


Derzeit verwenden viele Anwendungen wie Google News Clustering-Algorithmen als Hauptimplementierungsmethode. Sie können große Mengen unbeschrifteter Daten verwenden, um leistungsstarkes Themen-Clustering zu erstellen. In diesem Artikel werden 6 Arten gängiger Methoden vorgestellt, vom grundlegendsten K-Means-Clustering bis hin zu leistungsstarken dichtebasierten Methoden. Sie haben jeweils ihre eigenen Fachgebiete und Szenarien, und die Grundideen sind nicht unbedingt auf Clustering-Methoden beschränkt.

Dieser Artikel beginnt mit einem einfachen und effizienten K-Means-Clustering und stellt dann Mean-Shift-Clustering, dichtebasiertes Clustering, Clustering mit Gaußschen Mischungs- und Maximum-Erwartungs-Methoden, hierarchisches Clustering und Methoden vor, die für strukturierte Datengruppen geeignet sind Erkennung. Wir analysieren nicht nur die grundlegenden Implementierungskonzepte, sondern geben auch die Vor- und Nachteile jedes Algorithmus an, um tatsächliche Anwendungsszenarien zu verdeutlichen.
Clustering ist eine Technik des maschinellen Lernens, bei der Datenpunkte gruppiert werden. Bei einer gegebenen Menge von Datenpunkten können wir einen Clustering-Algorithmus verwenden, um jeden Datenpunkt einer bestimmten Gruppe zuzuordnen. Theoretisch sollten Datenpunkte, die zur gleichen Gruppe gehören, ähnliche Eigenschaften und/oder Merkmale haben, während Datenpunkte, die zu verschiedenen Gruppen gehören, sehr unterschiedliche Eigenschaften und/oder Merkmale haben sollten. Clustering ist eine unbeaufsichtigte Lernmethode und eine Technik zur statistischen Datenanalyse, die in vielen Bereichen häufig verwendet wird.
K-Means ist wahrscheinlich der bekannteste Clustering-Algorithmus. Es ist Teil vieler Einführungskurse in die Datenwissenschaft und das maschinelle Lernen. Sehr einfach zu verstehen und im Code zu implementieren! Bitte sehen Sie sich das Bild unten an.

K-Means Clustering
Zuerst wählen wir einige Klassen/Gruppen aus und initialisieren ihre jeweiligen Mittelpunkte zufällig. Um die Anzahl der zu verwendenden Klassen zu ermitteln, empfiehlt es sich, einen kurzen Blick auf die Daten zu werfen und zu versuchen, die verschiedenen Gruppen zu identifizieren. Der Mittelpunkt ist der Ort mit der gleichen Länge wie jeder Datenpunktvektor, der im obigen Bild „X“ ist.
Klassifizieren Sie jeden Punkt, indem Sie den Abstand zwischen dem Datenpunkt und der Mitte jeder Gruppe berechnen, und klassifizieren Sie dann den Punkt in die Gruppe, der die Gruppenmitte am nächsten liegt.
Basierend auf diesen Klassifizierungspunkten verwenden wir den Mittelwert aller Vektoren in der Gruppe, um das Gruppenzentrum neu zu berechnen.
Wiederholen Sie diese Schritte für eine bestimmte Anzahl von Iterationen oder bis sich das Gruppenzentrum nach jeder Iteration kaum ändert. Sie können das Gruppenzentrum auch einige Male nach dem Zufallsprinzip initialisieren und dann den Lauf auswählen, der die besten Ergebnisse zu liefern scheint.
K-Means hat den Vorteil, dass es schnell ist, da wir eigentlich nur den Abstand zwischen dem Punkt und dem Mittelpunkt der Gruppe berechnen: sehr wenig Rechenaufwand! Es hat also eine lineare Komplexität O(n).
Andererseits hat K-Means einige Nachteile. Zuerst müssen Sie auswählen, wie viele Gruppen/Klassen es gibt. Dies geschieht nicht immer sorgfältig, und im Idealfall möchten wir, dass der Clustering-Algorithmus uns bei der Lösung des Problems hilft, wie viele Klassen zu klassifizieren sind, da sein Zweck darin besteht, Erkenntnisse aus den Daten zu gewinnen. K-Means startet auch von zufällig ausgewählten Clusterzentren, sodass es in verschiedenen Algorithmen zu unterschiedlichen Clustering-Ergebnissen führen kann. Daher sind die Ergebnisse möglicherweise nicht reproduzierbar und nicht konsistent. Andere Clustering-Methoden sind konsistenter.
K-Medians ist ein weiterer Clustering-Algorithmus im Zusammenhang mit K-Means, mit der Ausnahme, dass die Gruppenzentren nicht anhand des Mittelwerts, sondern mithilfe des Medianvektors der Gruppe neu berechnet werden. Diese Methode ist unempfindlich gegenüber Ausreißern (da der Median verwendet wird), ist jedoch bei größeren Datensätzen viel langsamer, da bei der Berechnung des Medianvektors bei jeder Iteration eine Sortierung erforderlich ist.
Mean Shift Clustering ist ein auf Schiebefenstern basierender Algorithmus, der versucht, dichte Bereiche von Datenpunkten zu finden. Hierbei handelt es sich um einen Schwerpunkt-basierten Algorithmus, dessen Ziel es ist, den Mittelpunkt jeder Gruppe/Klasse zu lokalisieren. Dies wird erreicht, indem die Kandidatenpunkte des Mittelpunkts auf den Mittelwert der Punkte innerhalb des Schiebefensters aktualisiert werden. Diese Kandidatenfenster werden dann in einer Nachbearbeitungsphase gefiltert, um Beinahe-Duplikate zu eliminieren und so den endgültigen Satz von Mittelpunkten und ihren entsprechenden Gruppen zu bilden. Bitte beachten Sie die Legende unten.

Mean-Shift-Clustering für ein einzelnes Schiebefenster
Der gesamte Prozess von Anfang bis Ende für alle Schiebefenster ist unten dargestellt. Jeder schwarze Punkt repräsentiert den Schwerpunkt des Schiebefensters und jeder graue Punkt repräsentiert einen Datenpunkt.

Der gesamte Prozess des Mean-Shift-Clusterings
Im Vergleich zum K-Means-Clustering erfordert diese Methode nicht die Auswahl der Anzahl der Cluster, da die Mean-Shift dies automatisch erkennt. Das ist ein großer Vorteil. Die Tatsache, dass sich die Clusterzentren in Richtung der maximalen Punktdichte gruppieren, ist ebenfalls sehr zufriedenstellend, da es sehr intuitiv ist, die natürlichen datengesteuerten Implikationen zu verstehen und sich daran anzupassen. Der Nachteil besteht darin, dass die Wahl der Fenstergröße/des Fensterradius „r“ möglicherweise unwichtig ist.
DBSCAN ist ein dichtebasierter Clustering-Algorithmus, der dem Mean Shift ähnelt, aber einige erhebliche Vorteile bietet. Schauen Sie sich unten eine weitere lustige Grafik an und legen Sie los!

DBSCAN hat viele Vorteile gegenüber anderen Clustering-Algorithmen. Erstens ist überhaupt keine feste Anzahl von Clustern erforderlich. Außerdem werden Ausreißer als Rauschen identifiziert, im Gegensatz zur Mittelwertverschiebung, bei der Datenpunkte einfach in Clustern gruppiert werden, selbst wenn sie sehr unterschiedlich sind. Darüber hinaus ist es sehr gut in der Lage, Cluster jeder Größe und Form zu finden.
Der Hauptnachteil von DBSCAN besteht darin, dass es nicht so gut funktioniert wie andere Clustering-Algorithmen, wenn die Dichte der Cluster unterschiedlich ist. Dies liegt daran, dass sich die Einstellungen des Entfernungsschwellenwerts ε und minPoints, die zur Identifizierung von Nachbarschaftspunkten verwendet werden, mit Clustern ändern, wenn sich die Dichte ändert. Dieser Nachteil tritt auch bei sehr hochdimensionalen Daten auf, da der Abstandsschwellenwert ε wiederum schwer abzuschätzen ist.
Ein großer Nachteil von K-Means ist die einfache Verwendung von Cluster-Center-Mitteln. Aus dem Diagramm unten können wir ersehen, warum dies nicht der beste Ansatz ist. Auf der linken Seite können Sie sehr deutlich erkennen, dass es zwei kreisförmige Cluster mit unterschiedlichen Radien gibt, deren Mittelpunkt auf dem gleichen Mittelwert liegt. K-Means kann diese Situation nicht bewältigen, da die Mittelwerte dieser Cluster sehr nahe beieinander liegen. K-Means schlägt auch in Fällen fehl, in denen die Cluster nicht kreisförmig sind, wiederum aufgrund der Verwendung des Mittelwerts als Clusterzentrum.

Zwei Fehlerfälle von K-Means
Gaußsche Mischungsmodelle (GMMs) geben uns mehr Flexibilität als K-Means. Für GMMs gehen wir davon aus, dass die Datenpunkte gaußverteilt sind; dies ist eine weniger restriktive Annahme als die Verwendung des Mittelwerts zur Annahme, dass sie kreisförmig sind. Auf diese Weise haben wir zwei Parameter, um die Form des Clusters zu beschreiben: Mittelwert und Standardabweichung! Am Beispiel von 2D bedeutet dies, dass die Cluster jede Art von elliptischer Form annehmen können (da wir Standardabweichungen sowohl in x- als auch in y-Richtung haben). Daher wird jede Gaußsche Verteilung einem einzelnen Cluster zugeordnet.
Um die Gaußschen Parameter (wie Mittelwert und Standardabweichung) jedes Clusters zu ermitteln, verwenden wir einen Optimierungsalgorithmus namens Expectation Maximum (EM). Schauen Sie sich das Diagramm unten an, das ein Beispiel für eine Gaußsche Anpassung an einen Cluster ist. Anschließend können wir den Prozess des Maximum-Expectation-Clusterings mithilfe von GMMs fortsetzen.

Der Einsatz von GVMs bietet zwei wesentliche Vorteile. Erstens sind GMMs hinsichtlich der Cluster-Kovarianz flexibler als K-Means; aufgrund des Standardabweichungsparameters können Cluster jede elliptische Form annehmen, anstatt auf Kreise beschränkt zu sein. K-Means ist eigentlich ein Sonderfall von GMM, bei dem die Kovarianz jedes Clusters in allen Dimensionen nahe bei 0 liegt. Zweitens kann es viele Cluster pro Datenpunkt geben, da GMMs Wahrscheinlichkeiten verwenden. Wenn sich ein Datenpunkt also in der Mitte zweier überlappender Cluster befindet, können wir seine Klasse einfach dadurch definieren, dass wir sagen, dass X Prozent davon zur Klasse 1 und Y Prozent zur Klasse 2 gehören. Das heißt, GMMs unterstützen hybride Qualifikationen.
Hierarchische Clustering-Algorithmen werden tatsächlich in zwei Kategorien unterteilt: Top-Down oder Bottom-Up. Bottom-up-Algorithmen behandeln zunächst jeden Datenpunkt als einen einzelnen Cluster und führen dann nacheinander zwei Cluster zusammen (oder aggregieren), bis alle Cluster zu einem einzigen Cluster zusammengeführt sind, der alle Datenpunkte enthält. Daher wird hierarchisches Bottom-up-Clustering als agglomeratives hierarchisches Clustering oder HAC bezeichnet. Diese Clusterhierarchie wird durch einen Baum (oder ein Dendrogramm) dargestellt. Die Wurzel des Baumes ist der einzige Cluster, der alle Proben sammelt, und die Blätter sind die Cluster mit nur einer Probe. Bevor Sie mit den Schritten des Algorithmus beginnen, sehen Sie sich bitte die Legende unten an.

Agglomerative hierarchische Clusterbildung
Hierarchisches Clustering erfordert nicht, dass wir die Anzahl der Cluster angeben. Wir können sogar auswählen, welche Anzahl von Clustern am besten aussieht, da wir einen Baum erstellen. Darüber hinaus ist der Algorithmus nicht empfindlich gegenüber der Wahl der Distanzmetrik; sie funktionieren alle gleich gut, wohingegen bei anderen Clustering-Algorithmen die Wahl der Distanzmetrik entscheidend ist. Ein besonders gutes Beispiel für hierarchische Clustering-Methoden ist, wenn die zugrunde liegenden Daten eine hierarchische Struktur haben und Sie die Hierarchie wiederherstellen möchten; andere Clustering-Algorithmen können dies nicht. Im Gegensatz zur linearen Komplexität von K-Means und GMM gehen diese Vorteile der hierarchischen Clusterbildung auf Kosten einer geringeren Effizienz, da sie eine zeitliche Komplexität von O(n³) aufweist.
Wenn unsere Daten als Netzwerk oder Diagramm dargestellt werden können, können wir die Graph-Community-Erkennungsmethode verwenden, um das Clustering abzuschließen. In diesem Algorithmus wird eine Graphengemeinschaft normalerweise als eine Teilmenge von Eckpunkten definiert, die enger miteinander verbunden sind als andere Teile des Netzwerks.
Der vielleicht intuitivste Fall sind soziale Netzwerke. Die Eckpunkte stellen Personen dar, und die die Eckpunkte verbindenden Kanten stellen Benutzer dar, die Freunde oder Fans sind. Um ein System jedoch als Netzwerk zu modellieren, müssen wir einen Weg finden, die verschiedenen Komponenten effizient zu verbinden. Zu den innovativen Anwendungen der Graphentheorie für die Clusterbildung gehören die Merkmalsextraktion von Bilddaten, die Analyse von Genregulationsnetzwerken usw.
Unten sehen Sie ein einfaches Diagramm, das 8 kürzlich aufgerufene Websites zeigt, die über Links auf ihren Wikipedia-Seiten miteinander verbunden sind.

Die Farbe dieser Eckpunkte zeigt ihre Gruppenbeziehung an und die Größe wird anhand ihrer Zentralität bestimmt. Diese Cluster machen auch im wirklichen Leben Sinn, wo die gelben Scheitelpunkte normalerweise Referenz-/Suchseiten und die blauen Scheitelpunkte alle Online-Veröffentlichungsseiten (Artikel, Tweets oder Code) sind.
Angenommen, wir haben das Netzwerk in Gruppen gruppiert. Diesen Modularitätswert können wir dann verwenden, um die Qualität des Clusterings zu bewerten. Eine höhere Punktzahl bedeutet, dass wir das Netzwerk in „genaue“ Gruppen segmentiert haben, während eine niedrige Punktzahl bedeutet, dass unsere Clusterbildung eher zufällig ist. Wie in der folgenden Abbildung gezeigt:

Modularität kann mit der folgenden Formel berechnet werden:

wobei L die Anzahl der Kanten im Netzwerk darstellt, k_i und k_j sich auf den Grad jedes Scheitelpunkts beziehen, der möglich ist berechnet werden, indem jede Zeile addiert wird. Sie wird durch Addition der Elemente in jeder Spalte erhalten. Die Multiplikation der beiden und die Division durch 2L stellt die erwartete Anzahl von Kanten zwischen den Eckpunkten i und j dar, wenn das Netzwerk zufällig zugewiesen wird.
Insgesamt stellen die Begriffe in Klammern den Unterschied zwischen der wahren Struktur des Netzwerks und der erwarteten Struktur dar, wenn sie zufällig kombiniert werden. Die Untersuchung seines Werts zeigt, dass er den höchsten Wert zurückgibt, wenn A_ij = 1 und ( k_i k_j ) / 2L klein ist. Dies bedeutet, dass bei einer „unerwarteten“ Kante zwischen den Fixpunkten i und j der resultierende Wert höher ist.
Das letzte δc_i, c_j ist die berühmte Kronecker-δ-Funktion (Kronecker-Delta-Funktion). Hier ist die Python-Erklärung:

Die Modularität des Diagramms kann mit der obigen Formel berechnet werden. Je höher die Modularität, desto besser ist der Grad der Gruppierung des Netzwerks in verschiedene Gruppen. Der beste Weg, das Netzwerk zu gruppieren, kann daher gefunden werden, indem durch Optimierungsmethoden nach maximaler Modularität gesucht wird.
Kombinatorik sagt uns, dass es für ein Netzwerk mit nur 8 Eckpunkten 4140 verschiedene Clustering-Methoden gibt. Ein Netzwerk aus 16 Eckpunkten würde auf über 10 Milliarden Arten gruppiert werden. Die möglichen Clustering-Methoden eines Netzwerks mit 32 Eckpunkten werden 128 Septillionen (10^21) überschreiten; wenn Ihr Netzwerk 80 Eckpunkte hat, übersteigt die Anzahl der möglichen Clustering-Methoden die Anzahl der Clustering-Methoden im beobachtbaren Universum.
Wir müssen also auf eine Heuristik zurückgreifen, die bei der Bewertung der Cluster mit den höchsten Modularitätswerten gut funktioniert, ohne jede Möglichkeit auszuprobieren. Hierbei handelt es sich um einen Algorithmus namens Fast-Greedy Modularity-Maximization, der dem oben beschriebenen agglomerativen hierarchischen Clustering-Algorithmus etwas ähnelt. Es ist nur so, dass Mod-Max Gruppen nicht basierend auf der Entfernung zusammenfasst, sondern Gruppen basierend auf Änderungen in der Modularität.
So funktioniert es:
Community-Erkennung ist ein beliebtes Forschungsgebiet in der Graphentheorie. Ihre Einschränkungen spiegeln sich hauptsächlich darin wider, dass sie einige kleine Cluster ignoriert und nur auf strukturierte Graphenmodelle anwendbar ist. Allerdings weist diese Art von Algorithmus eine sehr gute Leistung bei typischen strukturierten Daten und realen Netzwerkdaten auf.
Das Obige sind die 6 wichtigsten Clustering-Algorithmen, die Datenwissenschaftler kennen sollten! Am Ende dieses Artikels zeigen wir Visualisierungen verschiedener Algorithmen!
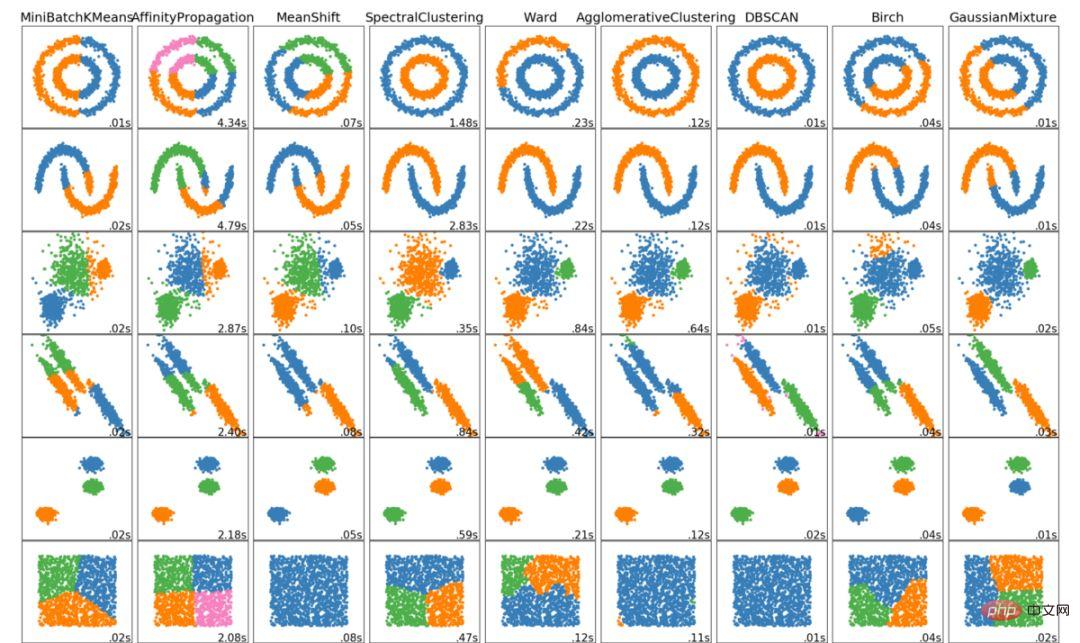
Das obige ist der detaillierte Inhalt vonSechs Clustering-Algorithmen, die Datenwissenschaftler kennen müssen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Algorithmus zum Ersetzen von Seiten
Algorithmus zum Ersetzen von Seiten
 So stellen Sie Videos wieder her, die offiziell aus Douyin entfernt wurden
So stellen Sie Videos wieder her, die offiziell aus Douyin entfernt wurden
 So erstellen Sie einen Softlink
So erstellen Sie einen Softlink
 Was bedeutet Marge in CSS?
Was bedeutet Marge in CSS?
 Nach dem Einschalten des Computers zeigt der Monitor kein Signal
Nach dem Einschalten des Computers zeigt der Monitor kein Signal
 PS-Tastenkombinationen für Helligkeit und Kontrast
PS-Tastenkombinationen für Helligkeit und Kontrast
 Was ist der Unterschied zwischen GUID- und MBR-Formaten?
Was ist der Unterschied zwischen GUID- und MBR-Formaten?
 Datenstruktur der C-Sprache
Datenstruktur der C-Sprache








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



