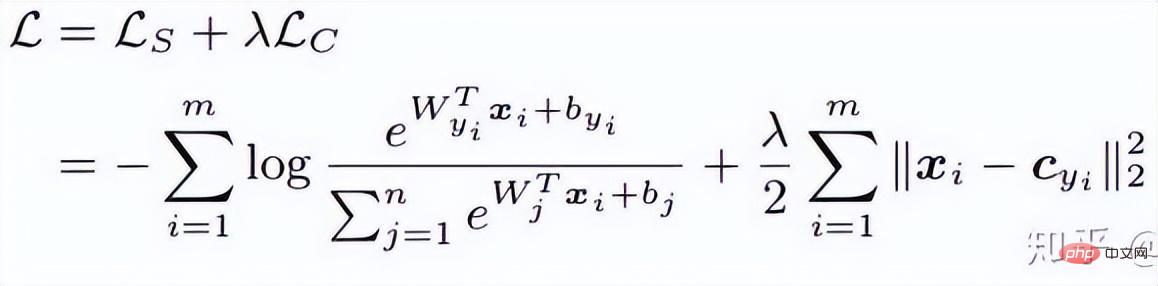
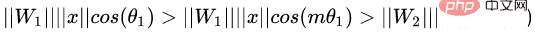
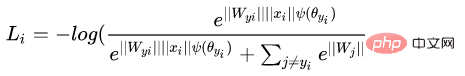
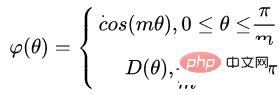
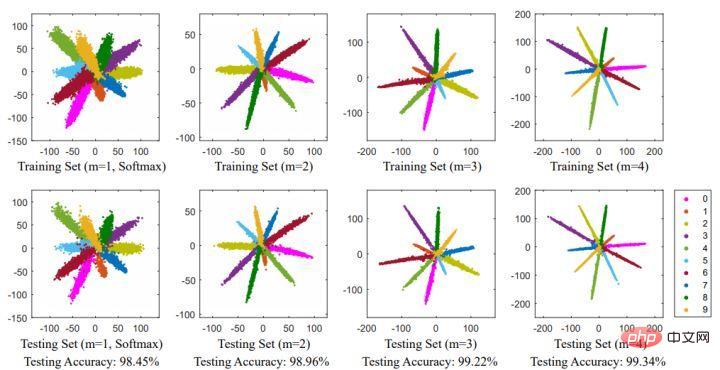
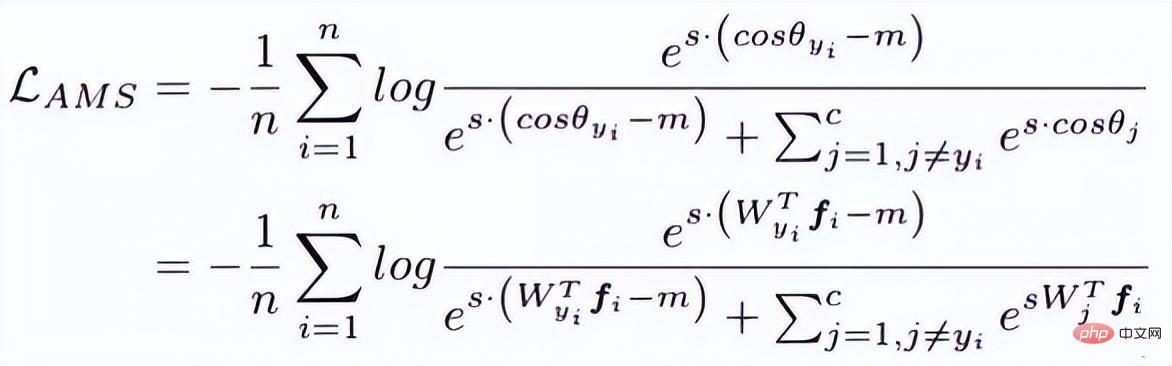
Abschließend verwenden wir das Bild im Artikel, um dieses Problem zu erläutern, und erstellen außerdem eine Zusammenfassung des Teils der margenbasierten Klassifizierung in diesem Kapitel. 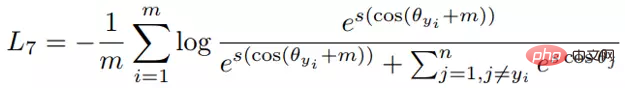
Verwenden Sie ModelArts, um Gesichtsmodelle zu trainieren

run_face_detection_train.sh
Nach dem Login kopieren<span style="color: rgb(111, 66, 193); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">sh</span> run_face_detection_train.sh data_path model_output_path
Nach dem Login kopierendetection_train_data/train/images/label.txtval/images/label.txttest/images/label.txt
Nach dem Login kopierenrun_face_recognition_train.sh
Nach dem Login kopieren<span style="color: rgb(111, 66, 193); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">sh</span> run_face_recognition_train.sh data_path model_output_path
Nach dem Login kopierenrecognition_train_data/cele.idxcele.lstcele.recproperty
Nach dem Login kopierenrun_generate_data_base.sh
Nach dem Login kopieren<span style="color: rgb(111, 66, 193); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">sh</span> run_generate_data_base.sh data_path detect_model_path recognize_model_path db_output_path
Nach dem Login kopierenrun_face_recognition.sh
Nach dem Login kopieren<span style="color: rgb(111, 66, 193); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">sh</span> run_generate_data_base.sh data_path db_path detect_model_path recognize_model_path
Nach dem Login kopieren
Die Docker-Umgebung kann auf dem lokalen Computer erstellt werden, oder Sie können einen elastischen Cloud-Server in der Huawei Cloud erwerben, um die Docker-Umgebung zu erstellen. Informationen zum gesamten Vorgang finden Sie in der offiziellen Docker-Dokumentation: 



Verwenden Sie den Huawei Cloud-Trainingsjob für das Training
„dls_get_app“, das ist der Befehl zum Herunterladen von OBS. Andere Teile werden entsprechend Ihrem eigenen Trainingsskript modifiziert. 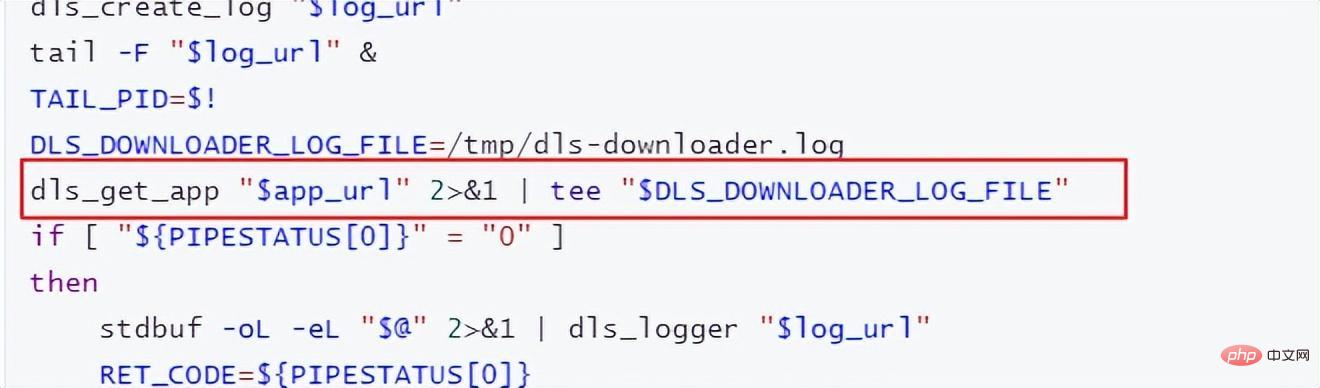

Postscript
Das obige ist der detaillierte Inhalt vonVerstehen Sie den Entwicklungstrend der Gesichtserkennungsalgorithmus-Technologie in einem Artikel. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Welche Währung ist USDT?
Welche Währung ist USDT?
 So lösen Sie den Löschdatei-Fehlercode 5
So lösen Sie den Löschdatei-Fehlercode 5
 So lesen Sie Daten in einer Excel-Datei in Python
So lesen Sie Daten in einer Excel-Datei in Python
 Verlauf der Oracle-Ansichtstabellenoperationen
Verlauf der Oracle-Ansichtstabellenoperationen
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 Welche Software ist cdr
Welche Software ist cdr
 Eine vollständige Liste der Tastenkombinationen für Ideen
Eine vollständige Liste der Tastenkombinationen für Ideen
 Was tun, wenn Linux beim Ausführen einer Datei „Keine solche Datei oder kein solches Verzeichnis' anzeigt?
Was tun, wenn Linux beim Ausführen einer Datei „Keine solche Datei oder kein solches Verzeichnis' anzeigt?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



