


Sucherinnerung als Grundlage des Suchsystems bestimmt die Obergrenze der Effektverbesserung. Die größte Herausforderung, vor der wir stehen, besteht darin, den bestehenden massiven Rückrufergebnissen weiterhin einen differenzierten Mehrwert zu verleihen. Die Kombination aus multimodalem Pre-Training und Recall eröffnet uns neue Horizonte und bringt eine deutliche Verbesserung der Online-Effekte.
Multimodales Vortraining steht im Mittelpunkt der Forschung in Wissenschaft und Industrie. Durch Vortraining an großen Datenmengen kann die semantische Korrespondenz zwischen verschiedenen Modalitäten ermittelt werden, die auf vielfältige Weise verwendet werden kann Bei nachgelagerten Aufgaben können beispielsweise visuelles Beantworten von Fragen, visuelles Denken sowie das Abrufen von Bildern und Texten den Effekt verbessern. Innerhalb der Gruppe gibt es auch einige Forschungen und Anwendungen zum multimodalen Vortraining. Im Taobao-Hauptsuchszenario besteht ein natürlicher modalübergreifender Abrufbedarf zwischen der vom Benutzer eingegebenen Suchanfrage und den abzurufenden Produkten. In der Vergangenheit wurden jedoch mehr Titel und statistische Merkmale für Produkte verwendet. und intuitivere Funktionen wie Bilder wurden ignoriert. Aber bei bestimmten Suchanfragen mit visuellen Elementen (z. B. weißes Kleid, Blumenkleid) glaube ich, dass jeder von dem Bild zuerst auf der Suchergebnisseite angezogen wird.
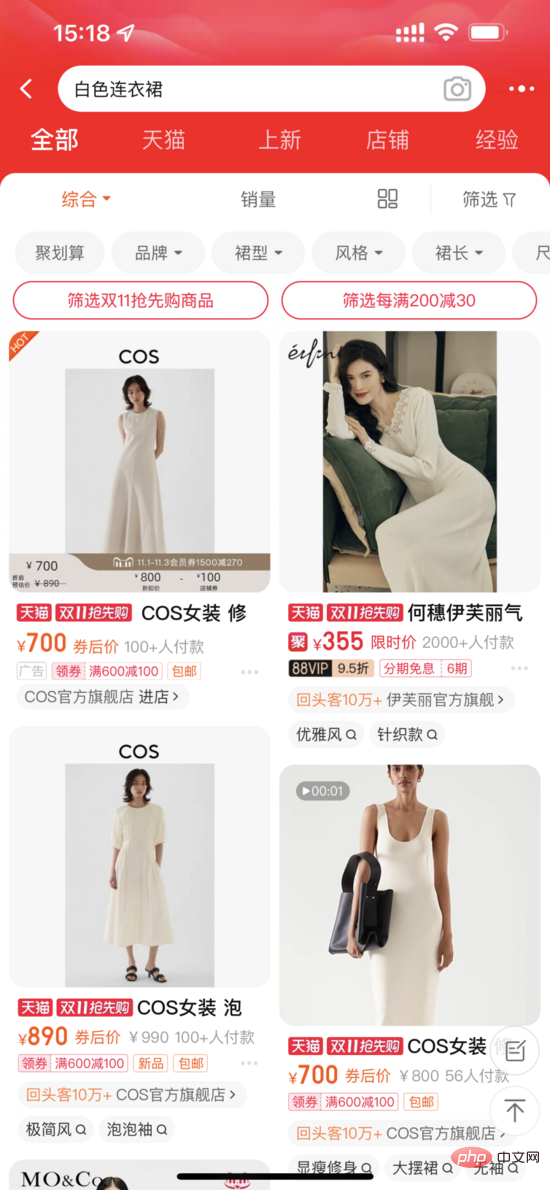

Taobao-Hauptsuchszene
Einerseits nimmt das Bild eine prominentere Position ein, andererseits enthält das Bild möglicherweise Informationen, die nicht im Titel enthalten sind. wie weiße, gebrochene visuelle Elemente wie Blumen. Bei Letzterem sind zwei Situationen zu unterscheiden: Zum einen sind zwar Informationen im Titel vorhanden, diese können aber aufgrund von Anzeigeeinschränkungen nicht vollständig angezeigt werden. Zum anderen hat dies keinen Einfluss auf den Rückruf des Produkts Es gibt keine Informationen im Titel, sondern im Bild. Das heißt, das Bild kann relativ zum Text inkrementiert werden. Auf Letzteres müssen wir uns konzentrieren.
Bei der Anwendung multimodaler Technologie im Hauptszenario für Suche und Rückruf müssen zwei Hauptprobleme gelöst werden:
Unsere Lösung lautet wie folgt:
 wobei das verbleibende Text-Token darstellt
wobei das verbleibende Text-Token darstellt
 wobei die verbleibenden Bildtoken darstellt
wobei die verbleibenden Bildtoken darstellt
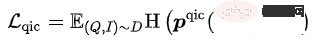 Darunter
Darunter  kann Zur Berechnung stehen verschiedene Methoden zur Verfügung:
kann Zur Berechnung stehen verschiedene Methoden zur Verfügung:
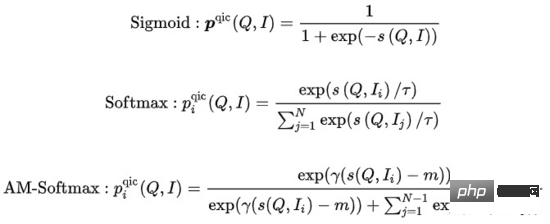
wobei die Ähnlichkeitsberechnung darstellt, den Temperaturhyperparameter darstellt, und m den Skalierungsfaktor bzw. den Relaxationsfaktor darstellen
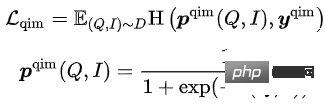
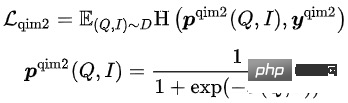
Das Trainingsziel des Modells besteht darin, den Gesamtverlust zu minimieren:
Unter diesen 5 Vortrainingsaufgaben befinden sich die MLM-Aufgabe und die MPM-Aufgabe über dem Item Tower, Modellierung Titel Oder die Fähigkeit, modalübergreifende Informationen zu verwenden, um sich gegenseitig wiederherzustellen, nachdem ein Teil des Tokens des Bildes maskiert wurde. Über dem Abfrageturm gibt es eine unabhängige MLM-Aufgabe. Durch die gemeinsame Nutzung des Encoders des Abfrageturms und des Artikelturms werden die semantische Beziehung und die Lücke zwischen Abfrage und Titel modelliert. Die QIC-Aufgabe verwendet das innere Produkt der beiden Türme, um die Vortrainings- und Downstream-Vektorrückrufaufgaben bis zu einem gewissen Grad auszurichten, und verwendet AM-Softmax, um den Abstand zwischen der Darstellung der Abfrage und der Darstellung der am häufigsten angeklickten Elemente unter der Abfrage zu schließen , und verschieben Sie den Abstand zwischen der Abfrage und den am häufigsten angeklickten Elementen. Die QIM-Aufgabe befindet sich oberhalb des modalübergreifenden Encoders und verwendet modalübergreifende Informationen, um die Übereinstimmung von Abfrage und Element zu modellieren. Aufgrund des Rechenaufwands beträgt das positive und negative Stichprobenverhältnis der üblichen NSP-Aufgabe 1:1. Um den Abstand zwischen positiven und negativen Stichproben weiter zu vergrößern, wird eine schwierige negative Stichprobe basierend auf den Ergebnissen der Ähnlichkeitsberechnung erstellt QIC-Aufgabe. Die QIM2-Aufgabe befindet sich an derselben Stelle wie die QIM-Aufgabe und modelliert explizit die inkrementellen Informationen, die Bilder relativ zu Text liefern. „Vektorrückrufmodell“ Aus Leistungsgründen wird häufig die Struktur der Benutzer- und Artikel-Zwillingstürme zur Berechnung des inneren Produkts von Vektoren verwendet. Ein Kernproblem des Vektorrückrufmodells ist: Wie werden positive und negative Proben erstellt und wie groß ist die Anzahl der negativen Proben. Unsere Lösung besteht darin, den Klick des Benutzers auf einen Artikel auf einer Seite als positive Stichprobe zu verwenden, Zehntausende negativer Stichproben basierend auf der Klickverteilung im gesamten Produktpool abzutasten und mithilfe von „Sampled Softmax Loss“ aus der Stichprobe abzuleiten, dass die Der Artikel befindet sich im vollständigen Produktpool mit Klickwahrscheinlichkeit.
Nach dem gängigen FineTune-Paradigma haben wir versucht, vorab trainierte Vektoren direkt in Twin Towers MLP einzugeben und dabei groß angelegte negative Stichproben und Sampled Softmax zu kombinieren, um den multimodalen Vektorabruf zu trainieren Modell. Im Gegensatz zu den üblichen kleinen Downstream-Aufgaben ist die Trainingsstichprobengröße der Vektorrückrufaufgabe jedoch riesig und liegt in der Größenordnung von Milliarden. Wir haben beobachtet, dass die Parametermenge von MLP das Training des Modells nicht unterstützen kann und bald seinen eigenen Konvergenzzustand erreichen wird, aber der Effekt ist nicht gut. Gleichzeitig werden vorab trainierte Vektoren im Vektorabrufmodell als Eingaben und nicht als Parameter verwendet und können im Verlauf des Trainings nicht aktualisiert werden. Infolgedessen steht das Vortraining für relativ kleine Datenmengen im Widerspruch zu nachgelagerten Aufgaben für große Datenmengen.
Es gibt mehrere Lösungen, das Pre-Training-Modell in das Vektor-Recall-Modell zu integrieren. Allerdings ist die Anzahl der Parameter des Pre-Training-Modells zu groß und mit der Stichprobengröße des Vektor-Recall-Modells verbunden , es kann bei begrenzten Ressourcen nicht verwendet werden. Führen Sie als Nächstes regelmäßige Schulungen zu einem angemessenen Zeitpunkt durch. Eine andere Methode besteht darin, im Vektorabrufmodell eine Parametermatrix zu erstellen, die vorab trainierten Vektoren in die Matrix zu laden und die Parameter der Matrix im Verlauf des Trainings zu aktualisieren. Nach Untersuchungen ist diese Methode hinsichtlich der technischen Umsetzung relativ aufwändig. Auf dieser Grundlage schlagen wir eine Modellstruktur vor, die Vektoraktualisierungen vor dem Training einfach und machbar modelliert.
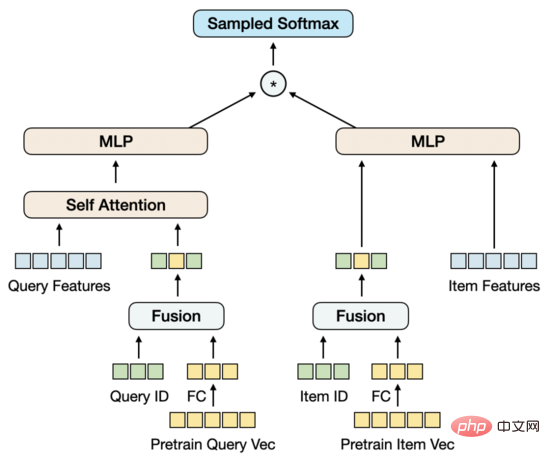
Wir reduzieren zunächst die Dimension des Pre-Training-Vektors durch FC. Der Grund, warum die Dimension hier statt im Pre-Training reduziert wird, liegt im Strom Der hochdimensionale Vektor liegt für eine negative Probenentnahme immer noch im akzeptablen Leistungsbereich. In diesem Fall entspricht die Dimensionsreduzierung bei der Vektorrückrufaufgabe eher dem Trainingsziel. Gleichzeitig führen wir die ID-Einbettungsmatrix von Abfrage und Element ein. Die Einbettungsdimension stimmt mit der Dimension des reduzierten Vortrainingsvektors überein und führt dann die ID und den Vortrainingsvektor zusammen. Der Ausgangspunkt dieses Entwurfs besteht darin, eine Parametermenge einzuführen, die ausreicht, um umfangreiche Trainingsdaten zu unterstützen, und gleichzeitig eine adaptive Aktualisierung des Vortrainingsvektors im Verlauf des Trainings zu ermöglichen.
Bei der Fusion nur von ID- und Pre-Training-Vektoren übersteigt die Wirkung des Modells nicht nur die Wirkung des Twin-Tower-MLP, das nur Pre-Training-Vektoren verwendet, sondern auch das Basismodell MGDSPR, das enthält weitere Funktionen. Darüber hinaus kann die Einführung weiterer Funktionen auf dieser Basis den Effekt weiter verbessern.
Für die Wirkung des Pre-Training-Modells werden normalerweise die Indikatoren der nachgelagerten Aufgaben zur Bewertung verwendet, und einzelne Bewertungsindikatoren werden selten verwendet . Auf diese Weise sind jedoch die Iterationskosten des vorab trainierten Modells relativ hoch, da für jede Iteration einer Version des Modells die entsprechende Vektorrückrufaufgabe trainiert und anschließend die Indikatoren der Vektorrückrufaufgabe ausgewertet werden müssen Der gesamte Prozess wird sehr lang sein. Gibt es wirksame Metriken für die alleinige Bewertung vorab trainierter Modelle? Wir haben Rank@K zum ersten Mal in einigen Artikeln ausprobiert. Dieser Indikator wird hauptsächlich zur Bewertung der Bild-Text-Übereinstimmungsaufgabe verwendet: Verwenden Sie zunächst das vorab trainierte Modell, um den künstlich erstellten Kandidatensatz zu bewerten, und berechnen Sie dann die Top-K-Ergebnisse, sortiert nach Trefferquote für Bild und Text Der Anteil übereinstimmender positiver Proben. Wir haben Rank@K direkt auf die Abfrage-Element-Zuordnungsaufgabe angewendet und festgestellt, dass die Ergebnisse nicht den Erwartungen entsprachen. Ein besseres Pre-Training-Modell mit Rank@K kann im Downstream-Vektor-Recall-Modell schlechtere Ergebnisse erzielen und kann Pre-Training nicht leiten. Training. Iterationen des Trainings des Modells. Auf dieser Grundlage vereinheitlichen wir die Bewertung des Vortrainingsmodells und die Bewertung des Vektorrückrufmodells und verwenden dieselben Bewertungsindikatoren und -prozesse, die die Iteration des Vortrainingsmodells relativ effektiv steuern können.
Recall@K: Der Bewertungsdatensatz besteht aus den Daten des nächsten Tages des Trainingssatzes. Zuerst werden die Klick- und Transaktionsergebnisse verschiedener Benutzer unter derselben Abfrage in  aggregiert Die vom Modell vorhergesagten Top-K-Ergebnisse werden berechnet Pre-Training/Vektor-Recall-Modell und verwenden Sie den Abruf des nächsten Nachbarn, um eine Abfrage der Top-K-Elemente zu erhalten. Dieser Prozess simuliert den Vektorrückruf in der Online-Engine, um die Konsistenz zwischen Offline und Online aufrechtzuerhalten. Für das vorab trainierte Modell besteht der Unterschied zwischen diesem Indikator und Rank@K darin, dass die Abfrage- und Elementvektoren aus dem Modell für den Abruf des inneren Vektorprodukts extrahiert werden, anstatt direkt das Modalfusionsmodell zu verwenden, um zusätzlich eine Abfrage zu bewerten Um nicht nur übereinstimmende Elemente abzurufen, ist es auch erforderlich, Klicks und Transaktionselemente verschiedener Benutzer im Rahmen dieser Abfrage abzurufen.
aggregiert Die vom Modell vorhergesagten Top-K-Ergebnisse werden berechnet Pre-Training/Vektor-Recall-Modell und verwenden Sie den Abruf des nächsten Nachbarn, um eine Abfrage der Top-K-Elemente zu erhalten. Dieser Prozess simuliert den Vektorrückruf in der Online-Engine, um die Konsistenz zwischen Offline und Online aufrechtzuerhalten. Für das vorab trainierte Modell besteht der Unterschied zwischen diesem Indikator und Rank@K darin, dass die Abfrage- und Elementvektoren aus dem Modell für den Abruf des inneren Vektorprodukts extrahiert werden, anstatt direkt das Modalfusionsmodell zu verwenden, um zusätzlich eine Abfrage zu bewerten Um nicht nur übereinstimmende Elemente abzurufen, ist es auch erforderlich, Klicks und Transaktionselemente verschiedener Benutzer im Rahmen dieser Abfrage abzurufen.
Für das Vektorrückrufmodell müssen Sie nach dem Anstieg von Recall@K auf ein bestimmtes Niveau auch auf die Korrelation zwischen Abfrage und Element achten. Ein Modell mit geringer Relevanz wird, selbst wenn es die Sucheffizienz verbessern kann, auch mit einer Verschlechterung der Benutzererfahrung und einer Zunahme von Beschwerden und einer Zunahme der öffentlichen Meinung aufgrund einer Zunahme schlechter Fälle konfrontiert sein. Wir verwenden ein Offline-Modell, das mit dem Online-Korrelationsmodell konsistent ist, um die Korrelation zwischen Abfrage und Artikel sowie zwischen Abfrage- und Artikelkategorien zu bewerten.
Wir haben in einigen Kategorien einen Produktpool mit einer Ebene von 100 Millionen ausgewählt, um einen Datensatz vor dem Training zu erstellen.
Unser Basismodell ist ein optimiertes FashionBert, das QIM- und QIM2-Aufgaben hinzufügt. Beim Extrahieren von Abfrage- und Elementvektoren verwenden wir Mean Pooling nur für Nicht-Padding-Tokens. Die folgenden Experimente untersuchen die Vorteile, die die Modellierung mit zwei Türmen im Vergleich zu einem einzelnen Turm mit sich bringt, und geben die Rolle wichtiger Teile durch Ablationsexperimente an.

Aus diesen Experimenten können wir folgende Schlussfolgerungen ziehen:
Wir haben 1 Milliarde angeklickte Seiten ausgewählt, um einen Vektor-Recall-Datensatz zu erstellen. Jede Seite enthält 3 Klickelemente als positive Proben, und 10.000 negative Proben werden basierend auf der Klickverteilung aus dem Produktpool entnommen. Auf dieser Grundlage konnte keine signifikante Verbesserung des Effekts durch eine weitere Ausweitung der Trainingsdatenmenge oder eine negative Probenentnahme beobachtet werden.
Unser Basismodell ist das MGDSPR-Modell der Hauptsuche. Die folgenden Experimente untersuchen die Vorteile, die durch die Kombination von multimodalem Vortraining mit Vektorrückruf im Vergleich zur Grundlinie erzielt werden, und geben die Rolle wichtiger Teile durch Ablationsexperimente an.
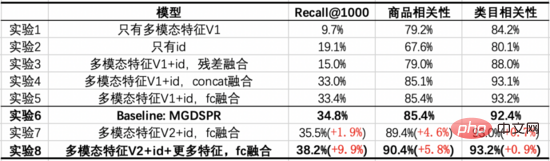
Aus diesen Experimenten können wir die folgenden Schlussfolgerungen ziehen:
Wir haben aus den Top-1000-Ergebnissen des Vektorrückrufmodells die Elemente herausgefiltert, die das Online-System abrufen konnte, und festgestellt, dass die Korrelation der verbleibenden inkrementellen Ergebnisse im Wesentlichen unverändert ist. Bei einer großen Anzahl von Abfragen sehen wir, dass diese inkrementellen Ergebnisse Bildinformationen über den Produkttitel hinaus erfassen und eine gewisse Rolle in der semantischen Lücke zwischen Abfrage und Titel spielen. Suchanfrage: Hübscher Anzug
Suchanfrage: Taillenbetontes Damenhemd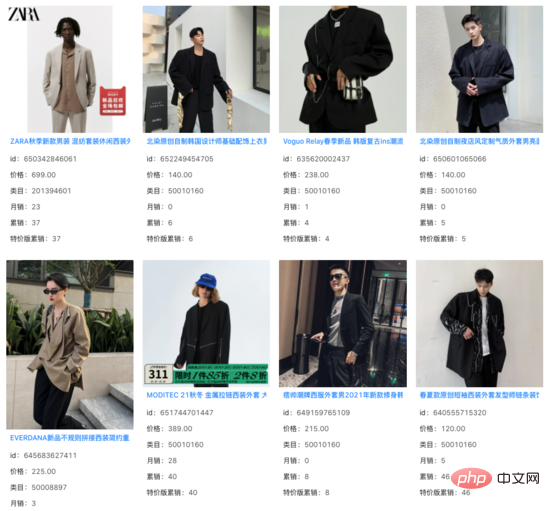
Um die Anwendungsanforderungen des Hauptsuchszenarios zu erfüllen, haben wir ein Text-Bild-Vortrainingsmodell vorgeschlagen, das die Struktur des quermodalen Dual-Tower-Eingabe-Encoders für Abfragen und Elemente übernimmt, in dem die Der Artikelturm enthält mehrere Bilder und Texte. Die Matching-Aufgaben „Query-Item“ und „Query-Image“ sowie die Multiklassifizierungsaufgabe „Query-Item“, die durch das innere Produkt der Zwillingstürme „Query“ und „Item“ modelliert wird, bringen das Vortraining näher an die nachgelagerte Vektorabrufaufgabe heran. Gleichzeitig wird die Aktualisierung vorab trainierter Vektoren im Vektorabruf modelliert. Bei begrenzten Ressourcen kann ein Vortraining mit relativ kleinen Datenmengen dennoch die Leistung nachgelagerter Aufgaben verbessern, die große Datenmengen verwenden.
In anderen Hauptsuchszenarien, wie z. B. Produktverständnis, Relevanz und Sortierung, besteht auch die Notwendigkeit, multimodale Technologie anzuwenden. Wir haben uns auch an der Erforschung dieser Szenarien beteiligt und sind davon überzeugt, dass die multimodale Technologie in Zukunft für immer mehr Szenarien Vorteile bringen wird.
Taobao-Hauptsuchrückrufteam: Das Team ist für den Rückruf und die grobe Sortierung der Links im Hauptsuchlink verantwortlich. Die aktuelle technische Hauptrichtung ist der personalisierte Vektorrückruf mit mehreren Zielen basierend auf Vollraumproben. und groß angelegte Vorhersagen basierend auf trainiertem multimodalem Rückruf, ähnlichem semantischem Umschreiben von Abfragen basierend auf kontrastivem Lernen und groben Ranking-Modellen usw.
Das obige ist der detaillierte Inhalt vonErforschung der multimodalen Technologie in Taobao-Hauptsucherinnerungsszenarien. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was bedeutet Taobao b2c?
Was bedeutet Taobao b2c?
 Taobao passwortfreie Zahlung
Taobao passwortfreie Zahlung
 Welche Fähigkeiten sind erforderlich, um in der PHP-Branche zu arbeiten?
Welche Fähigkeiten sind erforderlich, um in der PHP-Branche zu arbeiten?
 Was bedeutet Legacy-Startup?
Was bedeutet Legacy-Startup?
 Was sind die DOS-Befehle?
Was sind die DOS-Befehle?
 So fahren Sie Ihren Computer schnell herunter
So fahren Sie Ihren Computer schnell herunter
 Der Unterschied zwischen ++a und a++ in der C-Sprache
Der Unterschied zwischen ++a und a++ in der C-Sprache
 So bereinigen Sie das Laufwerk C des Computers, wenn es voll ist
So bereinigen Sie das Laufwerk C des Computers, wenn es voll ist








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



