

 Technologie-Peripheriegeräte
KI
Wahrnehmungsnetzwerk zur Tiefen-, Lage- und Straßeneinschätzung in gemeinsamen Fahrszenarien
Technologie-Peripheriegeräte
KI
Wahrnehmungsnetzwerk zur Tiefen-, Lage- und Straßeneinschätzung in gemeinsamen Fahrszenarien
Wahrnehmungsnetzwerk zur Tiefen-, Lage- und Straßeneinschätzung in gemeinsamen Fahrszenarien

Das am 22. Juli hochgeladene arXiv-Papier „JPerceiver: Joint Perception Network for Depth, Pose and Layout Estimation in Driving Scenes“ berichtet über die Arbeit von Professor Tao Dacheng von der University of Sydney, Australien, und dem Beijing JD Research Institute.

Tiefenschätzung, visuelle Odometrie (VO) und Szenenlayoutschätzung aus der Vogelperspektive (BEV) sind drei Schlüsselaufgaben für die Wahrnehmung von Fahrszenen, die die Grundlage für Bewegungsplanung und Navigation beim autonomen Fahren bilden. Obwohl sie sich ergänzen, konzentrieren sie sich in der Regel auf separate Aufgaben und behandeln selten alle drei gleichzeitig.
Ein einfacher Ansatz besteht darin, dies unabhängig in sequentieller oder paralleler Weise durchzuführen, aber es gibt drei Nachteile, nämlich 1) Tiefe und VO-Ergebnisse werden durch das inhärente Skalenmehrdeutigkeitsproblem beeinflusst; 2) BEV-Layout wird normalerweise separat für Straße und Straße geschätzt Fahrzeug, wobei die explizite Overlay-Underlay-Beziehung ignoriert wird. 3) Obwohl die Tiefenkarte ein nützlicher geometrischer Anhaltspunkt für die Ableitung des Szenenlayouts ist, wird das BEV-Layout tatsächlich direkt aus dem Vorderansichtsbild vorhergesagt, ohne dass tiefenbezogene Informationen verwendet werden.
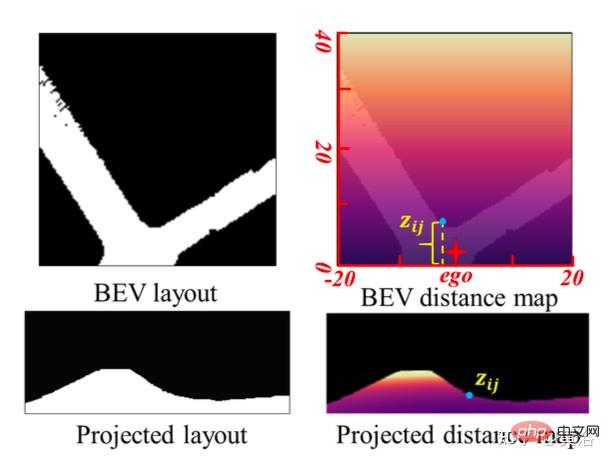
Dieser Artikel schlägt ein gemeinsames Wahrnehmungs-Framework JPerceiver vor, um diese Probleme zu lösen und gleichzeitig die skalenwahrgenommene Tiefe, VO- und BEV-Layout aus monokularen Videosequenzen zu schätzen. Verwenden Sie die geometrische Cross-View-Transformation (CGT), um den absoluten Maßstab vom Straßenlayout auf die Tiefe und VO gemäß einem sorgfältig entworfenen Maßstabsverlust zu übertragen. Gleichzeitig soll ein Cross-View- und Cross-Modal-Transfer-Modul (CCT) Tiefenhinweise nutzen, um durch Aufmerksamkeitsmechanismen Überlegungen zum Straßen- und Fahrzeuglayout anzustellen.
JPerceiver ist in einer End-to-End-Multitask-Lernmethode geschult, bei der die CGT-Skalenverlust- und CCT-Module den Wissenstransfer zwischen Aufgaben fördern und das Lernen von Funktionen für jede Aufgabe erleichtern. Der Code und das Modell können heruntergeladen werdenhttps://github.com/sunnyHelen/JPerceiver.
Wie in der Abbildung gezeigt, besteht JPerceiver aus drei Netzwerken: Tiefe, Haltung und Straßenlayout , die alle auf einer Encoder-Decoder-Architektur basieren. Das Tiefennetzwerk zielt darauf ab, die Tiefenkarte Dt des aktuellen Frames It vorherzusagen, wobei jeder Tiefenwert den Abstand zwischen einem 3D-Punkt und der Kamera darstellt. Das Ziel des Posennetzwerks besteht darin, die Posentransformation Tt→t+m zwischen dem aktuellen Frame It und seinem benachbarten Frame It+m vorherzusagen. Das Ziel des Straßenlayoutnetzwerks besteht darin, das BEV-Layout Lt des aktuellen Rahmens abzuschätzen, dh die semantische Belegung von Straßen und Fahrzeugen in der kartesischen Draufsichtebene. Die drei Netzwerke werden im Training gemeinsam optimiert.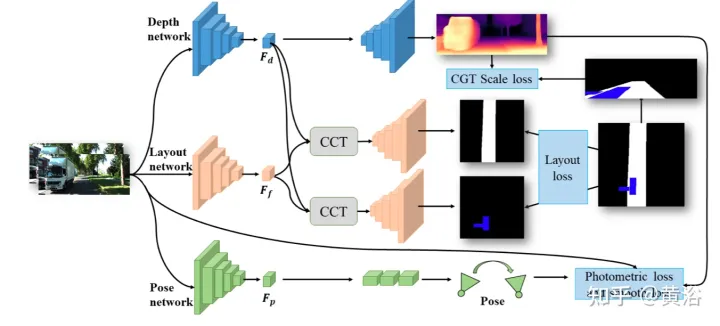
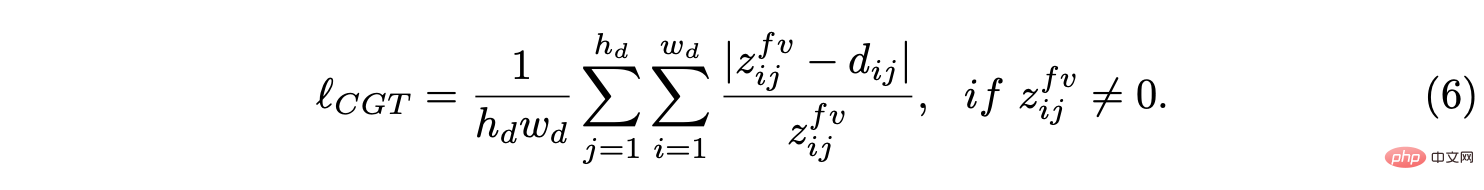
CCT -CV und CCT-CM des Cross-View-Moduls und des Cross-Modal-Moduls.
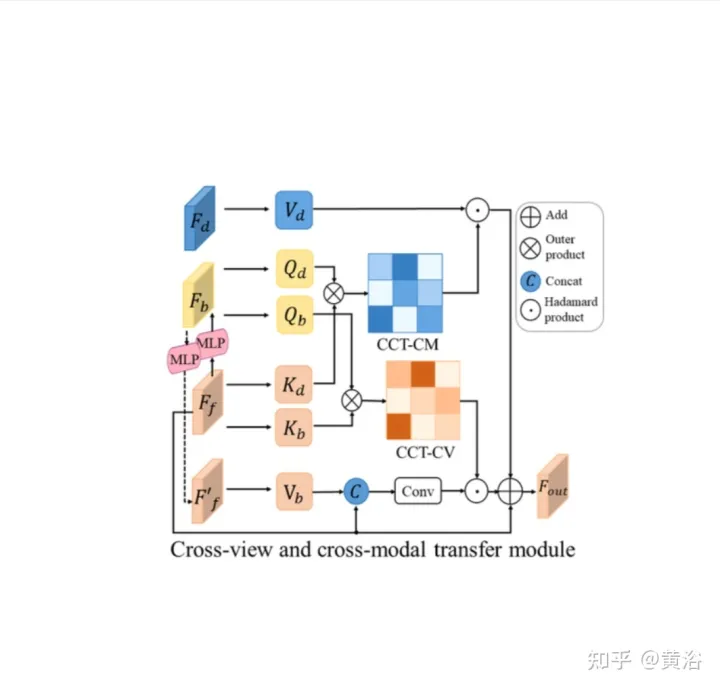
In CCT werden Ff und Fd vom Encoder des entsprechenden Wahrnehmungszweigs extrahiert, während Fb durch einen Ansichtsprojektions-MLP zur Konvertierung von Ff in BEV und einen zyklusverlustbeschränkten gleichen MLP zur erneuten Konvertierung in Ff′ erhalten wird.
In CCT-CV wird der Queraufmerksamkeitsmechanismus verwendet, um die geometrische Entsprechung zwischen der Vorwärtsansicht und den BEV-Merkmalen zu ermitteln. Anschließend leitet er die Verfeinerung der Vorwärtsansichtsinformationen und bereitet die BEV-Schlussfolgerung vor. Um die Bildfunktionen der Vorwärtsansicht vollständig nutzen zu können, werden Fb und Ff auf Patches projiziert: Qbi und Kbi als Abfrage bzw. Schlüssel.
Zusätzlich zur Nutzung der Vorwärtsansichtsfunktionen wird CCT-CM auch zum Übertragen von 3D-Geometrieinformationen aus Fd eingesetzt. Da Fd aus dem Vorwärtsansichtsbild extrahiert wird, ist es sinnvoll, Ff als Brücke zu verwenden, um die modalübergreifende Lücke zu verringern und die Entsprechung zwischen Fd und Fb zu lernen. Fd spielt die Rolle des Werts, wodurch wertvolle 3D-Geometrieinformationen im Zusammenhang mit BEV-Informationen erhalten und die Genauigkeit der Straßenlayoutschätzung weiter verbessert werden.
Bei der Erforschung eines gemeinsamen Lernrahmens zur gleichzeitigen Vorhersage verschiedener Layouts gibt es große Unterschiede in den Merkmalen und Verteilungen verschiedener semantischer Kategorien. Für Features muss in der Regel das Straßenlayout in Fahrszenarien verbunden werden, während unterschiedliche Fahrzeugziele segmentiert werden müssen.
Für die Verteilung werden mehr gerade Straßenszenen als Abbiegeszenen beobachtet, was in realen Datensätzen sinnvoll ist. Dieser Unterschied und dieses Ungleichgewicht erhöhen die Schwierigkeit des BEV-Layout-Lernens, insbesondere der gemeinsamen Vorhersage verschiedener Kategorien, da ein einfacher Kreuzentropieverlust (CE) oder L1-Verlust in diesem Fall fehlschlägt. Mehrere Segmentierungsverluste, darunter verteilungsbasierter CE-Verlust, regionsbasierter IoU-Verlust und Grenzverlust, werden zu einem Hybridverlust kombiniert, um das Layout jeder Kategorie vorherzusagen.
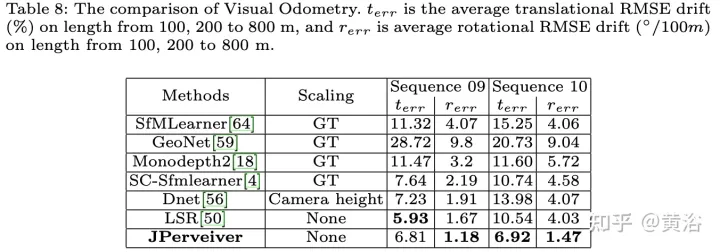
Die experimentellen Ergebnisse sind wie folgt:
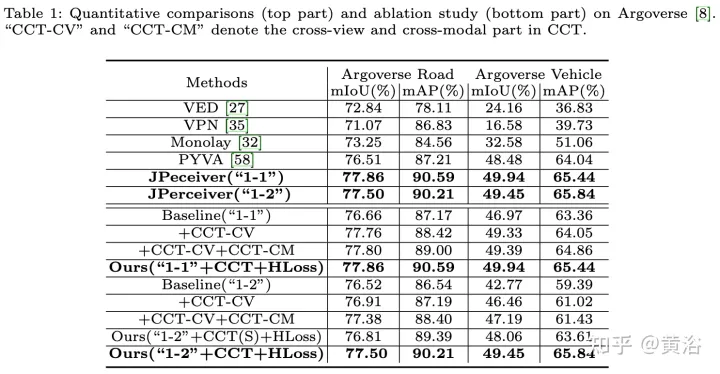
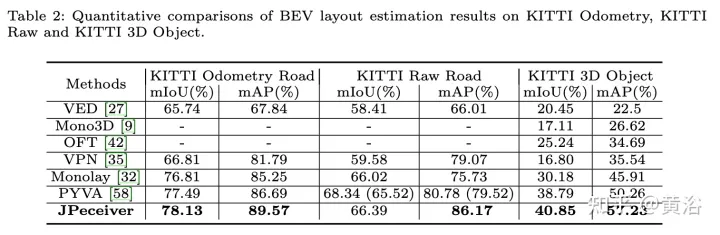
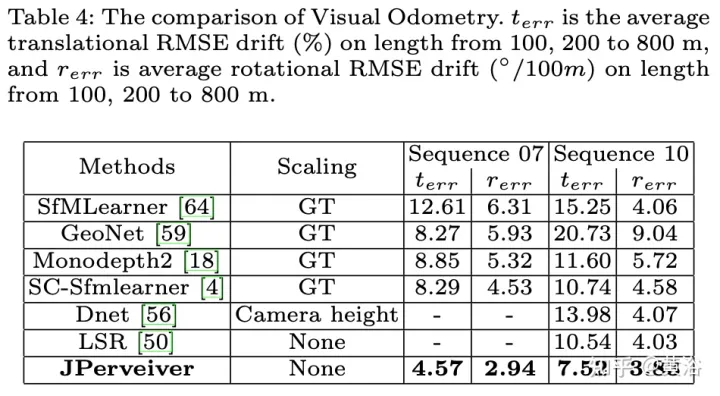
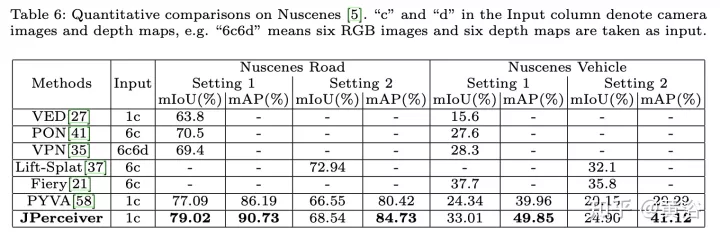
Das obige ist der detaillierte Inhalt vonWahrnehmungsnetzwerk zur Tiefen-, Lage- und Straßeneinschätzung in gemeinsamen Fahrszenarien. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undress AI Tool
Ausziehbilder kostenlos

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)



 Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Oben geschrieben und persönliches Verständnis des Autors. Dreidimensionales Gaussplatting (3DGS) ist eine transformative Technologie, die in den letzten Jahren in den Bereichen explizite Strahlungsfelder und Computergrafik entstanden ist. Diese innovative Methode zeichnet sich durch die Verwendung von Millionen von 3D-Gaußkurven aus, was sich stark von der Neural Radiation Field (NeRF)-Methode unterscheidet, die hauptsächlich ein implizites koordinatenbasiertes Modell verwendet, um räumliche Koordinaten auf Pixelwerte abzubilden. Mit seiner expliziten Szenendarstellung und differenzierbaren Rendering-Algorithmen garantiert 3DGS nicht nur Echtzeit-Rendering-Fähigkeiten, sondern führt auch ein beispielloses Maß an Kontrolle und Szenenbearbeitung ein. Dies positioniert 3DGS als potenziellen Game-Changer für die 3D-Rekonstruktion und -Darstellung der nächsten Generation. Zu diesem Zweck geben wir erstmals einen systematischen Überblick über die neuesten Entwicklungen und Anliegen im Bereich 3DGS.
 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Sparse4D v3 ist da! Weiterentwicklung der End-to-End-3D-Erkennung und -Verfolgung
Nov 24, 2023 am 11:21 AM
Sparse4D v3 ist da! Weiterentwicklung der End-to-End-3D-Erkennung und -Verfolgung
Nov 24, 2023 am 11:21 AM
Neuer Titel: Sparse4Dv3: Advancing End-to-End 3D Detection and Tracking Technology Papierlink: https://arxiv.org/pdf/2311.11722.pdf Der Inhalt, der neu geschrieben werden muss, ist: Codelink: https://github. com/linxuewu/ Inhalt neu geschrieben von Sparse4D: Die Zugehörigkeit des Autors ist Horizon Company. Thesenidee: Im autonomen Fahrwahrnehmungssystem sind 3D-Erkennung und -Verfolgung zwei grundlegende Aufgaben. Dieser Artikel befasst sich eingehender mit diesem Bereich basierend auf dem Sparse4D-Framework. In diesem Artikel werden zwei zusätzliche Trainingsaufgaben vorgestellt (temporales Instanz-Denoising-TemporalInstanceDenoising und Qualitätsschätzung-Q).
 Beherrschen Sie die Koordinatensystemkonvertierung wirklich? Multisensorik-Themen, die für das autonome Fahren unverzichtbar sind
Oct 12, 2023 am 11:21 AM
Beherrschen Sie die Koordinatensystemkonvertierung wirklich? Multisensorik-Themen, die für das autonome Fahren unverzichtbar sind
Oct 12, 2023 am 11:21 AM
Der erste Pilot- und Schlüsselartikel stellt hauptsächlich mehrere häufig verwendete Koordinatensysteme in der autonomen Fahrtechnologie vor und erläutert, wie die Korrelation und Konvertierung zwischen ihnen abgeschlossen und schließlich ein einheitliches Umgebungsmodell erstellt werden kann. Der Schwerpunkt liegt hier auf dem Verständnis der Umrechnung vom Fahrzeug in den starren Kamerakörper (externe Parameter), der Kamera-in-Bild-Konvertierung (interne Parameter) und der Bild-in-Pixel-Einheitenkonvertierung. Die Konvertierung von 3D in 2D führt zu entsprechenden Verzerrungen, Verschiebungen usw. Wichtige Punkte: Das Fahrzeugkoordinatensystem und das Kamerakörperkoordinatensystem müssen neu geschrieben werden: Das Ebenenkoordinatensystem und das Pixelkoordinatensystem. Schwierigkeit: Sowohl die Entzerrung als auch die Verzerrungsaddition müssen auf der Bildebene kompensiert werden. 2. Einführung Insgesamt gibt es vier visuelle Systeme Koordinatensystem: Pixelebenenkoordinatensystem (u, v), Bildkoordinatensystem (x, y), Kamerakoordinatensystem () und Weltkoordinatensystem (). Es gibt eine Beziehung zwischen jedem Koordinatensystem,
 SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
Originaltitel: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper-Link: https://arxiv.org/pdf/2402.02519.pdf Code-Link: https://github.com/HKUST-Aerial-Robotics/SIMPL Autor: Hong Kong University of Science und Technologie DJI-Papieridee: Dieses Papier schlägt eine einfache und effiziente Bewegungsvorhersagebasislinie (SIMPL) für autonome Fahrzeuge vor. Im Vergleich zum herkömmlichen Agent-Cent
 Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
0. Vorab geschrieben&& Persönliches Verständnis, dass autonome Fahrsysteme auf fortschrittlichen Wahrnehmungs-, Entscheidungs- und Steuerungstechnologien beruhen, indem sie verschiedene Sensoren (wie Kameras, Lidar, Radar usw.) verwenden, um die Umgebung wahrzunehmen, und Algorithmen und Modelle verwenden für Echtzeitanalysen und Entscheidungsfindung. Dies ermöglicht es Fahrzeugen, Verkehrszeichen zu erkennen, andere Fahrzeuge zu erkennen und zu verfolgen, das Verhalten von Fußgängern vorherzusagen usw. und sich so sicher an komplexe Verkehrsumgebungen anzupassen. Diese Technologie erregt derzeit große Aufmerksamkeit und gilt als wichtiger Entwicklungsbereich für die Zukunft des Transportwesens . eins. Aber was autonomes Fahren schwierig macht, ist herauszufinden, wie man dem Auto klarmachen kann, was um es herum passiert. Dies erfordert, dass der dreidimensionale Objekterkennungsalgorithmus im autonomen Fahrsystem Objekte in der Umgebung, einschließlich ihrer Standorte, genau wahrnehmen und beschreiben kann.
 Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Die Trajektorienvorhersage spielt eine wichtige Rolle beim autonomen Fahren. Unter autonomer Fahrtrajektorienvorhersage versteht man die Vorhersage der zukünftigen Fahrtrajektorie des Fahrzeugs durch die Analyse verschiedener Daten während des Fahrvorgangs. Als Kernmodul des autonomen Fahrens ist die Qualität der Trajektorienvorhersage von entscheidender Bedeutung für die nachgelagerte Planungssteuerung. Die Trajektorienvorhersageaufgabe verfügt über einen umfangreichen Technologie-Stack und erfordert Vertrautheit mit der dynamischen/statischen Wahrnehmung des autonomen Fahrens, hochpräzisen Karten, Fahrspurlinien, Fähigkeiten in der neuronalen Netzwerkarchitektur (CNN&GNN&Transformer) usw. Der Einstieg ist sehr schwierig! Viele Fans hoffen, so schnell wie möglich mit der Flugbahnvorhersage beginnen zu können und Fallstricke zu vermeiden. Heute werde ich eine Bestandsaufnahme einiger häufiger Probleme und einführender Lernmethoden für die Flugbahnvorhersage machen! Einführungsbezogenes Wissen 1. Sind die Vorschaupapiere in Ordnung? A: Schauen Sie sich zuerst die Umfrage an, S
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
